機器學習的入門指南,李宏毅2021機器學習課程知識點框架(從深度學習開始了解機器學習)
一.什麼是機器學習
在開始正式的學習之前,可能需要先了解幾個概念,機器學習(Machine Learning簡稱ML),人工智慧(Artificial Intelligence簡稱AI)和深度學習(Deeping Learning簡稱DL),人工智慧顧名思義通過人工的方式實現機器的智慧,是最終要達到的目的。據筆者所知,目前人類還沒有實現」真正」的人工智慧,即機器還沒有具有獨立思考的能力,目前的AI主要是通過一些技術使機器能夠達到人類的要求,並且看上去具有一定的智慧。機器學習是達到人工智慧的手段,讓機器通過學習達到智慧,機器學習本質上就是尋找一個函數,給定輸入的圖片,文字,語音等內容,輸出比如圖片標籤,文字涵義,語音內容等。而深度學習是機器學習的其中一種方法,近五六年以來,隨著GPU運算能力的不斷提升,深度學習相關的研究幾乎佔據了機器學習大部分內容。(因為目前ML領域的論文大多使用英語,而且有一部分術語沒有中文翻譯,為了嚴謹性之後的文章中會使用一些英文術語)
先把課程鏈接放在這裡 //www.bilibili.com/video/BV1Wv411h7kN
也可在台大官網查看全部課程相關資料 //speech.ee.ntu.edu.tw/~hylee/ml/2021-spring.html
二.基本概念
1.機器學習基本概念
機器學習主要有三類任務,分類(Classification),回歸(Regression),結構化學習(Structured Learning)
簡單定義分類與回歸 1、如果機器學習模型的輸出是離散值,讓機器去學會分類,例如布爾值,我們稱之為分類模型。2、而輸出連續值的模型,讓機器去擬合數據稱為回歸模型。
1,分類任務的衡量標準可以用準確率 2.回歸任務的衡量標準可以用方差
結構化學習:讓機器去產生有結構的內容,比如一段文字,一段語音等
機器學習的步驟,1.定義一個函數,函數的解釋詳見第一段
2.定義損失(以後稱之為loss),loss是機器預測的結果和正確結果相差多少
3.尋找最優結果(以後稱之為optimization),尋找loss最小的方法
機器學習使用的數據集種類:訓練集:訓練模型(以後稱之為model)使用的數據
驗證集:調整模型的超參數(以後稱之為hyperparameter)時用到的數據集
測試集:測試模型性能時用到的數據集
超參數:model中人為定義的參數,定義時需要一些人的經驗和知識(domain knowledge)
參數(parameter):可在model的訓練中學到的參數
2.深度學習的基本概念
深度學習的流程可能比較難以用語言描述,這個是對深度學習和反向傳播的講述比較生動和透徹的影片
神經網路的結構://www.bilibili.com/video/BV1bx411M7Zx
梯度下降法(Gradient Descent)://www.bilibili.com/video/BV1Ux411j7ri
反向傳播://www.bilibili.com/video/BV16x411V7Qg
分段線性(piecewise linear):任何一段都是線性的分段函數,可以近似擬合任何曲線
獨熱向量(one-hot vector):向量中只有一個1,剩下都是0
激勵函數(activate function):添加在每層網路後面,使網路可以擬合非線性函數,兩個ReLU 神經元的線性疊加即可擬合博雷爾可測函數(不知道也不重要),採用ReLU的神經網路,對於擬合解決實際問題中常見的函數來說是綽綽有餘了
為什麼引入非線性激勵函數? 如果不用激勵函數(其實相當於激勵函數是f(x) = x),在這種情況下你每一層輸出都是上層輸入的線性函數,很容易驗證,無論你神經網路有多少層,輸出都是輸入的線性組合,與沒有隱藏層效果相當,這種情況就是最原始的感知機(Perceptron)了。因此我們決定引入非線性函數作為激勵函數,這樣深層神經網路就有意義了(不再是輸入的線性組合)。最早的想法是sigmoid函數或者tanh函數,輸出有界,很容易充當下一層輸入。
為什麼引入Relu? 第一,採用sigmoid等函數,算激活函數時(指數運算),計算量大,反向傳播求誤差梯度時,求導涉及除法,計算量相對大,而採用Relu激活函數,整個過程的計算量節省很多。 第二,對於深層網路,sigmoid函數反向傳播時,很容易就會出現梯度消失的情況(在sigmoid接近飽和區時,變換太緩慢,導數趨於0,這種情況會造成資訊丟失,從而無法完成深層網路的訓練。第三,Relu會使一部分神經元的輸出為0,這樣就造成了網路的稀疏性,並且減少了參數的相互依存關係,緩解了過擬合問題的發生。
3.其他的一些概念
token的定義:直譯做令牌或記號,在句子中是人為定義的用來進行操作的基本單位,在漢語一個token一般是一個character,一個方塊字,在英語中可以是一個單詞或一個字母
BOS:begin of sentence,句首標識符,一種special token
EOS:end of sentence,句尾標識符,一種special token
SOTA:state of the art,最先進的,一般指新提出的模型超越以往的模型
4.深度學習任務攻略
課件原圖:
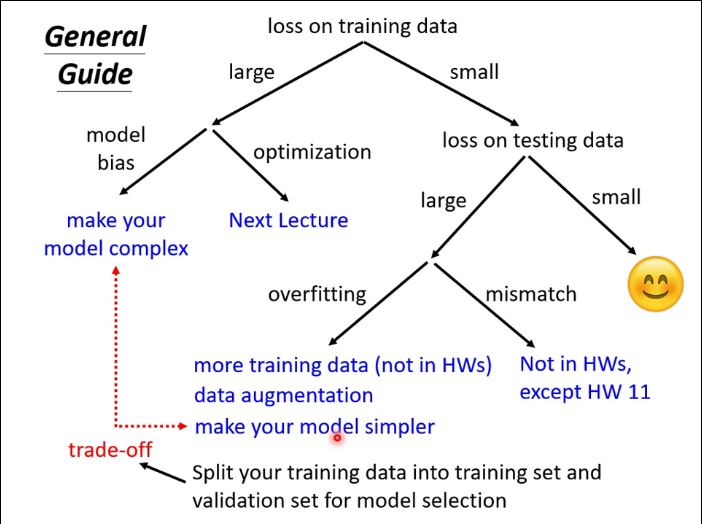
model bias:模型偏差,模型過於簡單導致擬合能力太弱
optimazation issue:梯度下降進入critical point(稍後解釋)
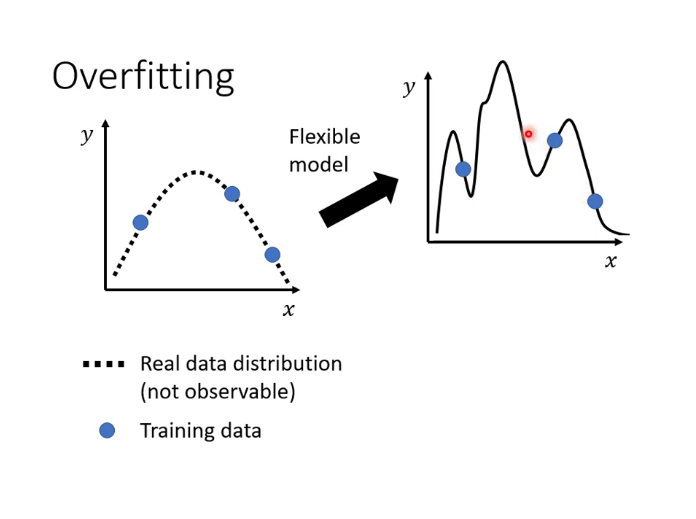
over fitting:過擬合,如圖
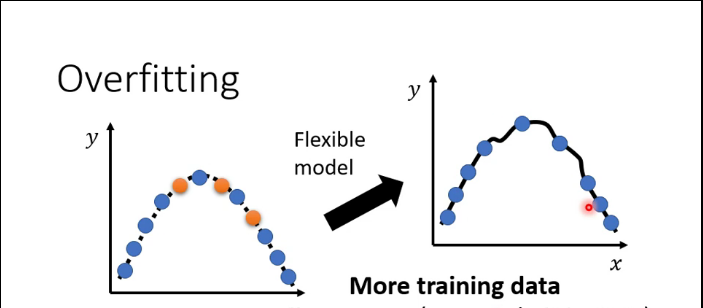
mismatch:誤配,測試集和訓練集的數據分布(distribution)不一致,需要用到domain adaptation/transfer learning(後面會解釋)
4.類神經網路中的一些概念
critical point:包含local minima(局部最小)和saddle point(鞍點),在loss的超平面中,梯度下降時可能會陷入這樣的點從而無法繼續優化,可以使用黑塞矩陣來判斷error surface某一點附近的地貌。
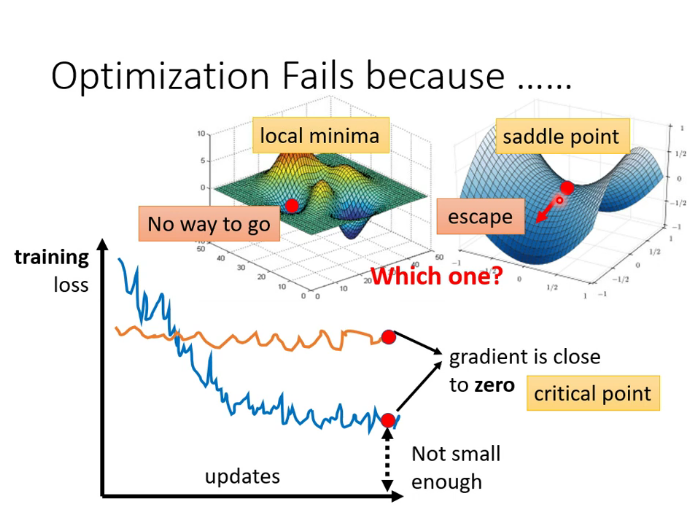
在實際應用中,這樣的情況其實不易出現。我們在三維空間中的error surface是一個二維的平面,可以走的方向非常有限。但一般的DL項目中,參數可能幾百維甚至上萬維,可走的路非常多,所以critical point的情況不易出現。
batch:執行一次梯度下降所用的數據,數據集大小稱之為batch size,pytorch讀取數據就是以batch讀入的
epoch:所有數據集訓練一次為一個epoch,執行20個epoch即每個數據都要用來訓練20次
iteration:一個epoch中以讀取了多少個batch
batch size * iteration = size of data set
批量梯度下降(Batch Gradient Descent,BGD):批量梯度下降法是最原始的形式,它是指在每一次迭代時使用所有樣本來進行梯度的更新,即iteration=1。
隨機梯度下降(Stochastic Gradient Descent,SGD):隨機梯度下降法不同於批量梯度下降,隨機梯度下降是每次迭代使用一個樣本來對參數進行更新。使得訓練速度加快,即batch size=1.
小批量梯度下降(Mini-Batch Gradient Descent, MBGD):小批量梯度下降,是對批量梯度下降以及隨機梯度下降的一個折中辦法。其思想是:每次迭代使用 batch_size個樣本來對參數進行更新。
BGD的並行效果好,一個batch里很多組數據可以做並行的運算,但train的效果不好
SGD的並行效果不好,每個batch只有一組數據,只能一個batch接一個batch的運算,但train的效果好
為什麼BGD和SGD訓練效果會有這樣的差異,說法有很多種,我個人更相信large batch 容易overfitting這個解釋。此外,還有說法是BGD更容易被卡在critical point。還有第三種說法如圖,large batch更容易陷入sharp minima,這也是一個亟待研究的課題。
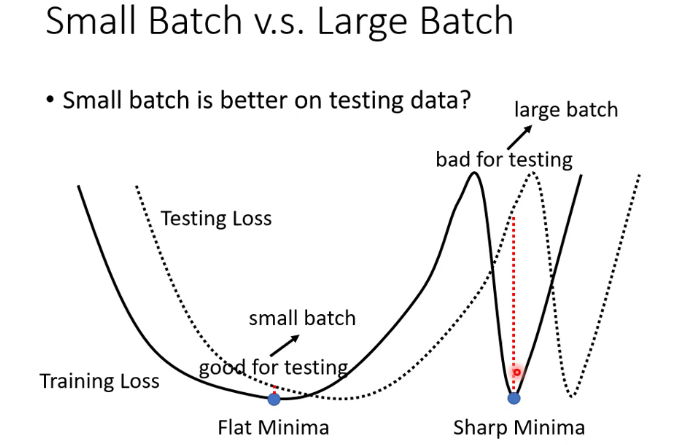
因此,MBGD是一個折衷的方法,也是目前最常用的方法。
動量(Momentum):選定梯度下降的方向時把之前的梯度也考慮進去,這樣就更容易「衝過」critical point
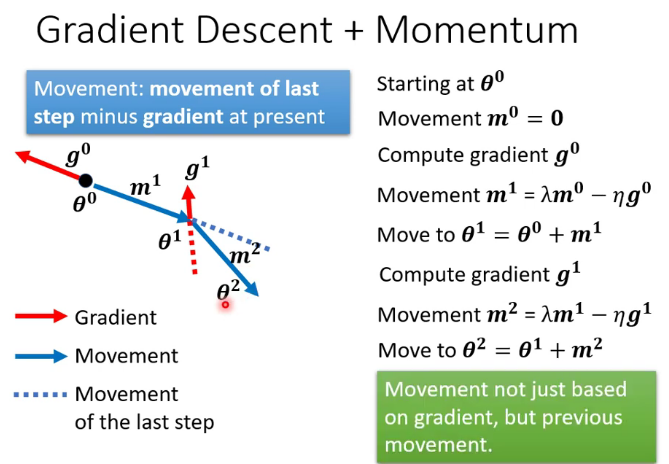
自適應學習率(Adaptive learning rate):固定的學習率會導致梯度大的時候步長過大,梯度小的時候步長太小甚至出現在有限的運算中不收斂的狀況,自適應學習率的演算法比如RMSprop可以解決這個問題。
Adam演算法就是RMSprop+Momentum
softmax:
假設我們有一個數組,V,Vi表示V中的第i個元素,那麼這個元素的Softmax值就是
也就是說,是該元素的指數,與所有元素指數和的比值。這個函數可以把一個數組所有的數都按照一定比例映射到[0,1]
loss函數的種類:
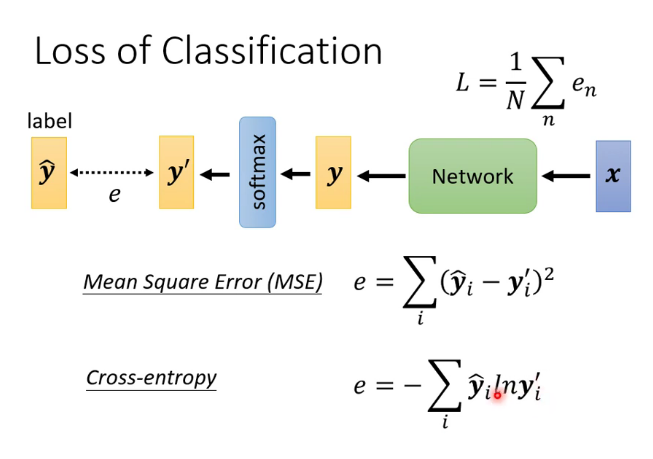
在某些情況下交叉熵(cross-entropy)具有與mse相同的global minima,但是error surface更加平滑,常使用在分類任務里。
批次標準化(batch normalization):使error surface更加平滑的一種方法,讓不同維度的數據 數值範圍更加接近。(softmax是縱向,batch normalization是橫向)
feature normalization是對數據集中所有數據進行操作,但GPU的memory有限,所以只對一個batch的數據進行操作,就是batch normalization
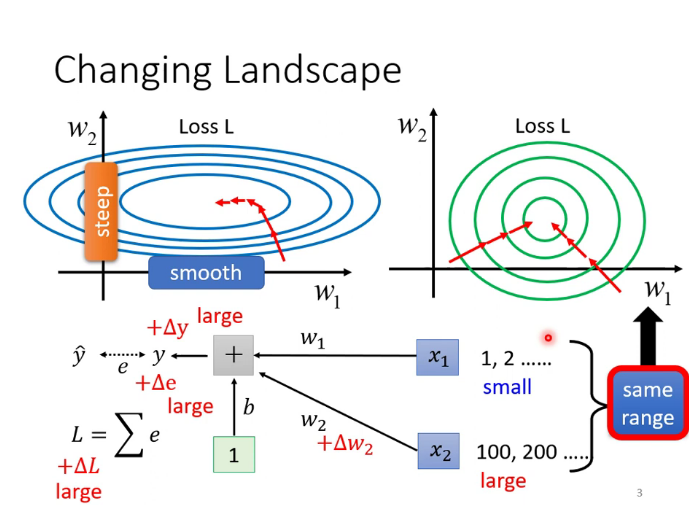
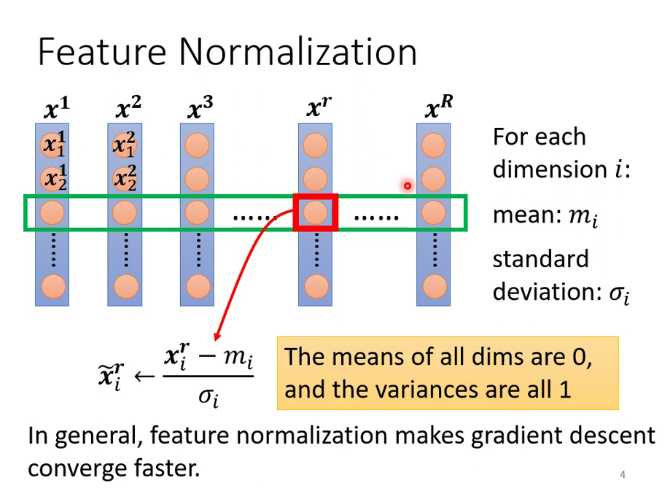
在testing時,數據往往不是以batch的形式輸入進來的,那如何計算均值和方差呢?pytorch中是這樣實現的,把training時的均值和方差加權計算儲存起來,testing時就用這個儲存的數。
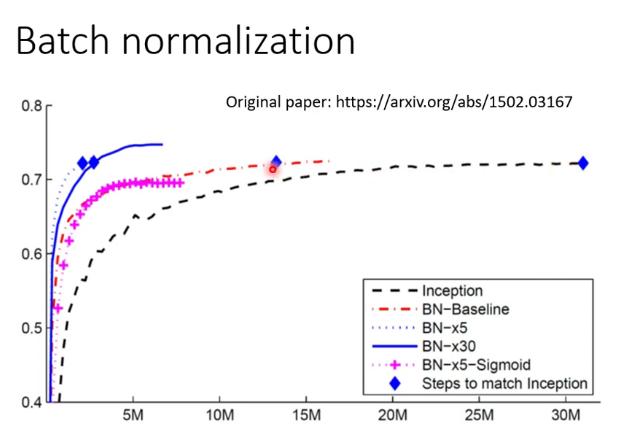
上圖可知,經過batch normalization處理的演算法有更快的收斂速度,但只要時間足夠長,是否batch normalization能達到幾乎一樣的accuracy
三.卷積神經網路(Convolutional Neural Networks, 簡稱CNN)
1.電腦是如何處理圖片的
把圖片變為向量
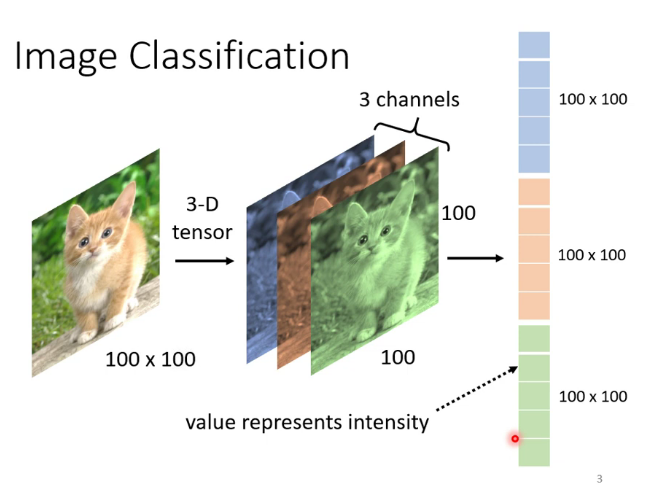
為什麼需要CNN:因為對於圖片來說,不是每一個像素(pixel)都與其他像素聯繫起來都能產生資訊,比如貓的嘴附近的一些像素可以構成貓臉的一部分,但貓的嘴和後面的樹沒有任何關係。而且對於影像這樣大的向量,做Fully connected network需要耗費大量計算資源。因此就產生了CNN。
2.CNN是如何做的
每個neural只接收上一層部分neural的輸出
先定義幾個符號:
深度(depth) : 顧名思義,它控制輸出單元的深度,也就是filter的個數,連接同一塊區域的神經元個數。又名:depth column
步幅(stride):它控制在同一深度的相鄰兩個隱含單元,與他們相連接的輸入區域的距離。如果步幅很小(比如 stride = 1)的話,相鄰隱含單元的輸入區域的重疊部分會很多; 步幅很大則重疊區域變少。
補零(zero-padding) : 我們可以通過在輸入單元周圍補零來改變輸入單元整體大小,從而控制輸出單元的空間大小。
感受野(receptive field):一個neural的所攝的範圍
這是一個一維的例子,左邊模型輸入單元有5個,左右邊界各補了一個零,步幅是1,感受野是3,因為每個輸出隱藏單元連接3個輸入單元,右邊那個模型是把步幅變為2,其餘不變。
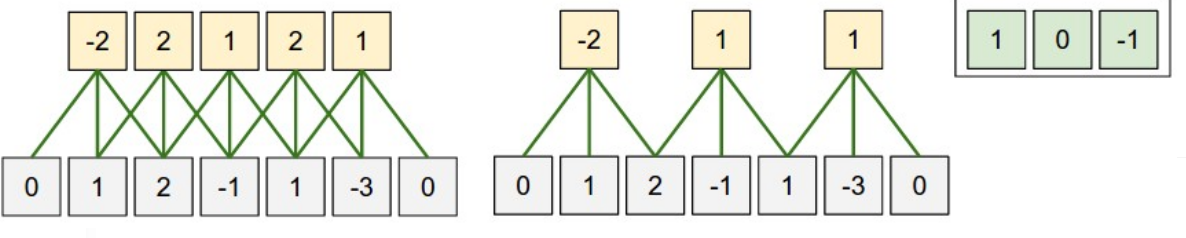
在二維中就是這樣
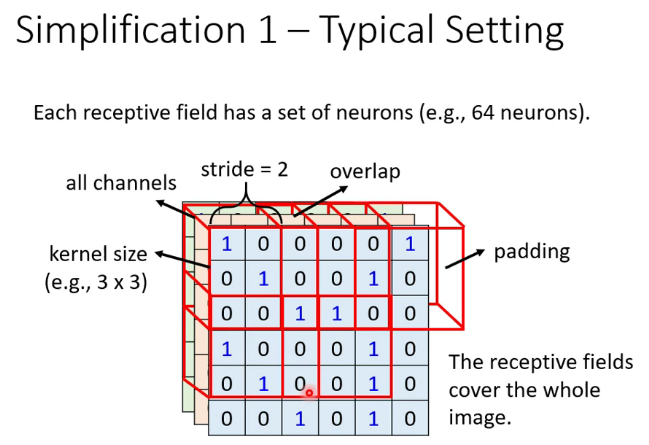
池化(pooling):用於壓縮向量大小。在卷積層進行特徵提取後,輸出的特徵圖會被傳遞至池化層進行特徵選擇和資訊過濾。池化層包含預設定的池化函數,其功能是將特徵圖中單個點的結果替換為其相鄰區域的特徵圖統計量。池化層選取池化區域與卷積核掃描特徵圖步驟相同,由池化大小、步長和填充控制。
隨著當前GPU計算能力的提升,很多CNN現在都不使用池化層。比如圍棋AI阿爾法狗就沒有pooling layer。
常用的pooling方法比如max pooling,每個範圍(比如2*2)保留一個最大值,這也是subsampling(子取樣)的一種
四.自注意力機制(Self-attention)
1.兩種任務
關於seq2seq
機器翻譯是一種典型的sequence to sequence的任務,即輸入是一個隊列,輸出也是一個隊列,可以簡稱seq2seq,那麼一個句子是如何用數字來表示的呢?
關於詞的表示這裡介紹了兩種方法
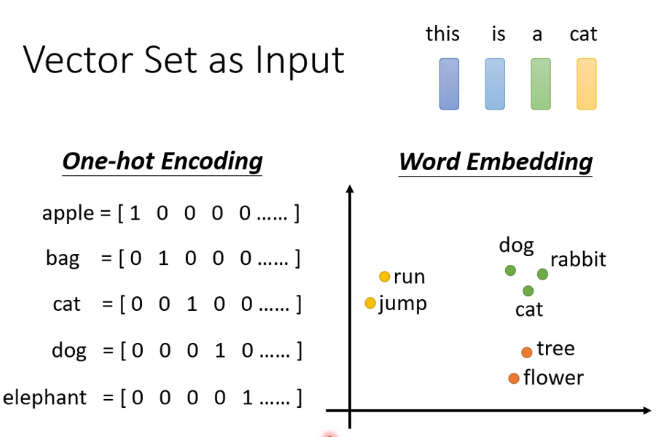
其中one -hot encoding不包含任何的語義諮詢,比如貓和狗的關係應該比貓和汽車的關係更近。而且這種表示方法需要的維度很高,比如有八萬個漢字,表示其中就需要一個八萬維的向量。但是這種方法容易理解,也比較簡單。
word embedding 一般可以用auto-coder來生成(之後介紹)
關於Sequence Labeling(序列標註)
詞性標註就是一種sequence labeling任務,即輸入是一個隊列,輸出是一串標籤,給定一個句子,為句子中的每個詞標註詞性,這就涉及到了為什麼需要Self-attention:舉一個簡單的例子I saw a saw.翻譯成中文是「我看見了一個鋸子」,那麼如何讓機器分辨第一個saw和第二個saw的詞性差別呢,這是就需要聯繫上下文,使用自注意力機制
2.self-attention
自注意力機制有很多種,常見的比如有dot-product attention和additive attention,接下來介紹最常見的一種,也是用在transformer里的方法,dot-product attention(點積型注意力機制)
**節選自某乎的解釋**,動畫影片詳見 //www.bilibili.com/video/BV1Wv411h7kN?p=23
設一個句子的長度為S,單詞embedding空間的維度為D,那麼一個句子就會被編碼為一個大小為 的矩陣。使用三個大小為
的權重矩陣
與之相乘,會得到為三個大小為
的編碼矩陣
。
代表query,
代表key,
代表value,自注意力機制就圍繞著這三個矩陣展開的,具體公式如下:
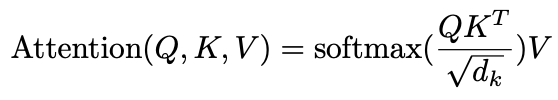
其中 正是注意力中最為重要的交互步驟:
代表著需要編碼的詞的資訊,
代表著句子中其它詞的資訊,相乘後得到句子中其它詞的權重值;
代表著每個位置單詞蘊含的語義資訊,在被加權求和後作為待編碼詞的編碼。我們會發現,此時的注意力機制將輸入矩陣編碼成大小為
的矩陣。所謂多頭注意力機制,就是將n個這樣得到的編碼進行拼接,得到大小為
(其中
的個數為
)的矩陣。在原文中,
的結果剛好等於
,兩者不相等也沒有關係,因為其後還有一個
矩陣,用於將編碼從
維轉化為
維。
3.基於self-attention的改進
(1)以上介紹的編碼方式里沒有位置的資訊,如果需要位置資訊可以使用positional encoding的方法,在詞向量中加入positional vector,這個是handcrafted的。
(2)當輸入的向量過長時,attention matrix可能會過大導致難以計算,這是可以用truncated self-attention,讓每個詞只注意它周圍的幾個詞,而不是整個輸入的篇章。
(3)muti-head self-attention多頭自注意力模型,有多個
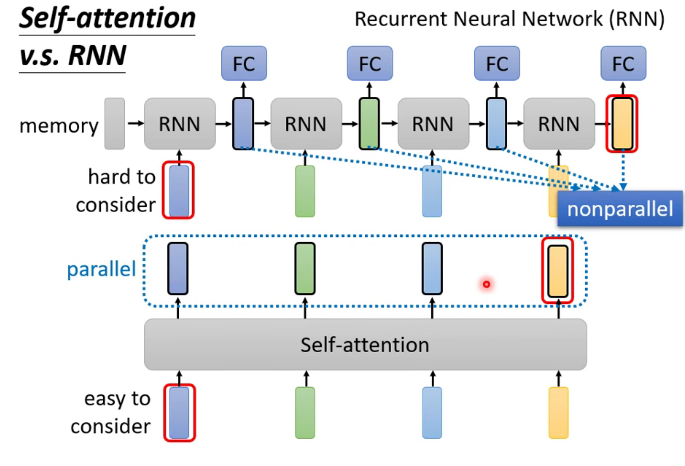
4.其他網路和self-attention的聯繫
CNN實際上是self-attention的特例

RNN(循環神經網路)可以被self-attention所代替
五.transformer
1. 模型結構
模型結構如下圖:
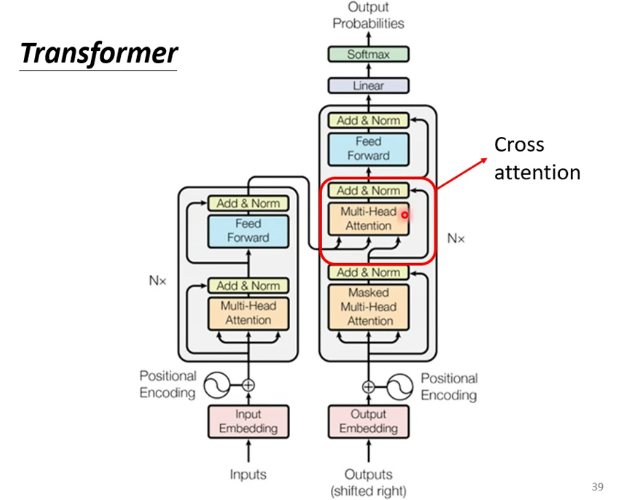
和大多數seq2seq模型一樣,transformer的結構也是由encoder和decoder組成。
2.Encoder
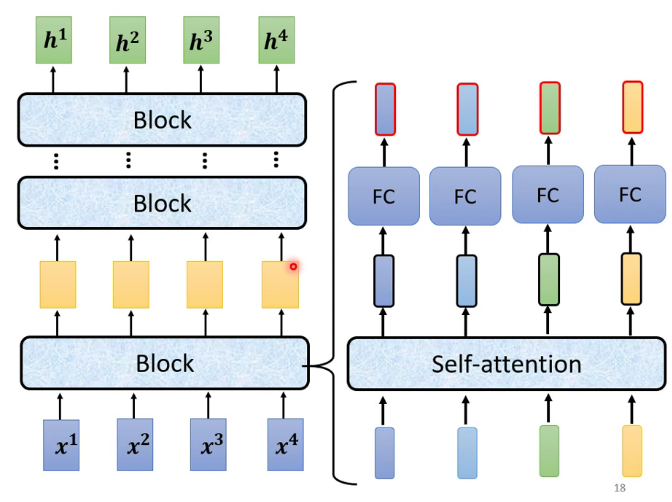
最簡單的encoder模型,由許多block組成,每個block是一個self-attention的結構
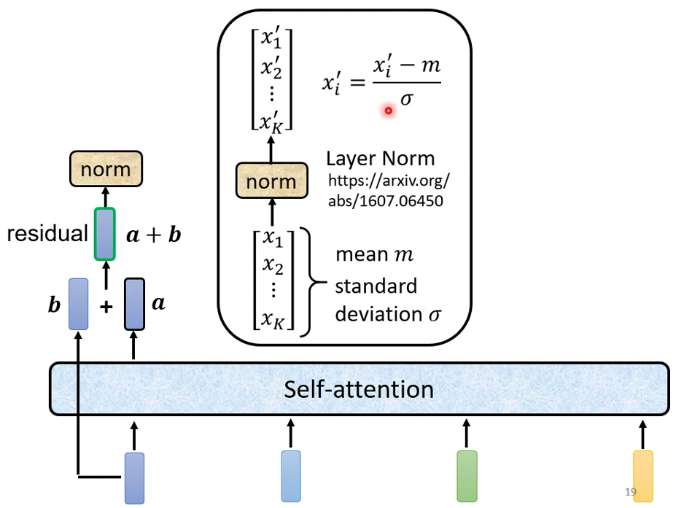
殘差連接和標準化:殘差連接是把輸入加到輸出上。標準化類似於softmax,也是針對一個向量的計算
3.Decoder
前面的輸出當作後面的輸入,進行多少個循環由機器自己決定
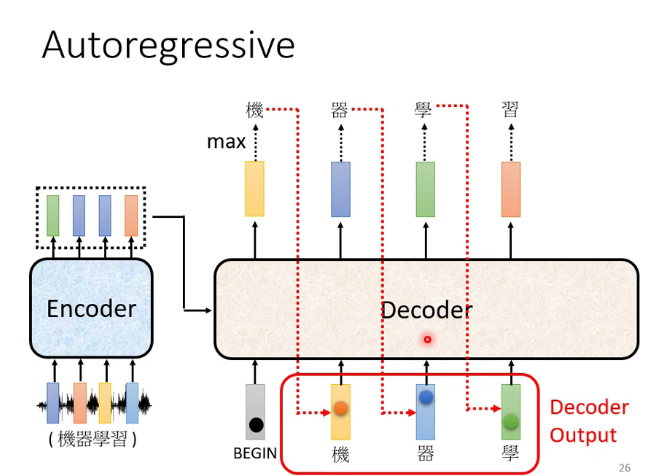
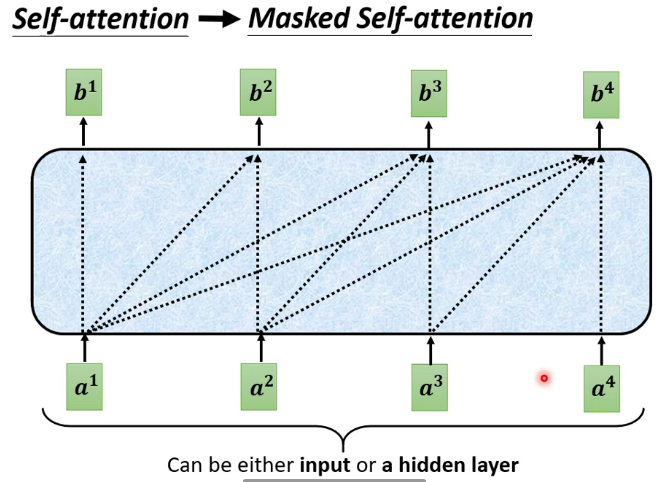
其中的masked self-attention:每個詞只能注意到出現在它之前的詞
Error propagation問題:前面的錯誤輸出導致後面的輸入也是錯的,一直錯下去,一步錯,步步錯
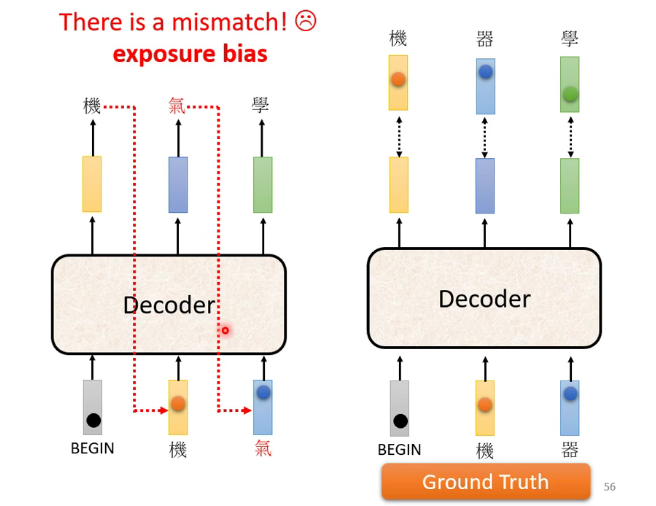
解決的辦法可以是訓練時就給機器看一些錯誤的資料
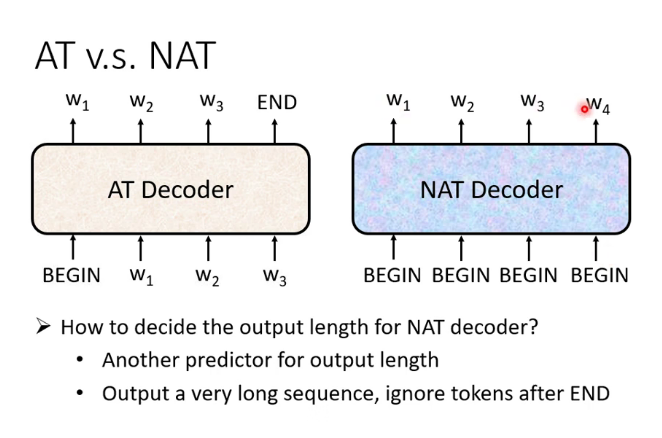
自回歸(Autoregression簡稱AR)和非自回歸(Non-Autoregression簡稱NAR)的Decoder:(這裡的T是translation的意思)
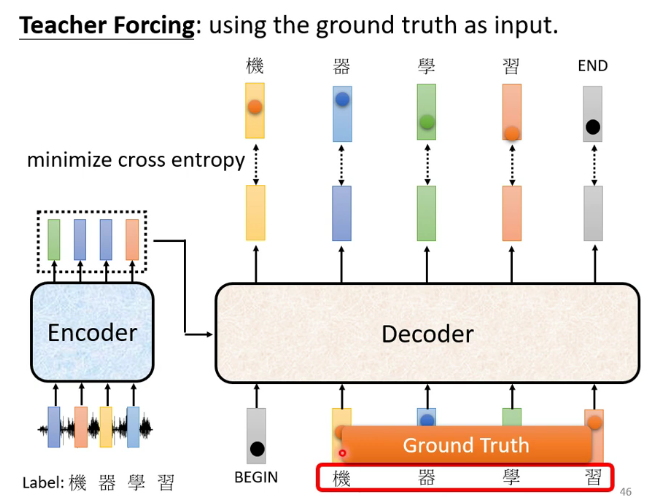
Decoder的訓練:
六.生成式對抗網路(Generative Adversarial Networks 簡稱GAN)
1.為什麼需要GAN
(1)有些網路需要一定的隨機性,比如去讓機器學著去玩電子遊戲,以人類玩這個電子遊戲的操作作為訓練集,而人類在遇到相同的環境時可能會進行不同的決策,而這些決策都是對的,比如向左轉或者向右轉,把這些操作都給機器學的時候機器可能會作出一些奇怪的決策,因此這類的機器學習任務需要一定的隨機性,隨機向左轉或向右轉。
(2)有些網路需要有一定的創新能力,創新也是隨機的
2.GAN的原理
首先大家都知道 GAN 有兩個網路,一個是 generator,一個是 discriminator,從二人零和博弈中受啟發,通過兩個網路互相對抗來達到最好的生成效果。流程如下:

主要流程類似上面這個圖。首先,有一個一代的 generator,它能生成一些很差的圖片,然後有一個一代的 discriminator,它能準確的把生成的圖片,和真實的圖片分類,簡而言之,這個 discriminator 就是一個二分類器,對生成的圖片輸出 0,對真實的圖片輸出 1。
接著,開始訓練出二代的 generator,它能生成稍好一點的圖片,能夠讓一代的 discriminator 認為這些生成的圖片是真實的圖片。然後會訓練出一個二代的 discriminator,它能準確的識別出真實的圖片,和二代 generator 生成的圖片。以此類推,會有三代,四代。。。n 代的 generator 和 discriminator,最後 discriminator 無法分辨生成的圖片和真實圖片,這個網路就擬合了。
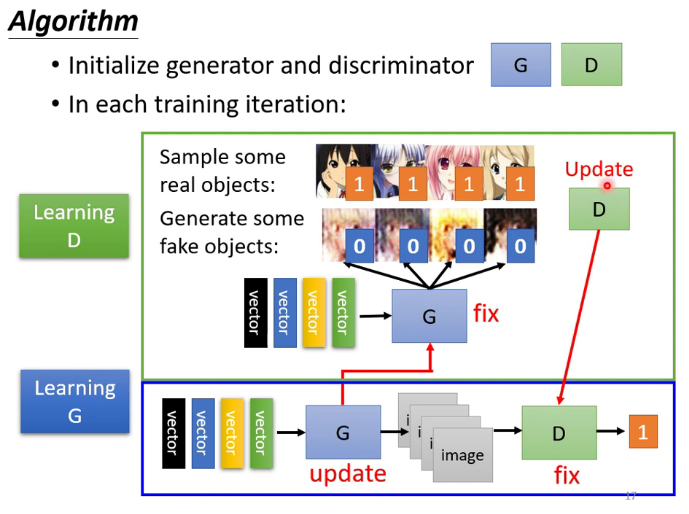
需要注意的是generator也需要輸入的向量,只不過向量是隨機的,以下是一段generator的程式碼

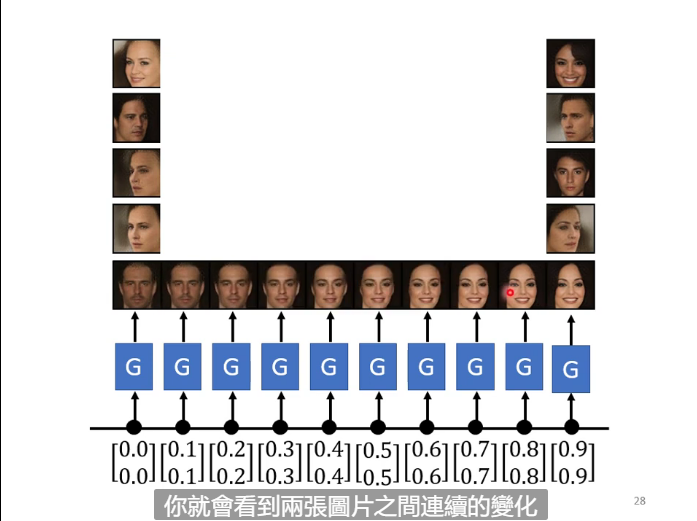
GAN也可以用來生成一段漸變的影像
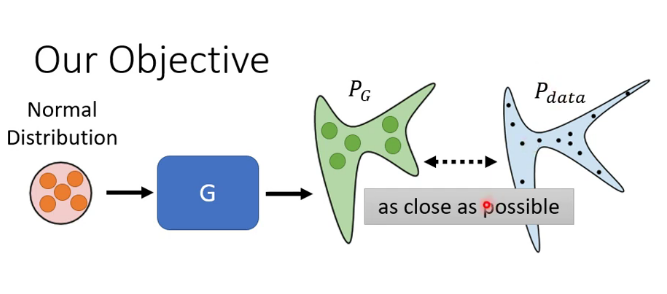
GAN的目標
3.GAN裡面的問題
因為GAN實際上是一個很難train的模型,所以經常會出現各種問題。比如:


4.cycle GAN
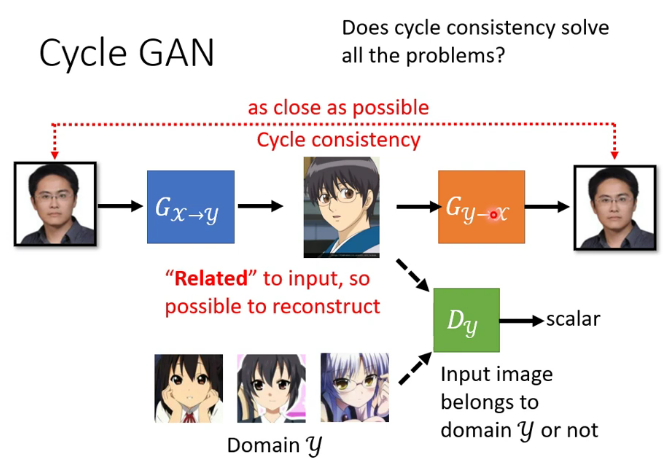
但cycle GAN會不會學到一些奇怪的准換,比如藍色的G把眼鏡轉換為一顆痣,橙色的G再把痣轉換為眼鏡,但這樣的情況不太容易出現,因為G這個network很「懶惰」,不太容易出現相似度差別比較大的結果,甚至有時不加那個橙色的G也能產生很好的結果。
七.BERT
1.監督學習,無監督,半監督,自監督
(1)首先比較監督和無監督學習,其最主要的區別在於模型在訓練時是否需要人工標註的標籤資訊。
監督學習利用大量的標註數據來訓練模型,模型的預測和數據的真實標籤產生損失後進行反向傳播,通過不斷的學習,最終可以獲得識別新樣本的能力。
無監督學習不依賴任何標籤值,通過對數據內在特徵的挖掘,找到樣本間的關係,比如聚類相關的任務。
(2)半監督學習在訓練階段結合了大量未標記的數據和少量標籤數據。與使用所有標籤數據的模型相比,使用訓練集的訓練模型在訓練時可以更為準確,而且訓練成本更低。
(3)和其他無監督學習不同,自監督學習主要是利用輔助任務(pretext)從大規模的無監督數據中挖掘自身的監督資訊,通過這種構造的監督資訊對網路進行訓練,從而可以學習到對下游任務有價值的表徵。換句話說自監督學習的監督資訊不是人工標註的,而是演算法在大規模無監督數據中自動構造監督資訊,來進行監督學習或訓練。自監督學習比如訓練機器做填空等。
2.BERT和自監督學習
BERT在pretrain階段使用了自監督方法
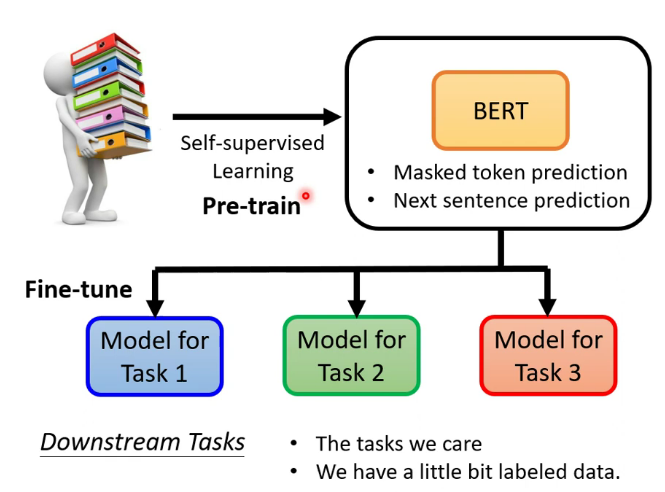
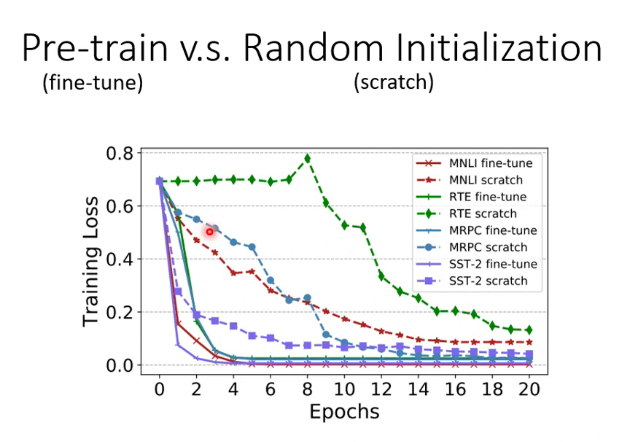
Bert的pretrain通常是以transformer的encoder為架構,最終的fine-tune可以較快降低loss的原因可能是pretrain的參數確實適合下游任務,也可能是pretrain的參數就適合於這種大型訓練
評判pretrain模型性能的方法:在語言處理上的公認標準:GLUE,包括七個待fine-tune的任務,用這些任務上的表現來評判

在其它類型的任務上目前還沒有公認標準
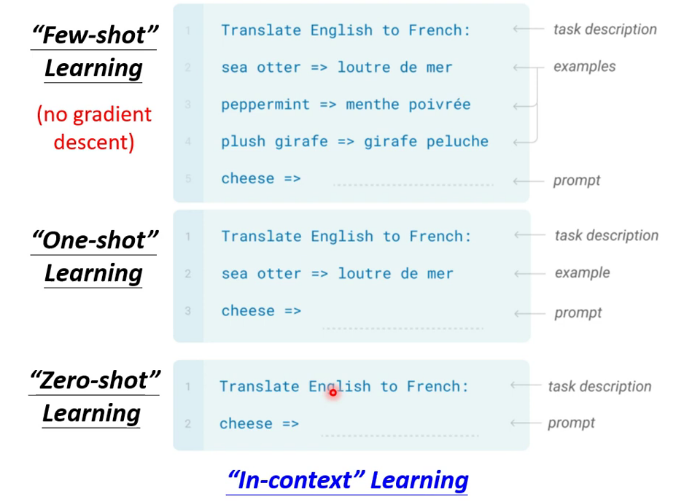
3.Few-shot Learning
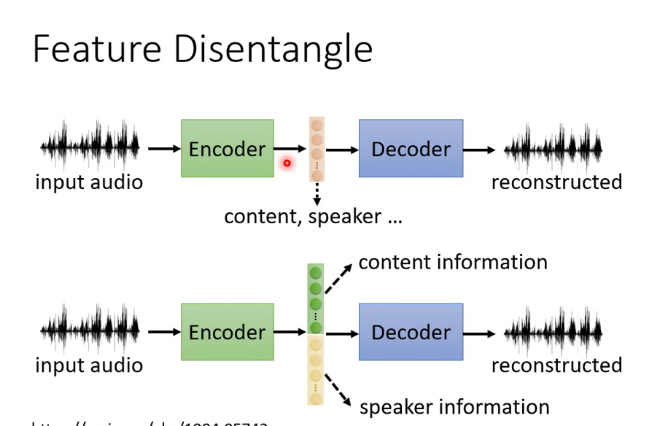
八.自編碼器(Auto-encoder)
1.什麼是自編碼器
類似於cycle GAN,可用於dimension reduction
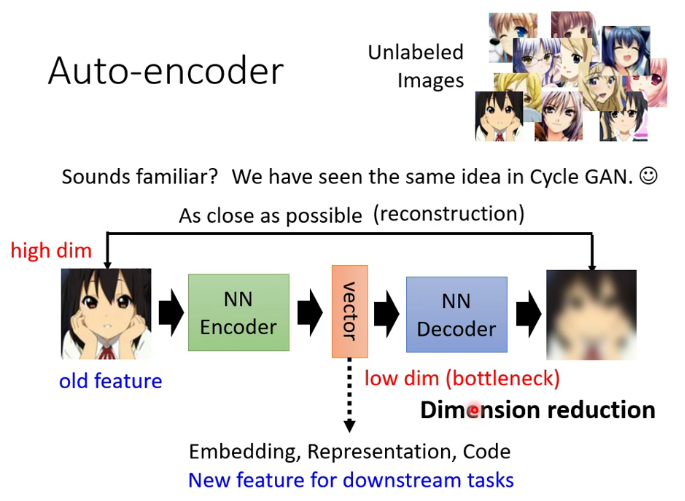
Discrete Representation
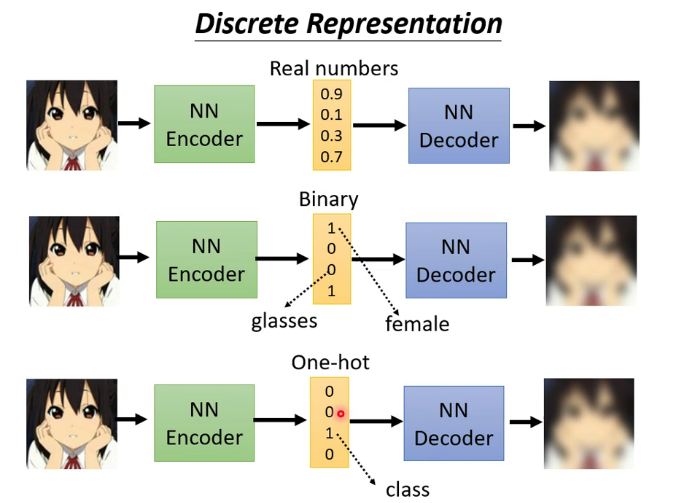
其中最後一個表示方法可以達到無監督聚類的效果
2.自編碼器應用
(1)decoder部分可以被看作一個generator
(2)異常檢測:根據能否重構來判斷這個輸入的數據是不是訓練時見過的類型
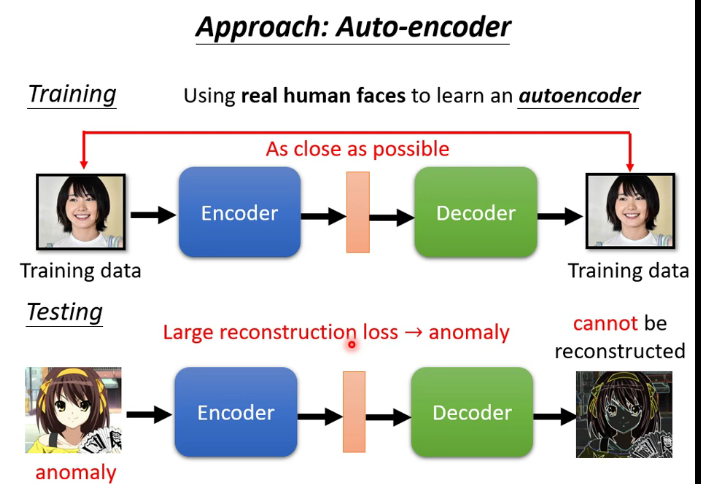
九.Adversarial Attack
1.來自人類的惡意攻擊
通過在圖片中加一點雜訊,讓圖片產生誤判,最佳效果是Non-perceivable,即人類無法感知到,但機器可以

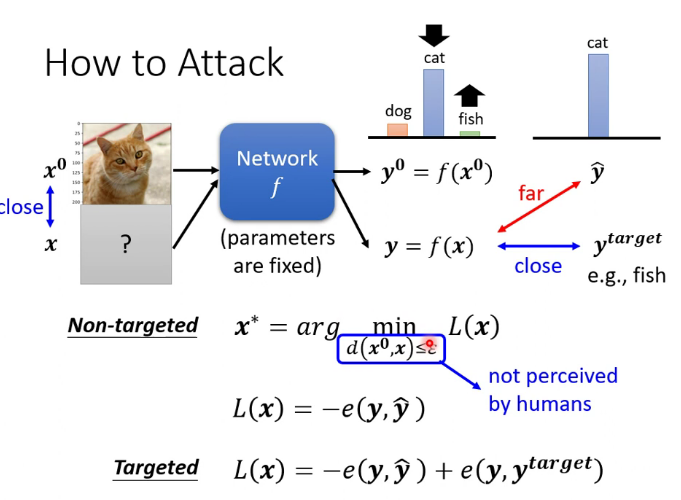
2.最簡單的攻擊方法:FGSM
只進行一次調整

3.黑箱攻擊和白箱攻擊
白箱攻擊:已知網路的內部結構進行攻擊
黑箱攻擊:未知網路的內部結構進行攻擊
已知訓練集時可以使用代理網路攻擊:
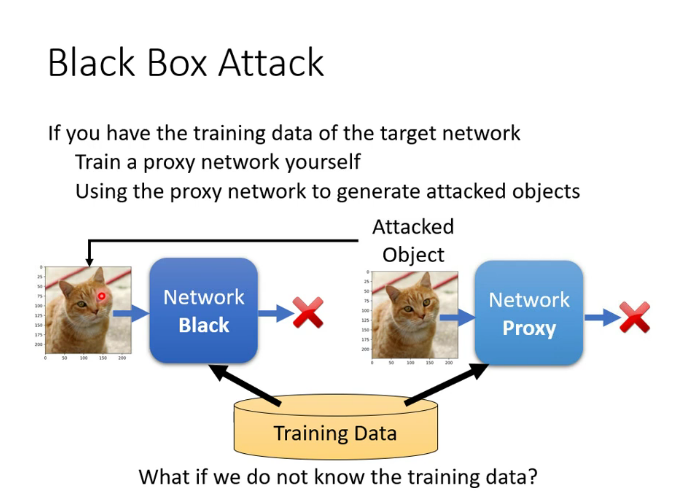
未知訓練集時,可以向目標網路輸入大量數據,再把輸出和輸入構成一個集合訓練代理網路
4.其他有趣的應用
寄生:
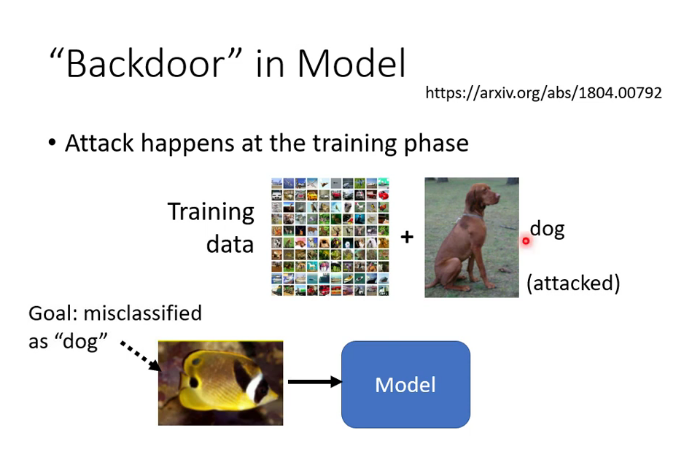
後門:
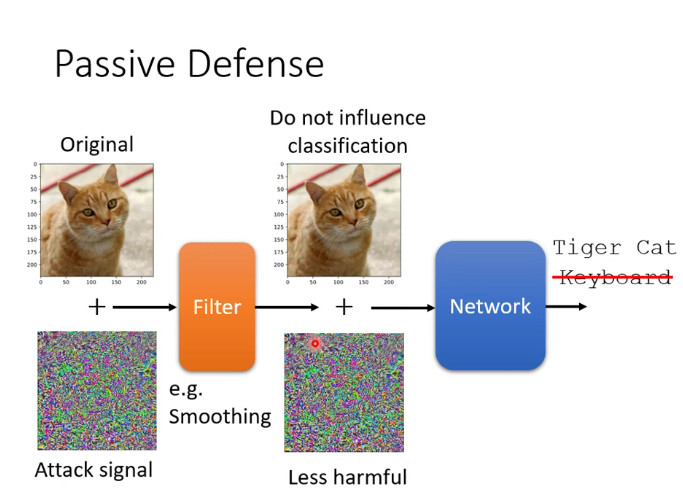
5.防禦攻擊
(1)被動防禦:比如使圖片模糊化(但如果在攻擊中把模糊化考慮為network中的一層,就會失去作用)
在網路中加入隨機的一層(不讓別人知道我出什麼招的最好辦法就是我自己都不知道我接下來要出什麼招)
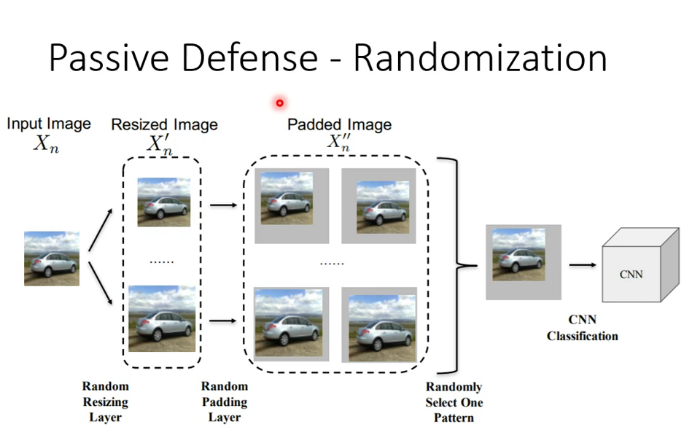
(2)主動防禦:在訓練階段加入攻擊資料

十.可解釋性
1.為什麼需要可解釋性
當我們在DL中調整了一大堆hyperparameter,我們可能需要理解機器在幹什麼,機器是否真正的理解了任務,如果模型具備了可解釋性,之後在當DL犯錯時,我們可能會更有效地找到它為什麼犯錯,錯在什麼地方。但可解釋性只是作為DL模型眾多指標中的一個,況且可解釋性也沒有一個公認的量化評判標準,如果僅僅因為可解釋性就拋棄一個表現良好的模型,無異於削足適履,因噎廢食。
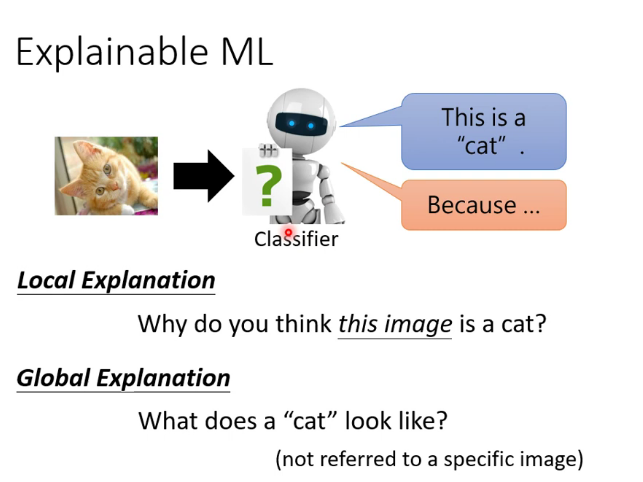
2.可解釋性的分類
3.解釋模型的技術
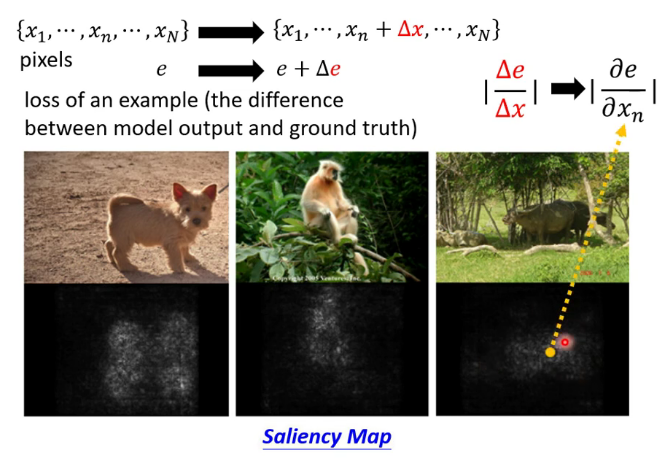
(1)製作顯著性圖

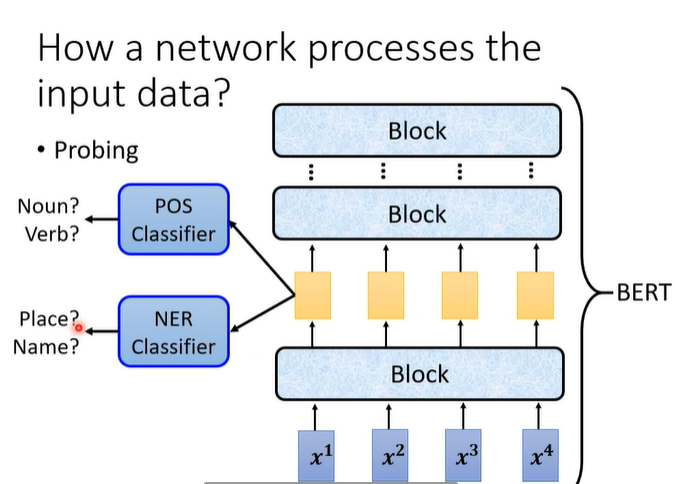
(2)probing
(3)一種global explaination技術
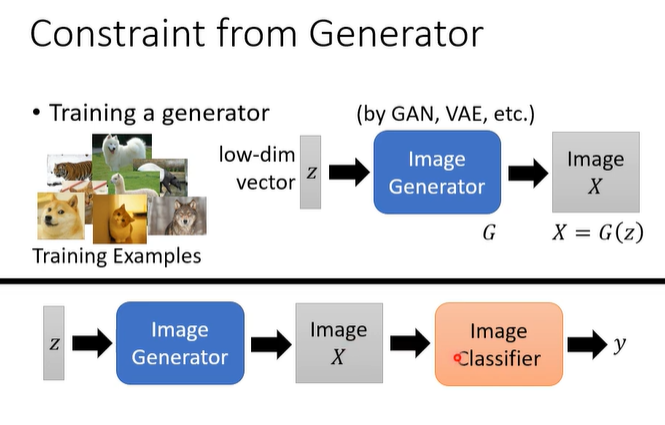
十一.領域自適應(Domain adaption)
1.概念
Domain shift:訓練集和測試集有不同的分布,類似於前面的mismatch
Domain adaption就是解決Domain shift的問題
2.兩種最簡單的情況
(1)待適應領域的數據集有少量labeled data:直接用這些數據做fine-tune
(2)有大量無標註數據:
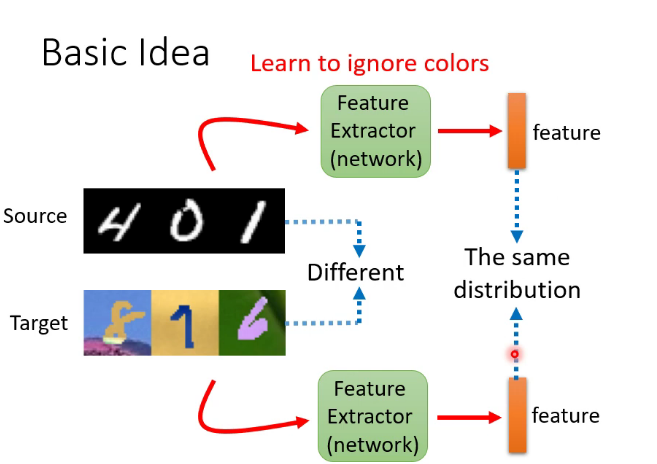
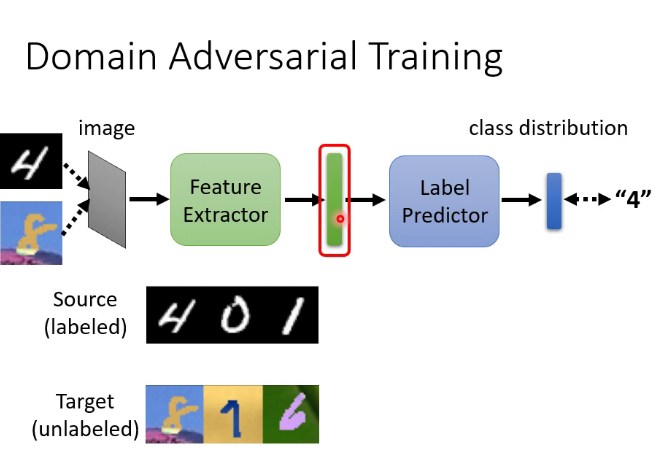
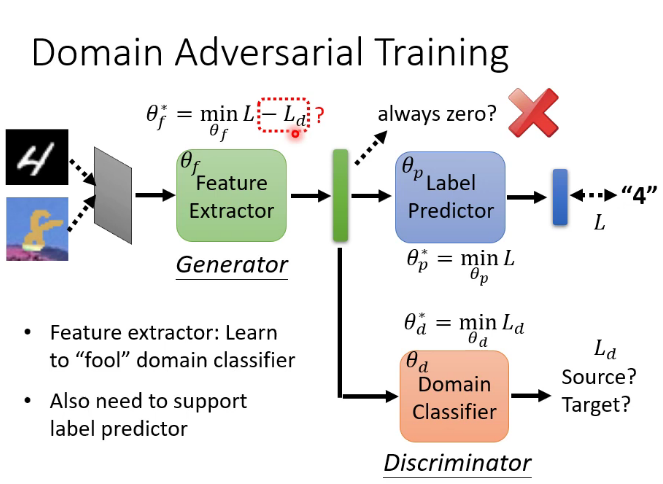
特徵提取器實質就是network的前幾層,具體是幾層可以自己決定,也是一個hyperparameter,結果是盡量讓上圖紅框處來自不同數據集的特徵分布接近
十二.強化學習(Reinforcement Learning簡稱RL)
RL既不屬於監督學習,也不是無監督學習。RL實際上是一個內容龐大的主題,這裡只做簡單介紹,之後有時間再專門學習然後更新這一塊的知識。
RL的訓練過程屬於馬爾可夫決策過程(Markov Decision Processes,MDPs)簡單說就是一個智慧體(Agent)採取行動(Action)從而改變自己的狀態(State)獲得獎勵(Reward)與環境(Environment)發生交互的循環過程。MDP 的策略完全取決於當前狀態(Only present matters),這也是它馬爾可夫性質的體現。
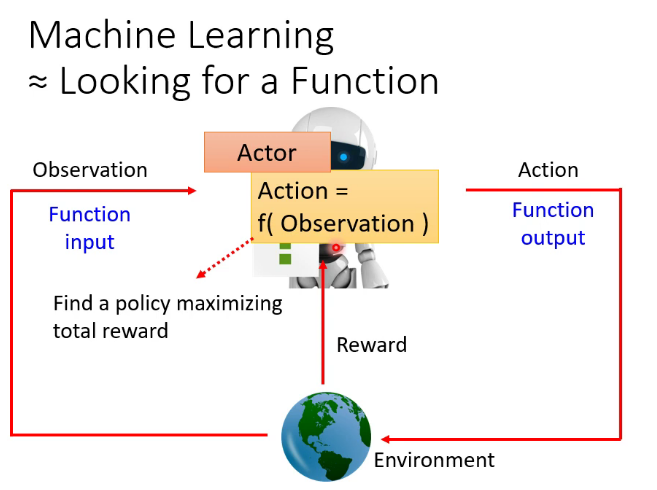
在不同的狀態(State)採取的動作 Action 也就是我們所說的策略 Policy 。常用符號 來表示策略。
我們的目的是讓reward達到最大,常用的方法是策略梯度下降,詳見原課程 //www.bilibili.com/video/BV1Wv411h7kN?p=73
十三.機器終身學習
1.簡述
讓已經學會某些任務的機器模型去學習新的任務
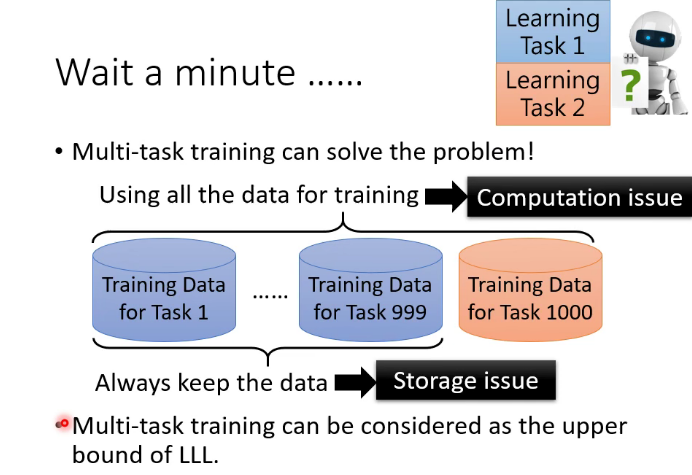
終身學習的upper bound:
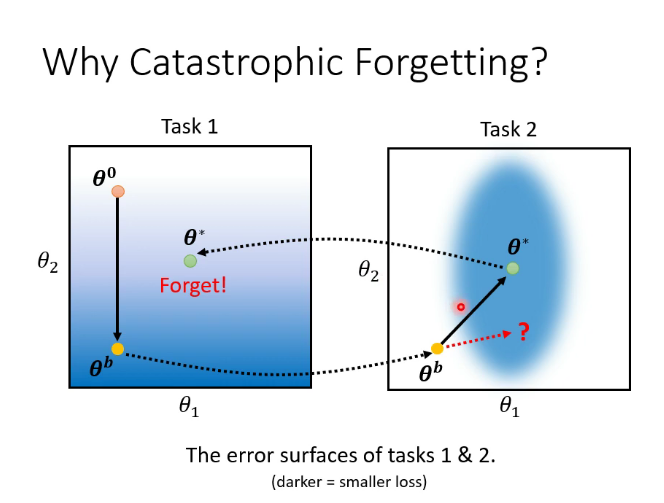
2.災難性遺忘
解決方案:
(1)Selective Synaptic Plasticity(可選擇的突觸可塑性):意思是訓練完一個任務後,模型中的一部分鏈接參數不能夠再動了,以後的訓練只能選擇修改另外一部分參數。這部分研究是發展的最為完整的,因此我們也主要學習這種做法

(2)Additional Nerual Resource Allocation(額外的神經資源分配):
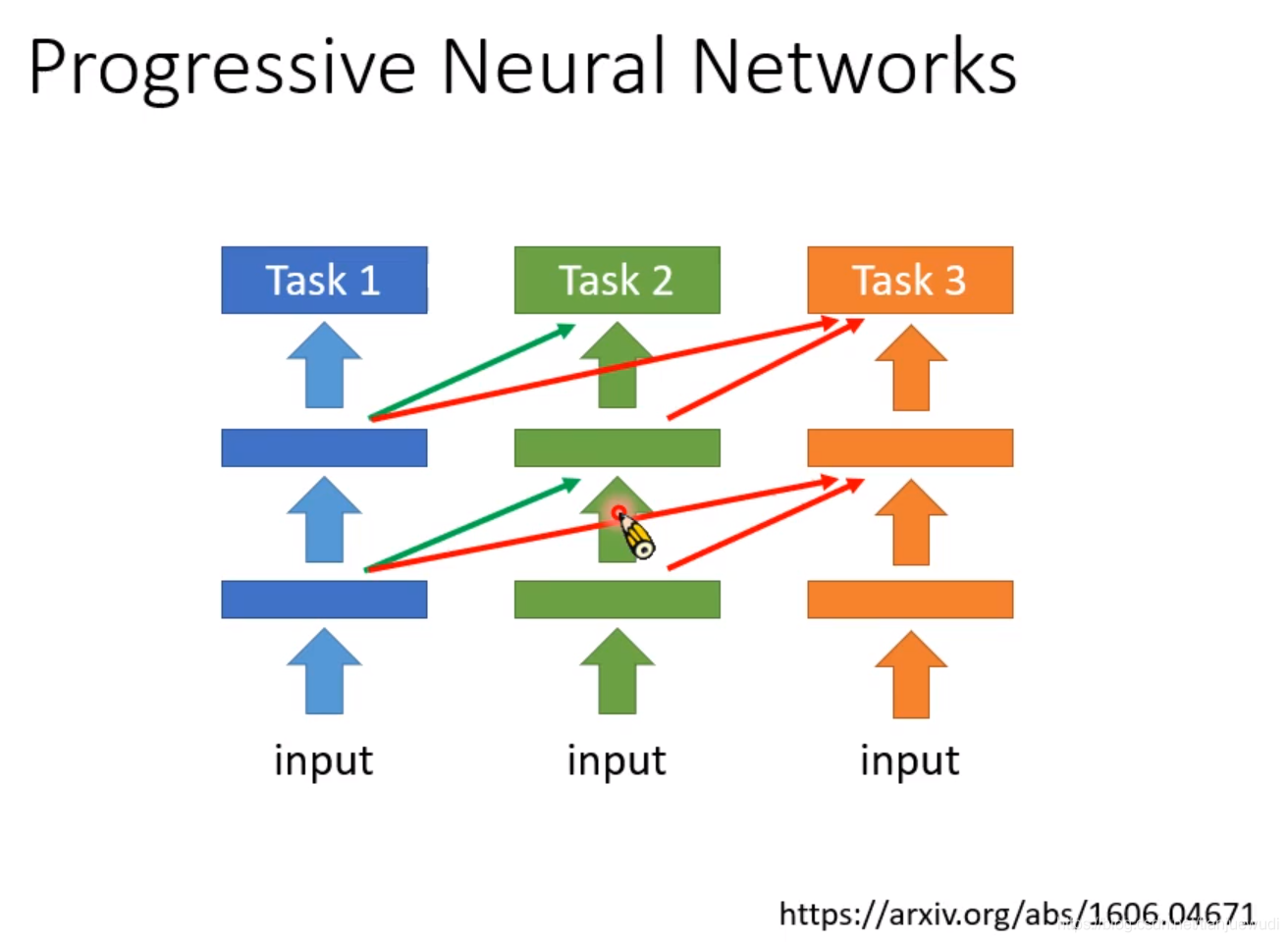
1.Progressive Neural Networks:這是最早的做法,當任務一訓練完成之後,我們就不要再動裡面的參數了,我們可以再新開一個模型,這個模型使用任務一隱藏層中的輸出作為輸入,然後再訓練自己的參數。任務三亦然。這個方法的缺點是模型隨著訓練任務數量的增多而增大,最後可能難以保存。但在任務量沒有太多的時候,這個也是可以派上用場的。
2.PackNet:這種做法是和Progressive Neural Networks相反,首先就建立一個比較大的Network,每次訓練任務只使用一小部分的參數
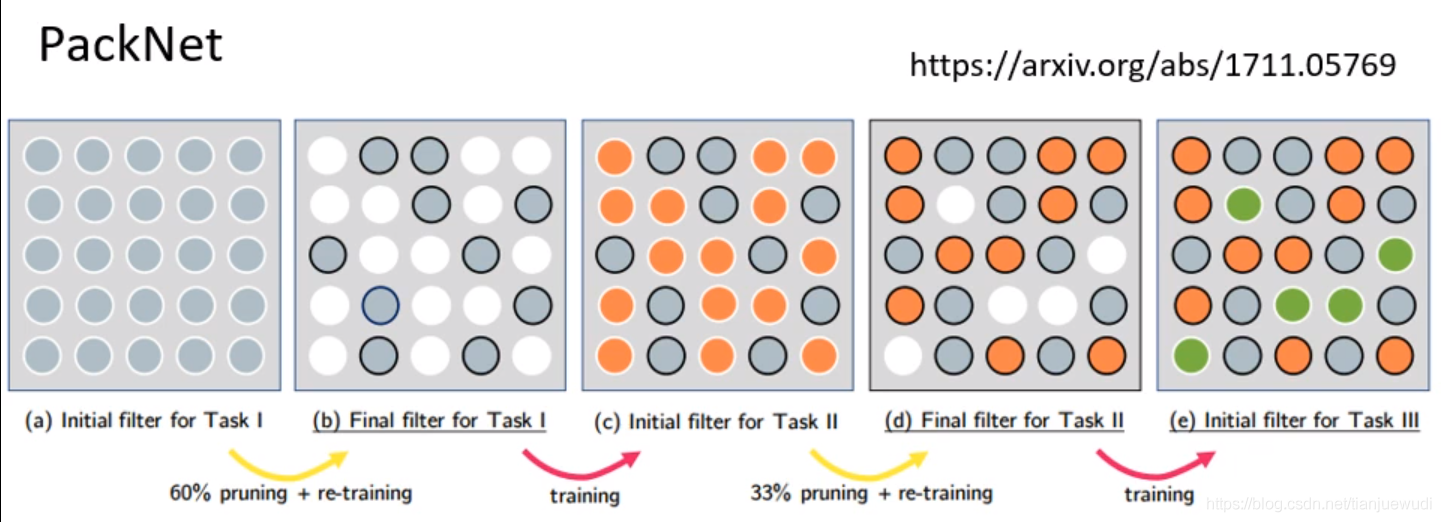
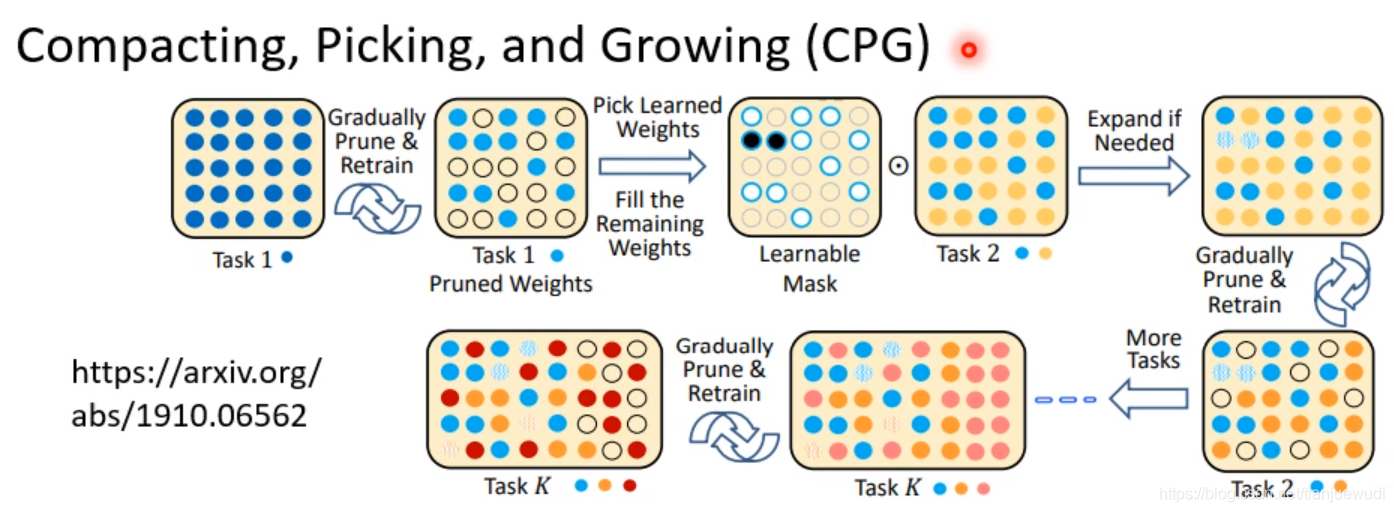
3.Compacting,Picking,and Growing(CPG):這種做法是上兩種的結合。生成一個比較大的網路但是我們一邊只使用部分參數,一邊新增新的網路,確保參數不會用完。
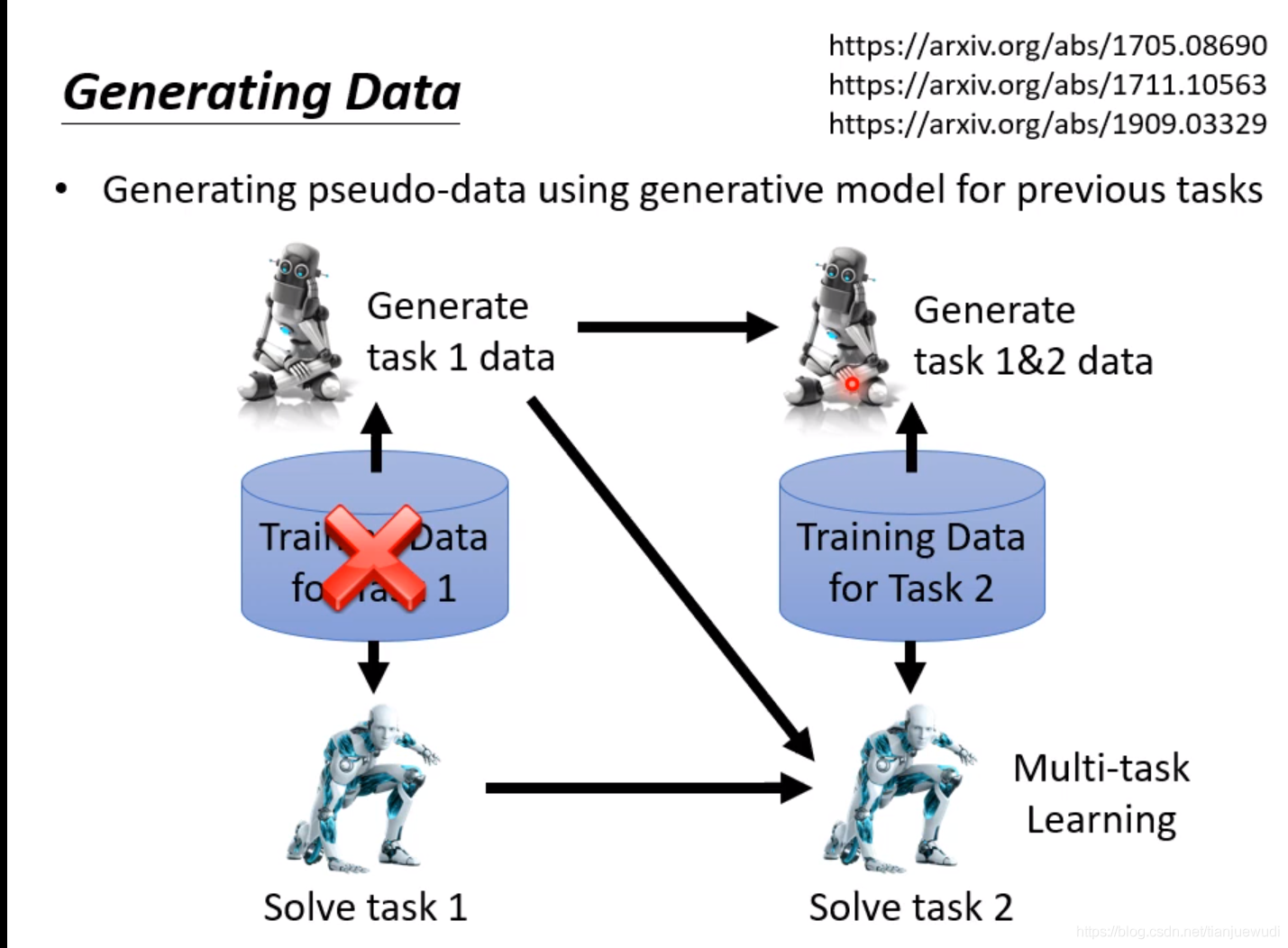
(3)Generating Data:這種做法是直接訓練一個Generator,這個Generator可以直接產生過去任務的資料,因此我們就不用保存過去的資料,直接用這個Generator生成過去的資料和現在任務的資料混合進行訓練,以達到同時學習所有數據的效果。這種做法是非常有效的,經過實驗證明,往往可以達到跟Multi-Task Learning差不多的結果。
十四.神經網路壓縮
因為有時候我們需要讓神經網路運行在資源有限的設備上,因此需要神經網路壓縮
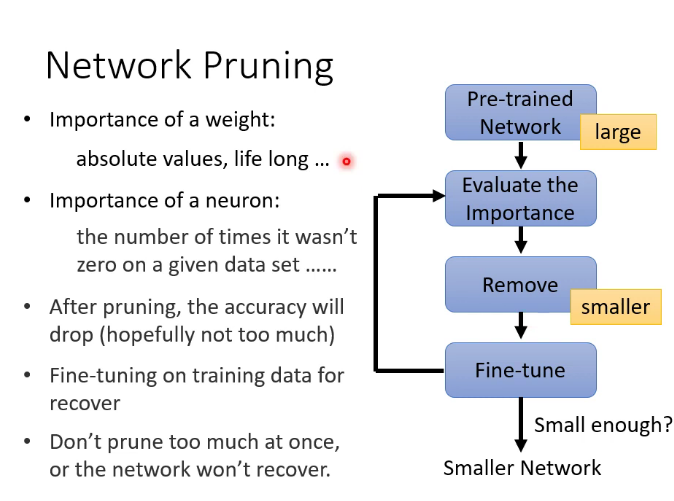
1.剪掉什麼
剪掉權重邊,神經網路會變成irregular,無法在pytorch里直接使用,因為參數不再是矩陣,也不能用GPU加速,因此不常用。常常直接剪掉神經元
2.為什麼不直接訓練一個小的network
大樂透假說:大的network有更多機會隨機出適合任務的模型參數
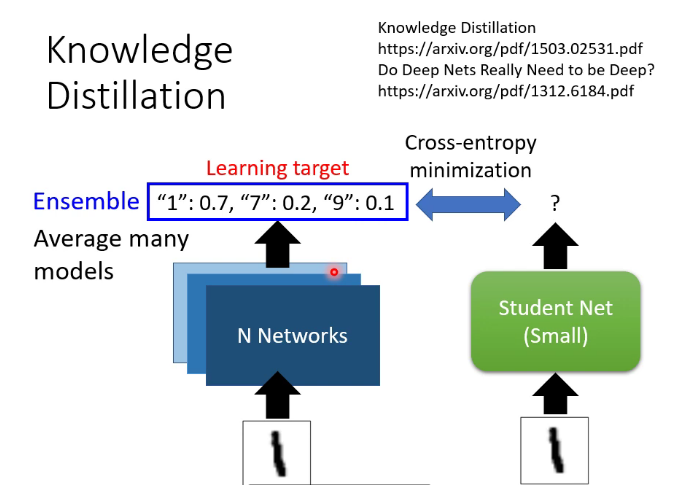
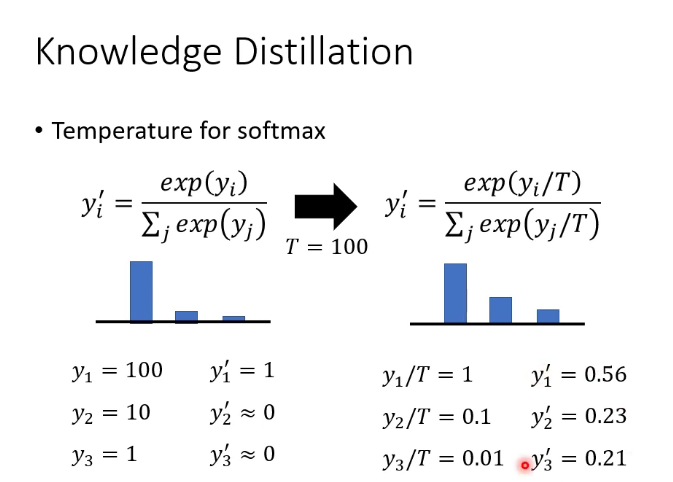
3.知識蒸餾(暗知識提取)
訓練一個teacher network,讓student network學習teacher的輸出,也可以訓練很多teacher求平均
4.Parameter Quantization:
降低參數精度,把參數取為低精度近似值
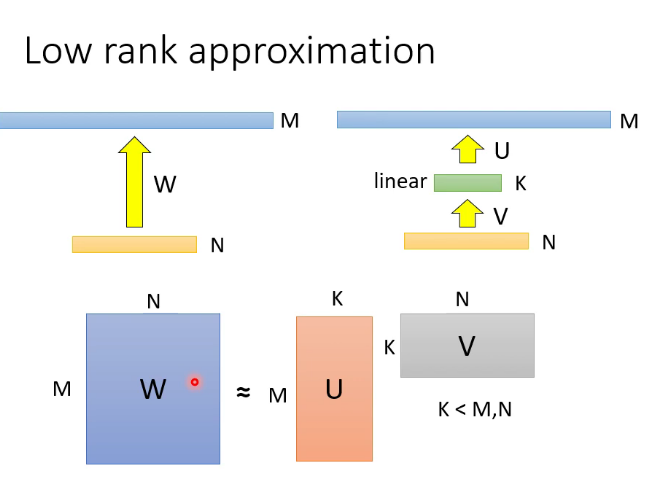
5.重新設計架構:
比如CNN,可以是使用低秩近似
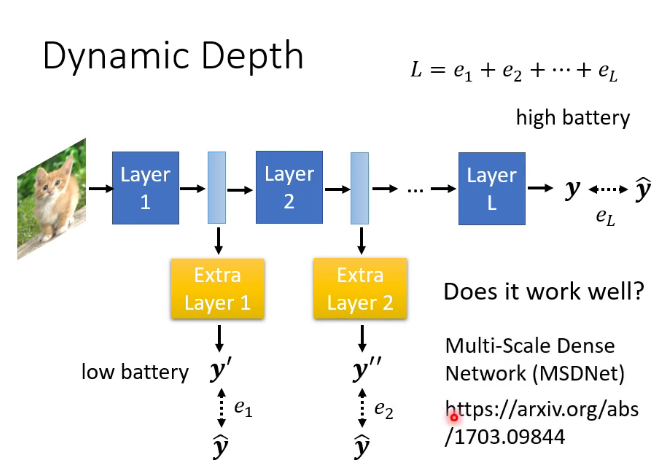
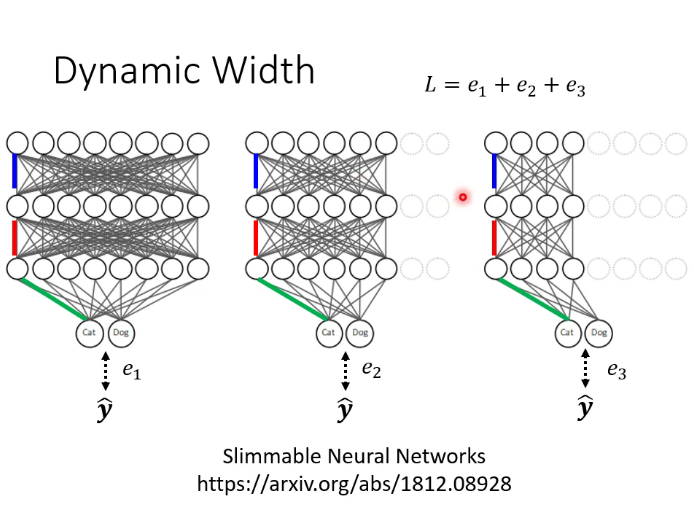
6.動態調整運算資源
動態高度和動態寬度
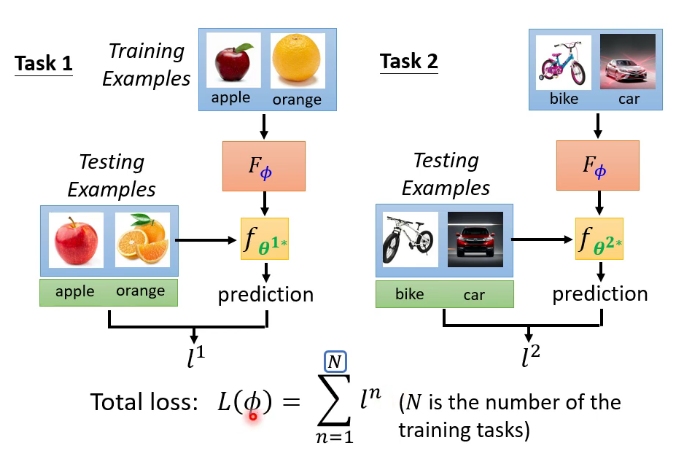
十五.元學習(Meta Learning)
meta learning實質就是learn to learn,比如下圖就是讓機器去學會一個能力,這個能力就是可以學會所有的二分類任務,即學會學習的能力。為了達成這個目標需要調整這個模型的參數,如果有了這個模型,之後的二分類任務就不用再調參數,「一勞永逸」,( 下圖的每一個epoch數據集相同,每個episode數據集可能不同)當前的演算法比如MAML。


十六.結語
李宏毅機器學習這門課只是對機器學習的熱門領域做了一個籠統的介紹,它的內容很全面很先進但又不是很細緻。我的文章更是對這門課的一個簡要概括,這個角度看這篇文章是對機器學習概括的概括(meta概括 ╮( ̄▽  ̄)╭ ),深度學習作為電腦學科一個發展時間並不長分支領域,有很多問題尚待解決。希望未來能更加努力地學習,與君共勉!

