Sentry 監控 – Snuba 數據中台架構(Data Model 簡介)
- 2021 年 10 月 10 日
- 筆記

系列
- 1 分鐘快速使用 Docker 上手最新版 Sentry-CLI – 創建版本
- 快速使用 Docker 上手 Sentry-CLI – 30 秒上手 Source Maps
- Sentry For React 完整接入詳解
- Sentry For Vue 完整接入詳解
- Sentry-CLI 使用詳解
- Sentry Web 性能監控 – Web Vitals
- Sentry Web 性能監控 – Metrics
- Sentry Web 性能監控 – Trends
- Sentry Web 前端監控 – 最佳實踐(官方教程)
- Sentry 後端監控 – 最佳實踐(官方教程)
- Sentry 監控 – Discover 大數據查詢分析引擎
- Sentry 監控 – Dashboards 數據可視化大屏
- Sentry 監控 – Environments 區分不同部署環境的事件數據
- Sentry 監控 – Security Policy 安全策略報告
- Sentry 監控 – Search 搜索查詢實戰
- Sentry 監控 – Alerts 告警
- Sentry 監控 – Distributed Tracing 分散式跟蹤
- Sentry 監控 – 面向全棧開發人員的分散式跟蹤 101 系列教程(一)
- Sentry 監控 – Snuba 數據中台架構簡介(Kafka+Clickhouse)
本節介紹數據在 Snuba 中的組織方式以及面向用戶的數據如何映射到底層資料庫(如: Clickhouse)。
Snuba 數據模型橫向分為邏輯模型(logical model)和物理模型(physical model)。邏輯數據模型是 Snuba 客戶端通過 Snuba 查詢語言可見的。此模型中的元素可能會也可能不會 1:1 映射到資料庫中的表。相反,物理模型將 1:1 映射到資料庫概念(如表和視圖)。
這種劃分背後的原因是,它允許 Snuba 通過邏輯數據模型公開一個穩定的介面,並在內部執行複雜的映射,對不同的表(物理模型的一部分)執行查詢,以一種對 client 透明的方式提高性能。
本節的其餘部分概述了組成兩個模型的概念以及它們如何相互連接。
下面描述的主要概念是數據集(dataset)、實體(entity)和存儲(storage)。

數據集
Dataset 是 Snuba 數據的命名空間。它提供了自己的 schema,並且在邏輯模型和物理模型方面都獨立於其他數據集。
數據集的示例是 discover(發現)、outcomes(結果)、sessions(會話)。他們之間沒有任何關係。
數據集可以看作是定義其抽象數據模型及其具體數據模型的組件的容器,如下所述。
實體和實體類型
Snuba 向客戶端公開的邏輯數據模型的基本塊(fundamental block)是實體。在邏輯模型中,實體表示抽象概念(如 transaction 或 error)的實例。在實踐中,Entity 對應於資料庫表中的一行。Entity Type 是實體的類(如 Errors 或 Transactions)。
邏輯數據模型由一組 Entity Types 及其 relationships 組成。
每個 Entity Type 都有一個 schema,該模式由具有相關抽象數據類型的欄位列表定義。 Dataset 的所有 Entity Types(可以有多個)的 schema 組成了對 Snuba client 可見的邏輯數據模型,Snuba 查詢根據該模型進行驗證。 不應該暴露較低級別的概念。
Entity Types 明確包含在 Dataset 中。一個 Entity Type 不能出現在多個數據集中。
實體類型之間的關係
數據集中的實體類型在邏輯上是相關的。支援兩種類型的關係:
- 實體集關係(
Entity Set Relationship)。這模仿了外鍵。這種關係旨在允許實體類型之間的連接。 目前它只支援一對一和一對多的關係。 - 繼承關係(
Inheritance Relationship)。這模仿了名義上的子類型(subtyping)。 一組實體類型可以共享一個父實體類型。子類型從父類型繼承schema。 從語義上講,父實體類型必須表示其類型從其繼承的所有實體的聯合。還必須能夠查詢父實體類型。這不能僅僅是一種邏輯關係。
實體類型和一致性
Entity Type 是 Snuba 可以提供一些強大的數據一致性保證的最大單元。具體來說,可以查詢期望 Serializable Consistency(可序列化的一致性) 的實體類型。這不會擴展到跨越多個實體類型的任何查詢,在這種情況下,我們最多將具有最終的一致性。
這也會對訂閱查詢(Subscription queries)產生影響。 這些一次只能對一種實體類型起作用,否則,它們將需要實體類型之間的一致性,而我們不支援這種一致性。
請注意!
準確地說,一致性單位(取決於 Entity Type)甚至可以更小,並且取決於數據攝取主題(data ingestion topics)的分區方式(例如 project_id),實體類型是 Snuba 允許的最大值。
存儲
Storage 表示並定義 Dataset 的物理數據模型。每個 Storage 表示在物理資料庫概念中具體化,如表或具體化視圖。因此,每個存儲都有一個由欄位及其類型定義的 schema,該欄位反映了 storage 映射到的 DB table/view 的物理模式,並且能夠提供生成 DDL 語句的所有詳細資訊,以在資料庫上構建表。
Storage 能夠將上面討論的邏輯模型中的邏輯概念映射到資料庫的物理概念,因此每個 Storage 都需要與一個 Entity Type 相關聯。具體來說:
- 每個
Entity Type必須由至少一個Readable Storage(我們可以在其上運行查詢的Storage)支援,但可以由多個Storage(例如預聚合物化視圖pre-aggregate materialized view)支援。每個Entity Type的多個Storage旨在允許查詢優化。 - 每個
Entity Type必須由一個且僅一個用於攝取數據和填充資料庫表的Writable Storage支援。 - 每個
Storage僅支援一種Entity Type。
示例
本節提供了一些示例,說明 Snuba data model 如何表示一些現實世界模型。
這些案例研究不一定反映當前的 Sentry production model,也不一定是同一部署的一部分。它們必須被視為孤立的例子。
單一實體數據集
這看起來像 Sentry 使用的 Outcomes 數據集。這實際上並沒有反映截至 2020 年 4 月的 Outcomes。儘管設計 Outcomes 應該朝著這個方向發展。
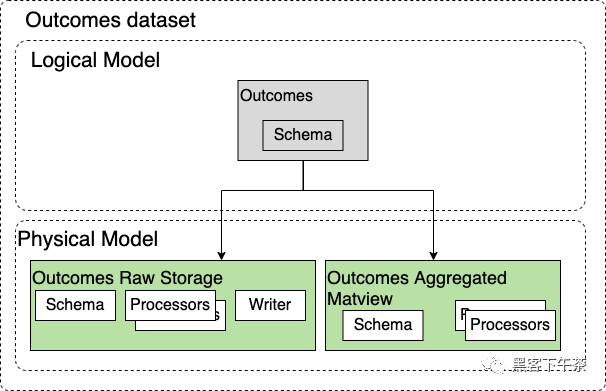
該 Dataset 只有一種 Entity Type,代表數據集攝取的單個 Outcome。查詢 raw Outcome 非常緩慢,所以我們有兩個 Storage。一個是反映我們攝取的數據的 Raw storage 和一個計算每小時聚合的 materialized view,查詢效率更高。Query Planner 將根據查詢是否可以在聚合數據上執行來選擇 storage。
多個實體類型數據集
此數據集的典型示例是 Discover 數據集。
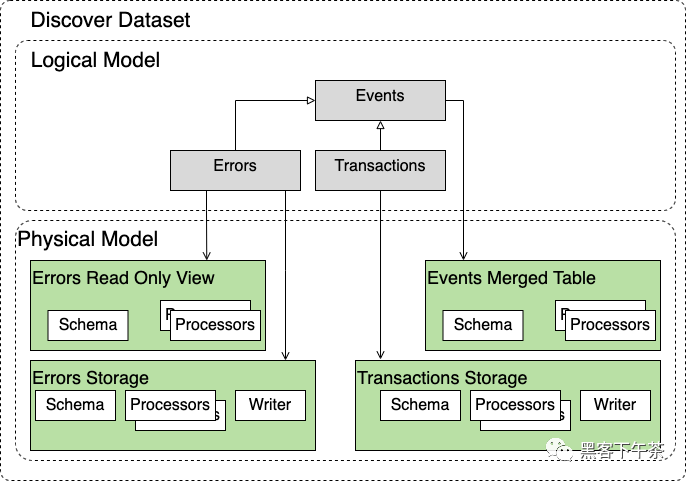
這具有三種 Entity Type。Errors、Transactions 並且它們都繼承自 Events。 這些形成了邏輯數據模型,因此查詢 Events Entity Type 給出了 Transactions 和 Errors 的聯合,但它只允許查詢中存在兩者之間的公共欄位。
出於性能原因,Errors Entity Type 由兩個 Storage 支援。 一個是用於攝取數據的主要 Errors Storage,另一個是read only view(只讀視圖),在查詢時對 Clickhosue 的負載較少,但提供較低的一致性保證。 Transactions 只有一個 storage,並且有一個 Merge Table 來為 Events 提供服務(本質上是兩個表聯合的視圖)。
連接實體類型
這是一個簡單的數據集示例,其中包含可以在查詢中連接在一起的多個實體類型。
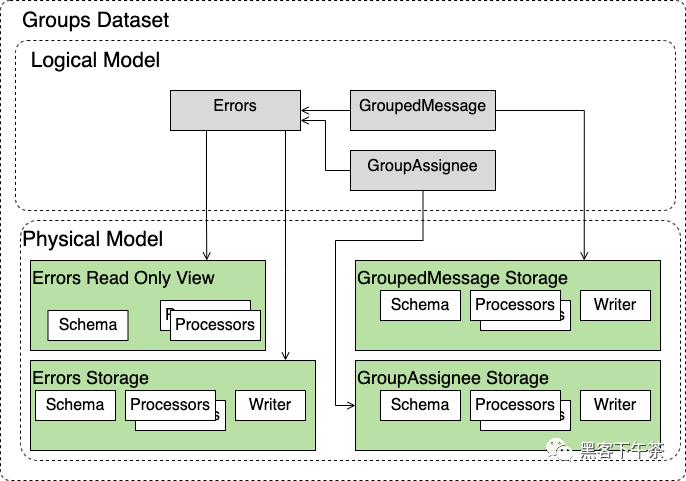
GroupedMessage 和 GroupAssingee 可以是帶有 Errors 的 left join 查詢的一部分。其餘部分與前面示例中討論的內容類似。


