Apache ShardingSphere 在京東白條場景的落地之旅
- 2021 年 10 月 14 日
- 筆記
京東白條使用 Apache ShardingSphere 解決了千億數據存儲和擴容的問題,為大促活動奠定了基礎。
2014 年初,「京東白條」作為業內互聯網信用支付產品,數據量爆髮式的增長,每一次大促備戰都是對技術人員的考驗,每一次的戰略轉型驅動著數據架構的成長。
–張棟芳,京東白條研發負責人
京東白條數據架構演進史
自 2014 年 2 月京東白條業務上線起,為滿足快速發展的業務和激增的海量數據,白條的數據架構經歷了數次演進。
-
2014~2015
Solr + HBase 的方案解決了核心、非核心業務系統對關鍵資料庫的訪問問題,Solr 作為被檢索欄位的索引,HBase 用作全量的數據存儲。
-
通過 Solr 集群分擔部分讀和寫的業務,緩解核心庫的壓力;
-
Solr 擴展體驗上欠佳,對業務也存在較大的入侵。
-
2015~2016
引入 NoSQL 方案,業務數據以月份進行分表存儲在 MongoDB 集群中,階段性滿足了結算處理場景中海量數據導入導出的需求。
-
查詢熱點數據效率高,非結構化的存儲方式易於修改表結構;
-
依然面對著擴展差、對業務入侵強的局面,而且耗記憶體。
-
2016~2017
隨著業務快速發展,數據量突破百億大關,此時 MongoDB 面臨著容量和性能的雙重考驗。京東白條大數據平台通過 DBRep 以 MySQL Slave 的形式採集變動資訊並存儲到消息中心,最後落盤到 ES 和 HBase 中。
-
該方案具有較強的數據實時性,擴展性良好;
-
基於業務框架的數據分片難以降低程式碼維護成本。
白條數據架構的演進間接地反應了互聯網消費金融的飛速發展,也說明了每一種解決方案在不同背景下都有不同的保質期。
迫在眉睫的架構解耦
為保證業務系統在數據激增情況下始終能保持高效運行,技術團隊在設計初期使用了數據分片數據架構,發揮極致性能的同時也兼顧程式碼的可控性,採用基於應用框架的數據拆分方案完成了數據拆分工作。
但隨著產品升級迭代,早期的解決方案演變成為了眼前的問題,通過業務框架實現的數據分片方案導致業務程式碼複雜度增加、維護成本不斷攀升,緊耦合的弊端原形畢露,應用每次升級都需要投入較多的精力對分片做相應調整,研發人員難以專註於業務本身。
面對如上問題,技術團隊經權衡後開始考慮使用成熟的分庫分表組件來承擔這部分工作,讓業務系統升級和架構調整不再複雜。基於自研框架分片和基於 ShardingSphere 分片的對比如下:
下一階段工作,解耦。
顯然京東白條數據架構將迎來一個新的階段,解耦的驅動力可以概括如下 3 方面:
-
聚焦精力:將基於架構的資料庫拆分,交給分表組件實現,研發精力需聚焦於業務本身;
-
簡化升級:解耦技術架構,簡化業務系統升級工作的研發流程;
-
規劃未來:為系統提供良好的擴展能力,從容應對「618」和「11. 11」等活動。
京東白條業務體量巨大,是名副其實的金融級高並發、海量數據的業務場景,因此分庫分表組件應具有以下特點:
1. 產品成熟穩定
2. 極致性能表現
3. 處理海量數據
4. 架構靈活擴展
Apache ShardingSphere 解決方案
ShardingSphere-JDBC 是 Apache ShardingSphere 的第一款產品,它定位為輕量級 Java 框架,在 Java 的 JDBC 層提供的額外服務。它使用客戶端直連資料庫,以 jar 包形式提供服務,無需額外部署和依賴,可理解為增強版的 JDBC 驅動,完全兼容 JDBC 和各種 ORM 框架。
ShardingSphere-JDBC 的以下特點能夠很好地滿足白條業務場景:
-
產品成熟:經數年打磨產品成熟度高,且社區活躍;
-
性能良好:微內核、輕量化的設計,性能損耗極小;
-
改造量小:支援原生的 MySQL 協議,研發工作量小;
-
擴展靈活:搭配使用遷移同步組件輕鬆實現數據擴展。
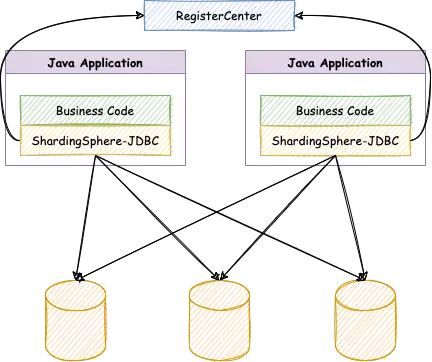
經內部大量系統性驗證之後,Apache ShardingSphere 成為了京東白條數據分片中間件的首選方案,2018 年底正式開始對接。
產品適配
為能全面支撐白條業務、提供更好的業務體驗,Apache ShardingSphere 在京東白條業務落地過程中對產品的功能和性能方面進行了更多的支援和提升,產品再一次經歷典型案例的打磨。
-
升級 SQL 引擎
白條的業務邏輯非常複雜且龐大,多樣化場景的需求對 SQL 的兼容程度有著較高要求,Apache ShardingSphere 重構了 SQL 解析模組,並支援了更多的 SQL。
- 路由至單數據節點 ,SQL 100% 兼容;
- 路由至多數據節點,可全面支援 DML、DDL、DCL、TCL 和部分 DAL。支援分頁、去重、排序、分組、聚合、關聯查詢。
-
分散式主鍵
Apache ShardingSphere 提供了內置的分散式主鍵生成器,例如 UUID、SNOWFLAKE 等分散式主鍵生成器。同時 Apache ShardingSphere 提供了分散式主鍵生成器的介面,用戶可自定義自增主鍵生成演算法來滿足特殊場景的需求。
-
業務分片鍵值注入
對於沒有分片條件的 SQL,Apache ShardingSphere 使用 ThreadLocal 管理分片鍵值,通過編程的方式向 HintManager 中添加分片條件,該分片條件僅在當前執行緒內生效,實現了 SQL 零侵入。
除了對功能上的增強,Apache ShardingSphere 為滿足京東白條業務嚴苛的性能要求,同時做了多方面調優。
-
SQL 解析結果快取
-
JDBC 元數據資訊快取
-
Bind 表 & 廣播表的使用
-
自動化執行引擎 & 流式歸併
經兩團隊通力合作,京東白條業務與 Apache ShardingSphere 相結合的各項指標滿足預期,性能與原生 JDBC 幾乎一致。
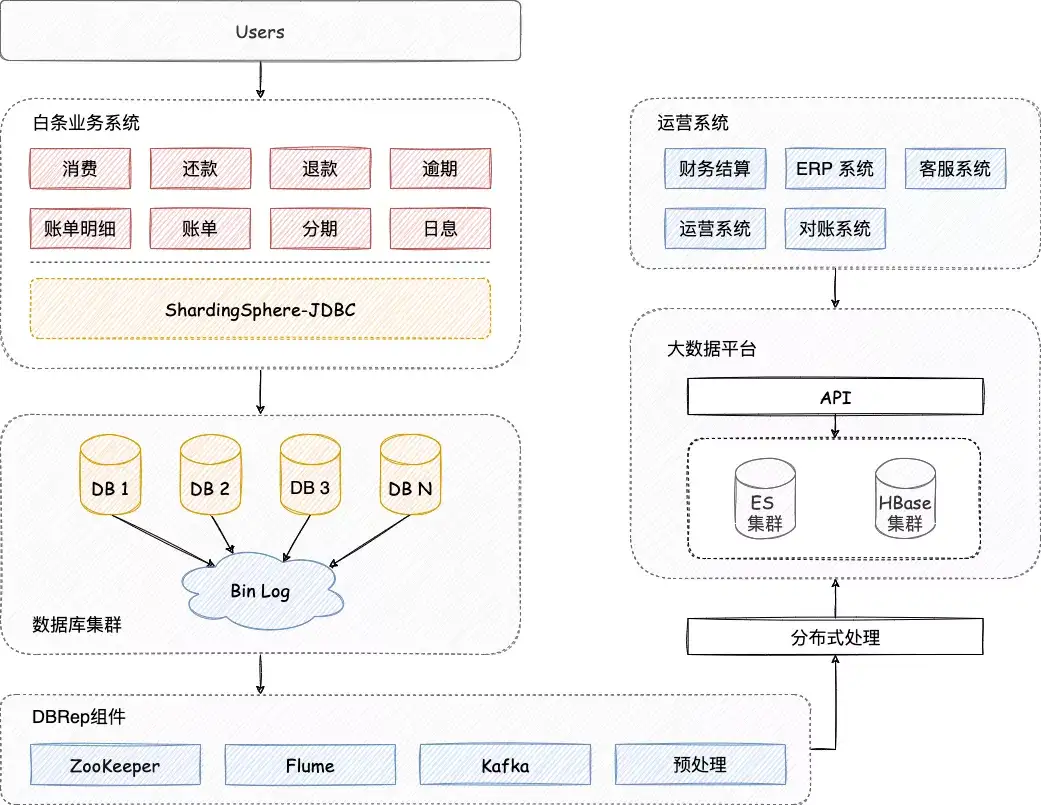
關於對接過程中的問題詳情及方案,請通過《Apache ShardingSphere 對接京東白條實戰》一文來了解。
業務割接
Apache ShardingSphere 使用訂製化 HASH 策略對數據進行分片,有效避免了熱點數據問題,拆分後的數據節點數達近萬個,整個割接過程大約持續了 4 周左右的時間。
1. DBRep 讀取數據,通過 Apache ShardingSphere 將數據同步至目標資料庫集群;
2. 兩套集群並行運行,數據遷移後再使用自研工具對業務和數據進行校驗。
DBRep 是 ShardingSphere-Scaling 產品設計的基石,Scaling 具備的自動化能力為後續的遷移擴容工作提供了更多的便利。
Apache ShardingSphere 帶來的收益
-
簡化升級路徑
通過架構解耦,業務系統升級所涉及技術棧得到有效縮短,研發團隊不再需要關注分表設計,精力全部聚焦於業務本身,升級路徑得到大幅度優化;
-
節省研發力量
引入成熟的 Apache ShardingSphere 無需重新開發分表組件,在簡化業務升級路徑的基礎上節省了大量研發力量;
-
架構靈活擴展
搭配使用 Scaling 同步遷移組件從容面對「618」和「11.11」等大型活動,系統靈活擴容。
寫在最後
京東白條業務的快速增長驅動著數據架構不斷升級,本次架構演進通過引入 Apache ShardingSphere 助力白條架構解耦,簡化了系統升級路徑,使研發團隊只需關注業務本身,同時也實現了數據架構的靈活擴展,在消費金融場景開啟了良好的開端。
互聯網信用消費模式發展逐步多樣化,未來 Apache ShardingSphere 將與京東展開更多業務場景的實踐和探索,通過推動金融科技創新發展,進一步提升互聯網金融的創新速度和效率。
ShardingSphere 作為 Apache 基金會下的頂級開源項目,在 GitHub 上獲得了超 14K Star 的關注,已成為行業內受歡迎的開源項目,全球有超過 170 家企業用戶登記使用,覆蓋金融、電子商務、雲服務、旅遊、物流、教育、文娛等多個領域。
* 歡迎更多技術團隊約稿投稿,和大家分享使用 ShardingSphere 的經驗思考。對案例感興趣的夥伴可聯繫社區經理(ss_assistant_1)或掃描下方二維碼回復「加群」進入技術交流群。

加入交流群


