想學好深度學習,你需要了解——熵!
- 2020 年 1 月 2 日
- 筆記

熵的概念比較晦澀難懂。但是,我們還是想最大化的用容易理解的語言將它說明白。盡量不要讓這部分知識成為大家學習的絆腳石。
歡迎一起討論,不足之處還望多多指正。具體內容如下。
7.7 快速了解資訊熵 (information entropy)
資訊熵 (information entropy)是一個度量單位,用來對資訊進行量化。比如可以用資訊熵來量化一本書所含有的資訊量。它就好比用米、厘米對長度進行量化一樣。
資訊熵這個詞是克勞德·艾爾伍德·香農從熱力學中借用過來的。在熱力學中,用熱熵來表示分子狀態混亂程度的物理量。克勞德·艾爾伍德·香農用資訊熵的概念來描述信源的不確定度。
7.7.1 資訊熵與概率的計算關係
任何資訊都存在冗餘,冗餘大小與資訊中每個符號(數字、字母或單詞)的出現概率或者說不確定性有關。
資訊熵是指去掉冗餘資訊後的平均資訊量。其值與資訊中每個符號的概率密切相關。
提示:
在Shannon 編碼定理中,介紹了熵是傳輸一個隨機變數狀態值所需的比特位下界。該定理的主要依據就是資訊熵中沒有冗餘資訊。
依據Shannon 編碼定理資訊熵還可以應用在數據壓縮方面。
一個信源發送出什麼符號是不確定的,衡量它可以根據其出現的概率來度量。概率大,出現機會多,不確定性小;反之不確定性就大,則資訊熵就越大。
1.資訊熵的特點
假設計算資訊熵的函數是I,計算概率的函數是P,則資訊熵的特點可以有如下表示:
(1)I是P的減函數。
(2)兩個獨立符號所產生的不確定性(資訊熵)應等於各自不確定性之和,即I(P1,P2)=I(P1)+I(P2)。
2.自資訊的計算公式
資訊熵屬於一個抽象概念,其計算方法本沒有固定公式。任何符合資訊熵特點的公式都可以被用作資訊熵的計算。
對數函數是一個符合資訊熵特性的函數。具體解釋如下:
(1)假設兩個是獨立不相關事件的概率為P(x,y),則P(x,y)=P(x)P(y)。
(2)如果將對數公式引入資訊熵計算的計算,則I(x,y)= log(P(x,y))=log(P(x))+log(P(y))。
(3)因為I(x)=log(P(x)),I(y)=log(P(y)),則I(x,y)=I(x)+I(y),正好符合資訊熵的可加性。
為了滿足I是P的減函數,則直接對P取倒數即可。於是,引入對數函數的資訊熵其公式可以寫成公式7-3。

(式7-3)
公式7-3中的I(x) 也被稱為隨機變數 x 的自資訊 (self-information),描述的是隨機變數的某個事件發生所帶來的資訊量。該函數在坐標軸上的曲線如圖7-46所示。

圖7-46 自資訊公式
由圖7-46可以看出,因為概率p的取值範圍為0~1,公式7-3中的負號也可以用來保證資訊量是非負數。
3.資訊熵的計算公式
在信源中,假如一個符號U可以有n種取值:U1…Ui…Un,對應概率為:P1…Pi…Pn,且各種符號的出現彼此獨立。則該信源所表達的資訊量可以通過求 I(x)=−logp(U)關於概率分布 p(U) 的期望得到。那麼U的資訊熵便可以寫成公式7-4。

(式7-4)
目前,資訊熵大多都是通過公式7-4進行計算的。在數學中對數一般取2為底,單位為比特。在神經網路中,對數一般以自然對數e為底,單位常常被稱為奈特(nats)。
由公式7-4可以看出,隨機變數的取值個數越多,狀態數也就越多,資訊熵就越大,說明混亂程度就越大。
以一個最簡單的單符號二元信源為例,該信源中的符號U僅可以取值為a或b。其中,取a的概率為p,則取b的概率為1-p。該信源的資訊熵可以記為H(U)=pI(p)+(1-p)I(1-p)。所形成的曲線如圖7-47所示。

圖7-47 二元信源的資訊熵
圖7-47中,x軸代表符號U取值為a的概率值P,y軸代表符號U的資訊熵H(U)。由圖7-47可以看出資訊熵有如下幾個特性:
(1)確定性:當符號U取值為a的概率值P=0和P=1時,U的值是確定的,沒有任何變化量,所以資訊熵為0。
(2)極值性:當P=0.5時,U的資訊熵達到了最大。這表明當變數U的取值為均勻分布時(所有的取值的概率都相同),熵最大。
(3)對稱性:即對稱於P=0.5
(4)非負性:即收到一個信源符號所獲得的資訊量應為正值,H(U)≥0。
4.了解連續資訊熵及其特性
在「3 資訊熵的計算公式」中所介紹公式適用於離散信源,即信源中的變數都是從離散數據中取值。
在資訊理論中,還有一種連續信源,即信源中的變數是從連續數據中取值。連續信源可以取值無限,資訊量是無限大,對其求資訊熵已無意義。一般常會已其它的連續信源做參照,用相對熵的值進行度量。此時連續資訊熵可以用來表示,它是一個有限的相對值,又稱相對熵(見7.7.4小節)。
連續資訊熵與離散信源的資訊熵特性相似,仍具有可加性。不同的是,連續信源的資訊熵不具非負性。但是,在取兩熵的差值為互資訊時,它仍具有非負性。這與力學中勢能的定義相仿。
7.7.2 了解聯合熵 (Joint entropy)
聯合熵 (Joint entropy)是將一維隨機變數分布推廣到多維隨機變數分布。設兩個變數X和Y ,它們的聯合資訊熵也可以由聯合概率P(X,Y)進行計算得來。如公式7-5。

公式7-5
公式7-5中的聯合概率分布P(X,Y)是指X,Y同時滿足某一條件的概率。還可以被記作P(XY)或者P(X∩Y)。
7.7.3 了解條件熵 (Conditional entropy)
條件熵 H()表示在已知隨機變數X的條件下隨機變數Y的不確定性。條件熵 H() 可以由聯合概率P(x,y)和條件概率P(y|x)進行計算得來。見公式7-6。
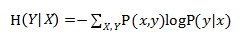
公式7-6
1.條件概率及對應的計算公式
公式7-6中的條件概率分布P(Y|X)是指Y基於X的條件概率,即在X的條件下Y出現的概率。它與聯合概率的關係見公式7-7。

公式7-7
公式7-7中的P(X)是指X的邊際概率(也叫邊緣概率)。整個公式可以描述為:「XY的聯合概率」等於「Y基於X的條件概率」乘以「X的邊際概率」。
2.條件熵對應的計算公式
條件熵 H(Y|X)的計算公式與條件概率非常相似,也可以由X和Y 的聯合資訊熵計算而來。見公式7-8。

公式7-8
公式7-8可以描述為:條件熵 H(Y|X)=聯合熵 H(X,Y) 減去X單獨的熵(邊緣熵) H(X)。即描述X和Y所需的資訊是描述X自己所需的資訊,加上給定X的條件下具體化Y所需的額外資訊。
7.7.4 交叉熵 (Cross entropy)
交叉熵在神經網路中常用於計算分類模型的損失。其數學意義可以有如下解釋:
假設樣本集的概率分布為p(x),模型預測結果的概率分布為q(x),則真實樣本集的資訊熵如公式7-9

(式7-9)
如果使用模型預測結果的概率分布為q(x)來表示來數據集中樣本分類的資訊熵,則公式可以寫成7-10

(式7-10)
公式7-10則為q(x)與p(x)的交叉熵。因為分類的概率來自於樣本集,所以式中的概率部分用q(x),而熵部分則是神經網路的計算結果,所以用q(x)。
7.7.5 相對熵 (Relative entropy)——KL散度
相對熵(relative entropy)又被稱為KL散度(Kullback-Leibler divergence)或資訊散度(information divergence),用來度量是兩個概率分布(probability distribution)間的非對稱性差異。在資訊理論中,相對熵等價於兩個概率分布的資訊熵(Shannon entropy)的差值。
1.相對熵的公式
設 p(x)、q(x) 是離散隨機變數X中取值的兩個概率分布,則p對 q的相對熵見公式7-11。

公式7-11
由公式7-11可知,當p(x)與q(x) 兩個概率分布相同時,相對熵為0(因為log1=0),並且相對熵具有不對稱性。
2.相對熵的與交叉熵之間的關係
將7-11的對數部分展開,可以看到相對熵與交叉熵之間的關係。見公式7-12

公式7-12
由7-12可以看出,p與 q的相對熵是由二者的交叉熵去掉p邊緣熵而來的。在深度學習中,由於訓練數據集是固定的,即p的熵一定,最小化交叉熵便等價於最小化預測結果與真實分布之間的相對熵(模型的輸出分布與真實分布的相對熵越小,表明模型對真實樣本擬合效果越好)。這也是為什麼要用交叉熵作為損失函數的原因。
在變分自編碼中,使用相對熵來計算損失,該損失函數用於指導生成器模型輸出的樣本分布更接近於高斯分布。因為目標分布不再是常數(不是來自於固定的樣本集),所以無法用交叉熵來代替。這也是為什麼變分自編碼中使用KL散度的原因。
7.7.6 互資訊(Mutual Information)
互資訊(Mutual Information)是資訊理論里一種有用的資訊度量,它用於度量2個變數間的共享資訊量。可以看成是一個隨機變數中包含的關於另一個隨機變數的資訊量,或者說是一個隨機變數由於已知另一個隨機變數而減少的不肯定性。
1.互資訊公式
設兩個變數X和Y ,它們的聯合概率分布為P(X,Y),邊際概率分別是P(X)、P(Y)。互資訊是指聯合概率P(X,Y)與邊際概率P(X)、P(Y)的相對熵。見公式7-13

公式7-13
2.互資訊的特性
互資訊具有一下特性:
(1) 對稱性:由於互資訊屬於兩個變數間的共享資訊,則
(2)獨立的變數間互資訊為0:如果兩個變數獨立,則它們之間沒有任何共享資訊,所以此時的互資訊為0。
(3)非負性:共享資訊要麼有,要麼沒有,所以互資訊量不會出現負值。
3.互資訊與條件熵之間的換算
由條件熵的公式7-8得知 (見7.7.3小節) ,聯合熵H(X,Y)可以由條件熵 H(Y|X)與X邊緣熵 H(X)相加而成。見公式7-14:

公式7-14
將7-14中等號兩邊交換位置,則也可以得到互資訊的公式,見式7-15

公式7-15
公式7-15與7-13是等價的(這裡省略了證明等價的推導過程)。
4.互資訊與聯合熵之間的換算
將式7-15的互資訊公式進一步展開,可以得到互資訊與聯合熵之間的關係。見公式7-16
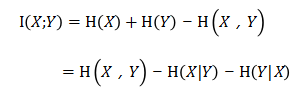
公式7-16
如果把互資訊當作集合運算中的並集。則會更好理解。如圖7-48所示。
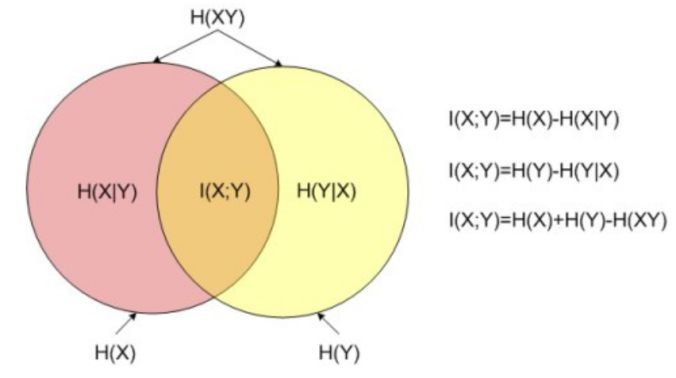
5.互資訊與相對熵之間的換算
互資訊還可以表示為兩個隨機變數X、Y 邊緣分布的乘積,相對於X、Y 聯合概率分布的相對熵。具體公式如式7-17。

公式7-17
在對抗神經網路(f-gan)以及圖神經網路(DGI)中,使用了互資訊來做為無監督方式提取特徵的方法。具體實現過程及配套程式碼請參考7.8節、11.10節。
以上內容節選自程式碼醫生工作室正在編寫的深度學習系列書籍——《深度學習之Pytorch:入門、原理與進階實戰》

推薦閱讀

點擊「閱讀原文」圖書配套資源


