淺析 Java 記憶體模型
文章轉載於 飛天小牛肉 的 《「跬步千里」詳解 Java 記憶體模型與原子性、可見性、有序性》、《JMM 最最最核心的概念:Happens-before 原則》
1. 為什麼要學習並發編程
對於 「我們為什麼要學習並發編程?」 這個問題,就好比 「我們為什麼要學習政治?」 一樣,也許你平常很少接觸到,然後背了一堆 「正確且偉大無比的廢話」,最終淪為八股被快速遺忘。
直到我開始去深入了解這塊知識而不是盲目背誦的時候,我才明白,它正確且偉大無比,但不是廢話。
儘管並發編程的各種底層原理以及其龐大的知識體系容易讓人心生畏懼,但是 Java 語言和 Java 虛擬機都提供了相當多的並發工具,替我們隱藏了很多的執行緒並發細節,使得我們在編碼時能更關注業務邏輯,把並發編程的門檻降低了不少。
但是無論語言、中間件和框架再如何先進,我們都不應該完全依賴於它們完成並發處理的所有事情,了解並發的內幕並學習其中的思想,仍然是成為一個高級程式設計師的必經之路。
我想,上面這段話大概可以回答 「我們為什麼要學習並發編程?」 這個問題了。
2. 為什麼需要並發編程
不知道各位有沒有聽說過被譽為電腦第一定律的摩爾定律,它是英特爾創始人之一戈登 · 摩爾長期觀察總結出來的經驗,雖然不是嚴格推導出來的真理,但最起碼迄今為止仍然是令人深信不疑的。其核心內容通俗來說就是 處理器的性能每隔兩年就會翻一倍。看起來像個廢話🐶。
而事實上,當今多核 CPU 的發展速度也確實正在支撐著摩爾定律的有效性。在時代的大背景下,並發編程已成燎原之勢,通過並發編程的形式將多核 CPU 的計算能力發揮到極致,性能得到提升。
舉個例子,在當今諸神黃昏的影像處理領域,很多影像處理演算法,在程式碼初步編寫完畢並調試正確後,其實仍然需要進行一個漫長的優化過程。因為儘管有些演算法的處理效果很棒,但是如果運算太過耗時,還是無法集成進產品給用戶使用的。
對於一副 1000 x 800 解析度的影像,我們最原始的處理思路就是從第 1 個像素開始,一直遍歷計算到最後一個像素。那麼面對如此龐大且複雜的計算量,為了提高演算法的性能,最直接也最容易實現的想法就是基於多執行緒充分利用多核 CPU 的計算能力。
可以將整個影像分成若干塊,比如我們的 CPU 是 8 核的,那麼可以分成 8 塊,每塊影像大小為 1000 * 100 像素,我們可以創建 8 個執行緒,每個執行緒處理一個影像塊,每個 CPU 分配執行一個執行緒。這樣,運算速度將得到明顯的提升。
當然了,這樣操作後,運算速度並不會恐怖的提升 4 倍,因為執行緒創建和釋放以及上下文切換都有一定的損耗。
這裡摘錄《Java 並發編程的藝術》書中的一段話來回答這個問題,我們為什麼需要並發執行緒?
多核 CPU 時代的到來打破了單核 CPU 對多執行緒效能的限制。多個 CPU 意味著每個執行緒可以使用自己的 CPU 運行,這減少了執行緒上下文切換的開銷,但隨著對應用系統性能和吞吐量要求的提高,出現了處理海量數據和請求的要求,這些都對高並發編程有著迫切的需求。
而至於多核 CPU 盛行的原因,《深入理解 Java 虛擬機 – 第 3 版》一書中也有所涉及,這裡我略作修改摘錄如下:
多任務處理在現代電腦作業系統中幾乎已是一項必備的功能了。在許多場景下,讓電腦同時去做幾件事情,不僅是因為電腦的運算能力強大了,更重要的原因是電腦的運算速度與它的存儲和通訊子系統速度的差距太大,這樣 CPU 不得不花費大量的時間等待其他資源,比如磁碟 I/O、網路通訊或者資料庫訪問等。
為此,我們就必須使用一些手段去把處理器的運算能力「壓榨」出來,否則就會造成很大的性能浪費,而讓電腦同時處理幾項任務則是最容易想到,也被證明是非常有效的「壓榨」手段。
另外,除了充分利用電腦處理器的能力外,一個服務端要同時對多個客戶端提供服務,則是另一個更具體的並發應用場景。
3. 從物理機中得到啟發
事實上,物理機遇到的並發問題與虛擬機中的情況有很多相似之處,物理機對並發的處理方案對虛擬機的實現也有相當大的參考意義,因此,我們有必要學習下物理機中處理問題的方法。
上文說過可以使用並發編程來充分利用 CPU 的資源,其中一個主要原因就是電腦的存儲設備與 CPU 的運算速度有著幾個數量級的差距,這樣 CPU 不得不花費大量的時間去等待其他資源。
這是軟體層面,而在硬體層面上,現代電腦系統都會在記憶體與 CPU 之間加入一層或多層讀寫速度儘可能接近 CPU 運算速度的高速快取來作為緩衝。
將運算需要使用的數據複製到快取中,讓運算能快速進行,在運算結束後再從快取同步回記憶體之中,這樣處理器就無須等待緩慢的記憶體讀寫了。
為此,這不可避免的帶來了一個新的問題:快取一致性(Cache Coherence)。
就是說當多個 CPU 的運算任務都涉及同一塊主記憶體區域時,將可能導致各自的快取數據不一致。如果真的發生這種情況,那同步回到主記憶體時該以誰的快取數據為準呢?
為了解決一致性的問題,需要各個 CPU 訪問快取時都遵循一些協議,在讀寫時要根據協議來進行操作。於是,我們引出了記憶體模型的概念。
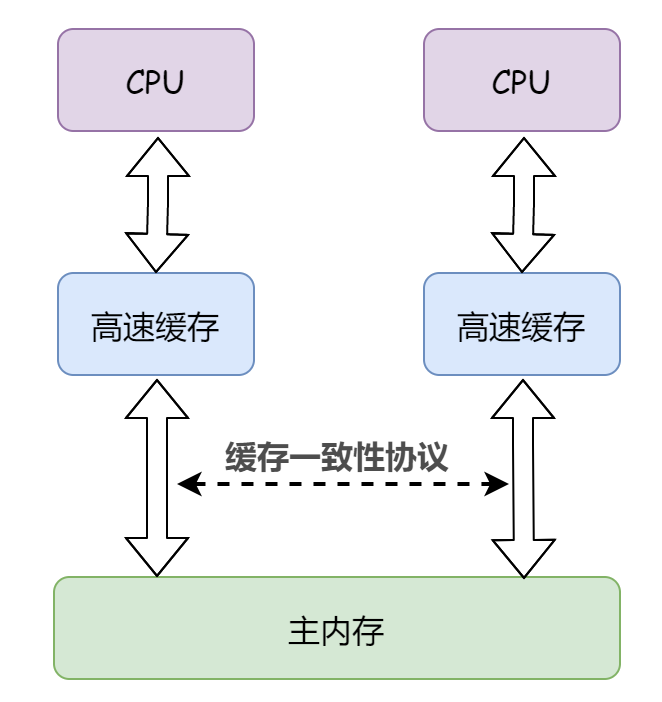
在物理機層面,記憶體模型可以理解為在特定的操作協議下,對特定的記憶體或高速快取進行讀寫訪問的過程抽象。
顯然,不同架構的物理機器可以擁有不一樣的記憶體模型,而 Java 虛擬機也擁有自己的記憶體模型,稱為 Java 記憶體模型(Java Memory Model,JMM),其目的就是為了屏蔽各種硬體和作業系統的記憶體訪問差異,以實現讓 Java 程式在各種平台下都能達到一致的記憶體訪問效果。
當然了,JMM 與這裡我們介紹的物理機的記憶體模型具有高度的可類比性。
4. Java 記憶體模型
JMM 規定了所有的變數都存儲在主記憶體(Main Memory)中,每條執行緒還有自己的工作記憶體(Working Memory)。
執行緒的工作記憶體中保存了被該執行緒使用的變數的主記憶體副本,執行緒對變數的所有操作(讀取、賦值等)都必須在工作記憶體中進行,而不能直接讀寫主記憶體中的數據。
此處的主記憶體可以與前面所說的物理機的主記憶體類比,當然,實際上它僅是虛擬機記憶體的一部分,工作記憶體可與前面講的高速快取類比。
《Java 並發編程的藝術》中把 「工作記憶體」 稱為 「本地記憶體」(Local Memory)。「工作記憶體」 是《深入理解 Java 虛擬機 – 第 3 版》這本書中的寫法。
多提一嘴,這裡的變數其實和我們日常編程中所說的變數不一樣,它包括了實例欄位、靜態欄位和構成數組對象的元素,但是不包括局部變數與方法參數,因為後面這倆是執行緒私有的,不會被共享,自然就不會存在競爭問題。各位知道就好,不必太過深究。
4.1 原子性
什麼是原子性
類比物理機,擁有快取一致性協議來規定主記憶體和高速快取之間的操作邏輯,那麼 JMM 中主記憶體與工作記憶體之間有沒有具體的交互協議呢?
Of Course!JMM 中定義了以下 8 種操作規範來完成一個變數從主記憶體拷貝到工作記憶體、以及從工作記憶體同步回主記憶體這一類的實現細節。Java 虛擬機實現時必須保證下面提及的每一種操作都是原子的、不可再分的。
暫時放下到底是哪 8 種操作,我們先談何為原子?
原子(atomic)本意是 「不能被進一步分割的最小粒子」,而原子操作(atomic operation)意為 「不可被中斷的一個或一系列操作」。
舉個經典的簡單例子,銀行轉賬,A 像 B 轉賬 100 元。轉賬這個操作其實包含兩個離散的步驟:
- 步驟 1:A 賬戶減去 100
- 步驟 2:B 賬戶增加 100
我們要求轉賬這個操作是原子性的,也就是說步驟 1 和步驟 2 是順續執行且不可被打斷的,要麼全部執行成功、要麼執行失敗。
試想一下,如果轉賬操作不具備原子性會導致什麼問題呢?
比如說步驟 1 執行成功了,但是步驟 2 沒有執行或者執行失敗,就會導致 A 賬戶少了 100 但是 B 賬戶並沒有相應的多出 100。
對於上述這種情況,符合原子性的轉賬操作應該是如果步驟 2 執行失敗,那麼整個轉賬操作就會失敗,步驟 1 就會回滾,並不會將 A 賬戶減少 100。
OK,了解了原子性的概念後,我們再來看 JMM 定義的 8 種原子操作具體是啥,以下了解即可,沒必要死記:
lock(鎖定):作用於主記憶體的變數,它把一個變數標識為一條執行緒獨佔的狀態。unlock(解鎖):作用於主記憶體的變數,它把一個處於鎖定狀態的變數釋放出來,釋放後的變數才可以被其他執行緒鎖定。read(讀取):作用於主記憶體的變數,它把一個變數的值從主記憶體傳輸到執行緒的工作記憶體中,以便隨後的load動作使用。load(載入):作用於工作記憶體的變數,它把 read 操作從主記憶體中得到的變數值放入工作記憶體的變數副本中。use(使用):作用於工作記憶體的變數,它把工作記憶體中一個變數的值傳遞給執行引擎,每當虛擬機遇到一個需要使用變數的值的位元組碼指令時將會執行這個操作。assign(賦值):作用於工作記憶體的變數,它把一個從執行引擎接收的值賦給工作記憶體的變數,每當虛擬機遇到一個給變數賦值的位元組碼指令時執行這個操作。store(存儲):作用於工作記憶體的變數,它把工作記憶體中一個變數的值傳送到主記憶體中,以便隨後的 write 操作使用。write(寫入):作用於主記憶體的變數,它把store操作從工作記憶體中得到的變數的值放入主記憶體的變數
事實上,對於
double和long類型的變數來說,load、store、read 和 write 操作在某些平台上允許有例外,稱為 「long 和 double 的非原子性協定」,不過一般不需要我們特別注意,這裡就不再過多贅述了。
這 8 種操作當然不是可以隨便用的,為了保證 Java 程式中的記憶體訪問操作在並發下仍然是執行緒安全的,JMM 規定了在執行上述 8 種基本操作時必須滿足的一系列規則。
這我就不一一列舉了,多提這麼一嘴的原因就是下文會涉及一些這其中的規則,為了防止大家看的時候雲里霧裡,所以先前說明白比較好。
上面我們舉了一個轉賬的例子,那麼,在具體的程式碼中,非原子性操作可能會導致什麼問題呢?
看下面這段程式碼,各位不妨考慮一個的問題,如果兩個執行緒對初始值為 0 的靜態變數一個做自增,一個做自減,各做 5000 次,結果一定是 0 嗎?
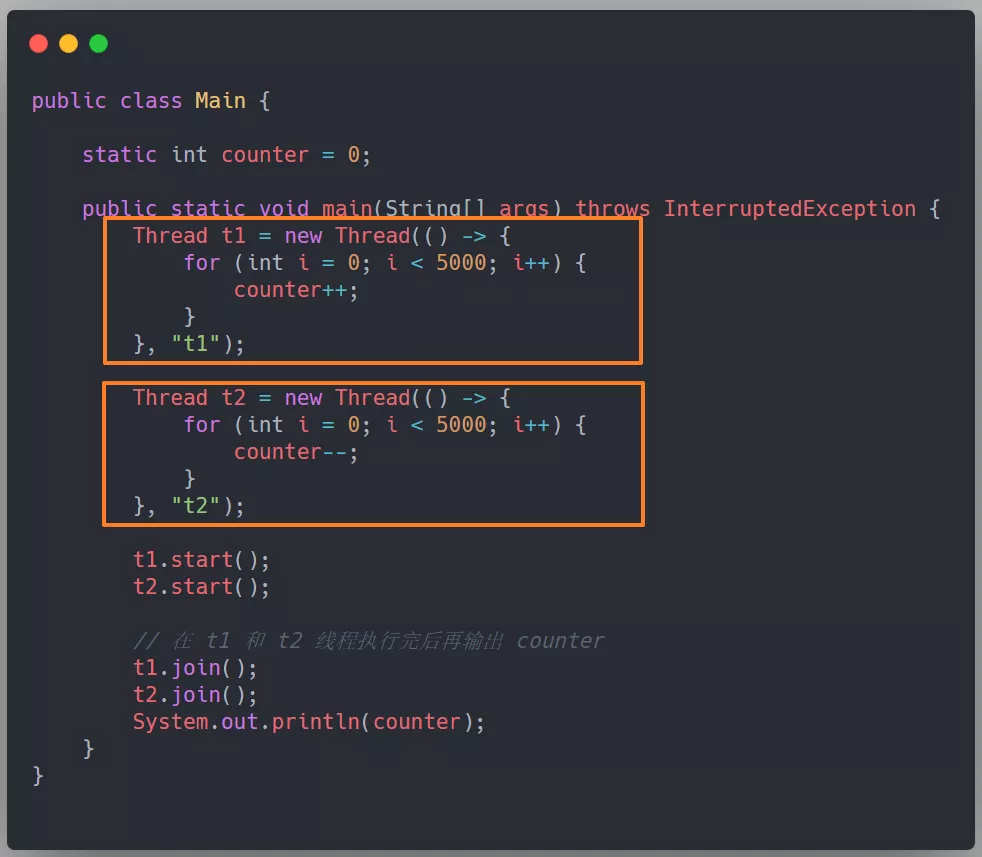
耳熟能詳的問題,我們無法保證這段程式碼執行結果的一定性(正確性),可能是正數、也可能是負數、當然也可能是 0。
那麼,我們就把這段程式碼稱為執行緒不安全的,就是說在單執行緒環境下正常運行的一段程式碼,在多執行緒環境中可能發生各種意外情況,導致無法得到正確的結果。
從執行緒安全的角度來反向理解執行緒不安全的概念可能更容易點,這裡參考《Java 並發編程實踐》上面的一句話:
一段程式碼在被多個執行緒訪問後,它仍然能夠進行正確的行為,那這段程式碼就是執行緒安全的。
至於這段程式碼執行緒不安全的原因,就是 Java 中對靜態變數自增和自減操作並不是原子操作,它倆其實都包含三個離散的操作:
- 步驟 1:讀取當前 i 的值
- 步驟 2:將 i 的值加 1(減 1)
- 步驟 3:寫回新值
可以看出來這是一個 讀 – 改 – 寫 的操作。
以 i++ 操作為例,我們來看看它對應的位元組碼指令:
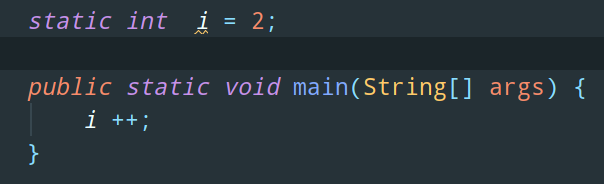
上方這段程式碼對應的位元組碼是這樣的:
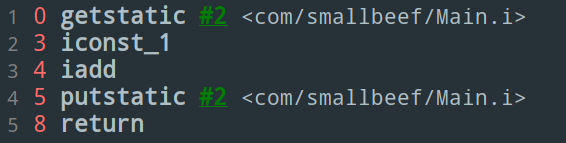
簡單解釋下這些位元組碼指令的含義:
getstatic i:獲取靜態變數 i 的值iconst_1:準備常量 1iadd:自增(自減操作對應 isub)putstatic i:將修改後的值存入靜態變數 i
如果是在單執行緒的環境下,先自增 5000 次,然後再自減 5000 次,那當然不會發生任何問題。
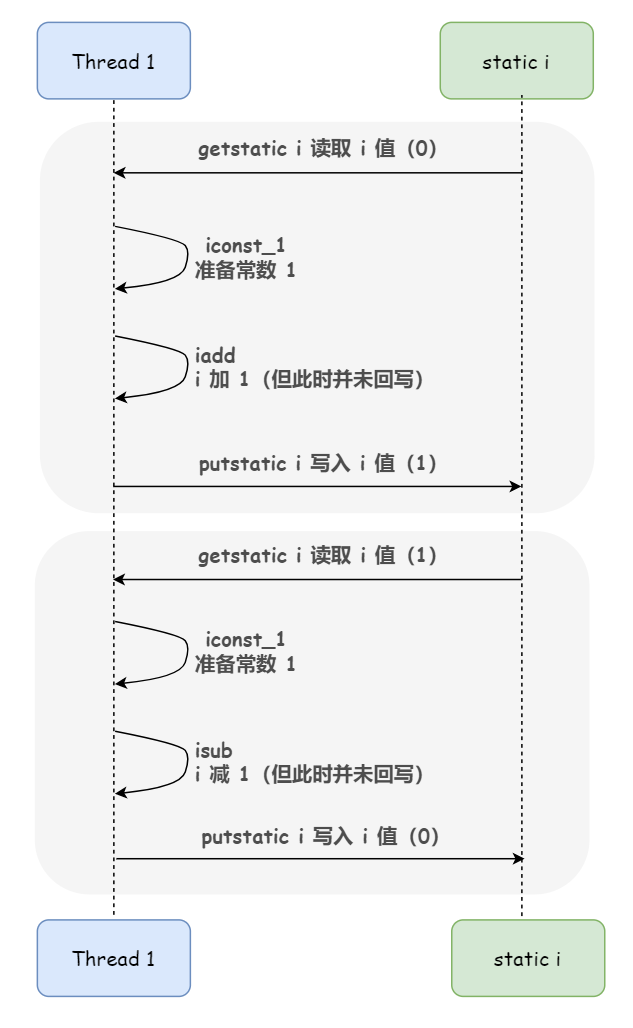
但是在多執行緒的環境下,由於 CPU 時間片調度的原因,可能 Thread1 正在執行自增操作著呢,CPU 剝奪了它的資源佔用,轉而分配給了 Thread2,也就是發生了執行緒上下文切換。這樣,就可能導致本該是一個連續的讀改寫動作(連續執行的三個步驟)被打斷了。
下圖出現的就是結果最終是負數的情況:
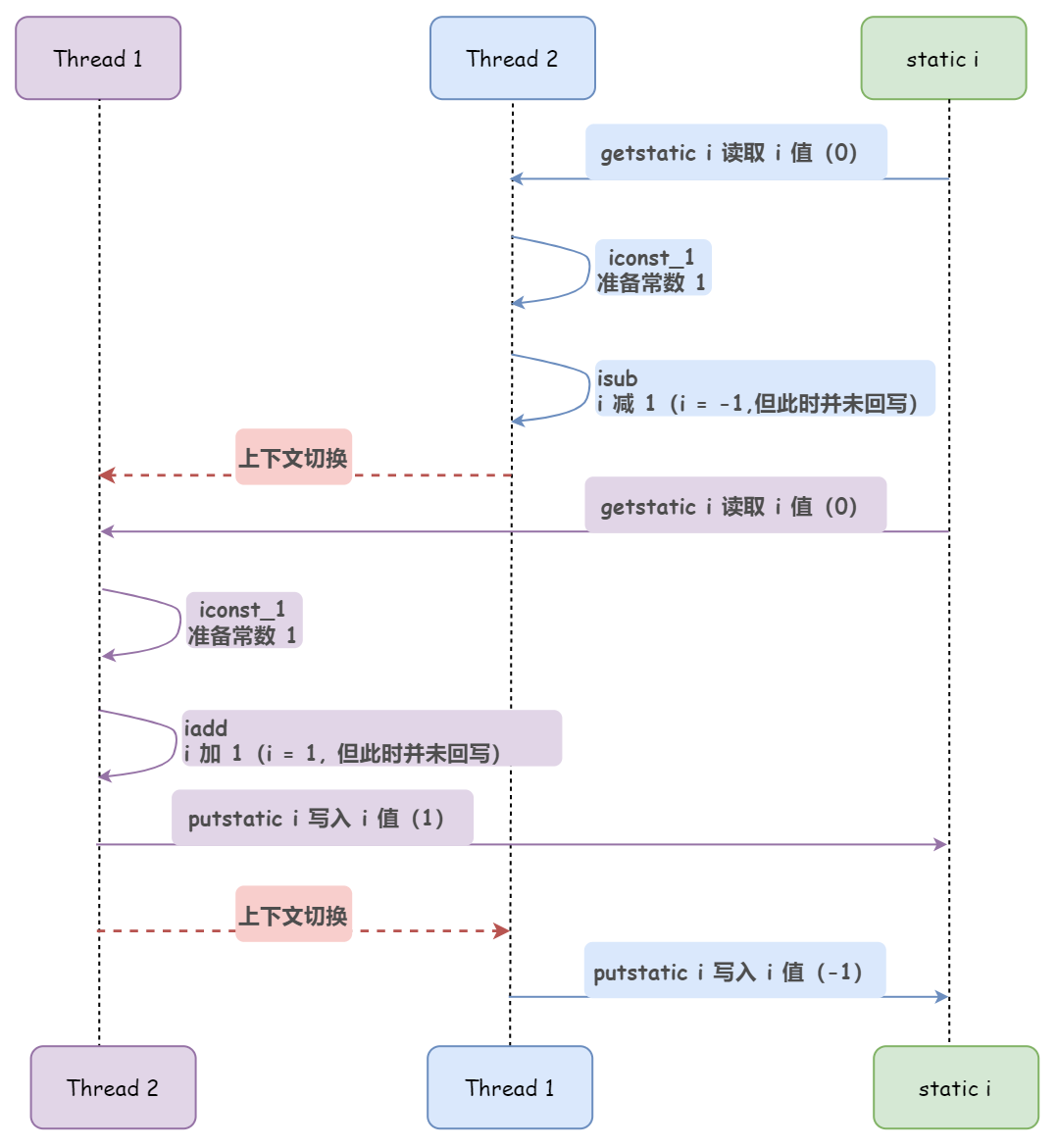
總結來說,如果多個 CPU 同時對某個共享變數進行讀-改-寫操作,那麼這個共享變數就會被多個 CPU 同時處理,由於 CPU 時間片調度等原因,某個執行緒的讀-改-寫操作可能會被其他執行緒打斷,導致操作完後共享變數的值和我們期望的不一致。
另外,多說一嘴,除了自增自減,我們常見的 i = j 這個操作也是非原子性的,它分為兩個離散的步驟:
- 步驟 1:讀取 j 的值
- 步驟 2:將 j 的值賦給 i
如何保證原子性
那麼,如何實現原子操作,也就是如何保證原子性呢?
對於這個問題,其實在處理器和 Java 程式語言層面,它們都提供了一些有效的措施,比如處理器提供了匯流排鎖和快取鎖,Java 提供了鎖和循環 CAS 的方式,這裡我們簡單解釋下 Java 保證原子性的措施。
由 Java 記憶體模型來直接保證的原子性變數操作包括read、load、assign、use、store 和 write這 6 個,我們大致可以認為,基本數據類型的訪問、讀寫都是具備原子性的(例外就是 long 和 double 的非原子性協定,各位只要知道這件事情就可以了,無須太過在意這些幾乎不會發生的例外情況)。
如果應用場景需要一個更大範圍的原子性保證,Java 記憶體模型還提供了 lock 和unlock 操作來滿足這種需求。
儘管 JVM 並沒有把 lock 和 unlock 操作直接開放給用戶使用,但是卻提供了更高層次的位元組碼指令 monitorenter 和 monitorexit 來隱式地使用這兩個操作。這兩個位元組碼指令反映到 Java 程式碼中就是同步塊 synchronized 關鍵字,因此在 synchronized 塊之間的操作也具備原子性。
而除了 synchronized 關鍵字這種 Java 語言層面的鎖,juc 並發包中的 java.util.concurrent.locks.Lock 介面也提供了一些類庫層面的鎖,比如ReentrantLock。
另外,隨著硬體指令集的發展,在 JDK 5 之後,Java 類庫中開始使用基於 cmpxchg 指令的 CAS 操作(又來一個重點),該操作由 sun.misc.Unsafe 類裡面的 compareAndSwapInt() 和 compareAndSwapLong() 等幾個方法包裝提供。不過在 JDK 9 之前 Unsafe 類是不開放給用戶使用的,只有 Java 類庫可以使用,譬如 juc 包裡面的整數原子類,其中的 compareAndSet() 和 getAndIncrement() 等方法都使用了 Unsafe 類的 CAS 操作來實現。
使用這種 CAS 措施的程式碼也常被稱為無鎖編程(Lock-Free)。
4.2 可見性
什麼是可見性
回到物理機,前文說過,由於引入了高速快取,不可避免的帶來了一個新的問題:快取一致性。而同樣的,這個問題在 Java 虛擬機中同樣存在,表現為工作記憶體與主記憶體的同步延遲,也就是記憶體可見性問題。
何為可見性?就是指當一個執行緒修改了共享變數的值時,其他執行緒能夠立即得知這個修改。
回顧下 Java 記憶體模型:
從上圖來看,如果執行緒 A 與執行緒 B 之間要通訊的話,必須要經歷下面 2 個步驟:
- 1)執行緒 A 把工作記憶體 A 中更新過的共享變數刷新到主記憶體中去
- 2)執行緒 B 到主記憶體中去讀取執行緒 A 之前已更新過的共享變數
也就是說,執行緒 A 在向執行緒 B 的通訊過程必須要經過主記憶體。
那麼,這就可能出現一個問題,舉個簡單的例子,看下面這段程式碼:
// 執行緒 1 執行的程式碼
int i = 0;
i = 1;
// 執行緒 2 執行的程式碼
j = i;
當執行緒 1 執行 i = 1 這句時,會先去主記憶體中讀取 i 的初始值,然後載入到執行緒 1 的的工作記憶體中,再賦值為1,至此,執行緒 1 的工作記憶體當中 i 的值變為 1 了,不過還沒有寫入到主記憶體當中。
如果在執行緒 1 準備把新的 i 值寫回主記憶體的時候,執行緒 2 執行了 j = i 這條語句,它會去主存讀取 i 的值並載入到執行緒 2 的工作記憶體當中,而此時主記憶體當中 i 的值還是 0,那麼就會使得 j 的值為 0,而不是 1。
這就是記憶體可見性問題,執行緒 1 修改了共享變數 i 的值,執行緒 2 並沒有立即得知這個修改。
如何保證可見性
各位可能脫口而出使用 volatile 關鍵字修飾共享變數,但除了這個,容易被大家忽略的是,其實 synchronized 和 final 這倆關鍵字也能保證可見性。
上面我提過一嘴,為了保證 Java 程式中的記憶體訪問操作在並發下仍然是執行緒安全的,JMM 規定了在執行 8 種基本原子操作時必須滿足的一系列規則,這其中有一條規則正是 sychronized 能夠保證原子性的理論支撐,如下:
- 對一個變數執行 unlock 操作之前,必須先把此變數同步回主記憶體中(執行 store、write 操作)
也就是說 synchronized在修改了工作記憶體中的變數後,解鎖前會將工作記憶體修改的內容刷新到主記憶體中,確保了共享變數的值是最新的,也就保證了可見性。
至於 final 關鍵字的可見性需要結合其記憶體語義深入來講,這裡就先簡單的概括下:被 final 修飾的欄位在構造器中一旦被初始化完成,並且構造器沒有把 this 的引用傳遞出去,那麼在其他執行緒中就能看見 final 欄位的值。
4.3 有序性
什麼是有序性
OK,說完了可見性,我們再回到物理機,其實除了增加高速快取之外,為了使 CPU 內部的運算單元能盡量被充分利用,CPU 可能會對輸入程式碼進行亂序執行優化,CPU 會在計算之後將亂序執行的結果重組,保證該結果與順序執行的結果是一致的,但並不保證程式中各個語句計算的先後順序與輸入程式碼中的順序一致,因此如果存在一個計算任務依賴另外一個計算任務的中間結果,那麼其順序性並不能靠程式碼的先後順序來保證。
與之類似的,Java 的編譯器也有這樣的一種優化手段:指令重排序(Instruction Reorder)。
那麼,既然能夠優化性能,重排序可以沒有限制的被使用嗎?
當然不,在重排序的時候,CPU 和編譯器都需要遵守一個規矩,這個規矩就是 as-if-serial 語義:不管怎麼重排序,單執行緒環境下程式的執行結果不能被改變。
為了遵守 as-if-serial 語義,CPU 和編譯器不會對存在數據依賴關係的操作做重排序,因為這種重排序會改變執行結果。
那麼這裡,我們又引出了 「數據依賴性」 的概念。
如果兩個操作訪問同一個變數,且這兩個操作中有一個為寫操作,此時這兩個操作之間就存在數據依賴性。
數據依賴性分為三種類型:寫後讀、寫後寫、讀後寫,看下圖:
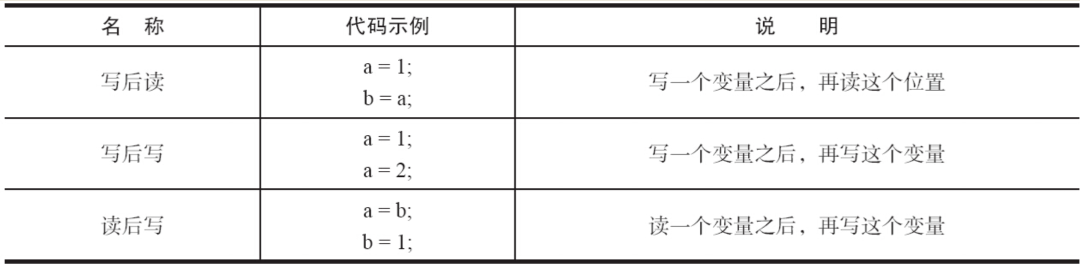
上面 3 種情況,只要重排序兩個操作的執行順序,程式的執行結果就會被改變。
其實考慮數據依賴關係的時候,各位可以通過畫圖來直觀的判斷。舉個例子:
int a = 1; // A
int b = 2; // B
int sum = a + b; // C
上面 3 個操作的數據依賴關係如下圖所示:
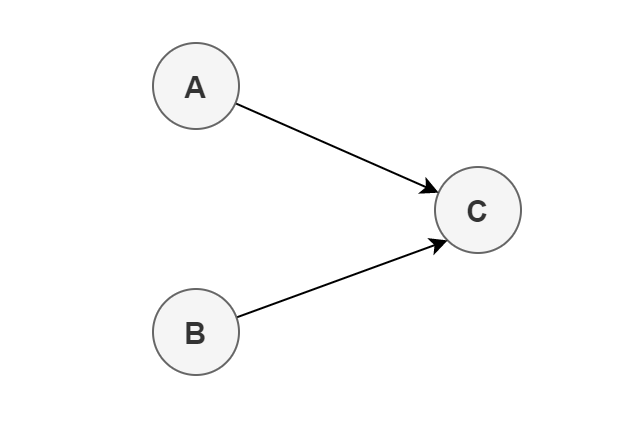
可以看出,A 和 C、B 和 C 之間存在數據依賴關係,因此在最終執行的指令序列中,C 不能被重排序到 A 或 B 的前面。但 A 和 B 之間沒有數據依賴關係,所以 CPU 和處理器可以重排序 A 和 B 之間的執行順序。如下是程式的兩種執行順序:
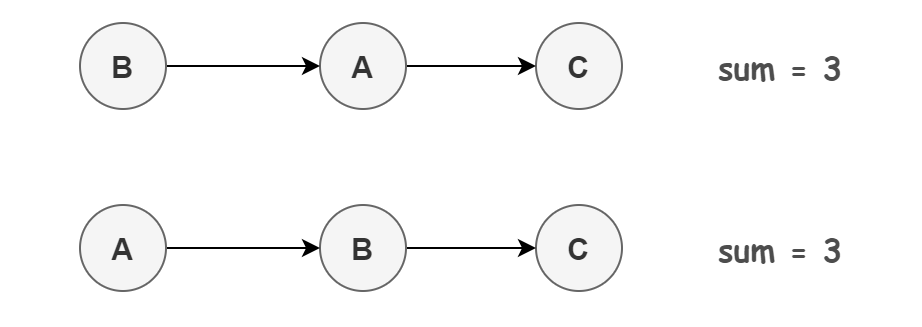
看起來好像沒啥問題,重排序之後程式的結果並沒有發生改變,還提升了性能。
然而,很不幸的是,我們這裡所說的數據依賴性僅針對單個 CPU 中執行的指令序列和單個執行緒中執行的操作,不同 CPU 之間和不同執行緒之間的數據依賴性是不被 CPU 和編譯器考慮的。
這就是為啥我在寫 as-if-serial 語義的時候把 「單執行緒」 加粗的目的了。
看下面這段程式碼:
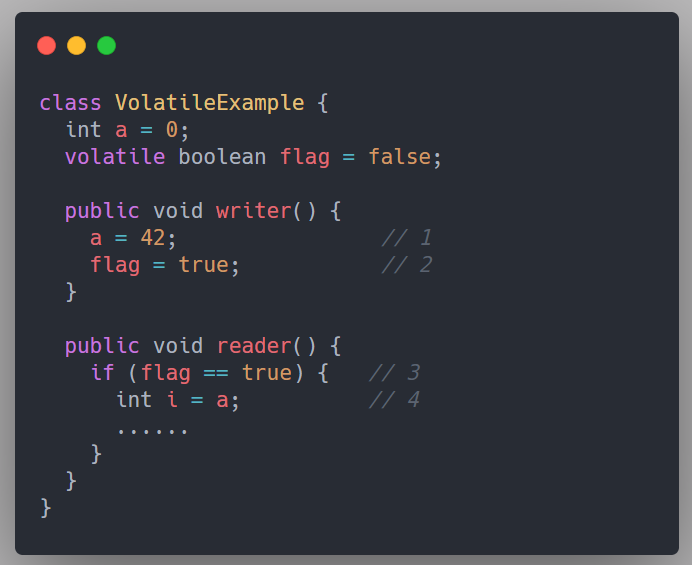
假設有兩個執行緒 A 和 B,A 首先執行 writer() 方法,隨後 B 執行緒接著執行 reader() 方法。執行緒 B 在執行操作 4 時,能否看到執行緒 A 在操作 1 把共享變數 a 修改成了 1 呢?
答案是不一定。
由於操作 1 和操作 2 沒有數據依賴關係,CPU 和編譯器可以對這兩個操作重排序;同樣的,操作 3 和操作 4 沒有數據依賴關係,編譯器和處理器也可以對這兩個操作重排序。
以操作 1 和操作 2 重排序為例,可能會產生什麼效果呢?
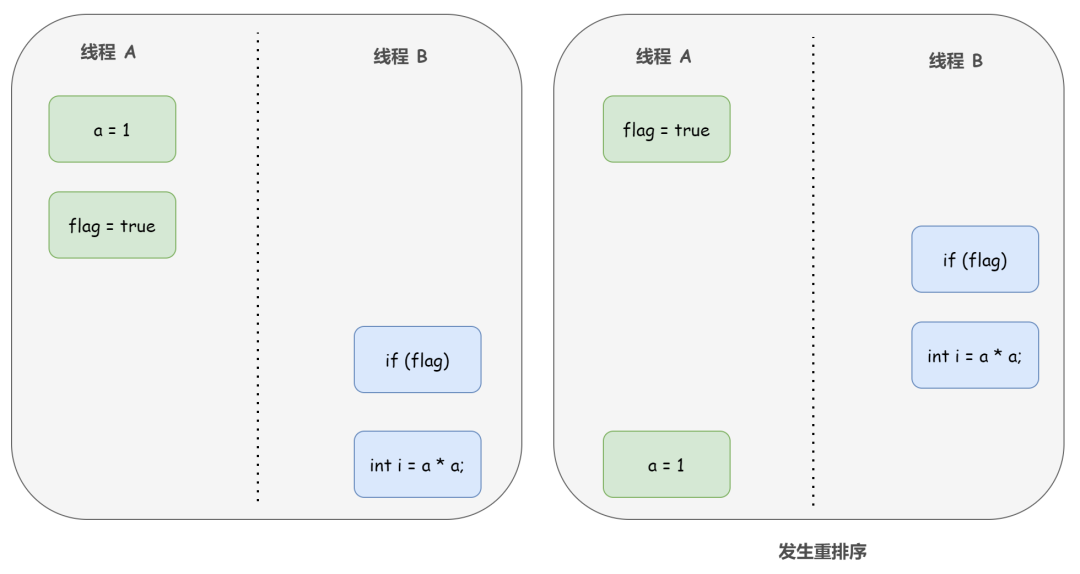
如上圖右邊所示,程式執行時,執行緒 A 首先寫標記變數 flag,隨後執行緒 B 讀這個變數。由於條件判斷為真,執行緒 B 將讀取變數 a。此時,變數 a 還沒有被執行緒 A 寫入,因此執行緒 B 讀到的 a 值仍然是 0。也就是說在這裡多執行緒程式的語義被重排序破壞了。
這樣,我們可以得出結論:CPU 和 Java 編譯器為了優化程式性能,會自發地對指令序列進行重新排序。在多執行緒的環境下,由於重排序的存在,就可能導致程式運行結果出現錯誤。
了解了重排序的概念,我們可以這樣總結下 Java 程式天然的有序性:
- 如果在本執行緒內觀察,所有的操作都是有序的(簡單來說就是執行緒內表現為串列)
- 如果在一個執行緒中觀察另一個執行緒,所有的操作都是無序的(這個無序主要就是指 「指令重排序」 現象和 「工作記憶體與主記憶體同步延遲」 現象)
如何保證有序性
Java 語言提供了 volatile 和 synchronized 兩個關鍵字來保證執行緒之間操作的有序性。
volatile 本身除了保證可見性的語義外,還包含了禁止指令重排序的語義,所以天生就具有保證有序性的功能。
而 synchronized 保證有序性的理論支撐,仍然是 JMM 規定在執行 8 種基本原子操作時必須滿足的一系列規則中的某一個提供的:
- 一個變數在同一個時刻只允許一條執行緒對其進行 lock 操作
這個規則決定了持有同一個鎖的兩個 synchronized 同步塊只能串列地進入。
不是很難理解吧,通俗來說,synchronized 通過排他鎖的方式保證了同一時間內,被 synchronized 修飾的程式碼是單執行緒執行的。所以,這就滿足了 as-if-serial 語義的一個關鍵前提,那就是單執行緒,這樣,有了 as-if-serial 語義的保證,單執行緒的有序性也就得到保障了。
5. Happens-before 原則
Happens-before 是 JMM 的靈魂,它是判斷數據是否存在競爭,執行緒是否安全的非常有用的手段。
如果 Java 記憶體模型中所有的有序性都僅靠 volatile 和 synchronized 來完成,那麼有很多操作都將會變得非常啰嗦,但是我們在編寫 Java 並發程式碼的時候並沒有察覺到這一點,這就歸功於 「先行發生」(Happens-Before)原則。依賴這個原則,我們可以通過幾條簡單規則快速解決並發環境下兩個操作之間是否可能存在衝突的所有問題,而不需要陷入 Java 記憶體模型苦澀難懂的定義之中。
關於 Happens-before,《Java 並發編程的藝術》書中是這樣介紹的:
Happens-before 是 JMM 最核心的概念。對應 Java 程式設計師來說,理解 Happens-before 是理解 JMM 的關鍵。
《深入理解 Java 虛擬機 – 第 3 版》書中是這樣介紹的:
Happens-before 是 JMM 的靈魂,它是判斷數據是否存在競爭,執行緒是否安全的非常有用的手段。
我想,這兩句話就已經足夠表明 Happens-before 原則的重要性。那為什麼 Happens-before 被不約而同的稱為 JMM 的核心和靈魂呢?生來如此。
5.1 JMM 設計者的難題與完美的解決方案
前面我們學習了 JMM 及其三大性質,事實上,從 JMM 設計者的角度來看,可見性和有序性其實是互相矛盾的兩點:
- 一方面,對於程式設計師來說,我們希望記憶體模型易於理解、易於編程,為此 JMM 的設計者要為程式設計師提供足夠強的記憶體可見性保證,專業術語稱之為 「強記憶體模型」
- 而另一方面,編譯器和處理器則希望記憶體模型對它們的束縛越少越好,這樣它們就可以做儘可能多的優化(比如重排序)來提高性能,因此 JMM 的設計者對編譯器和處理器的限制要儘可能地放鬆,專業術語稱之為 「弱記憶體模型」
對於這個問題,從 JDK 5 開始,也就是在 JSR-133 記憶體模型中,終於給出了一套完美的解決方案,那就是 Happens-before 原則,Happens-before 直譯為 「先行發生」,《JSR-133:Java Memory Model and Thread Specification》對 Happens-before 關係的定義如下:
1)如果一個操作 Happens-before 另一個操作,那麼第一個操作的執行結果將對第二個操作可見,而且第一個操作的執行順序排在第二個操作之前。
2)兩個操作之間存在 Happens-before 關係,並不意味著 Java 平台的具體實現必須要按照 Happens-before 關係指定的順序來執行。如果重排序之後的執行結果,與按 Happens-before 關係來執行的結果一致,那麼這種重排序並不非法(也就是說,JMM 允許這種重排序)
並不難理解,第 1 條定義是 JMM 對程式設計師強記憶體模型的承諾。從程式設計師的角度來說,可以這樣理解 Happens-before 關係:如果 A Happens-before B,那麼 JMM 將向程式設計師保證 — A 操作的結果將對 B 可見,且 A 的執行順序排在 B 之前。注意,這只是 Java記憶體模型向程式設計師做出的保證!
需要注意的是,不同於 as-if-serial 語義只能作用在單執行緒,這裡提到的兩個操作 A 和 B 既可以是在一個執行緒之內,也可以是在不同執行緒之間。也就是說,Happens-before 提供跨執行緒的記憶體可見性保證。
針對這個第 1 條定義,我來舉個例子:
// 以下操作在執行緒 A 中執行
i = 1; // a
// 以下操作在執行緒 B 中執行
j = i; // b
// 以下操作在執行緒 C 中執行
i = 2; // c
假設執行緒 A 中的操作 a Happens-before 執行緒 B 的操作 b,那我們就可以確定操作 b 執行後,變數 j 的值一定是等於 1。
得出這個結論的依據有兩個:一是根據 Happens-before 原則,a 操作的結果對 b 可見,即 「i=1」 的結果可以被觀察到;二是執行緒 C 還沒運行,執行緒 A 操作結束之後沒有其他執行緒會修改變數 i 的值。
現在再來考慮執行緒 C,我們依然保持 a Happens-before b ,而 c 出現在 a 和 b 的操作之間,但是 c 與 b 沒有 Happens-before 關係,也就是說 b 並不一定能看到 c 的操作結果。那麼 b 操作的結果也就是 j 的值就不確定了,可能是 1 也可能是 2,那這段程式碼就是執行緒不安全的。
再來看 Happens-before 的第 2 條定義,這是 JMM 對編譯器和處理器弱記憶體模型的保證,在給予充分的可操作空間下,對編譯器和處理器的重排序進行一定的約束。也就是說,JMM 其實是在遵循一個基本原則:只要不改變程式的執行結果(指的是單執行緒程式和正確同步的多執行緒程式),編譯器和處理器怎麼優化都行。
JMM 這麼做的原因是:程式設計師對於這兩個操作是否真的被重排序並不關心,程式設計師關心的是執行結果不能被改變。
文字可能不是很好理解,我們舉個例子,來解釋下第 2 條定義:雖然兩個操作之間存在 Happens-before 關係,但不意味著 Java 平台的具體實現必須要按照 Happens-before 關係指定的順序來執行。
int a = 1; // A
int b = 2; // B
int c = a + b; // C
根據 Happens-before 規則(下文會講),上述程式碼存在 3 個 Happens-before 關係:
1)A Happens-before B
2)B Happens-before C
3)A Happens-before C
可以看出來,在 3 個 Happens-before 關係中,第 2 個和第 3 個是必需的,但第 1 個是不必要的。
也就是說,雖然 A Happens-before B,但是 A 和 B 之間的重排序完全不會改變程式的執行結果,所以 JMM 是允許編譯器和處理器執行這種重排序的。
看下面這張 JMM 的設計圖更直觀:
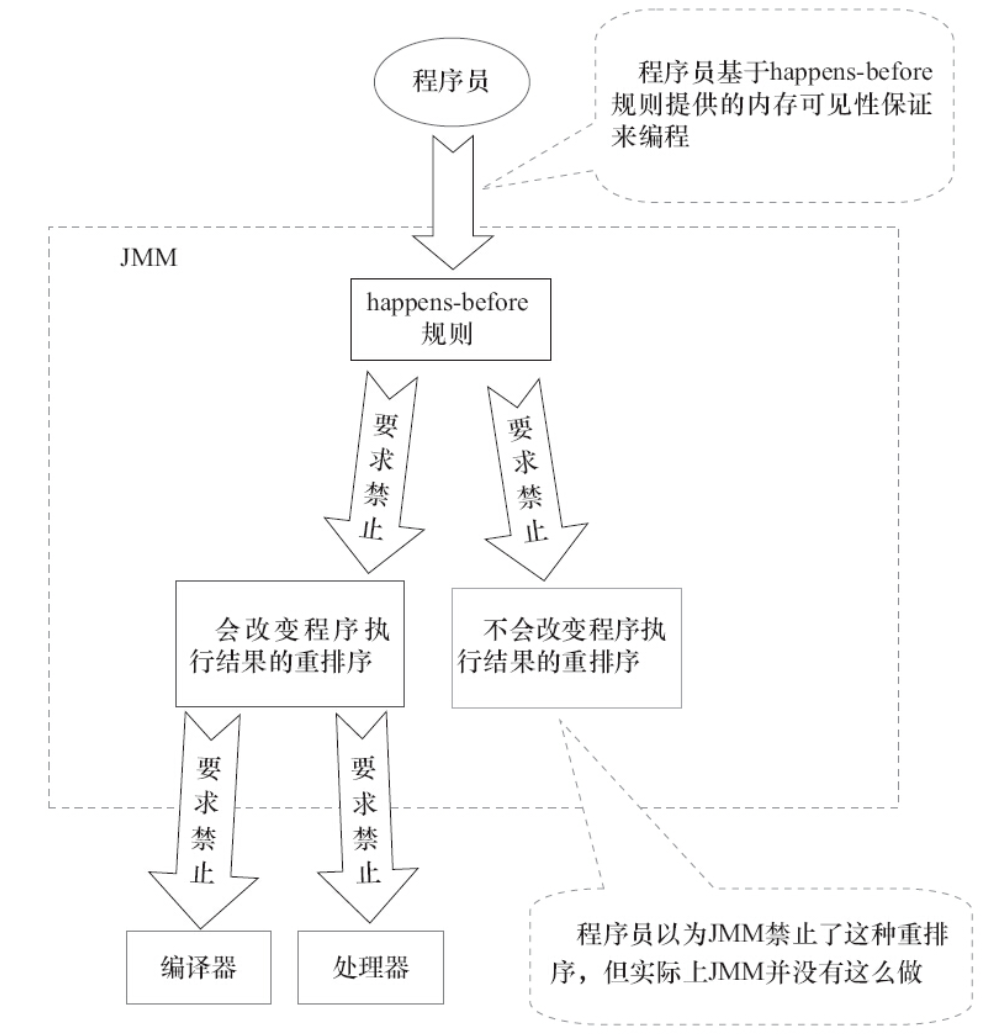
圖片來源《Java 並發編程的藝術》
其實,可以這麼簡單的理解,為了避免 Java 程式設計師為了理解 JMM 提供的記憶體可見性保證而去學習複雜的重排序規則以及這些規則的具體實現方法,JMM 就出了這麼一個簡單易懂的 Happens-before 原則,一個 Happens-before 規則就對應於一個或多個編譯器和處理器的重排序規則,這樣,我們只需要弄明白 Happens-before 就行了。
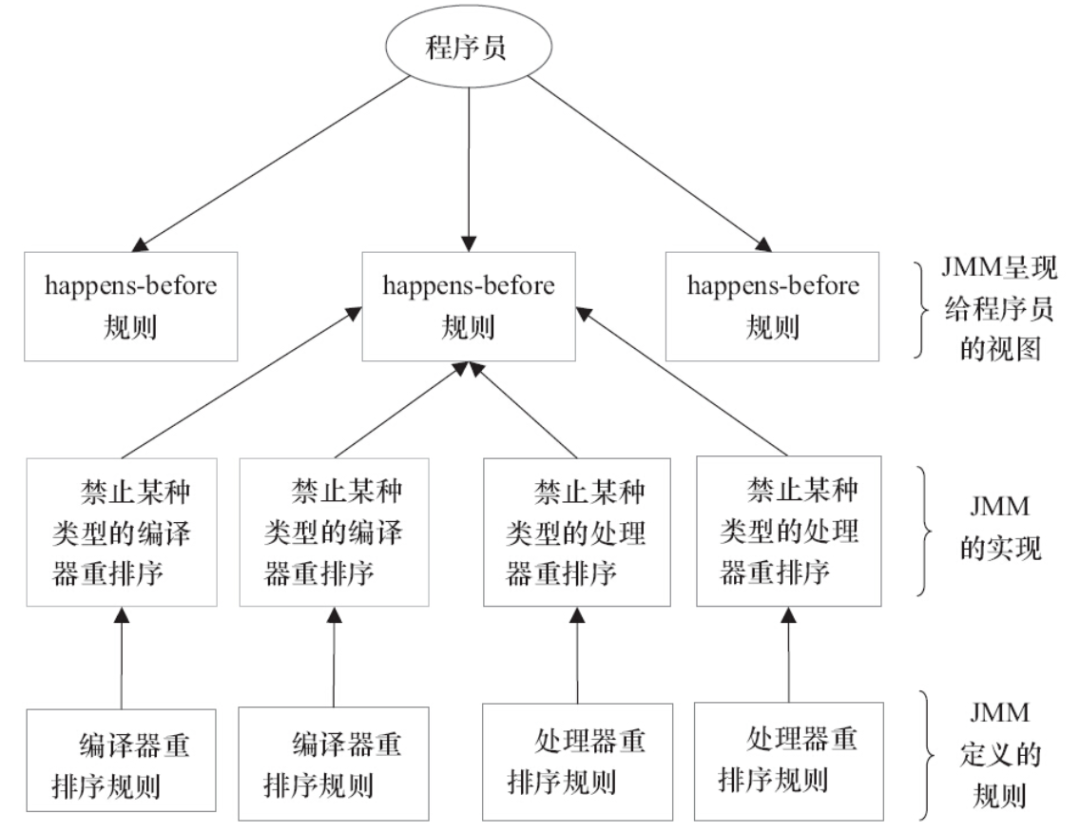
圖片來源《Java 並發編程的藝術》
5.2 八條 Happens-before 規則
《JSR-133:Java Memory Model and Thread Specification》定義了如下 Happens-before 規則, 這些就是 JMM 中「天然的」Happens-before 關係,這些 Happens-before 關係無須任何同步器協助就已經存在,可以在編碼中直接使用。如果兩個操作之間的關係不在此列,並且無法從下列規則推導出來,則它們就沒有順序性保障,JVM 可以對它們隨意地進行重排序。
1)程式次序規則(Program Order Rule):在一個執行緒內,按照控制流順序,書寫在前面的操作先行發生(Happens-before)於書寫在後面的操作。注意,這裡說的是控制流順序而不是程式程式碼順序,因為要考慮分支、循環等結構。
這個很好理解,符合我們的邏輯思維。比如我們上面舉的例子:
int a = 1; // A
int b = 2; // B
int c = a + b; // C
根據程式次序規則,上述程式碼存在 3 個 Happens-before 關係:
- A Happens-before B
- B Happens-before C
- A Happens-before C
2)管程鎖定規則(Monitor Lock Rule):一個 unlock 操作先行發生於後面對同一個鎖的 lock 操作。這裡必須強調的是 「同一個鎖」,而 「後面」 是指時間上的先後。
這個規則其實就是針對 synchronized 的。JVM 並沒有把 lock 和 unlock 操作直接開放給用戶使用,但是卻提供了更高層次的位元組碼指令 monitorenter 和 monitorexit來隱式地使用這兩個操作。這兩個位元組碼指令反映到 Java 程式碼中就是同步塊 — synchronized。
舉個例子:
synchronized (this) { // 此處自動加鎖
if (x < 1) {
x = 1;
}
} // 此處自動解鎖
根據管程鎖定規則,假設 x 的初始值是 10,執行緒 A 執行完程式碼塊後 x 的值會變成 1,執行完自動釋放鎖,執行緒 B 進入程式碼塊時,能夠看到執行緒 A 對 x 的寫操作,也就是執行緒 B 能夠看到 x == 1。
3)volatile 變數規則(Volatile Variable Rule):對一個 volatile 變數的寫操作先行發生於後面對這個變數的讀操作,這裡的 「後面」 同樣是指時間上的先後。
這個規則就是 JDK 1.5 版本對 volatile 語義的增強,其意義之重大,靠著這個規則搞定可見性易如反掌。
舉個例子:
假設執行緒 A 執行 writer() 方法之後,執行緒 B 執行 reader() 方法。
根據根據程式次序規則:1 Happens-before 2;3 Happens-before 4。
根據 volatile 變數規則:2 Happens-before 3。
根據傳遞性規則:1 Happens-before 3;1 Happens-before 4。
也就是說,如果執行緒 B 讀到了 「flag==true」 或者 「int i = a」 那麼執行緒 A 設置的「a=42」對執行緒 B 是可見的。
看下圖:
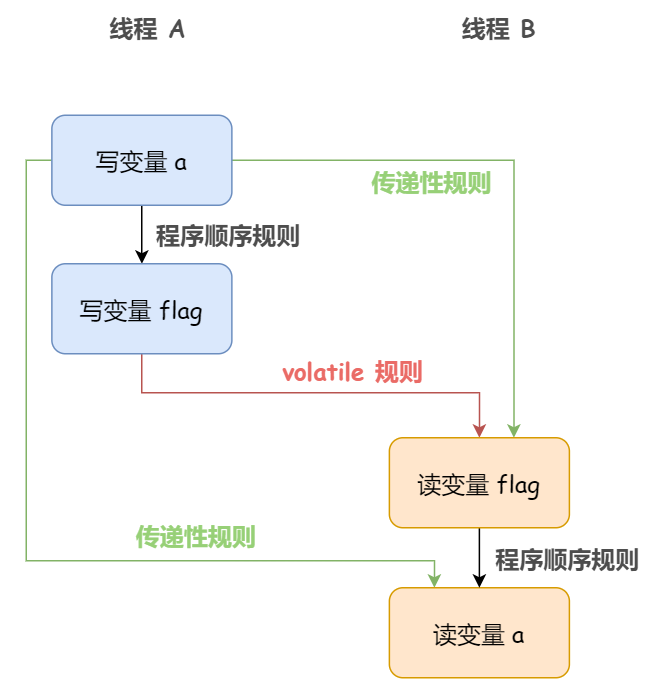
4)執行緒啟動規則(Thread Start Rule):Thread 對象的 start() 方法先行發生於此執行緒的每一個動作。
比如說主執行緒 A 啟動子執行緒 B 後,子執行緒 B 能夠看到主執行緒在啟動子執行緒 B 前的所有操作。
5)執行緒終止規則(Thread Termination Rule):執行緒中的所有操作都先行發生於對此執行緒的終止檢測,我們可以通過 Thread 對象的 join() 方法檢測是否結束、Thread 對象的 isAlive() 的返回值等手段檢測執行緒是否已經終止執行。
6)執行緒中斷規則(Thread Interruption Rule):對執行緒 interrupt() 方法的調用先行發生於被中斷執行緒的程式碼檢測到中斷事件的發生,可以通過 Thread 對象的 interrupted() 方法檢測到是否有中斷髮生。
7)對象終結規則(Finalizer Rule):一個對象的初始化完成(構造函數執行結束)先行發生於它的 finalize() 方法的開始。
8)傳遞性(Transitivity):如果操作 A 先行發生於操作 B,操作 B 先行發生於操作 C,那就可以得出操作 A 先行發生於操作 C 的結論。
5.3「時間上的先發生」 與 「先行發生」
上述 8 種規則中,還不斷提到了時間上的先後,那麼,「時間上的先發生」 與 「先行發生(Happens-before)」 到底有啥區別?
一個操作 「時間上的先發生」 是否就代表這個操作會是「先行發生」 呢?一個操作 「先行發生」 是否就能推導出這個操作必定是「時間上的先發生」呢?
很遺憾,這兩個推論都是不成立的。
舉兩個例子論證一下:
private int value = 0;
// 執行緒 A 調用
pubilc void setValue(int value){
this.value = value;
}
// 執行緒 B 調用
public int getValue(){
return value;
}
假設存在執行緒 A 和 B,執行緒 A 先(時間上的先後)調用了 setValue(1),然後執行緒 B 調用了同一個對象的 getValue() ,那麼執行緒 B 收到的返回值是什麼?
我們根據上述 Happens-before 的 8 大規則依次分析一下:
由於兩個方法分別由執行緒 A 和 B 調用,不在同一個執行緒中,所以程式次序規則在這裡不適用;
由於沒有 synchronized 同步塊,自然就不會發生 lock 和 unlock 操作,所以管程鎖定規則在這裡不適用;
同樣的,volatile 變數規則,執行緒啟動、終止、中斷規則和對象終結規則也和這裡完全沒有關係。
因為沒有一個適用的 Happens-before 規則,所以第 8 條規則傳遞性也無從談起。
因此我們可以判定,儘管執行緒 A 在操作時間上來看是先於執行緒 B 的,但是並不能說 A Happens-before B,也就是 A 執行緒操作的結果 B 不一定能看到。所以,這段程式碼是執行緒不安全的。
想要修復這個問題也很簡單?既然不滿足 Happens-before 原則,那我修改下讓它滿足不就行了。比如說把 Getter/Setter 方法都用 synchronized 修飾,這樣就可以套用管程鎖定規則;再比如把 value 定義為 volatile 變數,這樣就可以套用 volatile 變數規則等。
這個例子,就論證了一個操作 「時間上的先發生」 不代表這個操作會是 「先行發生(Happens-before)」。
再來看一個例子:
// 以下操作在同一個執行緒中執行
int i = 1;
int j = 2;
假設這段程式碼中的兩條賦值語句在同一個執行緒之中,那麼根據程式次序規則,「int i = 1」 的操作先行發生(Happens-before)於 「int j = 2」,但是,還記得 Happens-before 的第 2 條定義嗎?還記得上文說過 JMM 實際上是遵守這樣的一條原則:只要不改變程式的執行結果(指的是單執行緒程式和正確同步的多執行緒程式),編譯器和處理器怎麼優化都行。
所以,「int j=2」 這句程式碼完全可能優先被處理器執行,因為這並不影響程式的最終運行結果。
那麼,這個例子,就論證了一個操作 「先行發生(Happens-before)」 不代表這個操作一定是「時間上的先發生」。
這樣,綜上兩例,我們可以得出這樣一個結論:Happens-before 原則與時間先後順序之間基本沒有因果關係,所以我們在衡量並發安全問題的時候,盡量不要受時間順序的干擾,一切必須以 Happens-before 原則為準。
6. Happens-before 與 as-if-serial
綜上,我覺得其實讀懂了下面這句話也就讀懂了 Happens-before 了,這句話上文也出現過幾次:JMM 其實是在遵循一個基本原則,即只要不改變程式的執行結果(指的是單執行緒程式和正確同步的多執行緒程式),編譯器和處理器怎麼優化都行。
再回顧下 as-if-serial 語義:不管怎麼重排序,單執行緒環境下程式的執行結果不能被改變。
各位發現沒有?本質上來說 Happens-before 關係和 as-if-serial 語義是一回事,都是為了在不改變程式執行結果的前提下,儘可能地提高程式執行的並行度。只不過後者只能作用在單執行緒,而前者可以作用在正確同步的多執行緒環境下:
- as-if-serial 語義保證單執行緒內程式的執行結果不被改變,Happens-before 關係保證正確同步的多執行緒程式的執行結果不被改變。
- as-if-serial 語義給編寫單執行緒程式的程式設計師創造了一個幻境:單執行緒程式是按程式的順序來執行的。Happens-before 關係給編寫正確同步的多執行緒程式的程式設計師創造了一個幻境:正確同步的多執行緒程式是按 Happens-before 指定的順序來執行的。


