Redis核心原理與實踐–散列類型與字典結構實現原理
- 2021 年 9 月 27 日
- 筆記
- Redis核心原理與實踐
Redis散列類型可以存儲一組無序的鍵值對,它特別適用於存儲一個對象數據。
> HSET fruit name apple price 7.6 origin china
3
> HGET fruit price
"7.6"
本文分析Redis中散列類型以及其底層數據結構–字典的實現原理。
字典
Redis通常使用字典結構存儲用戶散列數據。
字典是Redis的重要數據結構。除了散列類型,Redis資料庫也使用了字典結構。
Redis使用Hash表實現字典結構。分析Hash表,我們通常關注以下幾個問題:
(1)使用什麼Hash演算法?
(2)Hash衝突如何解決?
(3)Hash表如何擴容?
提示:本章程式碼如無特別說明,均在dict.h、dict.c中。
定義
字典中鍵值對的定義如下:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
- key、v:鍵、值。
- next:下一個鍵值對指針。可見Redis字典使用鏈表法解決Hash衝突的問題。
提示:C語言union關鍵字用於聲明共用體,共用體的所有屬性共用同一空間,同一時間只能儲存其中一個屬性值。也就是說,dictEntry.v可以存放val、u64、s64、d中的一個屬性值。使用sizeof函數計算共用體大小,結果不會小於共用體中最大的成員屬性大小。
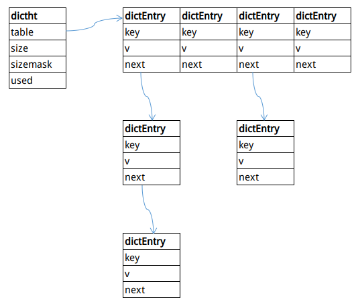
字典中Hash表的定義如下:
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
- table:Hash表數組,負責存儲數據。
- used:記錄存儲鍵值對的數量。
- size:Hash表數組長度。
dictht的結構如圖3-1所示。
字典的定義如下:
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx;
unsigned long iterators;
} dict;
- type:指定操作數據的函數指針。
- ht[2]:定義兩個Hash表用於實現字典擴容機制。通常場景下只使用ht[0],而在擴容時,會創建ht[1],並在操作數據時中逐步將ht[0]的數據移到ht[1]中。
- rehashidx:下一次執行擴容單步操作要遷移的ht[0]Hash表數組索引,-1代表當前沒有進行擴容操作。
- iterators:當前運行的迭代器數量,迭代器用於遍歷字典鍵值對。
dictType定義了字典中用於操作數據的函數指針,這些函數負責實現數據複製、比較等操作。
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
通過dictType指定操作數據的函數指針,字典就可以存放不同類型的數據了。但在一個字典中,鍵、值可以是不同的類型,但鍵必須類型相同,值也必須類型相同。
Redis為不同的字典定義了不同的dictType,如資料庫使用的server.c/dbDictType,散列類型使用的server.c/setDictType等。
操作分析
dictAddRaw函數可以在字典中插入或查找鍵:
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
// [1]
if (dictIsRehashing(d)) _dictRehashStep(d);
// [2]
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
// [3]
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
// [4]
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
// [5]
dictSetKey(d, entry, key);
return entry;
}
參數說明:
- existing:如果字典中已存在參數key,則將對應的dictEntry指針賦值給*existing,並返回null,否則返回創建的dictEntry。
【1】如果該字典正在擴容,則執行一次擴容單步操作。
【2】計算參數key的Hash表數組索引,返回-1,代表鍵已存在,這時dictAddRaw函數返回NULL,代表該鍵已存在。
【3】如果該字典正在擴容,則將新的dictEntry添加到ht[1]中,否則添加到ht[0]中。
【4】創建dictEntry,頭插到Hash表數組對應位置的鏈表中。Redis字典使用鏈表法解決Hash衝突,Hash表數組的元素都是鏈表。
【5】將鍵設置到dictEntry中。
dictAddRaw函數只會插入鍵,並不插入對應的值。可以使用返回的dictEntry插入值:
entry = dictAddRaw(dict,mykey,NULL);
if (entry != NULL) dictSetSignedIntegerVal(entry,1000);
Hash演算法
dictHashKey宏調用dictType.hashFunction函數計算鍵的Hash值:
#define dictHashKey(d, key) (d)->type->hashFunction(key)
Redis中字典基本都使用SipHash演算法(server.c/dbDictType、server.c/setDictType等dictType的hashFunction屬性指向的函數都使用了SipHash演算法)。該演算法能有效地防止Hash表碰撞攻擊,並提供不錯的性能。
Hash演算法涉及較多的數學知識,本書並不討論Hash演算法的原理及實現,讀者可以自行閱讀相關程式碼。
提示:Redis 4.0之前使用的Hash演算法是MurmurHash。即使輸入的鍵是有規律的,該演算法計算的結果依然有很好的離散性,並且計算速度非常快。Redis 4.0開始更換為SipHash演算法,應該是出於安全的考慮。
計算鍵的Hash值後,還需要計算鍵的Hash表數組索引:
static long _dictKeyIndex(dict *d, const void *key, uint64_t hash, dictEntry **existing)
{
unsigned long idx, table;
dictEntry *he;
if (existing) *existing = NULL;
// [1]
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
// [2]
for (table = 0; table <= 1; table++) {
idx = hash & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
if (existing) *existing = he;
return -1;
}
he = he->next;
}
// [3]
if (!dictIsRehashing(d)) break;
}
return idx;
}
【1】根據需要進行擴容或初始化Hash表操作。
【2】遍歷ht[0]、ht[1],計算Hash表數組索引,並判斷Hash表中是否已存在參數key。若已存在,則將對應的dictEntry賦值給*existing。
【3】如果當前沒有進行擴容操作,則計算ht[0]索引後便退出,不需要計算ht[1]。
擴容
Redis使用了一種漸進式擴容方式,這樣設計,是因為Redis是單執行緒的。如果在一個操作內將ht[0]所有數據都遷移到ht[1],那麼可能會引起執行緒長期阻塞。所以,Redis字典擴容是在每次操作數據時都執行一次擴容單步操作,擴容單步操作即將ht[0].table[rehashidx]的數據遷移到ht[1]。等到ht[0]的所有數據都遷移到ht[1],便將ht[0]指向ht[1],完成擴容。
_dictExpandIfNeeded函數用於判斷Hash表是否需要擴容:
static int _dictExpandIfNeeded(dict *d)
{
...
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
擴容需要滿足兩個條件:
(1)d->ht[0].used≥d->ht[0].size:Hash表存儲的鍵值對數量大於或等於Hash表數組的長度。
(2)開啟了dict_can_resize或者負載因子大於dict_force_resize_ratio。
d->ht[0].used/d->ht[0].size,即Hash表存儲的鍵值對數量/Hash表數組的長度,稱之為負載因子。dict_can_resize默認開啟,即負載因子等於1就擴容。負載因子等於1可能出現比較高的Hash衝突率,但這樣可以提高Hash表的記憶體使用率。dict_force_resize_ratio關閉時,必須等到負載因子等於5時才強制擴容。用戶不能通過配置關閉dict_force_resize_ratio,該值的開關與Redis持久化有關,等我們分析Redis持久化時再討論該值。
dictExpand函數開始擴容操作:
int dictExpand(dict *d, unsigned long size)
{
...
// [1]
dictht n;
unsigned long realsize = _dictNextPower(size);
...
// [2]
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
// [3]
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
// [4]
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
參數說明:
- size:新Hash表數組長度。
【1】_dictNextPower函數會將size調整為2的n次冪。
【2】構建一個新的Hash表dictht。
【3】ht[0].table==NULL,代表字典的Hash表數組還沒有初始化,將新dictht賦值給ht[0],現在它就可以存儲數據了。這裡並不是擴容操作,而是字典第一次使用前的初始化操作。
【4】否則,將新dictht賦值給ht[1],並將rehashidx賦值為0。rehashidx代表下一次擴容單步操作要遷移的ht[0] Hash表數組索引。
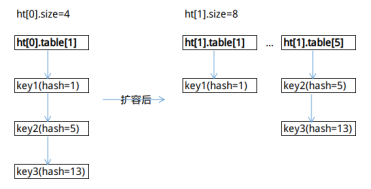
為什麼要將size調整為2的n次冪呢?這樣是為了ht[1] Hash表數組長度是ht[0] Hash表數組長度的倍數,有利於ht[0]的數據均勻地遷移到ht[1]。
我們看一下鍵的Hash表數組索引計算方法:idx=hash&ht.sizemask,由於sizemask= size-1,計算方法等價於:idx=hash%(ht.size)。
因此,假如ht[0].size為n,ht[1].size為2×n,對於ht[0]上的元素,ht[0].table[k]的數據,要不遷移到ht[1].table[k],要不遷移到ht[1].table[k+n]。這樣可以將ht[0].table中一個索引位的數據拆分到ht[1]的兩個索引位上。
圖3-2展示了一個簡單示例。
_dictRehashStep函數負責執行擴容單步操作,將ht[0]中一個索引位的數據遷移到ht[1]中。 dictAddRaw、dictGenericDelete、dictFind、dictGetRandomKey、dictGetSomeKeys等函數都會調用該函數,從而逐步將數據遷移到新的Hash表中。
_dictRehashStep調用dictRehash函數完成擴容單步操作:
int dictRehash(dict *d, int n) {
int empty_visits = n*10;
// [1]
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
assert(d->ht[0].size > (unsigned long)d->rehashidx);
// [2]
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
// [3]
de = d->ht[0].table[d->rehashidx];
while(de) {
uint64_t h;
nextde = de->next;
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
// [4]
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
return 1;
}
參數說明:
- n:本次操作遷移的Hash數組索引的數量。
【1】如果字典當前並沒有進行擴容,則直接退出函數。
【2】從rehashidx開始,找到第一個非空索引位。
如果這裡查找的的空索引位的數量大於n×10,則直接返回。
【3】遍歷該索引位鏈表上所有的元素。
計算每個元素在ht[1]的Hash表數組中的索引,將元素移動到ht[1]中。
【4】ht[0].used==0,代表ht[0]的數據已經全部移到ht[1]中。
釋放ht[0].table,將ht[0]指針指向ht[1],並重置rehashidx、d->ht[1],擴容完成。
縮容
執行刪除操作後,Redis會檢查字典是否需要縮容,當Hash表長度大於4且負載因子小於0.1時,會執行縮容操作,以節省記憶體。縮容實際上也是通過dictExpand函數完成的,只是函數的第二個參數size是縮容後的大小。
dict常用的函數如表3-1所示。
| 函數 | 作用 |
|---|---|
| dictAdd | 插入鍵值對 |
| dictReplace | 替換或插入鍵值對 |
| dictDelete | 刪除鍵值對 |
| dictFind | 查找鍵值對 |
| dictGetIterator | 生成不安全迭代器,可以對字典進行修改 |
| dictGetSafeIterator | 生成安全迭代器,不可對字典進行修改 |
| dictResize | 字典縮容 |
| dictExpand | 字典擴容 |
編碼
散列類型有OBJ_ENCODING_HT和OBJ_ENCODING_ZIPLIST兩種編碼,分別使用dict、ziplist結構存儲數據(redisObject.ptr指向dict、ziplist結構)。Redis會優先使用ziplist存儲散列元素,使用一個ziplist節點存儲鍵,後驅節點存放值,查找時需要遍歷ziplist。使用dict存儲散列元素,字典的鍵和值都是sds類型。散列類型使用OBJ_ENCODING_ZIPLIST編碼,需滿足以下條件:
(1)散列中所有鍵或值的長度小於或等於server.hash_max_ziplist_value,該值可通過hash-max-ziplist-value配置項調整。
(2)散列中鍵值對的數量小於server.hash_max_ziplist_entries,該值可通過hash-max- ziplist-entries配置項調整。
散列類型的實現程式碼在t_hash.c中,讀者可以查看源碼了解更多實現細節。
資料庫
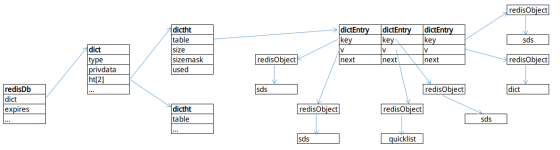
Redis是記憶體資料庫,內部定義了資料庫對象server.h/redisDb負責存儲數據,redisDb也使用了字典結構管理數據。
typedef struct redisDb {
dict *dict;
dict *expires;
dict *blocking_keys;
dict *ready_keys;
dict *watched_keys;
int id;
...
} redisDb;
- dict:資料庫字典,該redisDb所有的數據都存儲在這裡。
- expires:過期字典,存儲了Redis中所有設置了過期時間的鍵及其對應的過期時間,過期時間是long long類型的UNIX時間戳。
- blocking_keys:處於阻塞狀態的鍵和相應的客戶端。
- ready_keys:準備好數據後可以解除阻塞狀態的鍵和相應的客戶端。
- watched_keys:被watch命令監控的鍵和相應客戶端。
- id:資料庫ID標識。
Redis是一個鍵值對資料庫,全稱為Remote Dictionary Server(遠程字典服務),它本身就是一個字典服務。redisDb.dict字典中的鍵都是sds,值都是redisObject。這也是redisObject作用之一,它將所有的數據結構都封裝為redisObject結構,作為redisDb字典的值。
一個簡單的redisDb結構如圖3-3所示。
當我們需要操作Redis數據時,都需要從redisDb中找到該數據。
db.c中定義了hashTypeLookupWriteOrCreate、lookupKeyReadOrReply等函數,可以通過鍵找到redisDb.dict中對應的redisObject,這些函數都是通過調用dict API實現的,這裡不一一展示,感興趣的讀者可以自行閱讀程式碼。
總結:
- Redis字典使用SipHash演算法計算Hash值,並使用鏈表法處理Hash衝突。
- Redis字典使用漸進式擴容方式,在每次數據操作中都執行一次擴容單步操作,直到擴容完成。
- 散列類型的編碼格式可以為OBJ_ENCODING_HT、OBJ_ENCODING_ZIPLIST。
本文內容摘自作者新書《Redis核心原理與實踐》,這本書深入地分析了Redis常用特性的內部機制與實現方式,大部分內容源自對Redis 6.0源碼的分析,並從中總結出設計思路、實現原理。通過閱讀本書,讀者可以快速、輕鬆地了解Redis的內部運行機制。
經過該書編輯同意,我會繼續在個人技術公眾號(binecy)發布書中部分章節內容,作為書的預覽內容,歡迎大家查閱,謝謝。
