JVM詳解(四)——運行時數據區-堆
一、堆
1、介紹
Java運行程式對應一個進程,一個進程就對應一個JVM實例。一個JVM實例就有一個運行時數據區(Runtime),Runtime裡面,就只有一個堆,一個方法區。這裡也闡述了,方法區和堆是一個進程一份。而一個進程當中,可以有多個執行緒,那就意味著一個進程中的多個執行緒會共享堆空間和方法區。
一個JVM實例只存在一個堆記憶體,堆也是Java記憶體管理的核心區域。堆在JVM啟動的時候被創建,其空間大小也就確定了,是JVM管理的最大一塊記憶體空間,堆記憶體大小是可以調節的。
Java虛擬機規範規定,堆可以處於物理上不連續的記憶體空間中,但在邏輯上它應該被視為連續的。
所有的執行緒共享Java堆,在這裡還可以劃分執行緒私有的緩衝區(TLAB)。
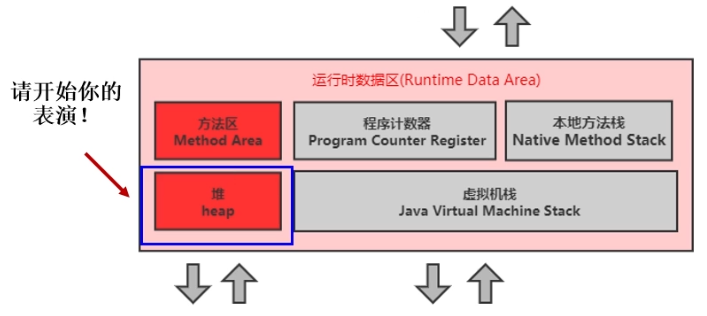
堆空間中,有一部分執行緒私有的緩衝區,叫TLAB,它不是所有執行緒共享的區域。
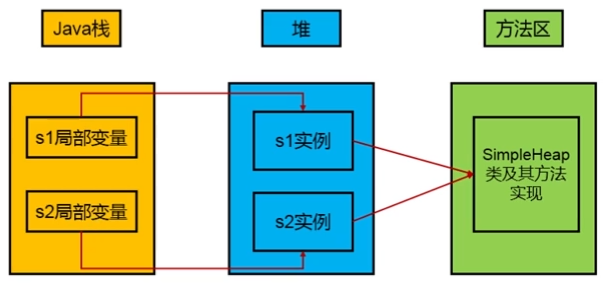
《Java虛擬機規範》中對堆的描述是:所有的對象實例以及數組都應當在運行時分配在堆上。其實,從實際使用角度來看,是”幾乎”所有的對象實例都在這裡分配記憶體。
數組和對象可能永遠不會存儲在棧上,因為棧幀中保存引用,這個引用指向對象或數組在堆中的位置。在方法結束後,堆中的對象不會馬上被移除,僅僅在垃圾收集的時候才會被移除。堆,是GC執行垃圾回收的重點區域。而頻繁的GC會影響用戶執行緒的執行。
為什麼是幾乎?逃逸分析,會去判斷在方法中對象是否發生了逃逸,如果沒有的話,會在棧上分配。
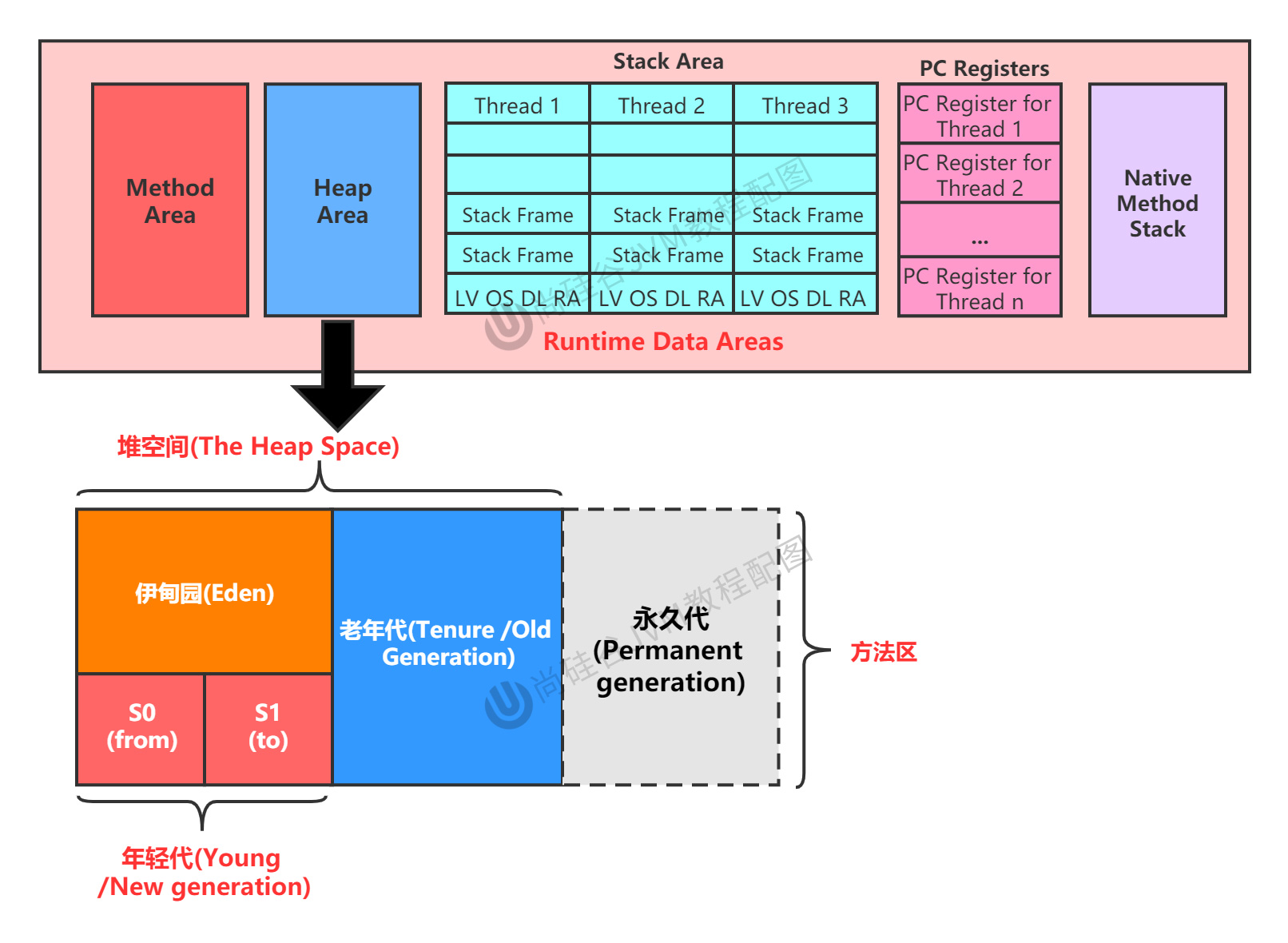
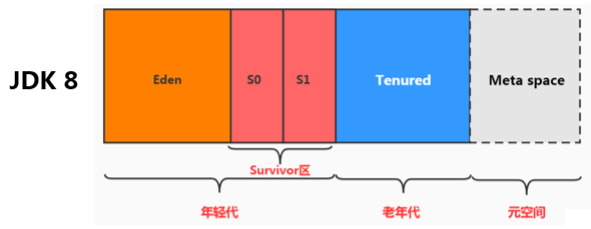
2、堆的記憶體結構
堆空間細分

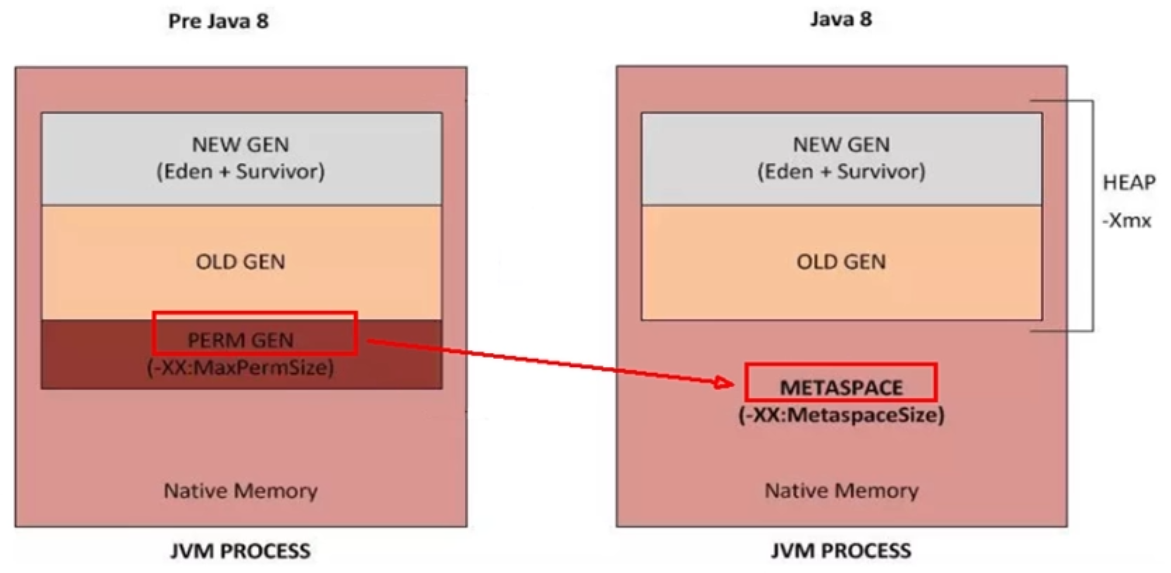
JDK7:
JDK8:
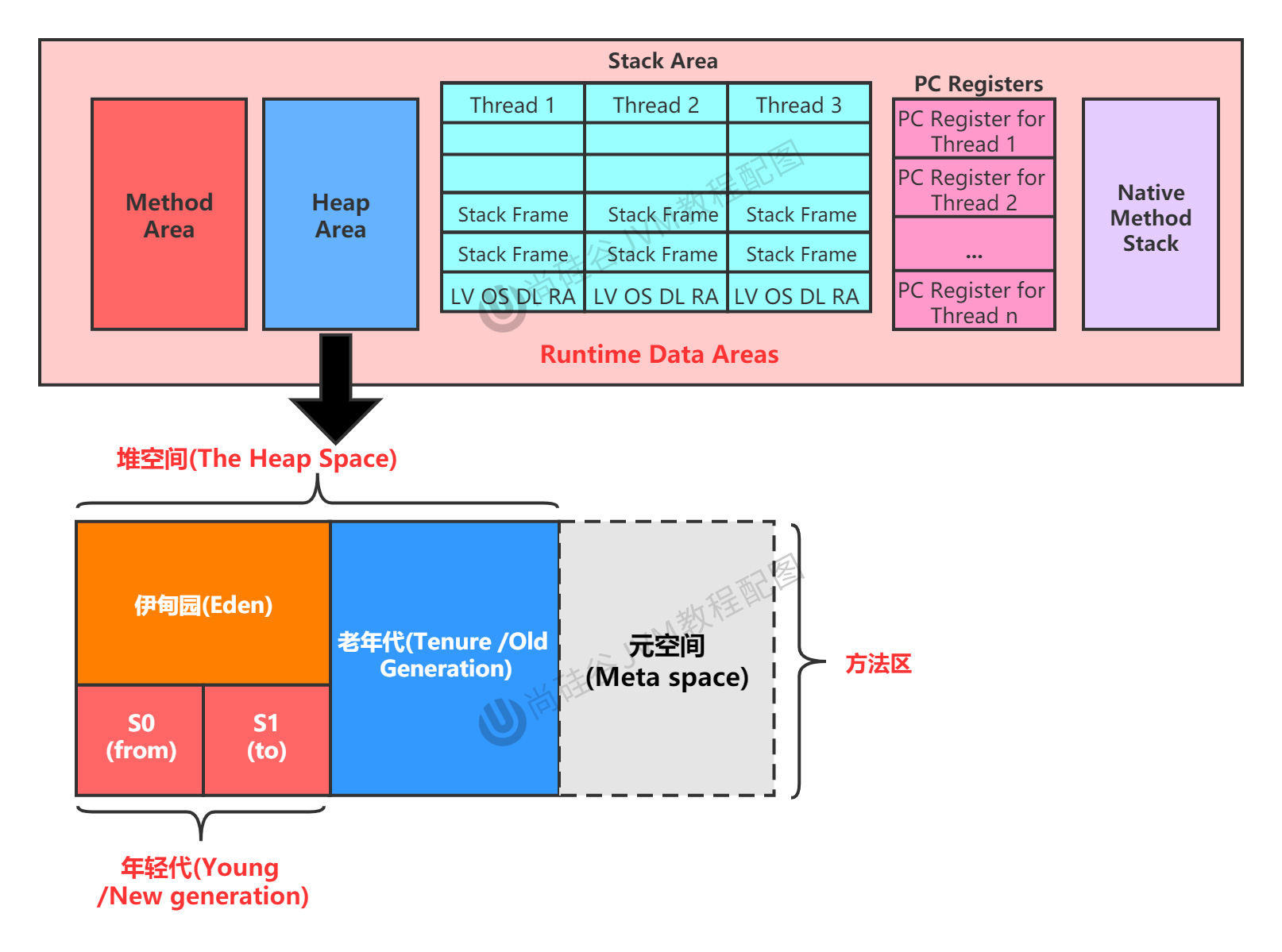
永久代–>元空間
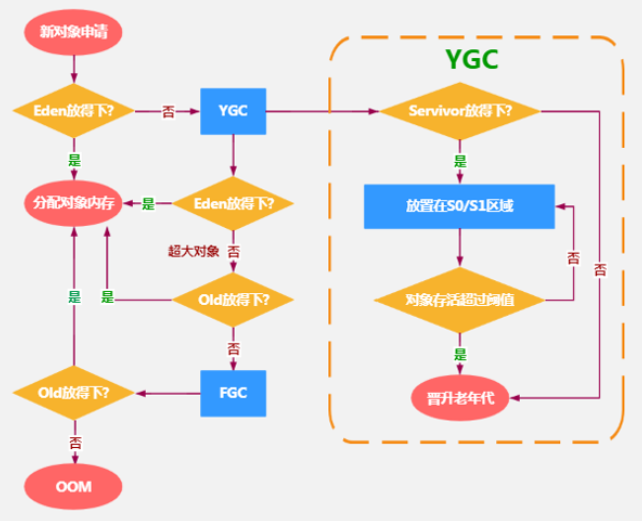
3、設置堆記憶體大小與OOM
Java堆用於存儲Java對象實例,在JVM啟動時就已經設定好了。可以通過-Xmx和-Xms來進行設置。一旦堆區的記憶體大小超過-Xmx所指定的最大記憶體時,將會拋出OutOfMemoryError異常。
-Xms:堆區的初始記憶體大小
-Xmx:堆區的最大記憶體大小-X:是JVM的運行參數
ms:是memory start
通常會將-Xms和-Xmx兩個參數配置相同的值,其目的是為了能夠在Java垃圾回收機制清理完堆區後不需要重新分割計算堆區的大小,從而提高性能。
理由:初始設置一個值之後,如果堆空間不夠的話,需要不斷的擴容。後續不用的話,也需要釋放。那麼,在伺服器使用的時候,堆空間不斷的擴容。在空閑的時候,也需要把堆空間做釋放,那頻繁的擴展和釋放,會造成不必要的系統壓力。
默認情況下,初始記憶體大小:物理電腦記憶體大小/64。最大記憶體:物理電腦記憶體大小/4。
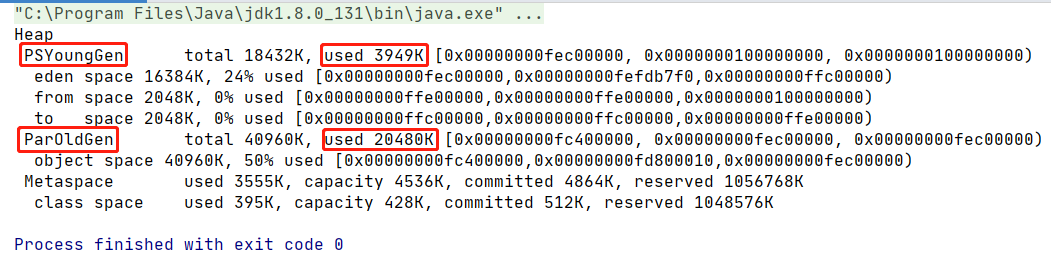
程式碼示例:設置堆記憶體大小
1 // 默認情況 2 public class Main { 3 public static void main(String[] args) { 4 5 // 返回Java虛擬機中的堆記憶體總量 6 long initialMemory = Runtime.getRuntime().totalMemory() / 1024 / 1024; 7 // 返回Java虛擬機試圖使用的最大堆記憶體量 8 long maxMemory = Runtime.getRuntime().maxMemory() / 1024 / 1024; 9 10 System.out.println("-Xms : " + initialMemory + "M"); 11 System.out.println("-Xmx : " + maxMemory + "M"); 12 13 System.out.println("系統記憶體大小為:" + initialMemory * 64.0 / 1024 + "G"); 14 System.out.println("系統記憶體大小為:" + maxMemory * 4.0 / 1024 + "G"); 15 16 // try { 17 // Thread.sleep(1000000); 18 // } catch (InterruptedException e) { 19 // e.printStackTrace(); 20 // } 21 } 22 } 23 24 // 默認值 25 // -Xms : 245M (約為 16G / 64) 26 // -Xmx : 3628M 27 // 系統記憶體大小為:15.3125G (這個值約等於系統記憶體) 28 // 系統記憶體大小為:14.171875G 29 30 // 設置堆參數:-Xms600m -Xmx600m 31 // -Xms : 575M 32 // -Xmx : 575M
為什麼設置的是600M。列印出來卻是575M呢?查看設置的參數:
方式一:jps / jstat -gc #{進程id}
方式二:-XX:+PrintGCDetails
因為統計是:eden + s0 + old

4、新生代與老年代
存儲在JVM中的Java對象可以被劃分為兩類:①生命周期較短的瞬時對象,這類對象的創建和消亡都非常迅速。②生命周期非常長的對象,在某些極端情況下還能夠與JVM的生命周期保持一致。
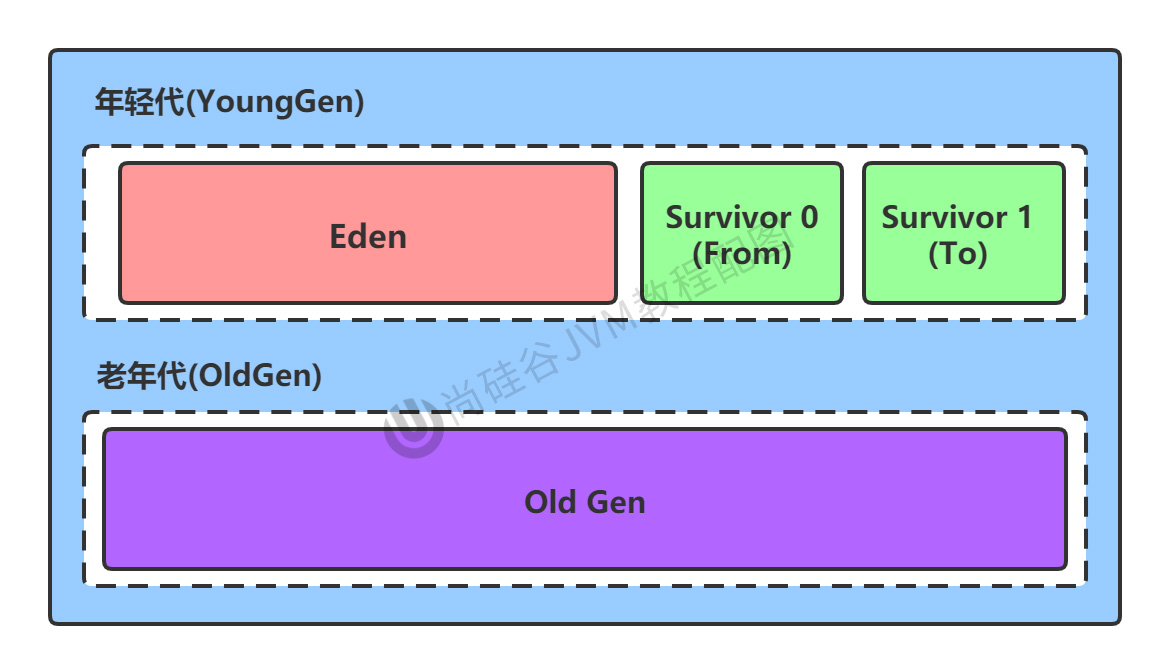
如下圖所示:堆空間的劃分,默認,新生代:老年代 = 1:2,S0:S1:Eden = 1:1:8。
可以通過-XX:NewRatio=2,-XX:SurvivorRatio=8來設置比例。
程式碼示例:查看比例關係
1 // 設置:-Xms600m -Xmx600m 2 // 可通過命令行的指令查看比例 3 jinfo -flag NewRatio #{進程id} 4 -XX:NewRatio=2 5 6 jinfo -flag SurvivorRatio #{進程id} 7 -XX:SurvivorRatio=8
可以發現,-XX:NewRatio的值是2,並且用jvisualvm.exe查看,記憶體的大小也是一致的。但是-XX:SurvivorRatio的值是8,但是查看的卻是6。怎麼回事呢?
這裡,官網文檔里給的是8,查看的也是8,但是實際運行記憶體分配是6。手動設置一下吧。
幾乎所有的Java對象都是在Eden區被new出來的。絕大部分的Java對象的銷毀都在新生代進行。新生代中80%的對象都是朝生夕死的。
可以使用-Xmn設置新生代的記憶體大小。
通常情況下,絕大多數Java對象的生命周期都是很短的。survivor區放的就是從Eden區通過minor gc存活下來的。老年代,存放新生代中經歷多次GC仍然存活的對象。
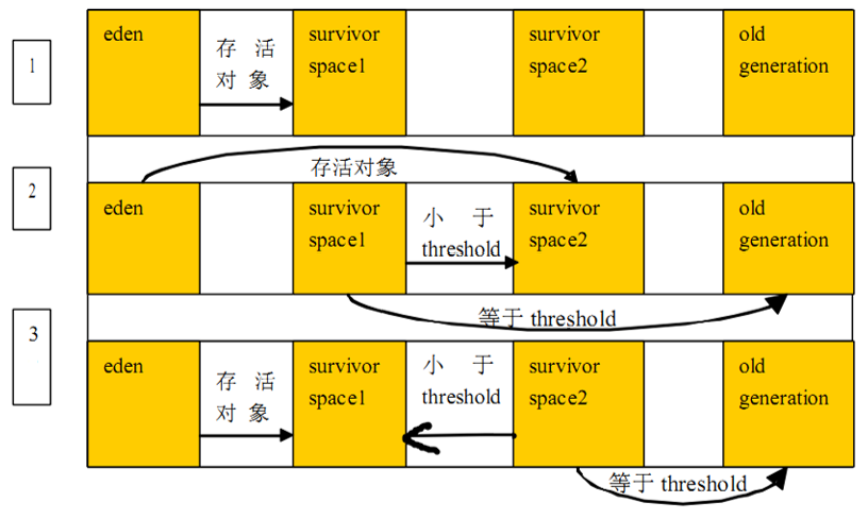
5、圖解對象分配過程(重要)
為新對象分配記憶體是一件非常嚴謹和複雜的任務,JVM的設計者們不僅需要考慮記憶體如何分配、在哪裡分配等問題,並且由於記憶體分配演算法與記憶體回收演算法密切相關,所以還需要考慮GC執行完記憶體回收後是否會在記憶體空間中產生記憶體碎片。圖解對象分配過程:
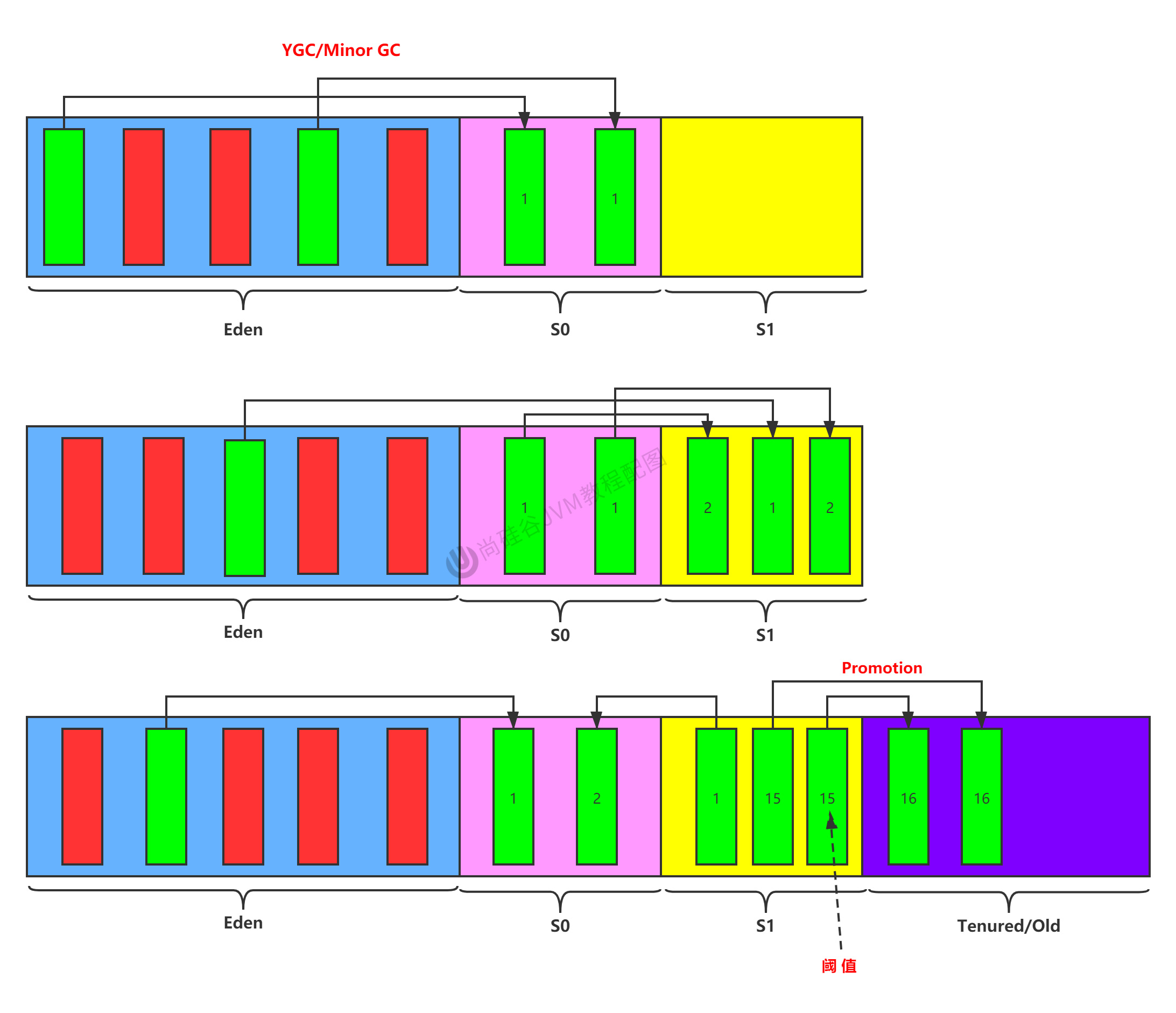
說明:綠色,存活;紅色,垃圾。
第一次:對象在Eden區產生,Eden區滿,如果再來對象,會進行一次gc,叫YGC,或者Minor GC,這時會觸發一個STW(stop the world),用戶執行緒會停止。
這時,Eden區放了5個對象,會去判斷誰是垃圾,誰不是垃圾。會清理掉紅色。把綠色的全部挪到S0區,且年齡計數器(每一個對象都有一個年齡計數器age) + 1。
第一次完畢:這時Eden區的數據被全部清空,只有S0區有兩個對象。
第二次:對象在Eden區產生,當他又滿了,會又觸發YGC(Minor GC)。被清理掉4個垃圾,存活1個,這時會把它放到S1區。
同一次過程中(YGC),會把S0區的兩個對象也要判斷是否為垃圾,是就回收;這裡不是,把S0的兩個也放到S1中,且age +1。
第二次完畢:這時Eden區的數據被全部清空,S0區被全部清空。只有S1區有三個對象。
……
重複上述過程,直到。
第N次:當對象 age 達到15(默認值)後,S1區的兩個對象會晉陞,它不再是挪到S0區,而是挪到老年代。
注意:上面說到Eden區一滿,如果再來對象,會進行一次gc,叫YGC,或者Minor GC。如果是S0區滿了,不會觸發YGC。YGC就會回收 eden + s0/s1區。
在老年代,相對悠閑。當老年代記憶體不足時,會觸發GC(Major GC),對老年代的記憶體清理。若執行之後發現依然無法進行對象的保存,會報OOM。
關於垃圾回收:頻繁在新生代,很少在老年代,幾乎不在永久代/元空間。
對象分配的特殊情況:
①新生代區,在沒有達到15的時候,有沒有可能直接晉陞到老年代呢?可能的!
②一出生就到老年代,也是有可能的。大對象Eden區放不下的話,直接放到老年代。
程式碼示例:JVisualVM演示對象的分配過程


1 // 用JVisualVM查看各個區的記憶體變化情況 2 // -Xms600m -Xmx600m 3 public class Main { 4 byte[] buffer = new byte[new Random().nextInt(1024 * 200)]; 5 6 public static void main(String[] args) { 7 ArrayList<Test> list = new ArrayList<>(); 8 while (true) { 9 list.add(new Test()); 10 try { 11 Thread.sleep(10); 12 } catch (InterruptedException e) { 13 e.printStackTrace(); 14 } 15 } 16 } 17 }
分配過程
6、Minor GC、Major GC、Full GC(重要)
調優:主要就是要減少GC次數。
JVM在GC時,並不是每次都對新生代、老年代、方法區一起回收,大部分回收指的新生代。針對HotSpot VM的實現,它裡面的GC按照回收區域分為兩大類型,一種是部分收集(Partial GC),一種是整堆收集(Full GC)。
部分收集(Partial GC):不是完整收集整個Java堆,又分為:
(1)新生代收集(Minor GC / Young GC):只是新生代(Eden,S0,S1)的收集。
(2)老年代收集(Major GC / Old GC):只是老年代的收集。目前,只有CMS GC會有單獨收集老年代的行為。
(3)混合收集(Mixed GC):收集整個新生代以及部分老年代。目前,只有G1 GC會有這種行為。
整堆收集(Full GC):收集整個Java堆和方法區。
注意:很多時候Major GC和Full GC會混淆使用,需要具體分辨是老年代回收還是整堆回收。重點關注Major GC、Full GC。因為他產生的用戶執行緒暫停時間比Minor GC高10倍以上。
Minor GC
觸發條件:Eden區滿。S0、S1區滿不會引發。回收:Eden + S0/S01。因為大多數Java對象都是朝生夕死,所有Minor GC非常頻繁,回收速度也比較快。Minor GC會引發STW,暫停其他用戶執行緒,等垃圾回收結束,用戶執行緒才恢復運行。
Major GC
觸發條件:老年代滿。對象從老年代消失時,我們說Major GC或Full GC發生了。出現了Major GC,至少會伴隨至少一次Minor GC(不是絕對是,在Parallel Scavenge收集器的收集策略里就有直接進行Major GC的策略選擇過程)。也就是老年代空間不足時,會先嘗試Minor GC,如果還不足,則Major GC。
Major GC的速度一般比Minor GC慢10倍以上,STW的時間也更長。
若Major GC後,記憶體還不足,報OOM。
Full GC
觸發條件:有以下5個。
(1)調用System.gc()時,建議系統執行Full GC,但這不是必然執行的。
(2)老年代空間不足。
(3)方法區空間不足。
(4)通過MinorGC後進入老年代的平均大小大於老年代的可用記憶體。
(5)由Eden區,S0區向S1區複製時,對象大小大於S1可用記憶體,則把該對象轉存到老年代,且老年代的可用記憶體小於該對象大小。
Full GC是開發或調優中需要盡量避免的。
程式碼示例:GC舉例,用於日誌分析
1 // 測試MinorGC、MajorGC、FullGC 2 // -Xms9m -Xmx9m -XX:+PrintGCDetails 3 public class GCTest { 4 public static void main(String[] args) { 5 int i = 0; 6 try { 7 List<String> list = new ArrayList<>(); 8 String a = "baidu.com"; 9 while (true) { 10 list.add(a); 11 a = a + a; 12 i++; 13 } 14 } catch (Throwable t) { 15 t.printStackTrace(); 16 System.out.println("遍歷次數為:" + i); 17 } 18 } 19 }
gc
7、堆空間分代思想
為什麼需要把堆空間分代?不分代就不能正常工作了嗎?經研究,不同對象的生命周期不同,70%~90%的對象是臨時對象。
不分代也可以。分代的唯一理由就是優化GC性能。如果沒有分代,所有的對象都在一塊,就如同把一個學校的人都關在一個教室,GC的時候要找到哪些對象是垃圾,就會對堆的所有區域進行掃描。而很多對象是朝生夕死的,如果分代的話,把新創建的對象放到一個地方,GC的時候先把這塊存儲朝生夕死的對象的區域進行回收,會騰出很大的空間出來,也有利於提供GC效率。

8、記憶體分配策略(對象提升規則)
針對不同年齡段的對象分配原則如下:
(1)優先分配到Eden。
(2)大對象直接分配到老年代,盡量避免程式中出現過多的大對象。
(3)長期存活的對象分配到老年代。
(4)動態對象年齡判斷:如果S0區中相同年齡的所有對象大小的總和大於S0空間的一半,年齡大於或等於該年齡的對象可以直接進入老年代,無須等到年齡閾值。
(5)空間分配擔保:-XX:HandlePromotionFailure
程式碼示例:大對象直接進入老年代
1 // -Xms60m -Xmx60m -XX:NewRatio=2 -XX:SurvivorRatio=8 -XX:+PrintGCDetails 2 public class YoungOldAreaTest { 3 public static void main(String[] args) { 4 // 20m 5 byte[] buffer = new byte[1024 * 1024 * 20]; 6 } 7 }
結果:可以看到,這個大對象直接出現在了老年代。
9、為對象分配記憶體:TLAB
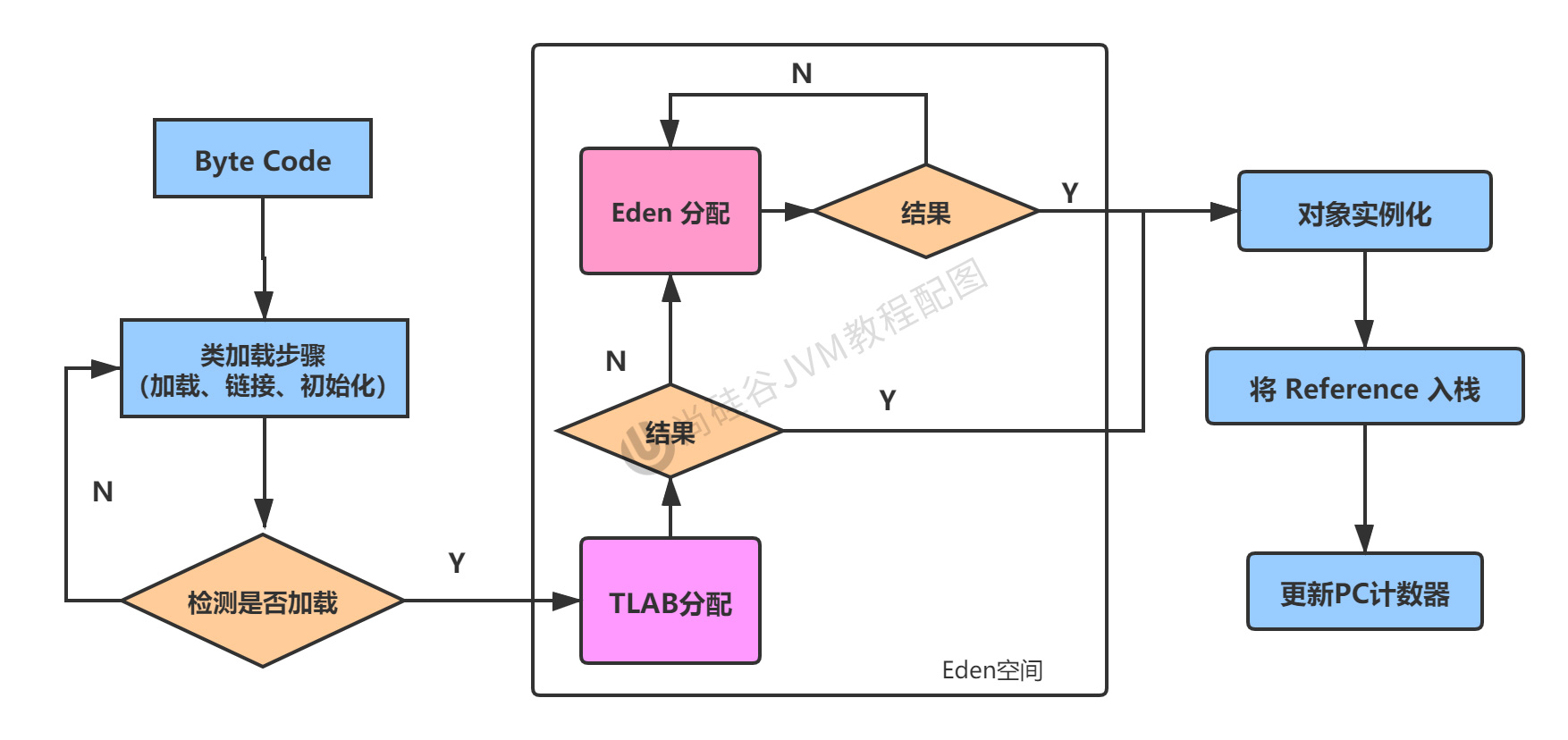
為什麼會有TLAB(Thread Local Allocation Buffer)?堆是執行緒共享區域,任何執行緒都可以訪問到堆中的共享數據。由於對象實例的創建在JVM中非常頻繁,因此在並發環境下從堆中劃分記憶體空間是不安全的,為避免多個執行緒操作同一地址,需要使用加鎖等機制,進而會影響分配速度。
什麼是TLAB?從記憶體模型而不是垃圾收集的角度,對Eden區繼續進行劃分,JVM為每個執行緒分配了一個私有快取區域,它包含在Eden空間內。多執行緒同時分配記憶體時,使用TLAB可以避免一系列的執行緒安全問題。同時還能夠提升記憶體內配的吞吐量,因此我們可以將這種記憶體分配方式稱之為快速分配策略。
據我所知,所有OpenJDK衍生出來的JVM都提供了TLAB的設計。
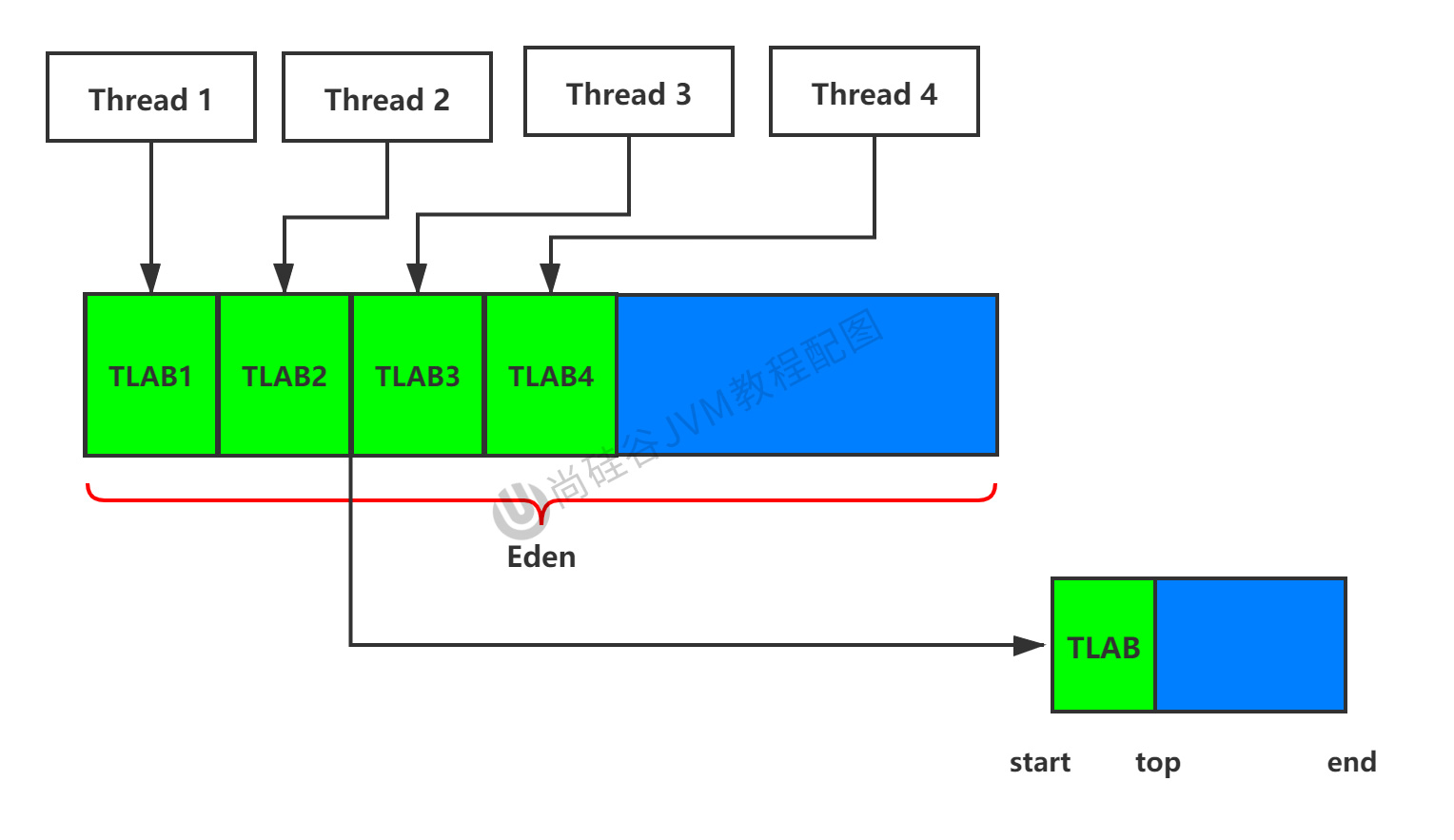
儘管不是所有的對象實例都能夠在TLAB中成功分配記憶體,但JVM確實是將TLAB作為記憶體分配的首選。默認情況下,TLAB空間記憶體非常小,僅占整個Eden區的1%。一旦對象在TLAB空間分配記憶體失敗時,JVM就會嘗試著通過使用加鎖機制確保數據操作的原子性,從而直接在Eden區中分配記憶體。
程式碼示例:
1 // 無參數設置。UseTLAB默認是開啟的 2 public class TLABArgsTest { 3 public static void main(String[] args) { 4 System.out.println("我只是來打個醬油~"); 5 6 try { 7 Thread.sleep(1000_000); 8 } catch (InterruptedException e) { 9 e.printStackTrace(); 10 } 11 } 12 }
對象分配過程:
二、逃逸分析
1、介紹
堆是分配對象的唯一選擇嗎?不是。棧上分配,標量替換。
在《深入理解Java虛擬機》中關於Java堆記憶體有這樣一段描述:
隨著JIT編譯期的發展與逃逸分析技術逐漸成熟,棧上分配、標量替換優化技術將會導致一些微妙的變化,所有的對象都分配到堆上也漸漸變得不那麼”絕對”了。
在Java虛擬機中,對象是在Java堆中分配記憶體的,這是一個普遍的常識。但是有一種特殊情況,就是如果經過逃逸分析後發現,這個對象並沒有逃逸出方法,那麼就可能被優化成棧上分配。這樣就無須在堆上分配記憶體,也無須進行垃圾回收了,這也是最常見的堆外存儲技術。
此外,前面提到的基於OpenJDK深度訂製的TaoBaoVM,其中創建的GCIH(GC invisible heap)技術實現off-heap,將生命周期較長的Java對象從heap中移至heap外,並且GC不能管理GCIH內部的Java對象,以此達到降低GC的回收頻率和提升GC的回收效率的目的。
2、逃逸分析:程式碼優化
使用逃逸分析,編譯器可以對程式碼做如下優化:
棧上分配:將堆分配轉化為棧分配,如果一個對象在子程式中被分配,如果指向該對象的指針永遠不會逃逸,對象可能是棧分配的候選,而不是堆分配。
同步省略:如果一個對象被發現只能從一個執行緒被訪問到,那麼對於這個對象的操作可以不考慮同步。
標量替換(分離對象):有的對象可能不需要作為一個連續的記憶體結構存在,也可以被訪問到,那麼對象的部分(或全部)可以不存儲在記憶體,而是存儲在CPU暫存器中。
這是一種可以有效減少Java程式中同步負載和記憶體堆分配壓力的跨函數全局數據流分析演算法。通過逃逸分析,Java編譯器能夠分析出一個新的對象的引用的使用範圍從而決定是否要將這個對象分配到堆上。
逃逸分析的基本行為就是分析對象動態作用域:
(1)當一個對象在方法中被定義後,對象只在方法內部使用,則認為沒有發生逃逸。
(2)當一個對象在方法中被定義後,它被外部方法所引用,則認為發生逃逸。例如作為調用參數傳遞到其他方法中。
程式碼示例:沒有逃逸
1 public void method1(){ 2 V v = new V(); 3 // use v 4 // ... 5 v = null; 6 }
沒有發生逃逸的對象,則可以分配到站上,隨著方法執行結束,棧空間就被移除。

如何快速的判斷是否發生了逃逸?就看new的對象實體是否有可能在方法外被調用。

3、棧上分配
JIT編譯器在編譯期間根據逃逸分析的結果,發現如果一個對象並沒有逃逸出方法的話,就可能被優化成棧上分配。分配完成後,繼續在調用棧內執行,最後執行緒結束,棧空間被回收,局部變數對象也被回收。這樣就無須進行垃圾回收了。
程式碼示例:棧上分配
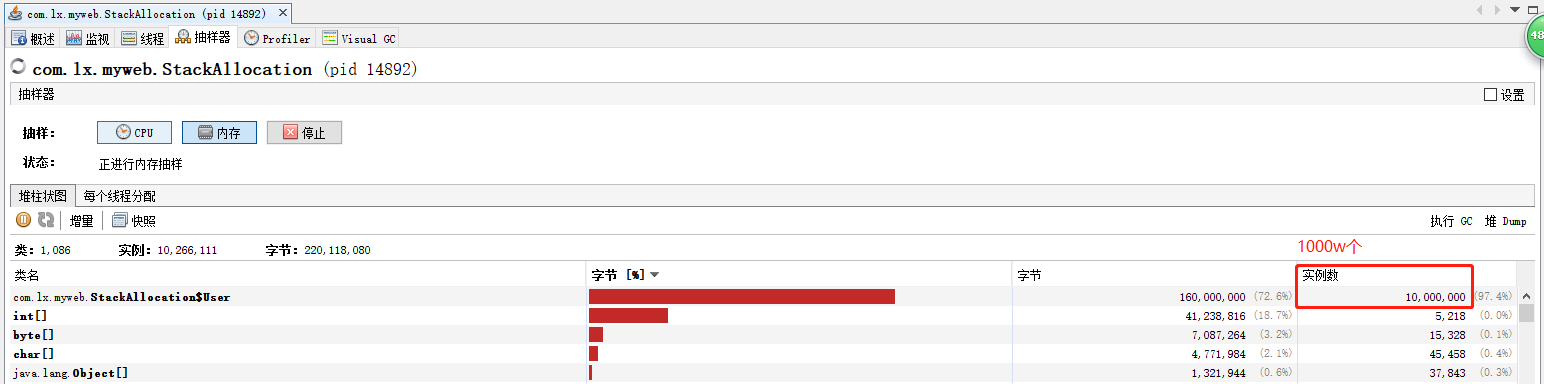
1 // -Xmx1G -Xms1G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails 2 public class StackAllocation { 3 public static void main(String[] args) { 4 long start = System.currentTimeMillis(); 5 6 for (int i = 0; i < 10000000; i++) { 7 alloc(); 8 } 9 10 // 查看執行時間 11 long end = System.currentTimeMillis(); 12 System.out.println("花費的時間為: " + (end - start) + " ms"); 13 14 // 為了方便查看堆記憶體中對象個數,執行緒sleep 15 try { 16 Thread.sleep(1000_000); 17 } catch (InterruptedException e1) { 18 e1.printStackTrace(); 19 } 20 } 21 22 private static void alloc() { 23 //未發生逃逸 24 User user = new User(); 25 } 26 27 static class User { 28 29 } 30 } 31 32 // -XX:-DoEscapeAnalysis 33 // 花費的時間為:108 ms 34 35 // -XX:+DoEscapeAnalysis 36 // 花費的時間為:4 ms
結果:未開啟逃逸分析
結果:開啟逃逸分析
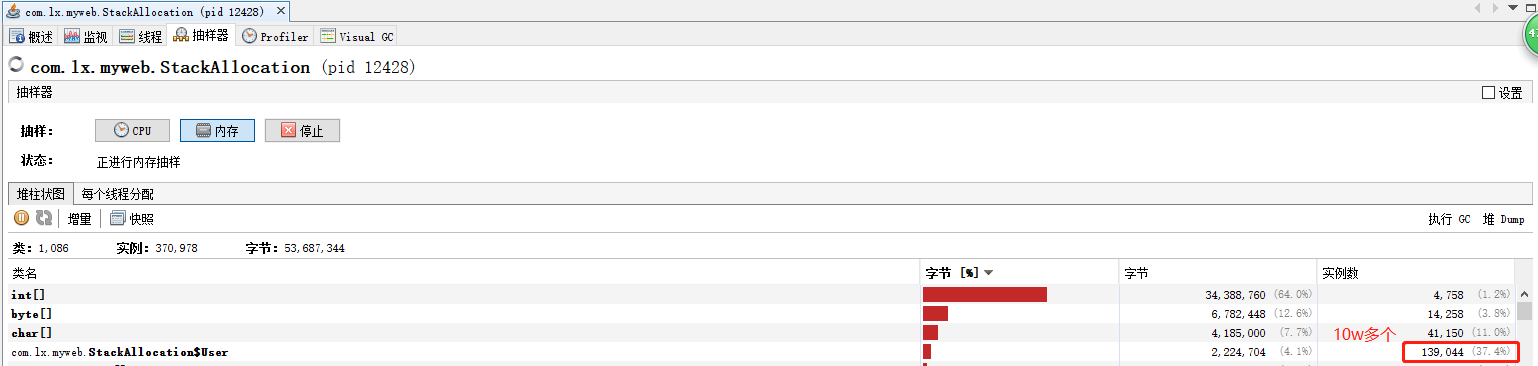
1 // -Xmx256m -Xms256m -XX:-DoEscapeAnalysis -XX:+PrintGCDetails 2 // 不開啟逃逸分析,這種情況,有GC 3 4 // -Xmx256m -Xms256m -XX:+DoEscapeAnalysis -XX:+PrintGCDetails 5 // 開啟逃逸分析,這種情況,沒有GC
4、同步省略
執行緒同步的代價是相當高的,同步的後果是降低並發性和性能。
在動態編譯同步塊的時候,JIT編譯器可以藉助逃逸分析來判斷同步塊所使用的鎖對象是否只能夠被一個執行緒訪問而沒有被發布到其他執行緒。如果沒有,那麼JIT編譯器在編譯這個同步塊的時候就會取消對這部分程式碼的同步。這樣就能大大提高並發性和性能。這個取消同步的過程就叫同步省略,也叫鎖消除。

5、標量替換
標量:指一個無法再分解成更小的數據的數據。Java中的原始數據類型就是標量。
聚合量:相對標量,還可以再分解的數據。Java中的對象就是聚合量。
標量替換:在JIT階段,如果經過逃逸分析,發現一個對象不會被外界訪問的話,那麼經過JIT優化,就會把這個對象拆解成若干個標量來代替。這個過程就是標量替換,表示允許將對象打散分配到棧上。

可以看到,Point這個聚合量經過逃逸分析後,發現它沒有逃逸,就被替換成兩個標量了。
標量替換的好處就是可以大大減少堆記憶體的佔用。因為一旦需要創建對象了,那麼就不再需要分配堆記憶體了。標量替換為棧上分配提供了很好的基礎。
程式碼示例:標量替換
1 public class Main { 2 3 public static void main(String[] args) { 4 long start = System.currentTimeMillis(); 5 6 for (int i = 0; i < 10000000; i++) { 7 alloc(); 8 } 9 10 long end = System.currentTimeMillis(); 11 System.out.println("花費的時間為: " + (end - start) + " ms"); 12 } 13 14 public static void alloc() { 15 User u = new User(); // 未發生逃逸 16 u.id = 5; 17 u.name = "www.baidu.com"; 18 } 19 20 static class User { 21 public int id; 22 public String name; 23 } 24 25 }
標量替換
結果:
1 // -Xmx100m -Xms100m -XX:+DoEscapeAnalysis -XX:+PrintGC 2 // -XX:-EliminateAllocations 3 // 一、開啟逃逸分析,不開啟標量替換,有GC 4 [GC (Allocation Failure) 25600K->784K(98304K), 0.0012734 secs] 5 [GC (Allocation Failure) 26384K->736K(98304K), 0.0031470 secs] 6 [GC (Allocation Failure) 26336K->720K(98304K), 0.0007684 secs] 7 [GC (Allocation Failure) 26320K->720K(98304K), 0.0007718 secs] 8 [GC (Allocation Failure) 26320K->720K(98304K), 0.0006689 secs] 9 [GC (Allocation Failure) 26320K->752K(101376K), 0.0007525 secs] 10 [GC (Allocation Failure) 32496K->692K(101376K), 0.0006699 secs] 11 [GC (Allocation Failure) 32436K->692K(101376K), 0.0002453 secs] 12 花費的時間為: 69 ms 13 14 // -XX:+EliminateAllocations 15 // 二、開啟逃逸分析,開啟標量替換,無GC 16 花費的時間為: 4 ms
結果
6、小結
逃逸分析並不成熟。其根本原因就是無法保證逃逸分析的性能消耗一定能高於其他的消耗。雖然經過逃逸分析可以做棧上分配、標量替換、鎖消除。但是逃逸分析自身也是需要進行一系列複雜的分析的,這其實也是一個相對耗時的過程。
一個極端的例子,就是經過逃逸分析之後,發現沒有一個對象是不逃逸的,那這個逃逸分析的過程就白白浪費了。
雖然這項技術並不十分成熟,但是它也是即時編譯器優化技術中一個十分重要的手段。
JVM會在棧上分配不會逃逸的對象,理論是可行的,但是取決於JVM設計者的選擇。據我所知,Hot Spot JVM並沒有這麼做,這一點在逃逸分析相關的文檔里已經說明,所以可以明確所有的對象實例都是創建在堆上的。
intern字元串的快取和靜態變數曾經都被分配在永久代上,而永久代已經被元空間取代。但是,intern字元串快取和靜態變數並沒有被轉移到元空間,而是在堆上分配。所以這一點同樣符合前面的結論:對象實例都是分配在堆上的。


