Hive調優
Hive建表優化
1,分區,分桶 一般是按照業務日期進行分區 每天的數據放在一個分區里
2,一般使用外部表,避免數據誤刪
3,選擇適當的文件儲存格式及壓縮格式
4,命名要規範
5,數據分層,表分離,但是也不要分的太散
Hive查詢優化
分區裁剪 where過濾,
先過濾,後join 分區分桶,
合併小文件 適當的子查詢(小表全局廣播,左連是大表在左,小表在右)
order by 語句: 是全局排序
sort by 語句: 是單reduce排序
distribute by語句: 是分區欄位
cluster by語句: 可以確保類似的數據的分發到同一個reduce task中,並且保證數據有序防止所有的數據分發到同一個reduce上,導致整體的job時間延長
cluster by語句的等價語句: distribute by Word sort by Word ASC
Hive數據傾斜優化
原因:key分布不均勻,數據重複
表現:任務進度長時間維持在99%(或100%),查看任務監控頁面,發現只有少量(1個或幾個)reduce子任務未完成。因為其處理的數據量和其他reduce差異過大。單一reduce的記錄數與平均記錄數差異過大,通常可能達到3倍甚至更多。 最長時長遠大於平均時長。
解決方案:
1、從數據源頭,業務層面進行優化
2、找到key重複的具體值,進行拆分,hash。非同步求和。(增加隨機數,加鹽,可以在key後concat拼接數,最後split切分)
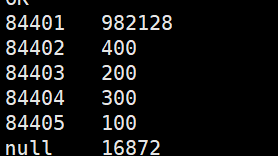
hive> select key,count(*) from data_skew group by key; (沒有優化前)
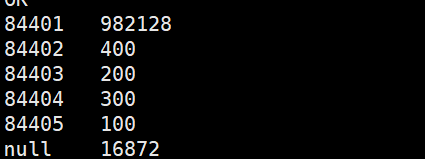
hive> select t.key,sum(t.c) from
> (select key,if(key==’84401′ or key==’null’,floor(8*rand()),0) as hash_key,count(*) as c
> from data_skew group by key,if(key==’84401′ or key==’null’,floor(8*rand()),0)) t
> group by t.key;
Hive作業優化
調整mapper和reducer的數量
太多map導致啟動產生過多開銷
按照輸入數據量大小確定reducer數目set mapred.reduce.tasks= 默認3
dfs -count /分區目錄/*
hive.exec.reducers.max設置阻止資源過度消耗
參數調節
set hive.map.aggr = true (hive2默認開啟)
Map 端部分聚合,相當於Combiner
hive.groupby.skewindata=true


