耗時一個月,整理出這份Hadoop吐血寶典
本文目錄:
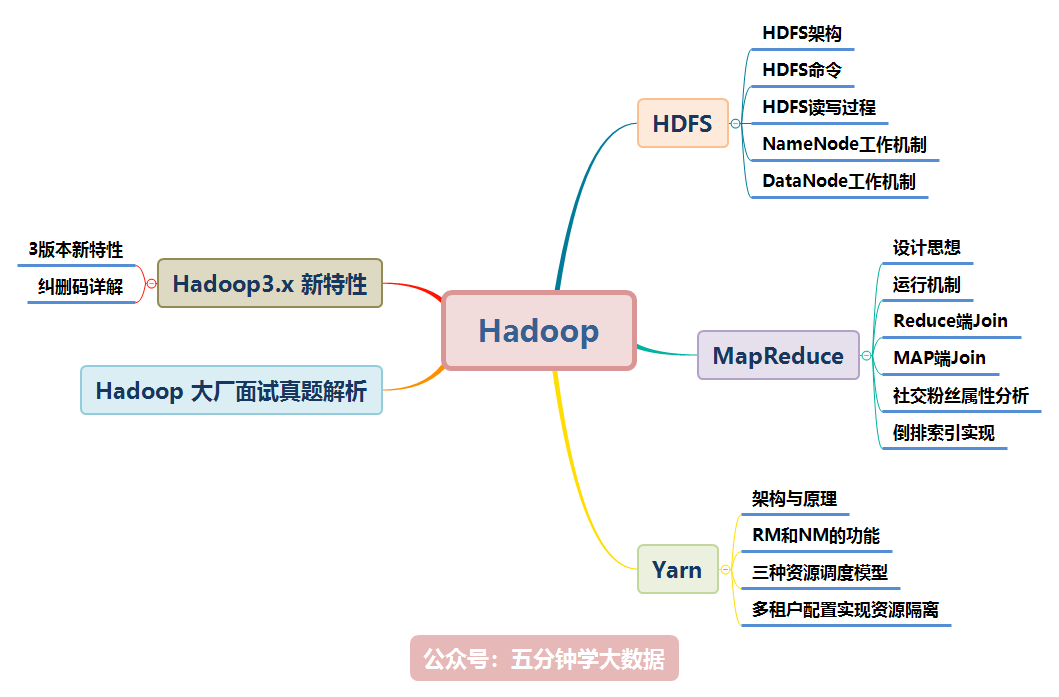
一、HDFS
二、MapReduce
三、Yarn
四、Hadoop3.x 新特性
五、Hadoop 大廠面試真題解析
Hadoop 涉及的知識點如下圖所示,本文將逐一講解:
本文檔參考了關於 Hadoop 的官網及其他眾多資料整理而成,為了整潔的排版及舒適的閱讀,對於模糊不清晰的圖片及黑白圖片進行重新繪製成了高清彩圖。
目前企業應用較多的是Hadoop2.x,所以本文是以Hadoop2.x為主,對於Hadoop3.x新增的內容會進行說明!
一、HDFS
1. HDFS概述
Hadoop 分散式系統框架中,首要的基礎功能就是文件系統,在 Hadoop 中使用 FileSystem 這個抽象類來表示我們的文件系統,這個抽象類下面有很多子實現類,究竟使用哪一種,需要看我們具體的實現類,在我們實際工作中,用到的最多的就是HDFS(分散式文件系統)以及LocalFileSystem(本地文件系統)了。
在現代的企業環境中,單機容量往往無法存儲大量數據,需要跨機器存儲。統一管理分布在集群上的文件系統稱為分散式文件系統。
HDFS(Hadoop Distributed File System)是 Hadoop 項目的一個子項目。是 Hadoop 的核心組件之一, Hadoop 非常適於存儲大型數據 (比如 TB 和 PB),其就是使用 HDFS 作為存儲系統. HDFS 使用多台電腦存儲文件,並且提供統一的訪問介面,像是訪問一個普通文件系統一樣使用分散式文件系統。
2. HDFS架構
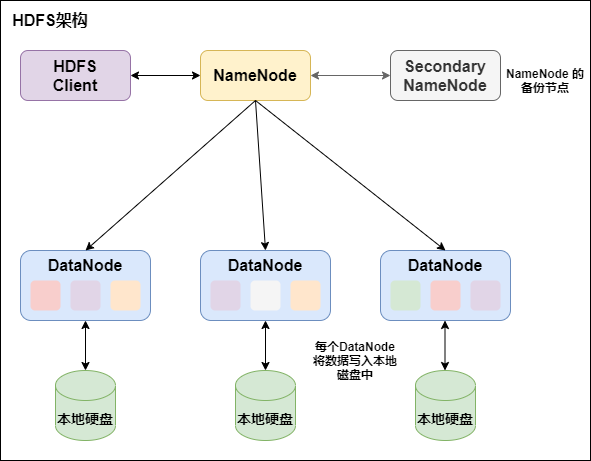
HDFS是一個主/從(Mater/Slave)體系結構,由三部分組成: NameNode 和 DataNode 以及 SecondaryNamenode:
-
NameNode 負責管理整個文件系統的元數據,以及每一個路徑(文件)所對應的數據塊資訊。
-
DataNode 負責管理用戶的文件數據塊,每一個數據塊都可以在多個 DataNode 上存儲多個副本,默認為3個。
-
Secondary NameNode 用來監控 HDFS 狀態的輔助後台程式,每隔一段時間獲取 HDFS 元數據的快照。最主要作用是輔助 NameNode 管理元數據資訊。
3. HDFS的特性
首先,它是一個文件系統,用於存儲文件,通過統一的命名空間目錄樹來定位文件;
其次,它是分散式的,由很多伺服器聯合起來實現其功能,集群中的伺服器有各自的角色。
1. master/slave 架構(主從架構)
HDFS 採用 master/slave 架構。一般一個 HDFS 集群是有一個 Namenode 和一定數目的 Datanode 組成。Namenode 是 HDFS 集群主節點,Datanode 是 HDFS 集群從節點,兩種角色各司其職,共同協調完成分散式的文件存儲服務。
2. 分塊存儲
HDFS 中的文件在物理上是分塊存儲(block)的,塊的大小可以通過配置參數來規定,默認大小在 hadoop2.x 版本中是 128M。
3. 名字空間(NameSpace)
HDFS 支援傳統的層次型文件組織結構。用戶或者應用程式可以創建目錄,然後將文件保存在這些目錄里。文件系統名字空間的層次結構和大多數現有的文件系統類似:用戶可以創建、刪除、移動或重命名文件。
Namenode 負責維護文件系統的名字空間,任何對文件系統名字空間或屬性的修改都將被 Namenode 記錄下來。
HDFS 會給客戶端提供一個統一的抽象目錄樹,客戶端通過路徑來訪問文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
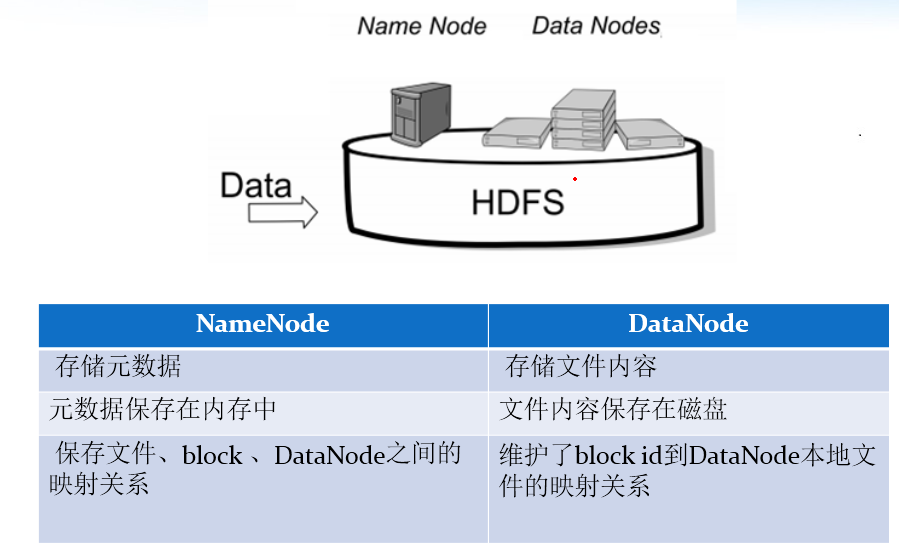
4. NameNode 元數據管理
我們把目錄結構及文件分塊位置資訊叫做元數據。NameNode 負責維護整個 HDFS 文件系統的目錄樹結構,以及每一個文件所對應的 block 塊資訊(block 的 id,及所在的 DataNode 伺服器)。
5. DataNode 數據存儲
文件的各個 block 的具體存儲管理由 DataNode 節點承擔。每一個 block 都可以在多個 DataNode 上。DataNode 需要定時向 NameNode 彙報自己持有的 block 資訊。 存儲多個副本(副本數量也可以通過參數設置 dfs.replication,默認是 3)
6. 副本機制
為了容錯,文件的所有 block 都會有副本。每個文件的 block 大小和副本係數都是可配置的。應用程式可以指定某個文件的副本數目。副本係數可以在文件創建的時候指定,也可以在之後改變。
7. 一次寫入,多次讀出
HDFS 是設計成適應一次寫入,多次讀出的場景,且不支援文件的修改。
正因為如此,HDFS 適合用來做大數據分析的底層存儲服務,並不適合用來做網盤等應用,因為修改不方便,延遲大,網路開銷大,成本太高。
4. HDFS 的命令行使用
如果沒有配置 hadoop 的環境變數,則在 hadoop 的安裝目錄下的bin目錄中執行以下命令,如已配置 hadoop 環境變數,則可在任意目錄下執行
help
格式: hdfs dfs -help 操作命令
作用: 查看某一個操作命令的參數資訊
ls
格式:hdfs dfs -ls URI
作用:類似於Linux的ls命令,顯示文件列表
lsr
格式 : hdfs dfs -lsr URI
作用 : 在整個目錄下遞歸執行ls, 與UNIX中的ls-R類似
mkdir
格式 : hdfs dfs -mkdir [-p] <paths>
作用 : 以<paths>中的URI作為參數,創建目錄。使用-p參數可以遞歸創建目錄
put
格式 : hdfs dfs -put <localsrc > ... <dst>
作用 : 將單個的源文件src或者多個源文件srcs從本地文件系統拷貝到目標文件系統中(<dst>對應的路徑)。也可以從標準輸入中讀取輸入,寫入目標文件系統中
hdfs dfs -put /rooot/bigdata.txt /dir1
moveFromLocal
格式: hdfs dfs -moveFromLocal <localsrc> <dst>
作用: 和put命令類似,但是源文件localsrc拷貝之後自身被刪除
hdfs dfs -moveFromLocal /root/bigdata.txt /
copyFromLocal
格式: hdfs dfs -copyFromLocal <localsrc> ... <dst>
作用: 從本地文件系統中拷貝文件到hdfs路徑去
appendToFile
格式: hdfs dfs -appendToFile <localsrc> ... <dst>
作用: 追加一個或者多個文件到hdfs指定文件中.也可以從命令行讀取輸入.
hdfs dfs -appendToFile a.xml b.xml /big.xml
moveToLocal
在 hadoop 2.6.4 版本測試還未未實現此方法
格式:hadoop dfs -moveToLocal [-crc] <src> <dst>
作用:將本地文件剪切到 HDFS
get
格式 hdfs dfs -get [-ignorecrc ] [-crc] <src> <localdst>
作用:將文件拷貝到本地文件系統。 CRC 校驗失敗的文件通過-ignorecrc選項拷貝。 文件和CRC校驗可以通過-CRC選項拷貝
hdfs dfs -get /bigdata.txt /export/servers
getmerge
格式: hdfs dfs -getmerge <src> <localdst>
作用: 合併下載多個文件,比如hdfs的目錄 /aaa/下有多個文件:log.1, log.2,log.3,...
copyToLocal
格式: hdfs dfs -copyToLocal <src> ... <localdst>
作用: 從hdfs拷貝到本地
mv
格式 : hdfs dfs -mv URI <dest>
作用: 將hdfs上的文件從原路徑移動到目標路徑(移動之後文件刪除),該命令不能跨文件系統
hdfs dfs -mv /dir1/bigdata.txt /dir2
rm
格式: hdfs dfs -rm [-r] 【-skipTrash】 URI 【URI 。。。】
作用: 刪除參數指定的文件,參數可以有多個。 此命令只刪除文件和非空目錄。
如果指定-skipTrash選項,那麼在回收站可用的情況下,該選項將跳過回收站而直接刪除文件;
否則,在回收站可用時,在HDFS Shell 中執行此命令,會將文件暫時放到回收站中。
hdfs dfs -rm -r /dir1
cp
格式: hdfs dfs -cp URI [URI ...] <dest>
作用: 將文件拷貝到目標路徑中。如果<dest> 為目錄的話,可以將多個文件拷貝到該目錄下。
-f
選項將覆蓋目標,如果它已經存在。
-p
選項將保留文件屬性(時間戳、所有權、許可、ACL、XAttr)。
hdfs dfs -cp /dir1/a.txt /dir2/bigdata.txt
cat
hdfs dfs -cat URI [uri ...]
作用:將參數所指示的文件內容輸出到stdout
hdfs dfs -cat /bigdata.txt
tail
格式: hdfs dfs -tail path
作用: 顯示一個文件的末尾
text
格式:hdfs dfs -text path
作用: 以字元形式列印一個文件的內容
chmod
格式:hdfs dfs -chmod [-R] URI[URI ...]
作用:改變文件許可權。如果使用 -R 選項,則對整個目錄有效遞歸執行。使用這一命令的用戶必須是文件的所屬用戶,或者超級用戶。
hdfs dfs -chmod -R 777 /bigdata.txt
chown
格式: hdfs dfs -chmod [-R] URI[URI ...]
作用: 改變文件的所屬用戶和用戶組。如果使用 -R 選項,則對整個目錄有效遞歸執行。使用這一命令的用戶必須是文件的所屬用戶,或者超級用戶。
hdfs dfs -chown -R hadoop:hadoop /bigdata.txt
df
格式: hdfs dfs -df -h path
作用: 統計文件系統的可用空間資訊
du
格式: hdfs dfs -du -s -h path
作用: 統計文件夾的大小資訊
count
格式: hdfs dfs -count path
作用: 統計一個指定目錄下的文件節點數量
setrep
格式: hdfs dfs -setrep num filePath
作用: 設置hdfs中文件的副本數量
注意: 即使設置的超過了datanode的數量,副本的數量也最多只能和datanode的數量是一致的
expunge (慎用)
格式: hdfs dfs -expunge
作用: 清空hdfs垃圾桶
5. hdfs的高級使用命令
5.1 HDFS文件限額配置
在多人共用HDFS的環境下,配置設置非常重要。特別是在 Hadoop 處理大量資料的環境,如果沒有配額管理,很容易把所有的空間用完造成別人無法存取。HDFS 的配額設定是針對目錄而不是針對帳號,可以讓每個帳號僅操作某一個目錄,然後對目錄設置配置。
HDFS 文件的限額配置允許我們以文件個數,或者文件大小來限制我們在某個目錄下上傳的文件數量或者文件內容總量,以便達到我們類似百度網盤網盤等限制每個用戶允許上傳的最大的文件的量。
hdfs dfs -count -q -h /user/root/dir1 #查看配額資訊
結果:

5.1.1 數量限額
hdfs dfs -mkdir -p /user/root/dir #創建hdfs文件夾
hdfs dfsadmin -setQuota 2 dir # 給該文件夾下面設置最多上傳兩個文件,發現只能上傳一個文件
hdfs dfsadmin -clrQuota /user/root/dir # 清除文件數量限制
5.1.2 空間大小限額
在設置空間配額時,設置的空間至少是 block_size * 3 大小
hdfs dfsadmin -setSpaceQuota 4k /user/root/dir # 限制空間大小4KB
hdfs dfs -put /root/a.txt /user/root/dir
生成任意大小文件的命令:
dd if=/dev/zero of=1.txt bs=1M count=2 #生成2M的文件
清除空間配額限制
hdfs dfsadmin -clrSpaceQuota /user/root/dir
5.2 HDFS 的安全模式
安全模式是hadoop的一種保護機制,用於保證集群中的數據塊的安全性。當集群啟動的時候,會首先進入安全模式。當系統處於安全模式時會檢查數據塊的完整性。
假設我們設置的副本數(即參數dfs.replication)是3,那麼在datanode上就應該有3個副本存在,假設只存在2個副本,那麼比例就是2/3=0.666。hdfs默認的副本率0.999。我們的副本率0.666明顯小於0.999,因此系統會自動的複製副本到其他dataNode,使得副本率不小於0.999。如果系統中有5個副本,超過我們設定的3個副本,那麼系統也會刪除多於的2個副本。
在安全模式狀態下,文件系統只接受讀數據請求,而不接受刪除、修改等變更請求。在,當整個系統達到安全標準時,HDFS自動離開安全模式。30s
安全模式操作命令
hdfs dfsadmin -safemode get #查看安全模式狀態
hdfs dfsadmin -safemode enter #進入安全模式
hdfs dfsadmin -safemode leave #離開安全模式
6. HDFS 的 block 塊和副本機制
HDFS 將所有的文件全部抽象成為 block 塊來進行存儲,不管文件大小,全部一視同仁都是以 block 塊的統一大小和形式進行存儲,方便我們的分散式文件系統對文件的管理。
所有的文件都是以 block 塊的方式存放在 hdfs 文件系統當中,在 Hadoop 1 版本當中,文件的 block 塊默認大小是 64M,Hadoop 2 版本當中,文件的 block 塊大小默認是128M,block塊的大小可以通過 hdfs-site.xml 當中的配置文件進行指定。
<property>
<name>dfs.block.size</name>
<value>塊大小 以位元組為單位</value> //只寫數值就可以
</property>
6.1 抽象為block塊的好處
-
- 一個文件有可能大於集群中任意一個磁碟
10T*3/128 = xxx塊 2T,2T,2T 文件方式存—–>多個block塊,這些block塊屬於一個文件
- 一個文件有可能大於集群中任意一個磁碟
-
- 使用塊抽象而不是文件可以簡化存儲子系統
-
- 塊非常適合用於數據備份進而提供數據容錯能力和可用性
6.2 塊快取
通常 DataNode 從磁碟中讀取塊,但對於訪問頻繁的文件,其對應的塊可能被顯示的快取在 DataNode 的記憶體中,以堆外塊快取的形式存在。默認情況下,一個塊僅快取在一個DataNode的記憶體中,當然可以針對每個文件配置DataNode的數量。作業調度器通過在快取塊的DataNode上運行任務,可以利用塊快取的優勢提高讀操作的性能。
例如:
連接(join)操作中使用的一個小的查詢表就是塊快取的一個很好的候選。 用戶或應用通過在快取池中增加一個cache directive來告訴namenode需要快取哪些文件及存多久。快取池(cache pool)是一個擁有管理快取許可權和資源使用的管理性分組。
例如:
一個文件 130M,會被切分成2個block塊,保存在兩個block塊裡面,實際佔用磁碟130M空間,而不是佔用256M的磁碟空間
6.3 hdfs的文件許可權驗證
hdfs的文件許可權機制與linux系統的文件許可權機制類似
r:read w:write x:execute
許可權x對於文件表示忽略,對於文件夾表示是否有許可權訪問其內容
如果linux系統用戶zhangsan使用hadoop命令創建一個文件,那麼這個文件在HDFS當中的owner就是zhangsan
HDFS文件許可權的目的,防止好人做錯事,而不是阻止壞人做壞事。HDFS相信你告訴我你是誰,你就是誰
6.4 hdfs的副本因子
為了保證block塊的安全性,也就是數據的安全性,在hadoop2當中,文件默認保存三個副本,我們可以更改副本數以提高數據的安全性
在hdfs-site.xml當中修改以下配置屬性,即可更改文件的副本數
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
7. HDFS 文件寫入過程(非常重要)
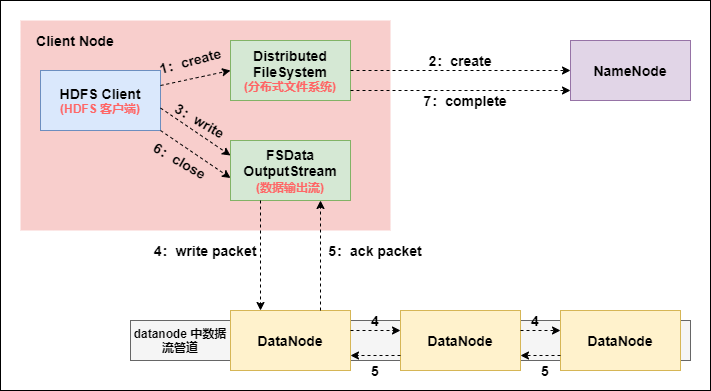
-
Client 發起文件上傳請求,通過 RPC 與 NameNode 建立通訊, NameNode 檢查目標文件是否已存在,父目錄是否存在,返回是否可以上傳;
-
Client 請求第一個 block 該傳輸到哪些 DataNode 伺服器上;
-
NameNode 根據配置文件中指定的備份數量及機架感知原理進行文件分配, 返回可用的 DataNode 的地址如:A, B, C;
Hadoop 在設計時考慮到數據的安全與高效, 數據文件默認在 HDFS 上存放三份, 存儲策略為本地一份,同機架內其它某一節點上一份,不同機架的某一節點上一份。
-
Client 請求 3 台 DataNode 中的一台 A 上傳數據(本質上是一個 RPC 調用,建立 pipeline ),A 收到請求會繼續調用 B,然後 B 調用 C,將整個 pipeline 建立完成, 後逐級返回 client;
-
Client 開始往 A 上傳第一個 block(先從磁碟讀取數據放到一個本地記憶體快取),以 packet 為單位(默認64K),A 收到一個 packet 就會傳給 B,B 傳給 C。A 每傳一個 packet 會放入一個應答隊列等待應答;
-
數據被分割成一個個 packet 數據包在 pipeline 上依次傳輸,在 pipeline 反方向上, 逐個發送 ack(命令正確應答),最終由 pipeline 中第一個 DataNode 節點 A 將 pipelineack 發送給 Client;
-
當一個 block 傳輸完成之後,Client 再次請求 NameNode 上傳第二個 block,重複步驟 2;
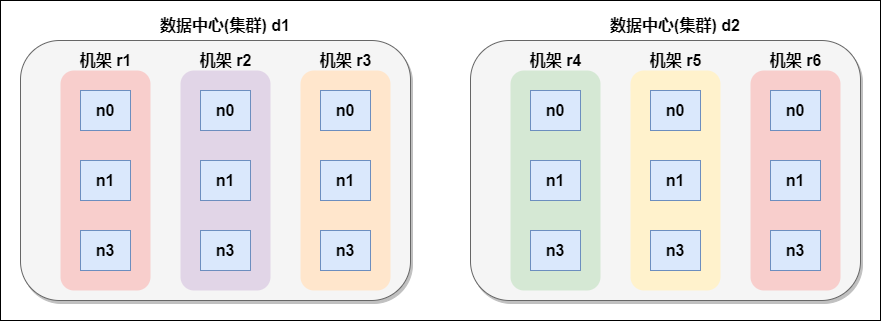
7.1 網路拓撲概念
在本地網路中,兩個節點被稱為「彼此近鄰」是什麼意思?在海量數據處理中,其主要限制因素是節點之間數據的傳輸速率——頻寬很稀缺。這裡的想法是將兩個節點間的頻寬作為距離的衡量標準。
節點距離:兩個節點到達最近的共同祖先的距離總和。
例如,假設有數據中心d1機架r1中的節點n1。該節點可以表示為/d1/r1/n1。利用這種標記,這裡給出四種距離描述。
Distance(/d1/r1/n1, /d1/r1/n1)=0(同一節點上的進程)
Distance(/d1/r1/n1, /d1/r1/n2)=2(同一機架上的不同節點)
Distance(/d1/r1/n1, /d1/r3/n2)=4(同一數據中心不同機架上的節點)
Distance(/d1/r1/n1, /d2/r4/n2)=6(不同數據中心的節點)
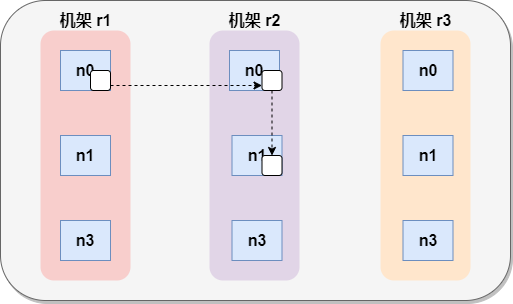
7.2 機架感知(副本節點選擇)
- 低版本Hadoop副本節點選擇
第一個副本在client所處的節點上。如果客戶端在集群外,隨機選一個。
第二個副本和第一個副本位於不相同機架的隨機節點上。
第三個副本和第二個副本位於相同機架,節點隨機。
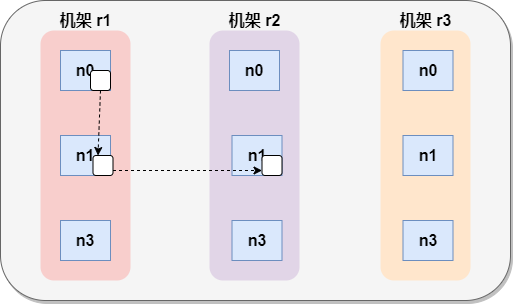
- Hadoop2.7.2 副本節點選擇
第一個副本在client所處的節點上。如果客戶端在集群外,隨機選一個。
第二個副本和第一個副本位於相同機架,隨機節點。
第三個副本位於不同機架,隨機節點。
8.HDFS 文件讀取過程(非常重要)
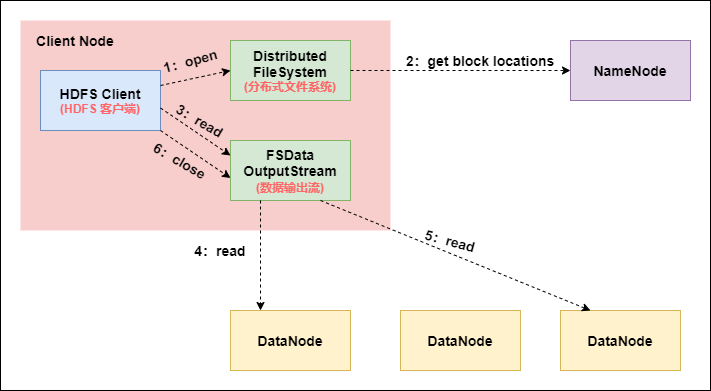
-
Client向NameNode發起RPC請求,來確定請求文件block所在的位置;
-
NameNode會視情況返迴文件的部分或者全部block列表,對於每個block,NameNode 都會返回含有該 block 副本的 DataNode 地址; 這些返回的 DN 地址,會按照集群拓撲結構得出 DataNode 與客戶端的距離,然後進行排序,排序兩個規則:網路拓撲結構中距離 Client 近的排靠前;心跳機制中超時彙報的 DN 狀態為 STALE,這樣的排靠後;
-
Client 選取排序靠前的 DataNode 來讀取 block,如果客戶端本身就是DataNode,那麼將從本地直接獲取數據(短路讀取特性);
-
底層上本質是建立 Socket Stream(FSDataInputStream),重複的調用父類 DataInputStream 的 read 方法,直到這個塊上的數據讀取完畢;
-
當讀完列表的 block 後,若文件讀取還沒有結束,客戶端會繼續向NameNode 獲取下一批的 block 列表;
-
讀取完一個 block 都會進行 checksum 驗證,如果讀取 DataNode 時出現錯誤,客戶端會通知 NameNode,然後再從下一個擁有該 block 副本的DataNode 繼續讀。
-
read 方法是並行的讀取 block 資訊,不是一塊一塊的讀取;NameNode 只是返回Client請求包含塊的DataNode地址,並不是返回請求塊的數據;
-
最終讀取來所有的 block 會合併成一個完整的最終文件。
從 HDFS 文件讀寫過程中,可以看出,HDFS 文件寫入時是串列寫入的,數據包先發送給節點A,然後節點A發送給B,B在給C;而HDFS文件讀取是並行的, 客戶端 Client 直接並行讀取block所在的節點。
9. NameNode 工作機制以及元數據管理(重要)
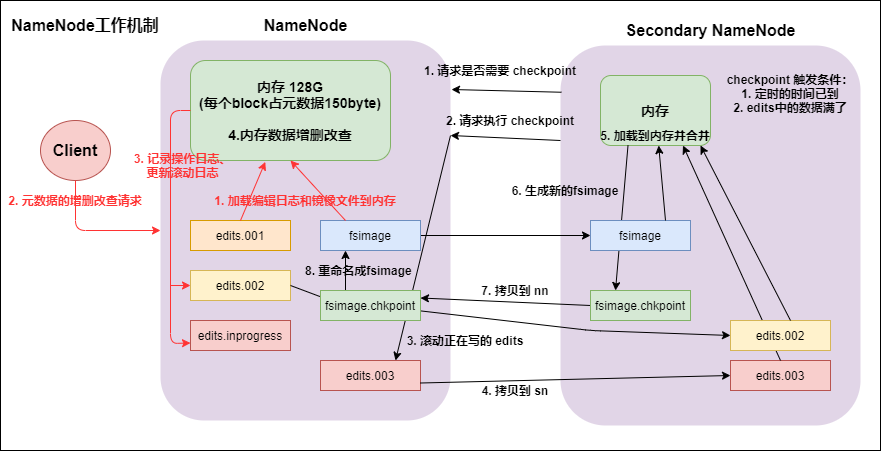
9.1 namenode 與 datanode 啟動
- namenode工作機制
- 第一次啟動namenode格式化後,創建fsimage和edits文件。如果不是第一次啟動,直接載入編輯日誌和鏡像文件到記憶體。
- 客戶端對元數據進行增刪改的請求。
- namenode記錄操作日誌,更新滾動日誌。
- namenode在記憶體中對數據進行增刪改查。
- secondary namenode
- secondary namenode詢問 namenode 是否需要 checkpoint。直接帶回 namenode 是否檢查結果。
- secondary namenode 請求執行 checkpoint。
- namenode 滾動正在寫的edits日誌。
- 將滾動前的編輯日誌和鏡像文件拷貝到 secondary namenode。
- secondary namenode 載入編輯日誌和鏡像文件到記憶體,併合並。
- 生成新的鏡像文件 fsimage.chkpoint。
- 拷貝 fsimage.chkpoint 到 namenode。
- namenode將 fsimage.chkpoint 重新命名成fsimage。
9.2 FSImage與edits詳解
所有的元數據資訊都保存在了FsImage與Eidts文件當中,這兩個文件就記錄了所有的數據的元數據資訊,元數據資訊的保存目錄配置在了 hdfs-site.xml 當中
<!--fsimage文件存儲的路徑-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas</value>
</property>
<!-- edits文件存儲的路徑 -->
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///opt/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits</value>
</property>
客戶端對hdfs進行寫文件時會首先被記錄在edits文件中。
edits修改時元數據也會更新。
每次hdfs更新時edits先更新後客戶端才會看到最新資訊。
fsimage:是namenode中關於元數據的鏡像,一般稱為檢查點。
一般開始時對namenode的操作都放在edits中,為什麼不放在fsimage中呢?
因為fsimage是namenode的完整的鏡像,內容很大,如果每次都載入到記憶體的話生成樹狀拓撲結構,這是非常耗記憶體和CPU。
fsimage內容包含了namenode管理下的所有datanode中文件及文件block及block所在的datanode的元數據資訊。隨著edits內容增大,就需要在一定時間點和fsimage合併。
9.3 FSimage文件當中的文件資訊查看
- 使用命令 hdfs oiv
cd /opt/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas/current
hdfs oiv -i fsimage_0000000000000000112 -p XML -o hello.xml
9.4 edits當中的文件資訊查看
- 查看命令 hdfs oev
cd /opt/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits
hdfs oev -i edits_0000000000000000112-0000000000000000113 -o myedit.xml -p XML
9.5 secondarynameNode如何輔助管理FSImage與Edits文件
- secnonaryNN通知NameNode切換editlog。
- secondaryNN從NameNode中獲得FSImage和editlog(通過http方式)。
- secondaryNN將FSImage載入記憶體,然後開始合併editlog,合併之後成為新的fsimage。
- secondaryNN將新的fsimage發回給NameNode。
- NameNode用新的fsimage替換舊的fsimage。
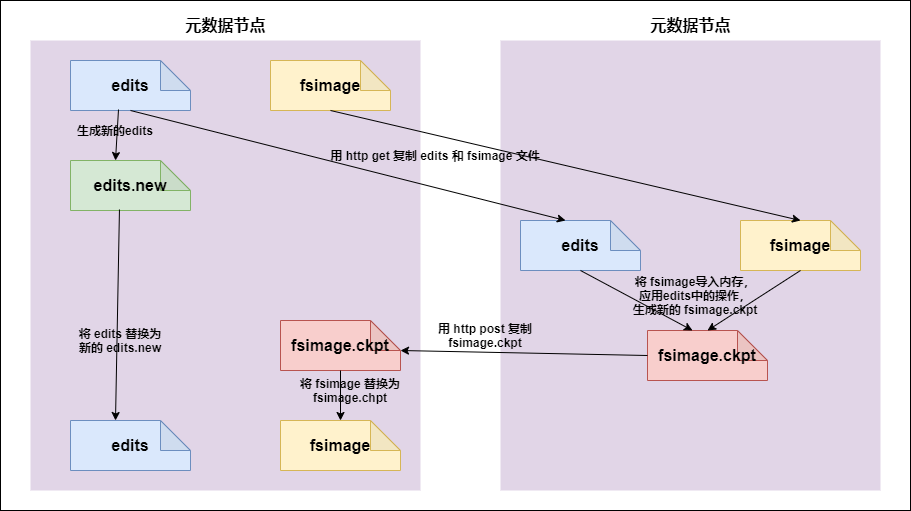
完成合併的是 secondarynamenode,會請求namenode停止使用edits,暫時將新寫操作放入一個新的文件中(edits.new)。
secondarynamenode從namenode中通過http get獲得edits,因為要和fsimage合併,所以也是通過http get 的方式把fsimage載入到記憶體,然後逐一執行具體對文件系統的操作,與fsimage合併,生成新的fsimage,然後把fsimage發送給namenode,通過http post的方式。
namenode從secondarynamenode獲得了fsimage後會把原有的fsimage替換為新的fsimage,把edits.new變成edits。同時會更新fsimage。
hadoop進入安全模式時需要管理員使用dfsadmin的save namespace來創建新的檢查點。
secondarynamenode在合併edits和fsimage時需要消耗的記憶體和namenode差不多,所以一般把namenode和secondarynamenode放在不同的機器上。
fsimage與edits的合併時機取決於兩個參數,第一個參數是默認1小時fsimage與edits合併一次。
- 第一個參數:時間達到一個小時fsimage與edits就會進行合併
dfs.namenode.checkpoint.period 3600
- 第二個參數:hdfs操作達到1000000次也會進行合併
dfs.namenode.checkpoint.txns 1000000
- 第三個參數:每隔多長時間檢查一次hdfs的操作次數
dfs.namenode.checkpoint.check.period 60
9.6 namenode元數據資訊多目錄配置
為了保證元數據的安全性,我們一般都是先確定好我們的磁碟掛載目錄,將元數據的磁碟做RAID1
namenode的本地目錄可以配置成多個,且每個目錄存放內容相同,增加了可靠性。
-
具體配置方案:
hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas</value>
</property>
9.7 namenode故障恢復
在我們的secondaryNamenode對namenode當中的fsimage和edits進行合併的時候,每次都會先將namenode的fsimage與edits文件拷貝一份過來,所以fsimage與edits文件在secondarNamendoe當中也會保存有一份,如果namenode的fsimage與edits文件損壞,那麼我們可以將secondaryNamenode當中的fsimage與edits拷貝過去給namenode繼續使用,只不過有可能會丟失一部分數據。這裡涉及到幾個配置選項
- namenode保存fsimage的配置路徑
<!-- namenode元數據存儲路徑,實際工作當中一般使用SSD固態硬碟,並使用多個固態硬碟隔開,冗餘元數據 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas</value>
</property>
- namenode保存edits文件的配置路徑
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits</value>
</property>
- secondaryNamenode保存fsimage文件的配置路徑
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/snn/name</value>
</property>
- secondaryNamenode保存edits文件的配置路徑
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/snn/edits</value>
</property>
接下來我們來模擬namenode的故障恢復功能
- 殺死namenode進程: 使用jps查看namenode的進程號 , kill -9 直接殺死。
- 刪除namenode的fsimage文件和edits文件。
根據上述配置, 找到namenode放置fsimage和edits路徑. 直接全部rm -rf 刪除。
- 拷貝secondaryNamenode的fsimage與edits文件到namenode的fsimage與edits文件夾下面去。
根據上述配置, 找到secondaryNamenode的fsimage和edits路徑, 將內容 使用cp -r 全部複製到namenode對應的目錄下即可。
- 重新啟動namenode, 觀察數據是否存在。
10. datanode工作機制以及數據存儲
- datanode工作機制
-
一個數據塊在datanode上以文件形式存儲在磁碟上,包括兩個文件,一個是數據本身,一個是元數據包括數據塊的長度,塊數據的校驗和,以及時間戳。
-
DataNode啟動後向namenode註冊,通過後,周期性(1小時)的向namenode上報所有的塊資訊。(dfs.blockreport.intervalMsec)。
-
心跳是每3秒一次,心跳返回結果帶有namenode給該datanode的命令如複製塊數據到另一台機器,或刪除某個數據塊。如果超過10分鐘沒有收到某個datanode的心跳,則認為該節點不可用。
-
集群運行中可以安全加入和退出一些機器。
- 數據完整性
- 當DataNode讀取block的時候,它會計算checksum。
- 如果計算後的checksum,與block創建時值不一樣,說明block已經損壞。
- client讀取其他DataNode上的block。
- datanode在其文件創建後周期驗證checksum。
- 掉線時限參數設置
datanode進程死亡或者網路故障造成datanode無法與namenode通訊,namenode不會立即把該節點判定為死亡,要經過一段時間,這段時間暫稱作超時時長。HDFS默認的超時時長為10分鐘+30秒。如果定義超時時間為timeout,則超時時長的計算公式為:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。
而默認的dfs.namenode.heartbeat.recheck-interval 大小為5分鐘,dfs.heartbeat.interval默認為3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的單位為毫秒,dfs.heartbeat.interval的單位為秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval </name>
<value>3</value>
</property>
-
DataNode的目錄結構
和namenode不同的是,datanode的存儲目錄是初始階段自動創建的,不需要額外格式化。
在/opt/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas/current這個目錄下查看版本號
cat VERSION
#Thu Mar 14 07:58:46 CST 2019
storageID=DS-47bcc6d5-c9b7-4c88-9cc8-6154b8a2bf39
clusterID=CID-dac2e9fa-65d2-4963-a7b5-bb4d0280d3f4
cTime=0
datanodeUuid=c44514a0-9ed6-4642-b3a8-5af79f03d7a4
storageType=DATA_NODE
layoutVersion=-56
具體解釋:
storageID:存儲id號。
clusterID集群id,全局唯一。
cTime屬性標記了datanode存儲系統的創建時間,對於剛剛格式化的存儲系統,這個屬性為0;但是在文件系統升級之後,該值會更新到新的時間戳。
datanodeUuid:datanode的唯一識別碼。
storageType:存儲類型。
layoutVersion是一個負整數。通常只有HDFS增加新特性時才會更新這個版本號。
- datanode多目錄配置
datanode也可以配置成多個目錄,每個目錄存儲的數據不一樣。即:數據不是副本。具體配置如下:
– 只需要在value中使用逗號分隔出多個存儲目錄即可
cd /opt/hadoop-2.6.0-cdh5.14.0/etc/hadoop
<!-- 定義dataNode數據存儲的節點位置,實際工作中,一般先確定磁碟的掛載目錄,然後多個目錄用,進行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas</value>
</property>
10.1 服役新數據節點
需求說明:
隨著公司業務的增長,數據量越來越大,原有的數據節點的容量已經不能滿足存儲數據的需求,需要在原有集群基礎上動態添加新的數據節點。
10.1.1 環境準備
- 複製一台新的虛擬機出來
將我們純凈的虛擬機複製一台出來,作為我們新的節點
- 修改mac地址以及IP地址
修改mac地址命令
vim /etc/udev/rules.d/70-persistent-net.rules
修改ip地址命令
vim /etc/sysconfig/network-scripts/ifcfg-eth0
- 關閉防火牆,關閉selinux
關閉防火牆
service iptables stop
關閉selinux
vim /etc/selinux/config
- 更改主機名
更改主機名命令,將node04主機名更改為node04.hadoop.com
vim /etc/sysconfig/network
- 四台機器更改主機名與IP地址映射
四台機器都要添加hosts文件
vim /etc/hosts
192.168.52.100 node01.hadoop.com node01
192.168.52.110 node02.hadoop.com node02
192.168.52.120 node03.hadoop.com node03
192.168.52.130 node04.hadoop.com node04
- node04伺服器關機重啟
node04執行以下命令關機重啟
reboot -h now
- node04安裝jdk
node04統一兩個路徑
mkdir -p /export/softwares/
mkdir -p /export/servers/
然後解壓jdk安裝包,配置環境變數
- 解壓hadoop安裝包
在node04伺服器上面解壓hadoop安裝包到/export/servers , node01執行以下命令將hadoop安裝包拷貝到node04伺服器
cd /export/softwares/
scp hadoop-2.6.0-cdh5.14.0-自己編譯後的版本.tar.gz node04:$PWD
node04解壓安裝包
tar -zxf hadoop-2.6.0-cdh5.14.0-自己編譯後的版本.tar.gz -C /export/servers/
- 將node01關於hadoop的配置文件全部拷貝到node04
node01執行以下命令,將hadoop的配置文件全部拷貝到node04伺服器上面
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/
scp ./* node04:$PWD
10.1.2 服役新節點具體步驟
- 創建dfs.hosts文件
在node01也就是namenode所在的機器的/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop目錄下創建dfs.hosts文件
[root@node01 hadoop]# cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
[root@node01 hadoop]# touch dfs.hosts
[root@node01 hadoop]# vim dfs.hosts
添加如下主機名稱(包含新服役的節點)
node01
node02
node03
node04
- node01編輯hdfs-site.xml添加以下配置
在namenode的hdfs-site.xml配置文件中增加dfs.hosts屬性
node01執行以下命令 :
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
# 添加一下內容
<property>
<name>dfs.hosts</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts</value>
</property>
<!--動態上下線配置: 如果配置文件中有, 就不需要配置-->
<property>
<name>dfs.hosts</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/accept_host</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/deny_host</value>
</property>
- 刷新namenode
- node01執行以下命令刷新namenode
[root@node01 hadoop]# hdfs dfsadmin -refreshNodes
Refresh nodes successful
- 更新resourceManager節點
- node01執行以下命令刷新resourceManager
[root@node01 hadoop]# yarn rmadmin -refreshNodes
19/03/16 11:19:47 INFO client.RMProxy: Connecting to ResourceManager at node01/192.168.52.100:8033
- namenode的slaves文件增加新服務節點主機名稱
node01編輯slaves文件,並添加新增節點的主機,更改完後,slaves文件不需要分發到其他機器上面去
node01執行以下命令編輯slaves文件 :
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim slaves
添加一下內容:
node01
node02
node03
node04
- 單獨啟動新增節點
node04伺服器執行以下命令,啟動datanode和nodemanager :
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
sbin/hadoop-daemon.sh start datanode
sbin/yarn-daemon.sh start nodemanager
- 使用負載均衡命令,讓數據均勻負載所有機器
node01執行以下命令 :
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
sbin/start-balancer.sh
10.2 退役舊數據
- 創建dfs.hosts.exclude配置文件
在namenod所在伺服器的/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop目錄下創建dfs.hosts.exclude文件,並添加需要退役的主機名稱
node01執行以下命令 :
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
touch dfs.hosts.exclude
vim dfs.hosts.exclude
添加以下內容:
node04.hadoop.com
特別注意:該文件當中一定要寫真正的主機名或者ip地址都行,不能寫node04
- 編輯namenode所在機器的hdfs-site.xml
編輯namenode所在的機器的hdfs-site.xml配置文件,添加以下配置
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
#添加一下內容:
<property>
<name>dfs.hosts.exclude</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts.exclude</value>
</property>
- 刷新namenode,刷新resourceManager
在namenode所在的機器執行以下命令,刷新namenode,刷新resourceManager :
hdfs dfsadmin -refreshNodes
yarn rmadmin -refreshNodes
- 節點退役完成,停止該節點進程
等待退役節點狀態為decommissioned(所有塊已經複製完成),停止該節點及節點資源管理器。注意:如果副本數是3,服役的節點小於等於3,是不能退役成功的,需要修改副本數後才能退役。
node04執行以下命令,停止該節點進程 :
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/hadoop-daemon.sh stop datanode
sbin/yarn-daemon.sh stop nodemanager
- 從include文件中刪除退役節點
namenode所在節點也就是node01執行以下命令刪除退役節點 :
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim dfs.hosts
刪除後的內容: 刪除了node04
node01
node02
node03
- node01執行一下命令刷新namenode,刷新resourceManager
hdfs dfsadmin -refreshNodes
yarn rmadmin -refreshNodes
- 從namenode的slave文件中刪除退役節點
namenode所在機器也就是node01執行以下命令從slaves文件中刪除退役節點 :
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim slaves
刪除後的內容: 刪除了 node04
node01
node02
node03
- 如果數據負載不均衡,執行以下命令進行均衡負載
node01執行以下命令進行均衡負載
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
sbin/start-balancer.sh
11. block塊手動拼接成為完整數據
所有的數據都是以一個個的block塊存儲的,只要我們能夠將文件的所有block塊全部找出來,拼接到一起,又會成為一個完整的文件,接下來我們就來通過命令將文件進行拼接:
- 上傳一個大於128M的文件到hdfs上面去
我們選擇一個大於128M的文件上傳到hdfs上面去,只有一個大於128M的文件才會有多個block塊。
這裡我們選擇將我們的jdk安裝包上傳到hdfs上面去。
node01執行以下命令上傳jdk安裝包
cd /export/softwares/
hdfs dfs -put jdk-8u141-linux-x64.tar.gz /
- web瀏覽器介面查看jdk的兩個block塊id
這裡我們看到兩個block塊id分別為
1073742699和1073742700
那麼我們就可以通過blockid將我們兩個block塊進行手動拼接了。
- 根據我們的配置文件找到block塊所在的路徑
根據我們hdfs-site.xml的配置,找到datanode所在的路徑
<!-- 定義dataNode數據存儲的節點位置,實際工作中,一般先確定磁碟的掛載目錄,然後多個目錄用,進行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas</value>
</property>
進入到以下路徑 : 此基礎路徑為 上述配置中value的路徑
cd /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas/current/BP-557466926-192.168.52.100-1549868683602/current/finalized/subdir0/subdir3
- 執行block塊的拼接
將不同的各個block塊按照順序進行拼接起來,成為一個完整的文件
cat blk_1073742699 >> jdk8u141.tar.gz
cat blk_1073742700 >> jdk8u141.tar.gz
移動我們的jdk到/export路徑,然後進行解壓
mv jdk8u141.tar.gz /export/
cd /export/
tar -zxf jdk8u141.tar.gz
正常解壓,沒有問題,說明我們的程式按照block塊存儲沒有問題
12. HDFS其他重要功能
1. 多個集群之間的數據拷貝
在我們實際工作當中,極有可能會遇到將測試集群的數據拷貝到生產環境集群,或者將生產環境集群的數據拷貝到測試集群,那麼就需要我們在多個集群之間進行數據的遠程拷貝,hadoop自帶也有命令可以幫我們實現這個功能
- 本地文件拷貝scp
cd /export/softwares/
scp -r jdk-8u141-linux-x64.tar.gz root@node02:/export/
- 集群之間的數據拷貝distcp
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
bin/hadoop distcp hdfs://node01:8020/jdk-8u141-linux-x64.tar.gz hdfs://cluster2:8020/
2. hadoop歸檔文件archive
每個文件均按塊存儲,每個塊的元數據存儲在namenode的記憶體中,因此hadoop存儲小文件會非常低效。因為大量的小文件會耗盡namenode中的大部分記憶體。但注意,存儲小文件所需要的磁碟容量和存儲這些文件原始內容所需要的磁碟空間相比也不會增多。例如,一個1MB的文件以大小為128MB的塊存儲,使用的是1MB的磁碟空間,而不是128MB。
Hadoop存檔文件或HAR文件,是一個更高效的文件存檔工具,它將文件存入HDFS塊,在減少namenode記憶體使用的同時,允許對文件進行透明的訪問。具體說來,Hadoop存檔文件可以用作MapReduce的輸入。
創建歸檔文件
-
第一步:創建歸檔文件
注意:歸檔文件一定要保證yarn集群啟動
cd /export/servers/hadoop-2.6.0-cdh5.14.0
bin/hadoop archive -archiveName myhar.har -p /user/root /user
- 第二步:查看歸檔文件內容
hdfs dfs -lsr /user/myhar.har
hdfs dfs -lsr har:///user/myhar.har
- 第三步:解壓歸檔文件
hdfs dfs -mkdir -p /user/har
hdfs dfs -cp har:///user/myhar.har/* /user/har/
3. hdfs快照snapShot管理
快照顧名思義,就是相當於對我們的hdfs文件系統做一個備份,我們可以通過快照對我們指定的文件夾設置備份,但是添加快照之後,並不會立即複製所有文件,而是指向同一個文件。當寫入發生時,才會產生新文件
- 快照使用基本語法
1、 開啟指定目錄的快照功能
hdfs dfsadmin -allowSnapshot 路徑
2、禁用指定目錄的快照功能(默認就是禁用狀態)
hdfs dfsadmin -disallowSnapshot 路徑
3、給某個路徑創建快照snapshot
hdfs dfs -createSnapshot 路徑
4、指定快照名稱進行創建快照snapshot
hdfs dfs -createSanpshot 路徑 名稱
5、給快照重新命名
hdfs dfs -renameSnapshot 路徑 舊名稱 新名稱
6、列出當前用戶所有可快照目錄
hdfs lsSnapshottableDir
7、比較兩個快照的目錄不同之處
hdfs snapshotDiff 路徑1 路徑2
8、刪除快照snapshot
hdfs dfs -deleteSnapshot <path> <snapshotName>
- 快照操作實際案例
1、開啟與禁用指定目錄的快照
[root@node01 hadoop-2.6.0-cdh5.14.0]# hdfs dfsadmin -allowSnapshot /user
Allowing snaphot on /user succeeded
[root@node01 hadoop-2.6.0-cdh5.14.0]# hdfs dfsadmin -disallowSnapshot /user
Disallowing snaphot on /user succeeded
2、對指定目錄創建快照
注意:創建快照之前,先要允許該目錄創建快照
[root@node01 hadoop-2.6.0-cdh5.14.0]# hdfs dfsadmin -allowSnapshot /user
Allowing snaphot on /user succeeded
[root@node01 hadoop-2.6.0-cdh5.14.0]# hdfs dfs -createSnapshot /user
Created snapshot /user/.snapshot/s20190317-210906.549
通過web瀏覽器訪問快照
//node01:50070/explorer.html#/user/.snapshot/s20190317-210906.549
3、指定名稱創建快照
[root@node01 hadoop-2.6.0-cdh5.14.0]# hdfs dfs -createSnapshot /user mysnap1
Created snapshot /user/.snapshot/mysnap1
4、重命名快照
hdfs dfs -renameSnapshot /user mysnap1 mysnap2
5、列出當前用戶所有可以快照的目錄
hdfs lsSnapshottableDir
6、比較兩個快照不同之處
hdfs dfs -createSnapshot /user snap1
hdfs dfs -createSnapshot /user snap2
hdfs snapshotDiff snap1 snap2
7、刪除快照
hdfs dfs -deleteSnapshot /user snap1
4. hdfs回收站
任何一個文件系統,基本上都會有垃圾桶機制,也就是刪除的文件,不會直接徹底清掉,我們一把都是將文件放置到垃圾桶當中去,過一段時間之後,自動清空垃圾桶當中的文件,這樣對於文件的安全刪除比較有保證,避免我們一些誤操作,導致誤刪除文件或者數據
- 回收站配置兩個參數
默認值fs.trash.interval=0,0表示禁用回收站,可以設置刪除文件的存活時間。
默認值fs.trash.checkpoint.interval=0,檢查回收站的間隔時間。
要求fs.trash.checkpoint.interval<=fs.trash.interval。
- 啟用回收站
修改所有伺服器的core-site.xml配置文件
<!-- 開啟hdfs的垃圾桶機制,刪除掉的數據可以從垃圾桶中回收,單位分鐘 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
- 查看回收站
回收站在集群的 /user/root/.Trash/ 這個路徑下
- 通過javaAPI刪除的數據,不會進入回收站,需要調用moveToTrash()才會進入回收站
//使用回收站的方式: 刪除數據
@Test
public void deleteFile() throws Exception{
//1. 獲取FileSystem對象
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), configuration, "root");
//2. 執行刪除操作
// fileSystem.delete(); 這種操作會直接將數據刪除, 不會進入垃圾桶
Trash trash = new Trash(fileSystem,configuration);
boolean flag = trash.isEnabled(); // 是否已經開啟了垃圾桶機制
System.out.println(flag);
trash.moveToTrash(new Path("/quota"));
//3. 釋放資源
fileSystem.close();
}
- 恢復回收站數據
hdfs dfs -mv trashFileDir hdfsdir
trashFileDir :回收站的文件路徑
hdfsdir :將文件移動到hdfs的哪個路徑下
- 清空回收站
hdfs dfs -expunge

