分散式事務(一)—分散式事務的概念
現今互聯網界,分散式系統和微服務架構盛行。一個簡單操作,在服務端非常可能是由多個服務和資料庫實例協同完成的。在互聯網金融等一致性要求較高的場景下,多個獨立操作之間的一致性問題顯得格外棘手。隨著業務的快速發展、業務複雜度越來越高,幾乎每個公司的系統都會從單體走向分散式,特別是轉向微服務架構,隨之而來就必然遇到分散式事務這個難題。本文會介紹分散式事務的一些相關概念。
分散式事務的概念
資料庫事務
資料庫事務的目的
資料庫事務(簡稱:事務)是資料庫管理系統執行過程中的一個邏輯單位,由一個有限的資料庫操作序列構成。資料庫事務通常包含了一個序列的對資料庫的讀/寫操作。包含有以下兩個目的:
- 為資料庫操作序列提供了一個從失敗中恢復到正常狀態的方法,同時提供了資料庫即使在異常狀態下仍能保持一致性的方法。
- 當多個應用程式在並發訪問資料庫時,可以在這些應用程式之間提供一個隔離方法,以防止彼此的操作互相干擾。
當事務被提交給了資料庫管理系統(DBMS),則DBMS需要確保該事務中的所有操作都成功完成且其結果被永久保存在資料庫中,如果事務中有的操作沒有成功完成,則事務中的所有操作都需要回滾,回到事務執行前的狀態;同時,該事務對資料庫或者其他事務的執行無影響,所有的事務都好像在獨立的運行。
ACID特性
資料庫事務擁有以下四個特性,習慣上被稱之為ACID特性:
- 原子性(Atomicity):事務中的所有操作作為一個整體像原子一樣不可分割,要麼全部成功,要麼全部失敗。
- 一致性(Consistency):事務的執行結果必須使資料庫從一個一致性狀態到另一個一致性狀態。一致性狀態是指:1.系統的狀態滿足數據的完整性約束(主碼,參照完整性,check約束等) 2.系統的狀態反應資料庫本應描述的現實世界的真實狀態,比如轉賬前後兩個賬戶的金額總和應該保持不變。
- 隔離性(Isolation):並發執行的事務不會相互影響,其對資料庫的影響和它們串列執行時一樣。比如多個用戶同時往一個賬戶轉賬,最後賬戶的結果應該和他們按先後次序轉賬的結果一樣。
- 持久性(Durability):事務一旦提交,其對資料庫的更新就是持久的。任何事務或系統故障都不會導致數據丟失。
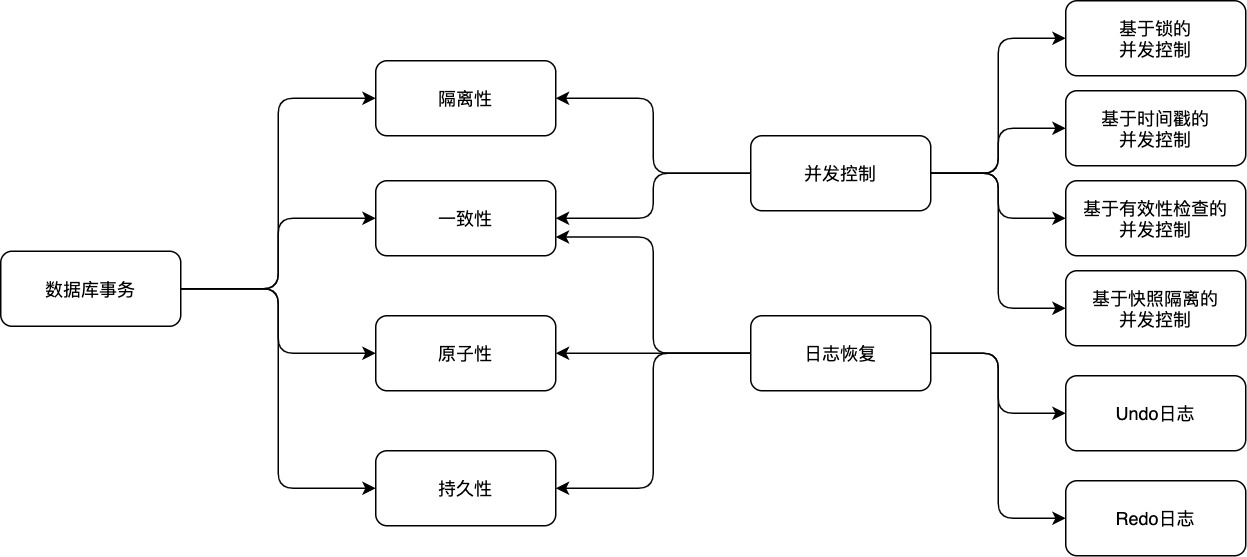
資料庫的並發控制
影響資料庫ACID實現的因素有兩個:並發和系統故障,相應地,資料庫系統通過並發控制技術和日誌恢復技術來實現資料庫的ACID特性。
並發控制技術是實現事務隔離性以及不同隔離級別的關鍵,實現方式有很多,按照其對可能衝突的操作採取的不同策略可以分為樂觀並發控制和悲觀並發控制兩大類。
- 樂觀並發控制:對於並發執行可能衝突的操作,假定其不會真的衝突,允許並發執行,直到真正發生衝突時才去解決衝突,比如讓事務回滾。
- 悲觀並發控制:對於並發執行可能衝突的操作,假定其必定發生衝突,通過讓事務等待(鎖)或者中止(時間戳排序)的方式使並行的操作串列執行。
其實現方式有多種: 基於封鎖的並發控制、基於時間戳的並發控制、基於有效性檢查的並發控制、基於快照隔離的並發控制.
資料庫日誌
資料庫運行過程中可能會出現故障,這些故障包括事務故障和系統故障兩大類
- 事務故障:比如非法輸入,系統出現死鎖,導致事務無法繼續執行。
- 系統故障:比如由於軟體漏洞或硬體錯誤導致系統崩潰或中止。
這些故障可能會對事務和資料庫狀態造成破壞,因而必須提供一種技術來對各種故障進行恢復,保證資料庫一致性,事務的原子性以及持久性。資料庫通常以日誌的方式記錄資料庫的操作從而在故障時進行恢復,因而可以稱之為日誌恢復技術。資料庫日誌包含undo和redo日誌。
分散式事務場景
當我們的單個資料庫的性能產生瓶頸的時候,我們可能會對資料庫進行分區,這裡所說的分區指的是物理分區,分區之後可能不同的庫就處於不同的伺服器上了,這個時候單個資料庫的ACID已經不能適應這種情況了,而在這種ACID的集群環境下,再想保證集群的ACID幾乎是很難達到,或者即使能達到那麼效率和性能會大幅下降,最為關鍵的是再很難擴展新的分區了,這個時候如果再追求集群的ACID會導致我們的系統變得很差,這時我們就需要引入一個新的理論原則來適應這種集群的情況,就是CAP原則或者叫CAP定理?
CAP定理
CAP定理是由加州大學伯克利分校Eric Brewer教授提出來的,他指出WEB服務無法同時滿足一下3個屬性:
- 一致性(Consistency):(等同於所有節點訪問同一份最新的數據副本)
- 可用性(Availability):(每次請求都能獲取到非錯的響應——但是不保證獲取的數據為最新數據)
- 分區容錯性(Partition tolerance):(以實際效果而言,分區相當於對通訊的時限要求。系統如果不能在時限內達成數據一致性,就意味著發生了分區的情況,必須就當前操作在C和A之間做出選擇。)
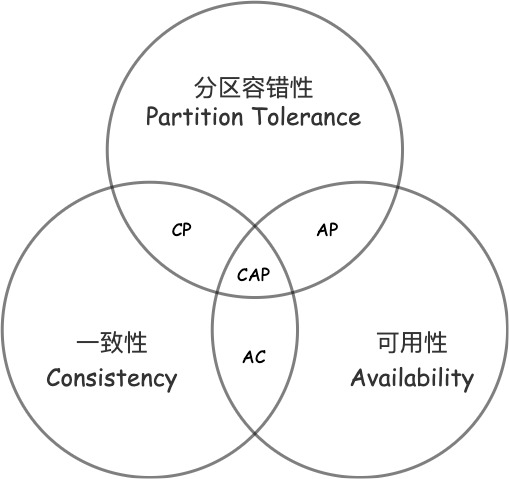
根據定理,分散式系統只能滿足三項中的兩項而不可能滿足全部三項。理解CAP理論的最簡單方式是想像兩個節點分處分區兩側。允許至少一個節點更新狀態會導致數據不一致,即喪失了C性質。如果為了保證數據一致性,將分區一側的節點設置為不可用,那麼又喪失了A性質。除非兩個節點可以互相通訊,才能既保證C又保證A,這又會導致喪失P性質。
因此在進行分散式架構設計時,必須做出取捨。當前一般是通過分散式快取中各節點的最終一致性來提高系統的性能,通過使用多節點之間的數據非同步複製技術來實現集群化的數據一致性。通常使用類似 memcached 之類的 NOSQL 作為實現手段。雖然 memcached 也可以是分散式集群環境的,但是對於一份數據來說,它總是存儲在某一台 memcached 伺服器上。如果發生網路故障或是伺服器死機,則存儲在這台伺服器上的所有數據都將不可訪問。由於數據是存儲在記憶體中的,重啟伺服器,將導致數據全部丟失。當然也可以自己實現一套機制,用來在分散式 memcached 之間進行數據的同步和持久化,但是實現難度是非常大的。
分區容錯性(Partition tolerance)
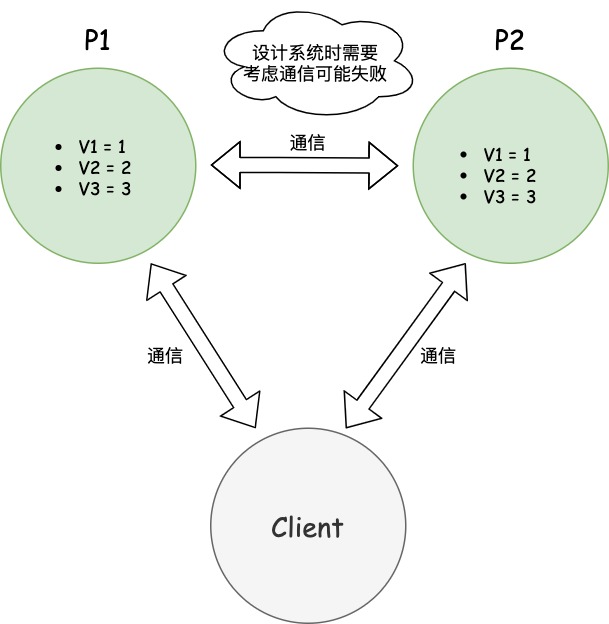
大多數分散式系統都分布在多個子網路。每個子網路就叫做一個區(partition)。分區容錯的意思是,區間通訊可能失敗。比如,一台伺服器放在中國,另一台伺服器放在美國,這就是兩個區,它們之間可能無法通訊。
圖中,P1和P2是兩台跨區的伺服器。P1向P2發送一條消息,P2可能無法收到。系統設計的時候,必須考慮到這種情況。一般來說,分區容錯無法避免,因此可以認為CAP的P總是成立。CAP定理告訴我們,剩下的C和A無法同時做到。
一致性(Consistency)
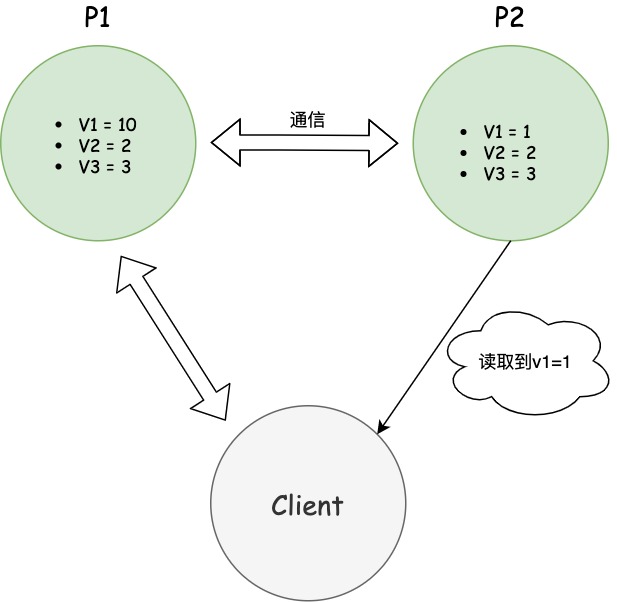
一致性意味著寫操作之後的讀操作,必須返回該值。舉例來說,某條記錄是v1=1,用戶向P1發起一個寫操作,將其改為v1=10,接下來,用戶的讀操作就會得到v1=10,這就叫一致性。
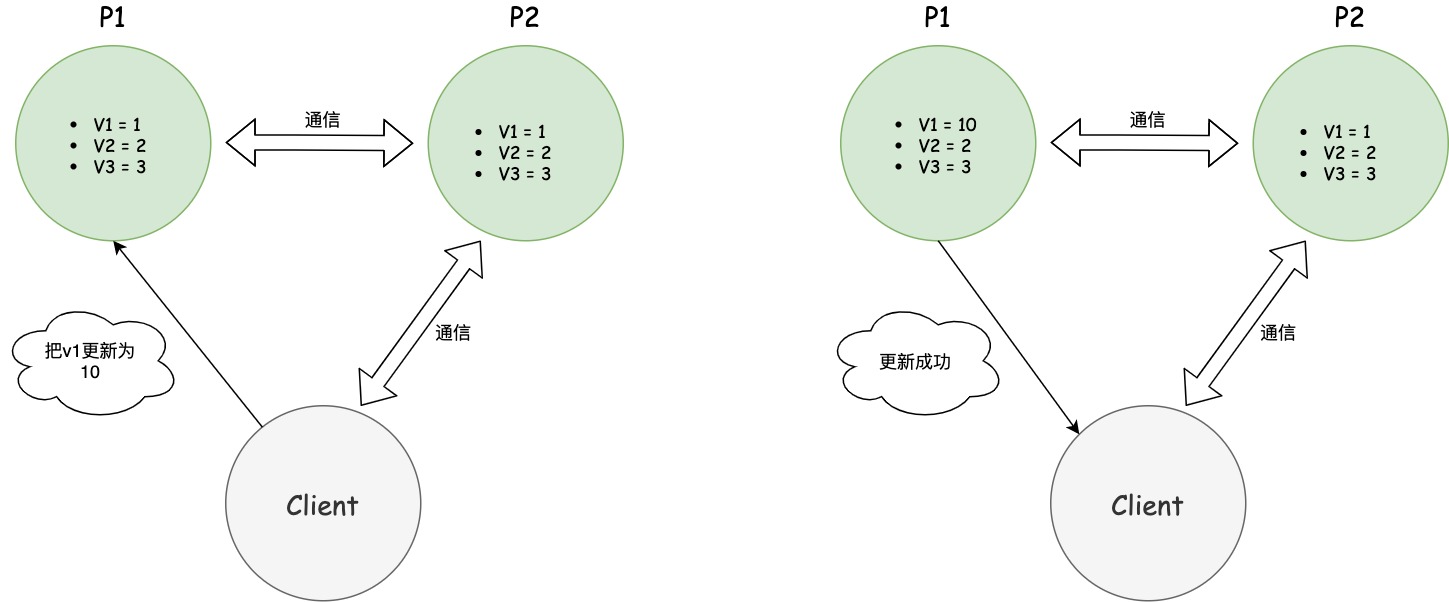
問題是,用戶有可能向P2發起讀操作,由於P2的值沒有發生變化,因此返回的是 v0。P1和P2讀操作的結果不一致,這就不滿足一致性了。
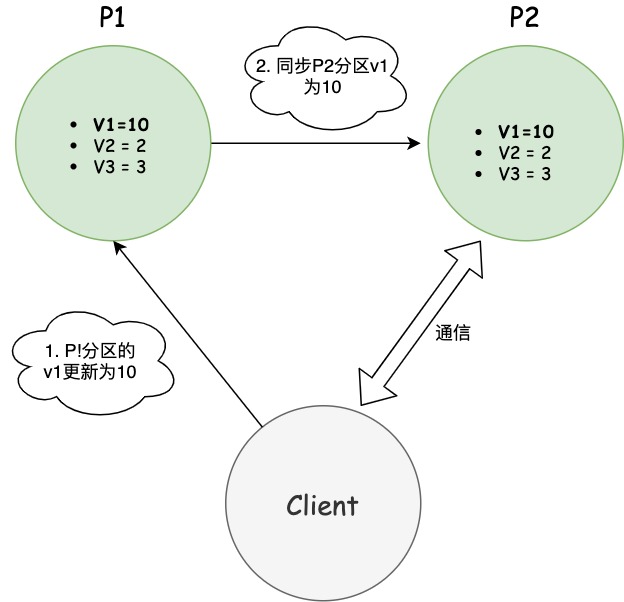
為了讓P2也能變為v1=10,就要在P1寫操作的時候,讓P1向P2發送一條消息,要求P2也改成v1=10。
可用性(Availability)
可用性是指只要收到用戶的請求,伺服器就必須給出回應。
用戶可以選擇向P1或P2發起讀操作。不管是哪台伺服器,只要收到請求,就必須告訴用戶v1的值,否則就不滿足可用性。
一致性和可用性的矛盾
一致性和可用性,為什麼不可能同時成立?答案很簡單,因為可能通訊失敗(即出現分區容錯)。
如果保證P2的一致性,那麼P1必須在寫操作時,鎖定P2的讀操作和寫操作。只有數據同步後,才能重新開放讀寫。鎖定期間,P2不能讀寫,沒有可用性。如果保證P2的可用性,那麼勢必不能鎖定P2,所以一致性不成立。綜上所述,P2無法同時做到一致性和可用性。系統設計時只能選擇一個目標。如果追求一致性,那麼無法保證所有節點的可用性;如果追求所有節點的可用性,那就沒法做到一致性。
那麼在什麼場合,可用性高於一致性?舉例來說,發布一張網頁到 CDN,多個伺服器有這張網頁的副本。後來發現一個錯誤,需要更新網頁,這時只能每個伺服器都更新一遍。一般來說,網頁的更新不是特彆強調一致性。短時期內,一些用戶拿到老版本,另一些用戶拿到新版本,問題不會特別大。當然,所有人最終都會看到新版本。所以,這個場合就是可用性高於一致性。
常見產品
Ereka->ereka是SpringCloud系列用來做服務註冊和發現的組件,作為服務發現的一個實現,在設計的時候就更考慮了可用性,保證了AP。
Zookeeper->Zookeeper在實現上犧牲了可用性,保證了一致性(單調一致性)和分區容錯性,也即:CP。所以這也是SpringCloud拋棄了zookeeper而選擇Ereka的原因。
Zookeeper當master掛了,會在30-120s進行leader選舉,這點類似於redis的哨兵機制,在選舉期間Zookeeper是不可用的,這麼長時間不能進行服務註冊,是無法忍受的,別說30s,5s都不能忍受。這時Zookeeper集群會癱瘓,這也是Zookeeper的CP,保持節點的一致性,犧牲了A/高可用。而Eureka不會,即使Eureka有部分掛掉,還有其他節點可以使用的,他們保持平級的關係,只不過資訊有可能不一致,這就是AP,犧牲了C/一致性。
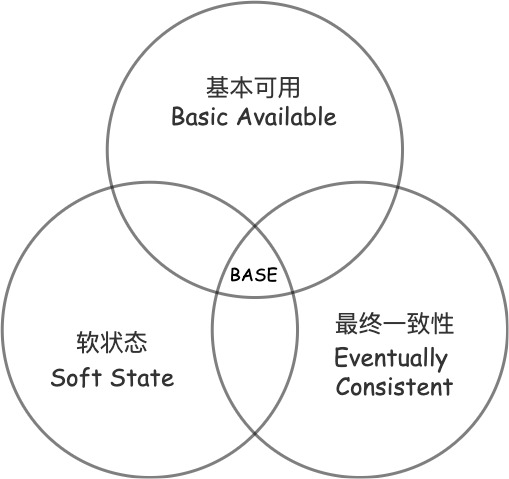
BASE理論
如前文中說CAP定理是三個單詞的縮寫,BASE也是一樣,是由Basically Available(基本可用),Soft state(軟狀態),和 Eventually consistent(最終一致性)三個短語的縮寫。
為什麼要BASE理論
CAP定理只能三選二,CAP理論表明,對於一個分散式系統而言,它是無法同時滿足Consistency(強一致性)、Availability(可用性) 和Partition tolerance(分區容忍性) 這三個條件的,最多只能滿足其中兩個。
分區容錯必須選,對於互聯網來說,由於網路環境是不可信的,所以分區容錯性(P)必須滿足
為了用戶體驗,先選可用性。現在只能在一致性和可用性之間做選擇,大部分情況下,大家都會選擇犧牲一部分的一致性來保證可用性,因為你不返回給用戶數據,這體驗也太差了,寧可拒絕服務也不能說能訪問卻沒有數據,當然,嚴格場景下,比如支付場景,強一致性是必須要滿足,這另說。
但是放棄了一致性的系統又失去了存在的意義,好了,我們只能放棄一致性,但是我們真這樣做了,將一致性放棄了,現在這個系統返回的數據你敢信嗎?沒有一致性,系統中的數據也就從根本上變得不可信了,那這數據拿來有什麼用,那這個系統也就沒有任何價值,根本沒用。
如上所述,由於我們三者都無法拋棄,但CAP定理限制了我們三者無法同時滿足,這種情況,我們會選擇盡量靠近CAP定理,即盡量讓C、A、P都滿足,在此大勢所趨下,出現了BASE定理。
核心思想
強一致性(Strong consistency)無法得到保障時(分區容錯和可用性滿足系統),我們可以根據業務自身的特點,採用適當的方式來達到最終一致性(Eventual consistency)。
基本可用(Basically Available)
基本可用是相對於正常的系統來說的,常見如下情況
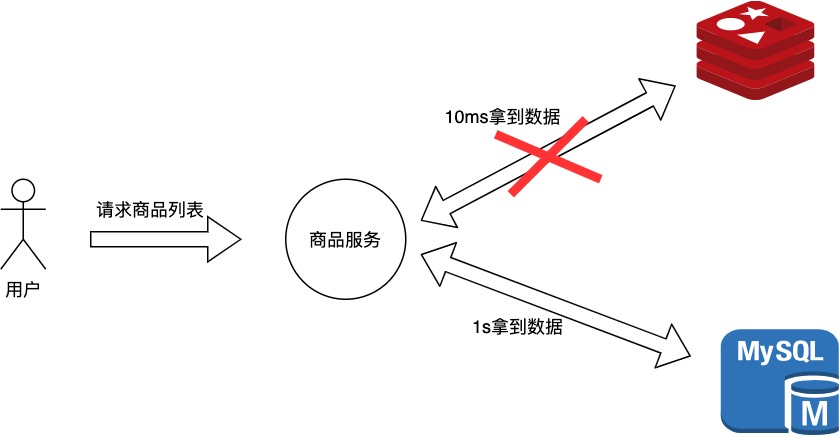
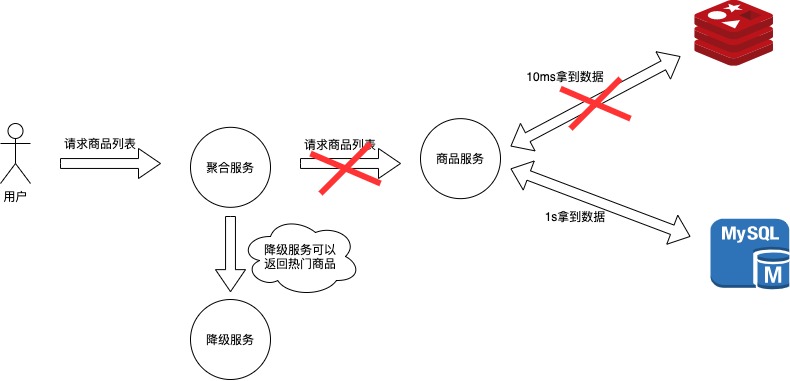
響應時間上的損失:正常情況下的搜索引擎0.5秒即返回給用戶結果,而基本可用看的搜索結果可能要1秒,2秒甚至3秒。如下圖中所示,本來用戶可以從redis用10ms讀取到數據,但是有些情況下為了保證一致性,需要從MySql花費1s讀取數據,用戶以更長的時間代價拿到了數據。
功能上的損失:在一個電商網站上,正常情況下,用戶可以順利完成每一筆訂單,但是到了促銷時間,可能為了應對並發,保護購物系統的穩定性,部分用戶會被引導到一個降級頁面。
軟狀態
軟狀態是相對原子性來說的
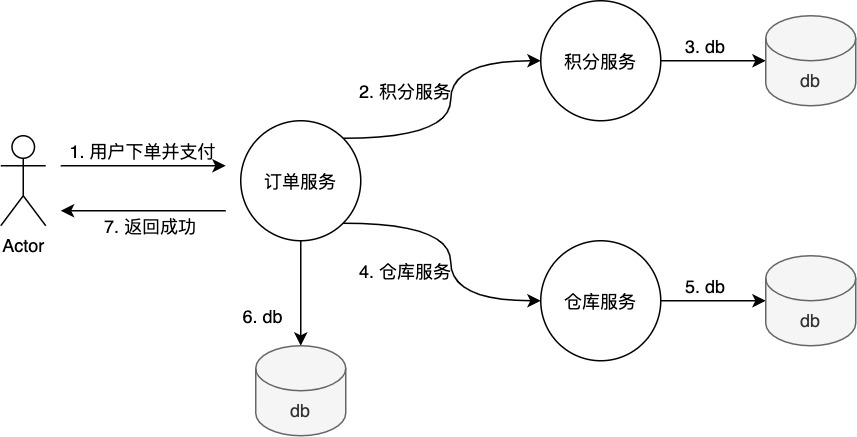
原子性(硬狀態)-> 要求多個節點的數據副本都是一致的,這是一種”硬狀態”。我們在之前學習過硬狀態,指的就是ACID的原子性。如下圖所示,硬狀態只有在訂單狀態、積分發送成功、倉庫出單成功,即三者同時成功的情況才算支付成功。
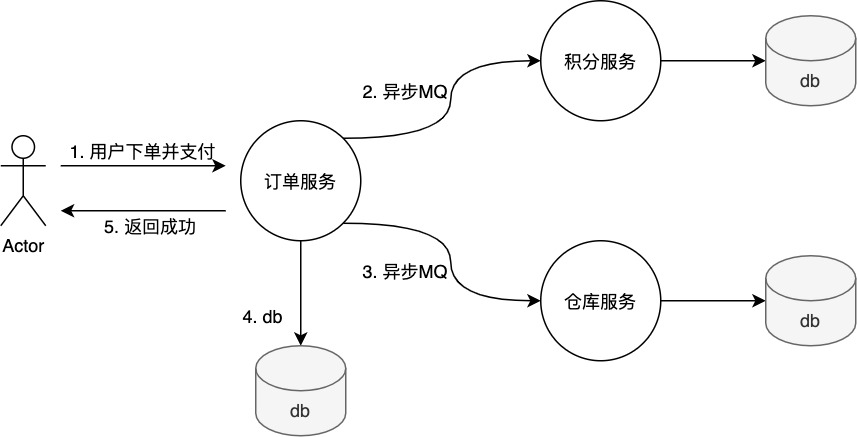
軟狀態(弱狀態)-> 允許系統中的數據存在中間狀態,並認為該狀態不影響系統的整體可用性,即允許系統在多個不同節點的數據副本存在數據延遲。軟狀態不需要完全符合ACID的原子性先把訂單狀態改成已支付成功,然後告訴用戶已經成功了,剩下在非同步發送mq消息通知積分服務和倉庫服務,即使消費失敗,MQ消息也會重新發送(重試)。
最終一致性(Eventually consistent)
弱一致性和強一致性相對,系統並不保證連續進程或者執行緒的訪問都會返回最新的更新過的值。系統在數據寫入成功之後,不承諾立即可以讀到最新寫入的值,也不會具體的承諾多久之後可以讀到。但會 儘可能保證在某個時間級別(比如秒級別)之後,可以讓數據達到一致性狀態。最終一致性是弱一致性的特定形式。
強一致性與弱一致性:其實只有兩類數據一致性,強一致性與弱一致性。強一致性也叫做線性一致性,除此以外,所有其他的一致性都是弱一致性的特殊情況。所謂強一致性,即複製是同步的,弱一致性,即複製是非同步的。
用戶更新網站頭像,在某個時間點,用戶向主庫發送更新請求,不久之後主庫就收到了請求。在某個時刻,主庫又會將數據變更轉發給自己的從庫。最後,主庫通知用戶更新成功。
如果在返回「更新成功」並使新頭像對其他用戶可見之前,主庫需要等待從庫的確認,確保從庫已經收到寫入操作,那麼複製是同步的,即強一致性。如果主庫寫入成功後,不等待從庫的響應,直接返回「更新成功」,則複製是非同步的,即弱一致性。
強一致性可以保證從庫有與主庫一致的數據。如果主庫突然宕機,我們仍可以保證數據完整。但如果從庫宕機或網路阻塞,主庫就無法完成寫入操作。
在實踐中,我們通常使一個從庫是同步的,而其他的則是非同步的。如果這個同步的從庫出現問題,則使另一個非同步從庫同步。這可以確保永遠有兩個節點擁有完整數據:主庫和同步從庫。 這種配置稱為半同步。
X/Open DTP模型與XA規範
X/Open,即現在的open group,是一個獨立的組織,主要負責制定各種行業技術標準。官網地址://www.opengroup.org/。X/Open組織主要由各大知名公司或者廠商進行支援,這些組織不光遵循X/Open組織定義的行業技術標準,也參與到標準的制定。下圖展示了open group目前主要成員(官網截圖):

DTP 參考模型:Distributed Transaction Processing: Reference Model
DTP XA規範: Distributed Transaction Processing: The XA Specification
參考文檔
維基百科——資料庫事務
維基百科——CAP定理
資料庫事務的概念及其實現原理
詳解分散式BASE定理
面試必問:分散式事務六種解決方案
漫畫:什麼是分散式事務?
聊聊分散式事務,再說說解決方案
分散式事務?No, 最終一致性
CAP 定理的含義
分散式事務概述
我是御狐神,歡迎大家關注我的微信公眾號:wzm2zsd

本文最先發布至微信公眾號,版權所有,禁止轉載!


