Sentry 監控 – Distributed Tracing 分散式跟蹤
- 2021 年 10 月 1 日
- 筆記

系列
- 1 分鐘快速使用 Docker 上手最新版 Sentry-CLI – 創建版本
- 快速使用 Docker 上手 Sentry-CLI – 30 秒上手 Source Maps
- Sentry For React 完整接入詳解
- Sentry For Vue 完整接入詳解
- Sentry-CLI 使用詳解
- Sentry Web 性能監控 – Web Vitals
- Sentry Web 性能監控 – Metrics
- Sentry Web 性能監控 – Trends
- Sentry Web 前端監控 – 最佳實踐(官方教程)
- Sentry 後端監控 – 最佳實踐(官方教程)
- Sentry 監控 – Discover 大數據查詢分析引擎
- Sentry 監控 – Dashboards 數據可視化大屏
- Sentry 監控 – Environments 區分不同部署環境的事件數據
- Sentry 監控 – Security Policy 安全策略報告
- Sentry 監控 – Search 搜索查詢實戰
- Sentry 監控 – Alerts 告警
目錄
- 什麼是跟蹤?
- 為什麼要跟蹤?
- 跟蹤(Traces)、事務(Transactions和跨度(Spans)
- 示例:調查緩慢的頁面載入
- 更多示例
- 跟蹤數據模型
- 更多資訊
- 數據取樣
- 跟蹤中的一致性
公眾號:黑客下午茶
分散式跟蹤(Distributed tracing)通過捕獲軟體系統之間的交互來提供相關錯誤和事務的連接視圖。通過跟蹤,Sentry 可以跟蹤您的軟體性能並顯示跨多個系統的錯誤影響。 通過服務追溯問題將您的前端連接到您的後端。
啟用性能監控以擴充您現有的錯誤數據,跟蹤從前端到後端的交互。通過跟蹤,Sentry 可以跟蹤您的軟體性能,測量吞吐量和延遲等指標,並顯示跨多個系統的錯誤影響。跟蹤使 Sentry 成為更完整的監控解決方案,幫助您更快地診斷問題並衡量應用程式的整體健康狀況。Sentry 中的跟蹤提供了以下見解:
- 特定錯誤事件或
issue發生了什麼 - 導致應用程式出現瓶頸或延遲
issue的條件 - 消耗時間最多的端點或操作
什麼是跟蹤?
首先,請注意跟蹤不是什麼:跟蹤不是分析。 儘管分析和跟蹤的目標有相當多的重疊,雖然它們都可用於診斷應用程式中的問題,但它們在測量內容和數據記錄方式方面有所不同。
profiler 可以測量應用程式操作的多個方面:執行的指令數、各種進程使用的記憶體量、給定函數調用所花費的時間量等等。生成的 profile 是這些測量值的統計匯總。
另一方面,tracing tool 關注發生了什麼(以及何時),而不是發生了多少次或花費了多長時間。 結果跟蹤(resulting trace)是在程式執行期間發生的事件日誌,通常跨多個系統。 儘管跟蹤最常見 – 或者,就 Sentry 的跟蹤而言,總是 – 包括時間戳(timestamps),允許計算持續時間,但測量性能並不是它們的唯一目的。 它們還可以顯示互連繫統交互的方式,以及一個系統中的問題可能導致另一個系統出現問題的方式。
為什麼要跟蹤?
應用程式通常由互連的組件組成,這些組件也稱為服務。 作為一個例子,讓我們看一個現代 Web 應用程式,它由以下組件組成,由網路邊界分隔:
Frontend (Single-Page Application)前端Backend (REST API)後端Task Queue任務隊列Database Server資料庫伺服器Cron Job Scheduler定時任務調度器
這些組件中的每一個都可以在不同的平台上用不同的語言編寫。每個都可以使用 Sentry SDK 單獨檢測以捕獲錯誤數據或崩潰報告,但該檢測不能提供完整的圖片,因為每個部分都是單獨考慮的。跟蹤允許您將所有數據聯繫在一起。
在我們的示例 Web 應用程式中,跟蹤意味著能夠跟蹤從前端到後端和後端的請求,從請求創建的任何後台任務(background tasks)或通知作業(notification jobs)中提取數據。這不僅可以讓您關聯 Sentry 錯誤報告,查看一個服務中的錯誤如何傳播到另一個服務,而且還可以讓您更深入地了解哪些服務可能對應用程式的整體性能產生負面影響。
在學習如何在您的應用程式中啟用跟蹤之前,了解一些關鍵術語以及它們之間的關係會有所幫助。
跟蹤(Traces)、事務(Transactions和跨度(Spans)
trace 表示您要測量或跟蹤的整個操作的記錄 – 例如頁面載入、用戶在應用程式中完成某些操作的實例或後端的 cron job。 當跟蹤包括多個服務中的工作時,例如上面列出的服務,它被稱為分散式跟蹤,因為跟蹤分布在這些服務中。
每個 trace 由一個或多個稱為 transactions 的樹狀結構組成,其節點稱為 spans。 在大多數情況下,每個 transaction 代表被調用服務的單個實例,並且該 transaction 中的每個 span 代表該服務執行單個工作單元,無論是調用該服務中的函數還是調用不同的服務。 這是一個示例跟蹤,分解為事務(transactions)和跨度(spans):

由於事務(transaction)具有樹結構,因此頂級跨度(top-level spans)本身可以分解為更小的跨度(smaller spans),這反映了一個函數可能調用許多其他更小的函數的方式; 這是使用父子隱喻來表達的,因此每個跨度都可能是多個其他子跨度的父跨度。 此外,由於所有樹都必須有一個根,因此每個事務中的一個跨度始終代表事務本身,而事務中的所有其他跨度都從該根跨度下降。這是上圖中事務之一的放大視圖:
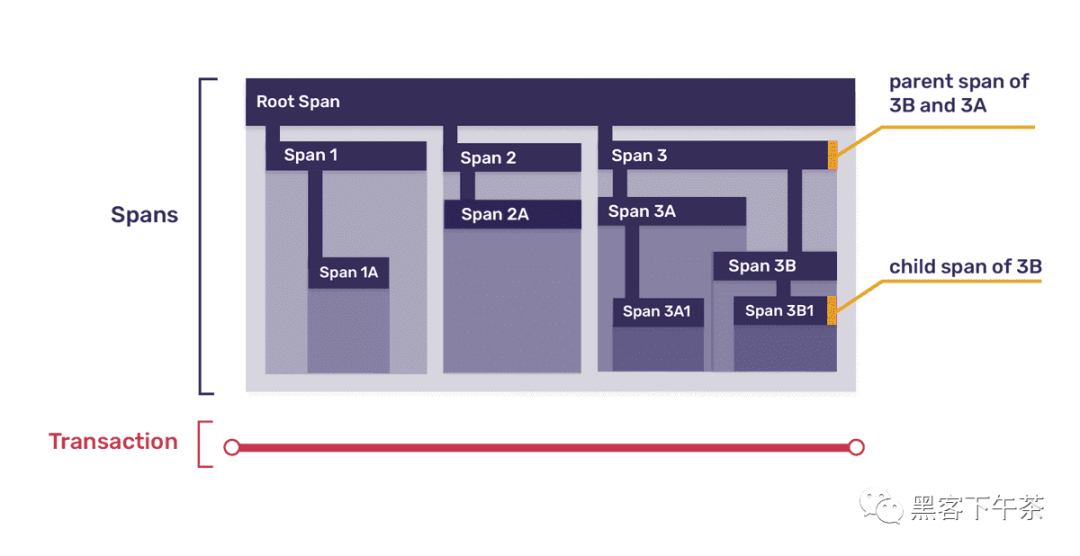
為了使所有這些更具體,讓我們再次考慮我們的示例 Web 應用程式。
示例:調查緩慢的頁面載入
假設您的 Web 應用程式載入緩慢,您想知道原因。 要使您的應用程式首先進入可用狀態,必須發生很多事情:對後端的多個請求,可能是一些工作 – 包括對資料庫或外部 API 的調用 – 在返迴響應之前完成,並由瀏覽器處理以呈現所有 將返回的數據轉化為對用戶有意義的內容。那麼這個過程的哪一部分會減慢速度?
假設在這個簡化的示例中,當用戶在瀏覽器中載入應用程式時,每個服務中都會發生以下情況:
Browser(瀏覽器)HTML、CSS和JavaScript各1個請求1次渲染任務,觸發2次JSON數據請求 ^
Backend(後端)3個提供靜態文件(HTML、CSS和JS)的請求2個JSON數據請求 –1個需要調用資料庫 –1個需要調用外部API並在將結果返回到前端之前處理結果^
Database Server(資料庫伺服器)1個請求需要2次查詢1查詢以檢查身份驗證1查詢獲取數據
注意:外部 API 並未準確列出,因為它是外部的,因此您看不到它的內部。
在此示例中,整個頁面載入過程(包括上述所有過程)由單個 trace 表示。 該跟蹤將由以下事務(transactions)組成:
1個瀏覽器事務(用於頁面載入)5個後端事務(每個請求一個)1個資料庫伺服器事務(用於單個DB請求)
每個事務將被分解為跨度(spans)如下:
- 瀏覽器頁面載入事務:
7個span1個根span代表整個頁面載入HTML、CSS和JS請求各1個(共3個)- 渲染任務的
1個span,它本身包含2個子span,每個JSON請求一個
讓我們在這裡暫停一下以說明一個重點:此處列出的瀏覽器事務中的一些(儘管不是全部)跨度與前面列出的後端事務有直接對應關係。 具體來說,瀏覽器事務中的每個請求跨度對應於後端中的一個單獨的請求事務。 在這種情況下,當一個服務中的跨度引起後續服務中的事務時,我們將原始跨度稱為事務及其根跨度的父跨度。在下圖中,波浪線代表這種父子關係。
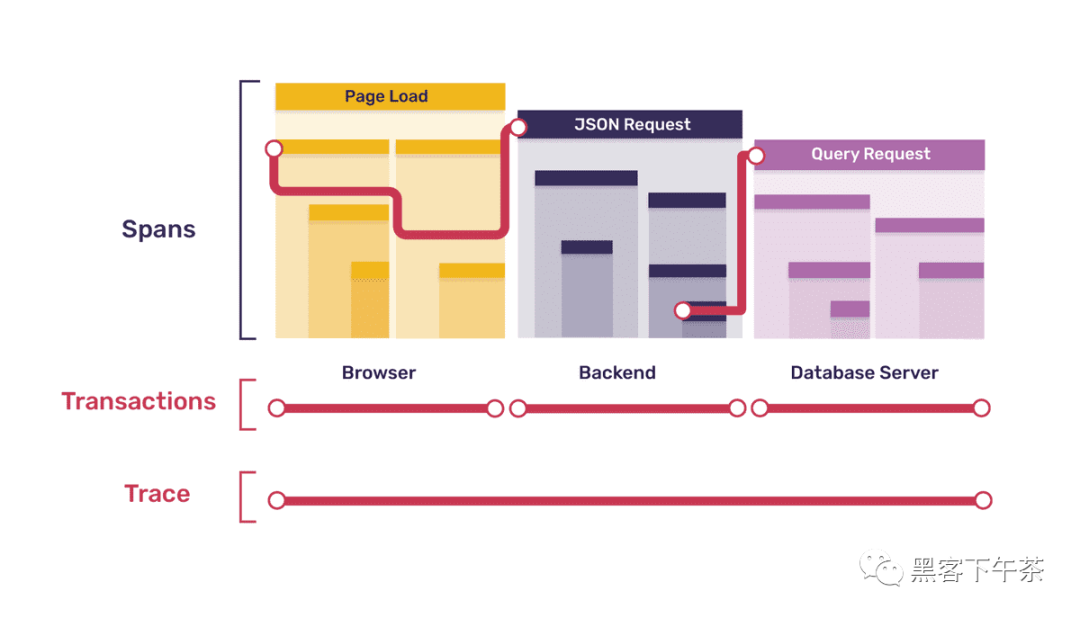
在我們的示例中,除了初始瀏覽器頁面載入事務之外的每個事務都是另一個服務中一個跨度的子項,這意味著除了瀏覽器事務根之外的每個根跨度都有一個父跨度(儘管在不同的服務中)。
在 fully-instrumented 的系統(其中每個服務都啟用了跟蹤的系統)中,這種模式將始終適用。 唯一的無父 span 將是初始 transaction 的根;每隔一個 span 都會有一個父級。 此外,parents 和 children 將始終生活在同一個服務中,除非在子 span 是子 transaction 的根的情況下,在這種情況下,父 span 將在調用服務中,而子 transaction/child 根 span 將在被調用服務中。
換句話說,一個 fully-instrumented 的系統創建一個跟蹤,它本身就是一個連接的樹——每個事務都是一個子樹——在這棵樹中,子樹/事務之間的邊界正是服務之間的邊界。上圖顯示了我們示例的完整跟蹤樹的一個分支。
現在,為了完整起見,回到我們的 spans:
- 後端 HTML/CSS/JS 請求事務:每個 1 個
span- 代表整個請求的 1 個根跨度(瀏覽器跨度的子項)^
- 帶有資料庫調用事務的後端請求:2 個
span- 1 個表示整個請求的根跨度(瀏覽器跨度的子項)
- 1 個跨度用於查詢資料庫(資料庫伺服器事務的父級)^
- 帶有 API 調用事務的後端請求:3 個
span- 1 個表示整個請求的根跨度(瀏覽器跨度的子項)
- API 請求的 1 個跨度(與資料庫調用不同,不是父跨度,因為 API 是外部的)
- 1 個跨度用於處理
API數據^
- 資料庫伺服器請求事務:3 個
span- 1 個代表整個請求的根跨度(上面後端跨度的子項)
- 1 跨度用於身份驗證查詢
- 1 個跨度用於查詢檢索數據的
總結一下這個例子:在檢測了所有服務之後,您可能會發現——出於某種原因——是資料庫伺服器中的身份驗證查詢(auth query)導致了速度變慢,佔了完成整個頁面載入過程所需時間的一半以上。跟蹤無法告訴你為什麼會發生這種情況,但至少現在你知道該去哪裡找了!
更多示例
本節包含更多跟蹤示例,分為事務(transaction)和跨度(span)。
衡量特定的用戶動作
如果您的應用程式涉及電子商務,您可能希望測量從用戶單擊「提交訂單(Submit Order)」到訂單確認出現之間的時間,包括跟蹤向支付處理器提交費用和發送訂單確認電子郵件。 整個過程是一個跟蹤,通常您會有事務 (T) 和跨度 (S) 用於:
- 瀏覽器全過程(T 和根跨度 S)
- 對後端的
XHR請求* (S) - 渲染確認
screen(S)^
- 對後端的
- 您的後端對該請求的處理(T 和根跨度 S)
- 計算總數的函數(
Function)調用 (S) - 存儲訂單資料庫(
DB)調用* (S) - 對支付處理器的
API調用 (S) - 電子郵件確認排隊* (S) ^
- 計算總數的函數(
- 您的資料庫更新客戶訂單歷史的工作(T 和根跨度 S)
- 單個
SQL查詢 (S) ^
- 單個
- 發送電子郵件的排隊任務(T 和根跨度 S)
- 用於填充電子郵件模板的函數調用 (S)
- 對電子郵件發送服務的
API調用 (S)
注意:帶星號的跨度表示作為後續事務(及其根跨度)的父跨度。
監控後台進程
如果您的後端定期輪詢外部服務的數據,對其進行處理、快取,然後將其轉發給內部服務,則發生這種情況的每個實例都是一個跟蹤,您通常會有以下事務 (T) 和跨度 (S):
- 完成整個過程的
cron job(T 和根跨度 S)API調用外部服務 (S)Processing函數 (S)- 調用快取服務* (S)
- API 調用內部服務* (S) ^
- 在您的快取服務中完成的工作(T 和根跨度 S)
- 檢查現有數據的快取 (S)
- 在快取中存儲新數據 (S) ^
- 您的內部服務對請求的處理(T 和根跨度 S)
- 服務可能為處理請求而做的任何事情 (S)
注意:帶星號的跨度表示作為後續事務(及其根跨度)的父跨度。
跟蹤數據模型
「給我看你的流程圖而隱藏你的表,我仍然莫名其妙。如果給我看你的表,那麼我將不再需要你的流程圖,因為它們太明顯了。」
Fred Brooks, 《The Mythical Man-Month》(人月神話)
雖然這個理論很有趣,但最終任何數據結構都是由它包含的數據類型定義的,數據結構之間的關係由它們之間的鏈接如何記錄來定義。跟蹤、事務和跨度也不例外。
Traces(跟蹤)
Traces 本身並不是一個實體。相反,跟蹤被定義為共享一個 trace_id 值的所有事務的集合。
Transactions(事務)
Transactions 與其根跨度共享其大部分屬性(開始和結束時間、標籤等),因此下面描述的跨度的相同選項在事務中可用,並且在任一位置設置它們是等效的。
Transactions 還有一個不包含在跨度中的附加屬性,稱為 transaction_name,它在 UI 中用於標識 transaction。transaction_name 值的常見示例包括後端請求事務的端點路徑(如 /store/checkout/ 或 api/v2/users/<user_id>/)、cron job 事務的任務名稱(如 data.cleanup.delete_inactive_users)和 URL( 像 //docs.sentry.io/performance-monitoring/distributed-tracing/) 用於頁面載入事務。
Spans(跨度)
transaction 中的大部分數據駐留在事務包含的單個 span 中。span 數據包括:
parent_span_id: 將span與其父span聯繫起來op: 標識跨度正在測量的操作類型或類別的短字元串start_timestamp:span打開時end_timestamp:span關閉時description:span操作的較長描述,唯一標識span,但跨span實例保持一致(可選)status: 指示操作狀態的短code(可選)tags:key-value對保存有關跨度的附加數據(可選)data: 關於span的任意結構的附加數據(可選)
op 和 description 屬性一起使用的示例是 op: sql.query 和 description: SELECT * FROM users WHERE last_active < %s。 status 屬性通常用於指示 span 操作的成功或失敗,或者在 HTTP 請求的情況下用於 response code。 最後,tags 和 data 允許您將更多上下文資訊附加到 span,例如 function: middleware.auth.is_authenticated 用於函數調用或 request: {url: ..., headers: ... , body: ...} 用於 HTTP 請求。
更多資訊
關於跟蹤、事務和跨度以及它們相互關聯的方式的一些更重要的點:
Trace Duration(跟蹤持續時間)
因為 trace 只是 transaction 的集合,所以 trace 沒有自己的開始和結束時間。 相反,trace 在其最早的 transaction 開始時開始,並在其最新的 transaction 結束時結束。 因此,您無法直接明確地開始或結束 trace。 相反,您通過在該 trace 中創建第一個 transaction 來創建 trace,並通過完成它包含的所有 transaction 來完成 trace。
Async Transactions(非同步事務)
由於非同步進程的可能性,子事務(child transaction)可能比包含其父跨度(parent span)的事務的壽命長很多數量級。例如,如果後端 API 調用啟動了一個長時間運行的處理任務,然後立即返迴響應,則後端事務將在非同步任務事務完成之前很久完成(並且其數據將被發送到 Sentry)。非同步性還意味著 transaction 發送到(和接收)Sentry 的順序與創建它們的順序沒有任何關係。 (相比之下,同一 trace 中 transaction 的接收順序與完成順序相關,但由於傳輸時間的可變性等因素,相關性遠非完美。)
Orphan Transactions(孤兒事務)
理論上,在一個 fully instrumented 的系統中,每個 trace 應該只包含一個 transaction 和一個 span(transaction的根),沒有父項,即原始服務中的 transaction。但是,在實踐中,您可能不會在每一項服務中都啟用 trace,或者檢測的服務可能由於網路中斷或其他不可預見的情況而無法報告 transaction。發生這種情況時,您可能會在跟蹤層次結構中看到間隙。 具體來說,您可能會在 span 的中途看到其父 span 尚未記錄為任何已知 transaction 的一部分的 transaction。這種非發起、無父 transaction 被稱為孤兒事務。
Nested Spans(嵌套跨度)
儘管我們上面的示例在其層次結構中有四個級別(跟蹤trace、事務transaction、跨度span、子跨度child span),但跨度嵌套的深度沒有設置限制。 但是,存在實際限制:發送到 Sentry 的事務有效負載具有最大允許大小,並且與任何類型的日誌記錄一樣,需要在數據的粒度與其可用性之間取得平衡。
Zero-duration Spans(零持續時間跨度)
跨度可能具有相同的開始時間和結束時間,因此被記錄為不佔用時間。這可能是因為 span 被用作標記(例如在瀏覽器的 Performance API 中完成的),或者因為操作花費的時間少於測量解析度(這將因服務而異)。
Clock Skew(時鐘偏移)
如果您從多台機器收集 transaction,您可能會遇到 clock skew,其中一個 transaction 中的時間戳與另一個 transaction 中的時間戳不一致。 例如,如果您的後端進行資料庫調用,則後端事務在邏輯上應該在資料庫事務之前開始。 但是,如果每台機器(分別託管後端和資料庫的機器)上的系統時間未同步到通用標準,則情況可能並非如此。 排序也有可能是正確的,但是兩個記錄的時間範圍沒有以準確反映實際發生的方式排列。為了減少這種可能性,我們建議使用網路時間協議 (NTP) 或您的雲提供商的時鐘同步服務。
如何發送數據
單個 span 不會發送到 Sentry; 相反,整個 transaction 作為一個單位發送。 這意味著 Sentry 的伺服器不會記錄任何 span 數據,直到它們所屬的 transaction 被關閉和分派。 然而,反過來就不是這樣了——儘管沒有 transaction 就不能發送 span,但 transaction 仍然有效,並且會被發送,即使它們包含的唯一 span 是它們的根 span。
數據取樣
當您在跟蹤設置中啟用取樣時,您可以選擇要發送到 Sentry 的已收集交易的百分比。例如,如果您有一個每分鐘接收 1000 個請求的端點,0.25 的取樣率將導致每分鐘大約 250 個事務 (25%) 被發送到 Sentry。(這個數字是近似的,因為每個請求要麼被跟蹤,要麼被獨立和偽隨機地跟蹤,概率為 25%。因此,以同樣的方式,100 個公平硬幣,在翻轉時會導致大約 50 個正面,SDK 將「決定」 在大約 250 個案例中收集跟蹤。)因為您知道取樣百分比,所以您可以推斷您的總流量。
在收集跟蹤時,我們建議對您的數據進行取樣,原因有兩個。 首先,雖然捕獲單個跟蹤的開銷最小,但捕獲每個頁面載入或每個 API 請求的跟蹤可能會給您的系統增加不希望的負載量。 其次,啟用取樣可以讓您更好地管理髮送到 Sentry 的事件數量,以便您可以根據組織的需求對其進行訂製。
選擇取樣率時,目標是不要收集太多數據(鑒於上述原因),而是收集足夠的數據,以便得出有意義的結論。如果您不確定要選擇什麼速率,我們建議從一個較低的值開始,並隨著您對流量模式和流量的了解逐漸增加,直到找到一個速率,使您能夠平衡性能和流量與數據準確性之間的關係。
跟蹤中的一致性
對於涉及多個事務的跟蹤,Sentry 使用 「基於頭部(head-based)」 的方法:在原始服務中做出取樣決策,然後將該決策傳遞給所有後續服務。要了解這是如何工作的,讓我們回到上面的 webapp示例。考慮兩個用戶 A 和 B,他們都在各自的瀏覽器中載入應用程式。當 A 載入應用程式時,SDK 偽隨機「決定」收集跟蹤,而當 B 載入應用程式時,SDK 「決定」不收集跟蹤。當每個瀏覽器向您的後端發出請求時,它會在這些請求的標題中包含「yes, please collect transactions)」或「no, don't collect transactions this time」的決定。
當您的後端處理來自 A 瀏覽器的請求時,它會看到 「yes」 的決定,收集事務和跨度數據,並將其發送給 Sentry。此外,它在向後續服務(如您的資料庫伺服器)發出的任何請求中都包含「yes」決定,這些服務同樣會收集數據,將數據發送給 Sentry,並將決定傳遞給它們調用的任何服務。通過這個過程,A的跟蹤中的所有相關事務都被收集並發送到 Sentry。
另一方面,當您的後端處理來自 B 瀏覽器的請求時,它會看到 「no」 決定,因此它不會收集和發送事務和跨度數據到 Sentry。然而,它在將決策傳播到後續服務方面做與在 A 的情況下所做的相同的事情,告訴他們也不要收集或發送數據。 然後他們又告訴他們調用的任何服務不要發送數據,這樣就不會收集到來自 B 跟蹤的事務。
簡而言之:這種 head-based 的方法的結果是,決策在原始服務中作出一次,並傳遞給所有後續服務,要麼收集給定跟蹤的所有事務,要麼不收集任何事務,因此不應存在任何不完整的跟蹤。
公眾號:黑客下午茶


