GAN實戰筆記——第二章自編碼器生成模型入門
- 2021 年 10 月 19 日
- 筆記
- GAN, GAN(生成對抗網路), 深度學習
自編碼器生成模型入門
之所以講解本章內容,原因有三。
- 生成模型對大多數人來說是一個全新的領域。大多數人一開始接觸到的往往都是機器學習中的分類任務——也許因為它們更為直觀;而生成模型試圖生成看起來很逼真的樣本,所以人們對它了解甚少。考慮到自編碼器(最近GAN的前身)豐富的資源和研究,所以選擇在一個更簡單的環境介紹生成模型。
- 生成模型非常具有挑戰性。由於生成模型代表性不足,大多數人不知道典型的生成結構是什麼樣子的,也不知道面臨何種挑戰。儘管自編碼器在許多方面與最常用的模型相近(例如,有一個明確的目標函數),但它們仍然展現出許多GAN也面臨的挑戰,如評估生成樣本品質有多困難。
- 生成模型是當前文獻中的研究點。自編碼器本身有它自己的用途。自編碼器是一個活躍的研究領域,甚至在某些領域是最前沿的並且被許多GAN模型顯示地採用。
一、生成模型簡介
你應該對「深度學習如何獲取影像中的原始像素並將其轉化為類別的預測」這種操作並不陌生。例如,可以取包含影像像素的3個矩陣(每個顏色通道各1個)在一個轉換系統中傳遞,最後得到一個數字。如果想反過來做,該怎麼辦呢?
從要生成內容的描述指令開始,最後在轉換系統的另一端得到影像。這是最簡單、最非正式的生成模型。
更正式一點,取一個特定的描述指令(z)——簡單地假設它是介於0和9之間的數字——並嘗試得到一個生成的樣本(\(x^*\))。理想情況下\(x^*\)應該和另一個真實的樣本x看起來一樣真實。描述指令z是潛在空間( latent space)中的某個激勵,我們不會總是得到相同的輸出\(x^*\)。這個潛在空間是一個習得的表徵——希望它按人類思考方式對人們有意義(「解離」)。不同的模型將學習相同數據的不同潛在表徵。
潛在空間是數據的隱式表示。自編碼器不是在未壓縮的版本中表達單詞或影像(例如機器學習工程師,或影像的JPEG編碼器),而是根據對數據的理解來對其進行壓縮和聚類。
二、自編碼器如何用於高級場景
顧名思義,自編碼器可以幫助我們對數據進行自動編碼,它由兩部分構成:編碼器和解碼器。為了便於說明,我們考慮這樣一個用例:壓縮。
三、什麼是GAN的自編碼器
自編碼器是一種神經網路,它的輸入和輸出是一致的,目標是使用稀疏的高階特徵重新組合來重構自己。
自編碼器與GAN的一個關鍵區分點是:我們用一個損失函數對整個自編碼器網路進行端到端的訓練,而GAN的生成器和判別器分別有損失函數。
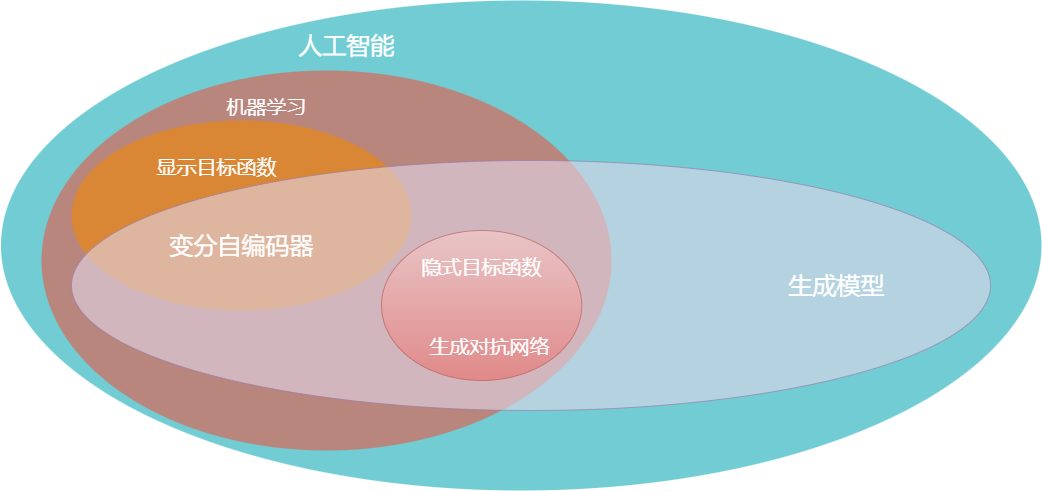
現在看看自編碼器和GAN所處的位置,如下圖所示。兩者都是生成模型,且都是人工智慧(AI)和機器學習(ML)的子集。
端到端思想:深度學習的一個重要思想即「端到端」的學習方式,屬表示學習的一種。這是深度學習區別於其他機器學習演算法的最重要的一個方面。過去解決一個人工智慧問題(以影像識別為例)往往通過分治法將其分解為預處理、特徵提取與選擇、分類器設計等若干步驟。分治法的動機是將影像識別的母問題分解為簡單、可控且清晰的若干小的子問題。不過分步解決子問題時,儘管可在子問題上得到最優解,但子問題上的最優並不意味著就能得到全局問題的最後解。對此,深度學習則為我們提供了另一種範式,即「端到端」學習方式,整個學習流程並不進行人為的子問題劃分,而是完全交給深度學習模型直接學習從原始輸入到期望輸出的映射。相比分治策略,「端到端」的學習方式具有協同增效的優勢,有更大可能獲得全局最優解。
在這種情況下,對於自編碼器(或其變分形式,VAE),我們有一個試圖優化的已明確寫出的函數(一個代價函數);但在GAN中沒有像均方誤差、準確率或ROC曲線下面積這樣明確的指標進行優化。GAN有兩個不能寫在一個函數中的相互競爭的目標。
四、自編碼器的構成
與機器學習中的許多進展一樣,自編碼器的高級理念很直觀,並遵循以下簡單步驟,如下圖所示。
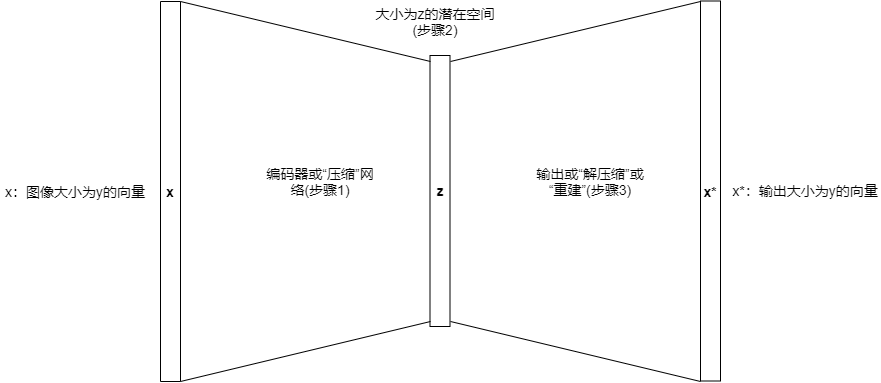
步驟解釋:
(1)壓縮關於機器學習工程師的所有知識。
(2)將其組合到潛在空間(給祖母的信中)。當利用對單詞的理解作為解碼器(步驟3)重建一個含義有損的版本時,你就得到了一個與原始輸入(即你的想法)在同一個空間的(祖母的頭腦中)想法的表示。
(1)編碼器網路:取一個表示x(如一個影像),然後用學過的編碼器(通常是一個單層或多層的神經網路)將維數從y減小到z。
(2)潛在空間(z):在訓練時,試圖建立具有一定意義的潛在空間。潛在空間通常是有較小維度的表示,起著中間步驟的作用。在這種數據的表示中,自編碼器試圖」組織其思想「。
(2)解碼器網路:用解碼器將原始對象重建到原始的維度,這通常由一個神經網路完成。它是編碼器的鏡像,對應著z到x*的步驟。我們可以用解碼的逆過程,從潛在空間的256個像素長的向量中得到784個像素長的重構向量(28×28大小的影像)。
下面給出一個自編碼器訓練過程的示例。
- 將影像x通過自編碼器輸入。
- 得到x*,即重建的影像。
- 評估重建損失,即x和x*之間的差異:
- 使用影像x和x*的像素之間的距離(如MAE)完成;
- 給定一個顯示目標的函數(||x-x*||),以通過梯度下降的形式進行優化
因此我們的任務就是找到解碼器和編碼器的參數,這些參數將最小化我們用梯度下降法更新的重構損失。
五、自編碼器的使用
儘管自編碼器很簡單,但是有很多理由值得我們關注它。
- 首先,我們可以自由地壓縮!這是因為上圖中的中間步驟(2)在潛在空間的維度上変成了一個智慧縮減的影像或對象。從理論上講,這可能比原始輸入小几個數量級,而且顯然不是無損的,但是如果願意的話,我們可以隨意利用這種副作用。
- 仍使用潛在空間,我們可以聯想到許多實際應用,如單類分類器(one- class classifier)——一種異常檢測演算法,可以在縮減的可更快搜索的潛在空間中查看項目,以檢查和目標類別的相似性。這就可以用於搜索(資訊檢索)或者異常檢測(比較潛在空間中的接近度)。
- 另一個用例是黑白影像的數據去噪或彩色化。如果有舊的/有雜訊的一張照片或者一段影片——例如第二次世界大戰時期的影像,那麼可以減少它們的噪點並重新著色。因此自編碼器與GAN的相似之處在於,GAN在這類應用程式中也表現很出色。
- 有些GAN的架構,例如BEGAN,將自編碼器用作其架構的一部分以幫助穩定訓練。
- 訓練自編碼器不需要帶標籤的數據。這讓我們更輕鬆,因為不需要我們去尋找標籤就可以自訓練。
- 最後同樣重要的是,可以用自編碼器生成新影像。自編碼器已應用於生成從數字到人臉到卧室的任何事物,但通常影像的解析度越高,性能就越差,因為輸出往往看起來很模糊。但是對於MINST數據集和其他低解析度影像來說,自編碼器的效果很好。
這些都可以做到,因為我們找到了已擁有數據的新表示。這種表示很有用,可以提取出壓縮資訊的核心資訊;基於隱式表達,它也很容易操作或生成新的數據。
六、變分自編碼器
變分自編碼器( Variational Auto- Encoders, VAE)作為深度生成模型的一種形式,是於2014年提出的生成式網路結構。
它以概率的方式描述對潛在空間的觀察,在數據生成方面表現出了巨大的應用價值。
VAE和生成對抗網路( Generative AdversarialNetworks, GAN)被視為無監督式學習領域最具硏究價值的方法之一。
自編碼器很好地解決了影像的編碼解碼問題,但如果使用隨機數產生隱含變數並不能輸出正確的影像。因為輸入影像編碼的隱含變數可能沒有一個正確的分布。
為了能夠讓隱含變數服從一定的分布,就需要對隱含變數進行限制。具體的方式是限制隱含變數的KL散度( Kullback Leibler Divergence)。
KL散度是兩個概率分布間差異的非對稱性度量。假設兩個分布P、Q的概率密度函數為p(x)和q(x),定義兩個分布之間的KL散度如下所示。
\]
為了讓隱含變數能夠服從預設的分布,可以令Q為預設的分布,P為隱含變數的分布,令這兩個分布的KL散度最小,這樣就能讓P分布逐漸逼近Q分布。
為了解決這個問題,在VAE模型中使用了重參數化( Reparameterization)的技巧。所謂重參數化,就是在實際的模型中,編碼器並不會生成隱含變數,而是輸出隱含變數服從的參數,然後使用這些參數產生服從一定分布的隱含變數。
以正態分布為例,在正態分布中,重要的參數有兩個,\(\mu\)代表分布的平均值,\(\sigma\)代表分布的標準差,這裡用N(\(\mu, \sigma^2\))來表示相應的正態分布。編碼器的目的就是用來生成\(\mu\)和\(\sigma\)兩個參數。
七、無監督學習
無監督學習( unsupervised learning)是一種從數據本身學習而不需要關於這些數據含義的附加標籤的機器學習。例如,聚類是無監督的,因為只是試圖揭示數據的底層表示;異常檢測是有監督的,因為需要人工標記的異常情況。
我們可以了解無監督機器學習為何與眾不同,可以使用任何數據而不必為特定目的對其進行標記。我們可以使用任何互聯網上的數據而不必為關心的每一種表示標記每個樣本,例如,這張圖片中有隻狗嗎?有輛車嗎?
在監督學習中,如果數據沒有針對確切任務的標籤,那麼別的(幾乎)所有標籤都可能是沒用的。如果你有一個可以對Google街景中的汽車分類的分類器,想對動物進行分類但是沒有這些動物影像的標籤,這種情況下使用相同數據集訓練一個動物分類器基本上是不可能的。即使這些樣本中經常出現動物,也需要標註者重新標註同樣的Google街景數據集中的動物。
本質上,我們需要在了解具體用例之前就考慮到數據的應用,這很困難!但是對於許多壓縮類型的任務,你總是有帶標記的數據,即數據本身。 研究人員把這種類型的機器學習稱為自監督。
由於訓練數據也充當了標籤,從一個關鍵的角度來看,訓練許多這樣的演算法會容易得多——畢竟現在有更多的數據可以處理。
1. 自編碼器
自編碼器由兩個神經網路組成:編碼器和解碼器。兩者都有激活函數,且只為每個函數使用一個中間層,這意味著每個網路中有兩個權重矩陣——對於編碼器網路,一個從輸入到中間層,一個從中間層到潛在空間;對於解碼器網路,又有一個從潛在空間到不同的中間層和一個從中間層到輸出的權重矩陣。如果每個網路都只有一個權重矩陣,那麼過程將類似於主成分分析(Principal Component Analysis,PCA)的成熟分析技術。