我驚了!CompletableFuture居然有性能問題!
- 2021 年 10 月 9 日
- 筆記
你好呀,我是歪歪。
國慶的時候閑來無事,就隨手寫了一點之前說的比賽的程式碼,目標就是保住前 100 混個大賽的文化衫就行了。
現在還混在前 50 的隊伍裡面,穩的一比。

其實我覺得大家做柔性負載均衡那題的思路其實都不會差太多,就看誰能把關鍵的資訊收集起來並利用上了。
由於是基於 Dubbo 去做的嘛,調試的過程中,寫著寫著我看到了這個地方:
org.apache.dubbo.rpc.protocol.AbstractInvoker#waitForResultIfSync

先看我框起來的這一行程式碼,aysncResult 的裡面有有個 CompletableFuture ,它調用的是帶超時時間的 get() 方法,超時時間是 Integer.MAX_VALUE,理論上來說效果也就等同於 get() 方法了。
從我直觀上來說,這裡用 get() 方法也應該是沒有任何毛病的,甚至更好理解一點。
但是,為什麼沒有用 get() 方法呢?
其實方法上的注釋已經寫到原因了,就怕我這樣的人產生了這樣的疑問:

抓住我眼球的是這這幾個單詞:
have serious performance drop。
性能嚴重下降。
大概就是說我們必須要調用 java.util.concurrent.CompletableFuture#get(long, java.util.concurrent.TimeUnit) 而不是 get() 方法,因為 get 方法被證明會導致性能嚴重的下降。
對於 Dubbo 來說, waitForResultIfSync 方法,是主鏈路上的方法。我個人覺得保守一點說,可以說 90% 以上的請求都會走到這個方法來,阻塞等待結果。所以如果該方法如果有問題,則會影響到 Dubbo 的性能。
Dubbo 作為中間件,有可能會運行在各種不同的 JDK 版本中,對於特定的 JDK 版本來說,這個優化確實是對於性能的提升有很大的幫助。
就算不說 Dubbo ,我們用到 CompletableFuture 的時候,get() 方法也算是我們常常會用到的一個方法。
另外,這個方法的調用鏈路我可太熟悉了。
因為我兩年前寫的第一篇公眾號文章就是探討 Dubbo 的非同步化改造的,《Dubbo 2.7新特性之非同步化改造》
當年,這部分程式碼肯定不是這樣的,至少沒有這個提示。
因為如果有這個提示的話,我肯定第一次寫的時候就注意到了。
果然,我去翻了一下,雖然圖片已經很模糊了,但是還是能隱約看到,之前確實是調用的 get() 方法:
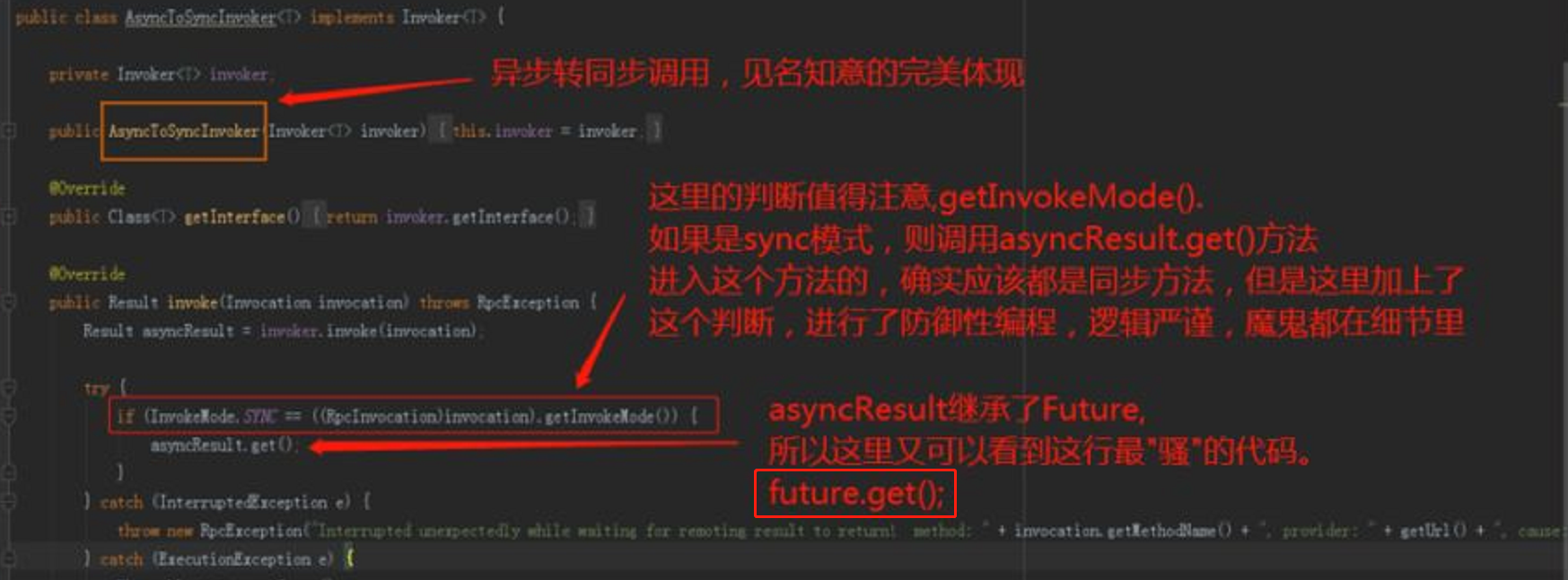
我還稱之為最「騷」的一行程式碼。
因為這一行的程式碼就是 Dubbo 非同步轉同步的關鍵程式碼。

前面只是一個引子,本文不會去寫 Dubbo 相關的知識點。
主要寫寫 CompletableFuture 的 get() 到底有啥問題。
放心,這個點面試肯定不考。只是你知道這個點後,恰好你的 JDK 版本是沒有修復之前的,寫程式碼的時候可以稍微注意一下。
學 Dubbo 在方法調用的地方加上一樣的 NOTICE,直接把逼格拉滿。等著別人問起來的時候,你再娓娓道來。
或者不經意間看到別人這樣寫的時候,輕飄飄的說一句:這裡有可能會有性能問題,可以去了解一下。

啥性能問題?
根據 Dubbo 注釋裡面的這點資訊,我也不知道啥問題,但是我知道去哪裡找問題。
這種問題肯定在 openJDK 的 bug 列表裡面記錄有案,所以第一站就是來這裡搜索一下關鍵字:
//bugs.openjdk.java.net/projects/JDK/issues/
一般來說,都是一些陳年老 BUG,需要搜索半天才能找到自己想要的資訊。
但是,這次運氣好到爆棚,彈出來的第一個就是我要找的東西,簡直是搞的我都有點不習慣了,這難道是傳說中的國慶獻禮嗎,不敢想不敢想。

標題就是:對CompletableFuture的性能改進。
裡面提到了編號為 8227019 的 BUG。
//bugs.openjdk.java.net/browse/JDK-8227019
我們一起看看這個 BUG 描述的是啥玩意。
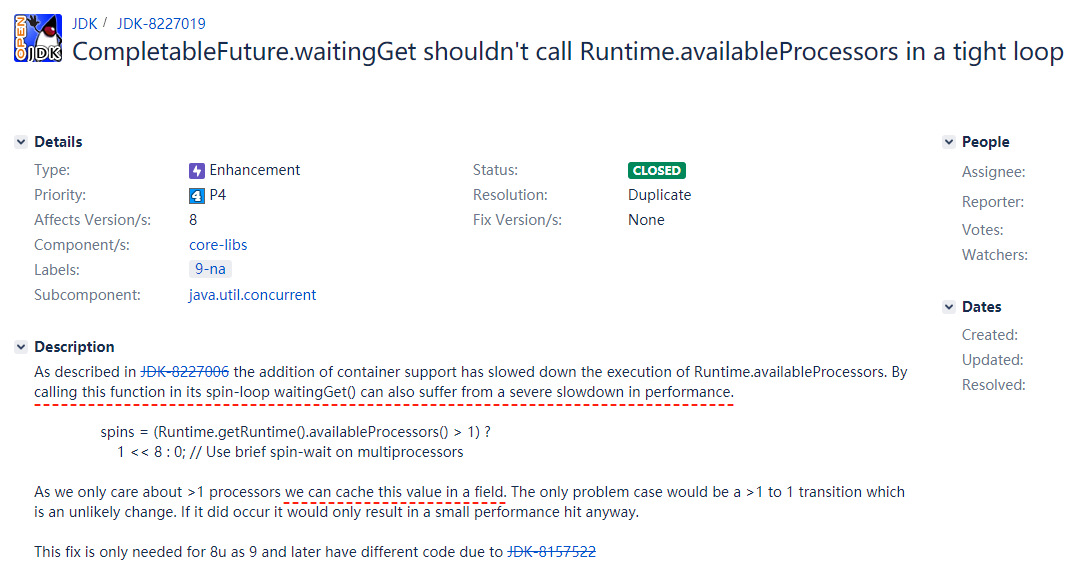
標題翻譯過來,大概意思就是說 CompletableFuture.waitingGet 方法裡面有一個循環,這個循環裡面調用了 Runtime.availableProcessors 方法。且這個方法被調用的很頻繁,這樣不好。
在詳細描述裡面,它提到了另外的一個編號為 8227006 的 BUG,這個 BUG 描述的就是為什麼頻繁調用 availableProcessors 不太好,但是這個我們先按下不表。
先研究一下他提到的這樣一行程式碼:
spins = (Runtime.getRuntime().availableProcessors() > 1) ?
1 << 8 : 0; // Use brief spin-wait on multiprocessors
他說位於 waitingGet 裡面,我們就去看看到底是怎麼回事嘛。
但是我本地的 JDK 的版本是 1.8.0_271,其 waitingGet 源碼是這樣的:
java.util.concurrent.CompletableFuture#waitingGet
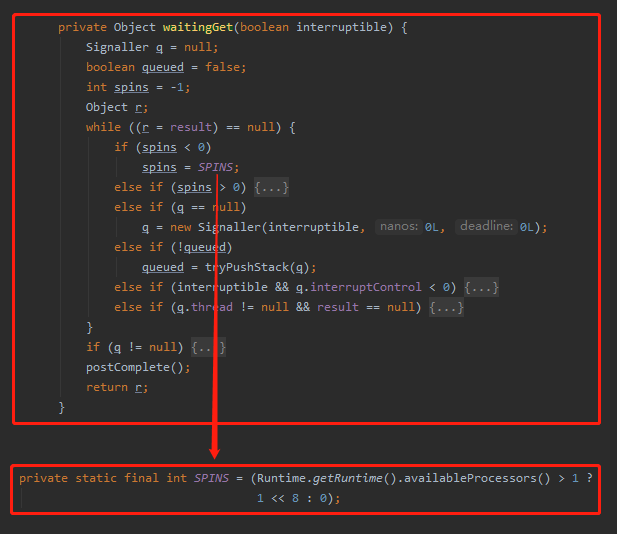
先不管這幾行程式碼是啥意思吧,反正我發現沒有看到 bug 中提到的程式碼,只看到了 spins=SPINS ,雖然 SPINS 調用了 Runtime.getRuntime().availableProcessors() 方法,但是該欄位被 static 和 final 修飾了,也就不存在 BUG 中描述的「頻繁調用」了。
於是我意識到我的版本是不對的,這應該是被修復之後的程式碼,所以去下載了幾個之前的版本。
最終在 JDK 1.8.0_202 版本中找到了這樣的程式碼:

和前面截圖的源碼的差異就在於前者多了一個 SPINS 欄位,把 Runtime.getRuntime().availableProcessors() 方法的返回快取了起來。
我一定要找到這行程式碼的原因就是要證明這樣的程式碼確實是在某些 JDK 版本中出現過。
好了,現在我們看一下 waitingGet 方法是幹啥的。
首先,調用 get() 方法的時候,如果 result 還是 null 那麼說明非同步執行緒執行的結果還沒就緒,則調用 waitingGet 方法:

而來到 waitingGet 方法,我們只關注 BUG 相關這兩個分支判斷:
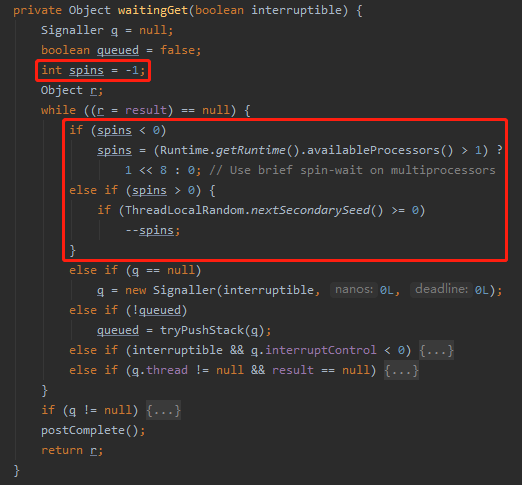
首先把 spins 的值初始化為 -1。
然後當 result 為 null 的時候,就一直進行 while 循環。
所以,如果進入循環,第一次一定會調用 availableProcessors 方法。然後發現是多處理器的運行環境,則把 spins 置為 1<<8 ,即 256。
然後再次進行循環,走入到 spins>0 的分支判斷,接著做一個隨機運算,隨機出來的值如果大於等於 0 ,則對 spins 進行減一操作。
只有減到 spins 為 0 的時候才會進入到後面的這些被我框起來的邏輯中:
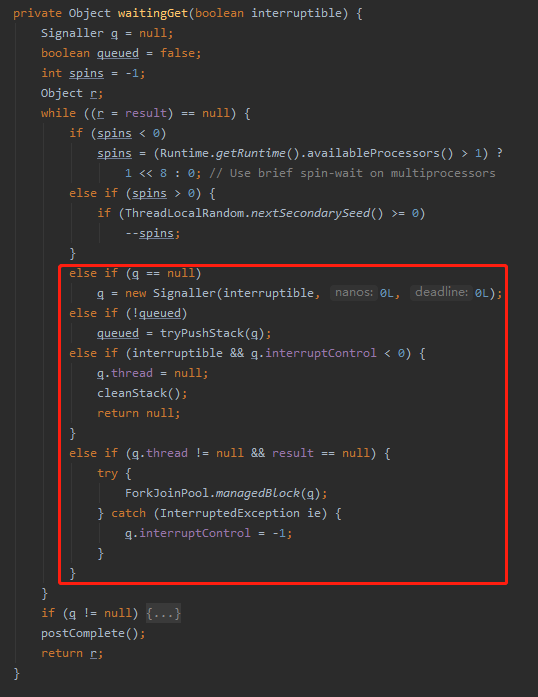
也就是說這裡就是把 spins 從 256 減到 0,且由於隨機函數的存在,循環次數一定是大於 256 次的。
但是還有一個大前提,那就是每次循環的時候都會去判斷循環條件是否還成立。即判斷 result 是否還是 null。為 null 才會繼續往下減。
所以,你說這段程式碼是在幹什麼事兒?
其實注釋上已經寫的很清楚了:

Use brief spin-wait on multiprocessors。
brief,這是一個四級辭彙哈,得記住,要考的。就是「短暫」的意思,是一個不規則動詞,其最高級是 briefest。
對了,spin 這個單詞大家應該認識吧,前面忘記給大家教單詞了,就一起講了,看小黑板:

所以注釋上說的就是:如果是多處理器,則使用短暫的自旋等待一下。
從 256 減到 0 的過程,就是這個「brief spin-wait」。
但是仔細一想,在自旋等待的這個過程中,availableProcessors 方法只是在第一次進入循環的時候調用了一次。
那為什麼說它耗費性能呢?
是的,確實是調用 get() 方法的只調用了一次,但是你架不住 get() 方法被調用的地方多啊。
就拿 Dubbo 舉例,絕大部分情況下的大家的調用方式都用的是默認的同步調用的方案。所以每一次調用都會到非同步轉同步這裡阻塞等待結果,也就說每次都會調用一次 get() 方法,即 availableProcessors 方法就會被調用一次。
那麼解決方案是什麼呢?
在前面我已經給大家看了,就是把 availableProcessors 方法的返回值找個欄位給快取起來:

但是後面跟了一個「problem」,這個「problem」就是說如果我們把多處理器這個值快取起來了,假設程式運行的過程中出現了從多處理器到單處理器的運行環境變化這個值就不準確了,雖然這是一個不太可能的變化。但是即使這個「problem」真的發生了也沒有關係,它只是會導致一個小小的性能損失。
所以就出現了前面大家看到的這樣的程式碼,這就是 「we can cache this value in a field」:
而體現到具體的程式碼變更是這樣的:
//cr.openjdk.java.net/~shade/8227018/webrev.01/src/share/classes/java/util/concurrent/CompletableFuture.java.udiff.html
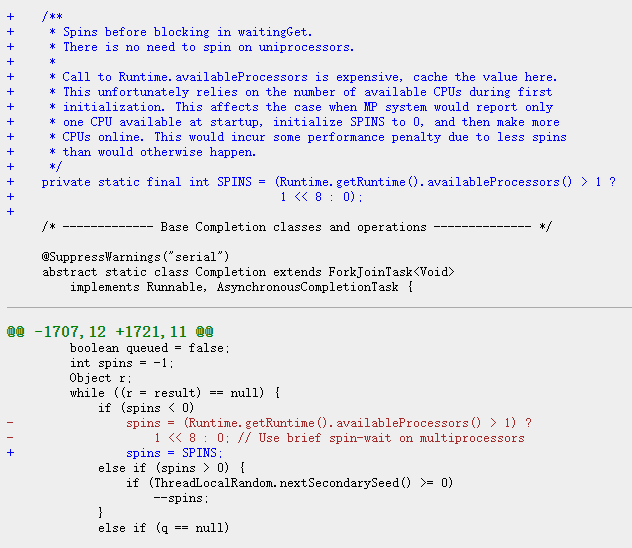
所以,當你去看這部分源碼的時候,你會看到 SPINS 欄位上其實還有很長一段話,是這樣的:

給大家翻譯一下:
1.在 waitingGet 方法中,進行阻塞操作前,進行旋轉。
2.沒有必要在單處理器上進行旋轉。
3.調用 Runtime.availableProcessors 方法的成本是很高的,所以在此快取該值。但是這個值是首次初始化時可用的 CPU 的數量。如果某系統在啟動時只有一個 CPU 可以用,那麼 SPINS 的值會被初始化為 0,即使後面再使更多的 CPU 在線,也不會發生變化。
當你有了前面的 BUG 的描述中的鋪墊之後,你就明白了為什麼這裡寫上了這麼一大段話。
有的同學就真的去翻程式碼,也許你看到的是這樣的:

什麼情況?根本就看不到 SPINS 相關的程式碼啊,這不是欺騙老實人嗎?

你別慌啊,猴急猴急的,我這不是還沒說完嘛?
我們再把目光放到圖片中的這句話上:

只需要在 JDK 8 中進行這個修復即可,因為 JDK 9 和更高版本的程式碼都不是這樣的寫的了。
比如在 JDK 9 中,直接拿掉了整個 SPINS 的邏輯,不要這個短暫的自旋等待了:
//hg.openjdk.java.net/jdk9/jdk9/jdk/rev/f3af17da360b

雖然,拿掉了這個短暫的自旋等待,但是其實也算是學習了一個騷操作。
問:怎麼在不引入時間的前提下,做出一個自旋等待的效果?
答案就是被拿掉的這段程式碼。
但是有一說一,我第一次看到這個程式碼的時候我就覺得彆扭。這一個短短的自旋能延長多少時間呢?
加入這個自旋,是為了稍晚一點執行後續邏輯中的 park 程式碼,這個稍重一點的操作。但是我覺得這個 「brief spin-wait」 的收益其實是微乎其微的。
所以我也理解為什麼後續直接把這一整坨程式碼拿掉了。而拿掉這一坨程式碼的時候,其實作者並沒有意識到這裡有 BUG。
而這裡提到的作者,其實就是 Doug Lea 老爺子。
我為什麼這樣說呢?
依據就在這個 BUG 鏈接裡面提到的編號為 8227018 的 BUG 中,它們其實描述的是同一個事情:

這裡面有這樣一段對話,出現了 David Holmes 和 Doug Lea:

Holmes 在這裡面提到了 「cache this value in a field」 的解決方案,並得到了 Doug 的同意。
Doug 說: JDK 9 已經不用 spin 了。
所以,我個人理解是 Doug 在不知道這個地方有 BUG 的情況下,拿掉了 SPIN 的邏輯。至於是出於什麼考慮,我猜測是收益確實不大,且程式碼具有一定的迷惑性。還不如拿掉之後,理解起來直觀一點。
Doug Lea 大家都耳熟能詳, David Holmes 是誰呢?
.png)
《Java 並發編程實戰》的作者之一,端茶就完事了。

而你要是對我以前的文章印象足夠深刻,那麼你會發現早在《Doug Lea在J.U.C包裡面寫的BUG又被網友發現了。》這篇文章裡面,他就已經出現過了:

老朋友又出現了,建議鐵汁們把夢幻聯動打在公屏上。
到底啥原因?
前面噼里啪啦的說了這麼大一段,核心思想其實就是 Runtime.availableProcessors 方法的調用成本高,所以在 CompletableFuture.waitingGet 方法中不應該頻繁調用這個方法。
但是 availableProcessors 為什麼調用成本就高了,依據是啥,得拿出來看看啊!
這一小節,就給大家看看依據是什麼。
依據就在這個 BUG 描述中:
//bugs.openjdk.java.net/browse/JDK-8227006
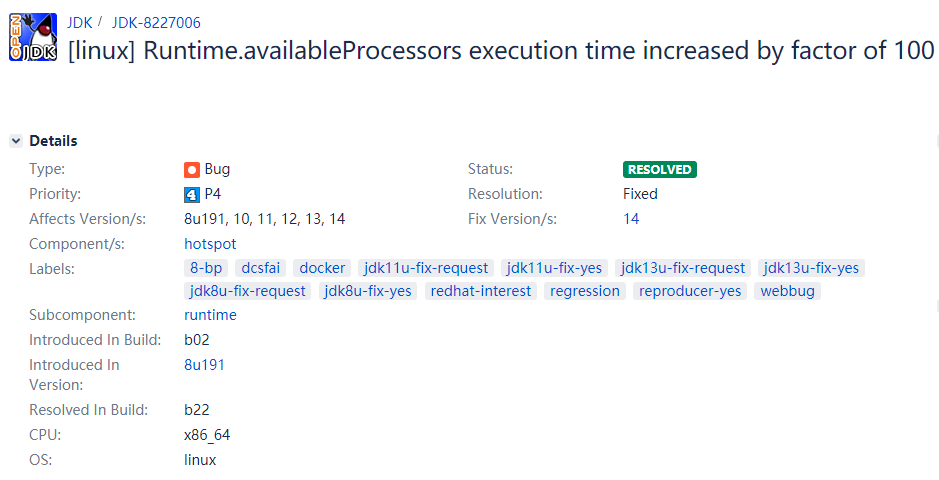
標題上說:在 linux 環境下,Runtime.availableProcessors 執行時間增加了 100 倍。
增加了 100 倍,肯定是有兩個不同的版本的對比,那麼是哪兩個版本呢?

在 1.8b191 之前的 JDK 版本上,下面的示常式序可以實現每秒 400 多萬次對 Runtime.availableProcessors 的調用。
但在 JDK build 1.8b191 和所有後來的主要和次要版本(包括11)上,它能實現的最大調用量是每秒4萬次左右,性能下降了100倍。
這就導致了 CompletableFuture.waitingGet 的性能問題,它在一個循環中調用了 Runtime.availableProcessors。因為我們的應用程式在非同步程式碼中表現出明顯的性能問題,waitingGet 就是我們最初發現問題的地方。
測試程式碼是這樣的:
public static void main(String[] args) throws Exception {
AtomicBoolean stop = new AtomicBoolean();
AtomicInteger count = new AtomicInteger();
new Thread(() -> {
while (!stop.get()) {
Runtime.getRuntime().availableProcessors();
count.incrementAndGet();
}
}).start();
try {
int lastCount = 0;
while (true) {
Thread.sleep(1000);
int thisCount = count.get();
System.out.printf("%s calls/sec%n", thisCount - lastCount);
lastCount = thisCount;
}
}
finally {
stop.set(true);
}
}
按照 BUG 提交者的描述,如果你在 64 位的 Linux 上,分別用 JDK 1.8b182 和 1.8b191 版本去跑,你會發現有近 100 倍的差異。
至於為什麼有 100 倍的性能差異,一位叫做 Fairoz Matte 的老哥說他調試了一下,定位到問題出現在調用 「OSContainer::is_containerized()」 方法的時候:
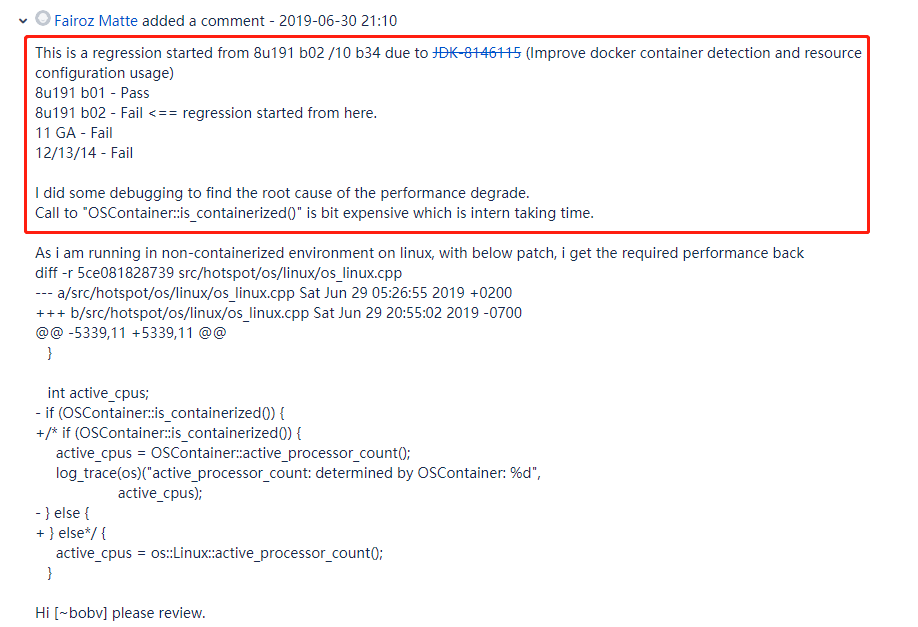
而且他也定位到了問題出現的最開始的版本號是 8u191 b02,在這個版本之後的程式碼都會有這樣的問題。
帶來問題的那次版本升級乾的事是改進 docker 容器檢測和資源配置的使用。
所以,如果你的 JDK 8 是 8u191 b02 之前的版本,且系統調用並發非常高,那麼恭喜你,有機會踩到這個坑。
然後,下面幾位大佬基於這個問題給出了很多解決方案,並針對各種解決方案進行討論。
有的解決方案,聽起來就感覺很麻煩,需要編寫很多的程式碼。
最終,大道至簡,還是選擇了實現起來比較簡單的 cache 方案,雖然這個方案也有一點瑕疵,但是出現的概率非常低且是可以接受的。

再看get方法
現在我們知道了這個沒有卵用的知識點之後,我們再看看為什麼調用帶超時時間的 get() 方法,沒有這個問題。
java.util.concurrent.CompletableFuture#get(long, java.util.concurrent.TimeUnit)
首先可以看到內部調用的方法都不一樣了:

有超時時間的 get() 方法,內部調用的是 timedGet 方法,入參就是超時時間。
點進 timedGet 方法就知道為什麼調用帶超時時間的 get() 方法沒有問題了:
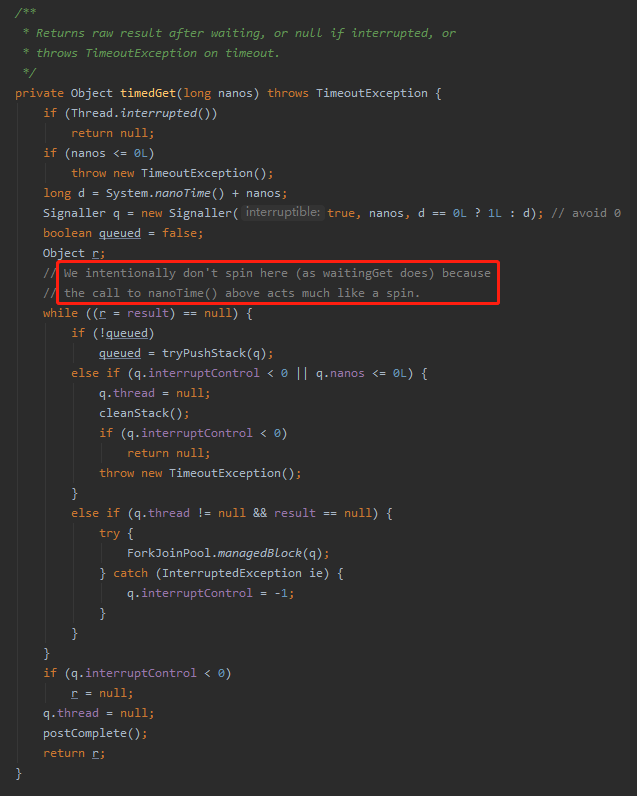
在程式碼的注釋裡面已經把答案給你寫好了:我們故意不在這裡旋轉(像waitingGet那樣),因為上面對 nanoTime() 的調用很像一個旋轉。
可以看到在該方法內部,根本就沒有對 Runtime.availableProcessors 的調用,所以也就不存在對應的問題。
現在,我們回到最開始的地方:
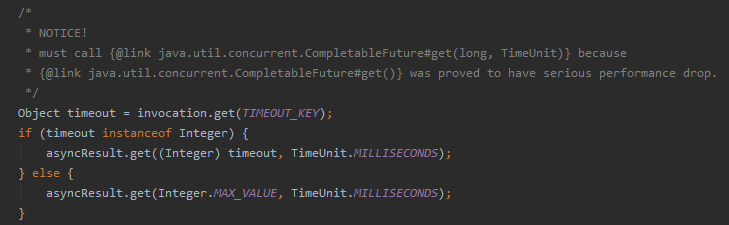
那麼你說,下面的 asyncResult.get(Integer.MAX_VALUE, TimeUnit.MILLISECONDS) 如果我們改成 asyncResult.get() 效果還是一樣的嗎?
肯定是不一樣的。
再說一次:Dubbo 作為開源的中間件,有可能會運行在各種不同的 JDK 版本中,且該方法是它主鏈路上的核心程式碼,對於特定的 JDK 版本來說,這個優化確實是對於性能的提升有很大的幫助。
所以寫中間件還是有點意思哈。
最後,再送你一個為 Dubbo 提交源碼的機會。
在其下面的這個類中:
org.apache.dubbo.rpc.AsyncRpcResult
還是存在這兩個方法:

但是上面的 get() 方法只有測試類在調用了:
完全可以把它們全部改掉調用 get(long timeout, TimeUnit unit) 方法,然後把 get() 方法直接刪除了。
我覺得肯定是能被 merge 的。
如果你想為開源項目做貢獻,熟悉一下流程,那麼這是一個不錯的小機會。




