Batch Size對神經網路訓練的影響
- 2021 年 9 月 25 日
- 筆記
前言
這篇文章非常全面細緻地介紹了Batch Size的相關問題。結合一些理論知識,通過大量實驗,文章探討了Batch Size的大小對模型性能的影響、如何影響以及如何縮小影響等有關內容。
本文來自公眾號CV技術指南的
歡迎關注公眾號CV技術指南 ,專註於電腦視覺的技術總結、最新技術跟蹤、經典論文解讀。
在本文中,我們試圖更好地理解批量大小對訓練神經網路的影響。具體而言,我們將涵蓋以下內容:
-
什麼是Batch Size?
-
為什麼Batch Size很重要?
-
小批量和大批量如何憑經驗執行?
-
為什麼大批量往往性能更差,如何縮小性能差距?
什麼是Batch Size?
訓練神經網路以最小化以下形式的損失函數:

![]()
-
theta 代表模型參數
-
m 是訓練數據樣本的數量
-
i 的每個值代表一個單一的訓練數據樣本
-
J_i 表示應用於單個訓練樣本的損失函數
通常,這是使用梯度下降來完成的,它計算損失函數相對於參數的梯度,並在該方向上邁出一步。隨機梯度下降計算訓練數據子集 B_k 上的梯度,而不是整個訓練數據集。

![]()
B_k 是從訓練數據集中取樣的一批,其大小可以從 1 到 m(訓練數據點的總數)。這通常稱為批量大小為 |B_k| 的小批量訓練。我們可以將這些批次級梯度視為「true」梯度的近似值,即整體損失函數相對於 theta 的梯度。
我們使用小批量是因為它傾向於更快地收斂,因為它不需要完全遍歷訓練數據來更新權重。
為什麼Batch Size很重要?
Keskar 等人指出,隨機梯度下降是連續的,且使用小批量,因此不容易並行化 。使用更大的批量大小可以讓我們在更大程度上並行計算,因為我們可以在不同的工作節點之間拆分訓練示例。這反過來可以顯著加快模型訓練。
然而,較大的批大小雖然能夠達到與較小的批大小相似的訓練誤差,但往往對測試數據的泛化效果更差 。訓練誤差和測試誤差之間的差距被稱為「泛化差距」。
因此,「holy grail」是使用大批量實現與小批量相同的測試誤差。這將使我們能夠在不犧牲模型準確性的情況下顯著加快訓練速度。
實驗是如何設置的?
我們將使用不同的批量大小訓練神經網路並比較它們的性能。
數據集:我們使用 Cats and Dogs 數據集,該數據集包含 23,262 張貓和狗的影像,在兩個類之間的比例約為 50/50。由於影像大小不同,我們將它們全部調整為相同大小。我們使用 20% 的數據集作為驗證數據,其餘作為訓練數據。
評估指標:我們使用驗證數據上的二元交叉熵損失作為衡量模型性能的主要指標。

![]()
來自 Cats vs Dogs 數據集的示例影像
基礎模型:定義了一個受 VGG16 啟發的基礎模型,在其中重複應用 (convolution ->max-pool) 操作,使用 ReLU 作為卷積的激活函數。然後,將輸出量展平並將其送入兩個完全連接的層,最後是一個帶有 sigmoid 激活的單神經元層,產生一個介於 0 和 1 之間的輸出,它表明模型是預測貓(0)還是 狗 (1).
訓練:使用學習率為 0.01 的 SGD。一直訓練到驗證損失在 100 次迭代中都沒有改善為止。
Batch Size如何影響訓練?

![]()
不同批次大小的訓練和驗證損失曲線

![]()
每個批次大小獲得的最佳損失

![]()
左:每個epoch的平均時間。中間:直到驗證損失收斂的epochs 數量。右圖:直到驗證損失收斂的總訓練時間。
從上圖中,我們可以得出結論,batch size越大:
-
訓練損失減少的越慢。
-
最小驗證損失越高。
-
每個時期訓練所需的時間越少。
-
收斂到最小驗證損失所需的 epoch 越多。
讓我們一一了解這些。首先,在大批量訓練中,訓練損失下降得更慢,如紅線(批量大小 256)和藍線(批量大小 32)之間的斜率差異所示。
其次,大批量訓練比小批量訓練實現更糟糕的最小驗證損失。例如,批量大小為 256 的最小驗證損失為 0.395,而批量大小為 32 時為 0.344。
第三,大批量訓練的每個 epoch 花費的時間略少——批量大小 256 為 7.7 秒,而批量大小 256 為 12.4 秒,這反映了與載入少量大批量相關的開銷較低,而不是許多小批量依次。如果我們使用多個 GPU 進行並行訓練,這種時間差異會更加明顯。
然而,大批量訓練需要更多的 epoch 才能收斂到最小值——批量大小 256 為 958,批量大小 32 為 158。因此,大批量訓練總體上花費的時間更長:批量大小 256 花費的時間幾乎是 32 的四倍!請注意,我們沒有在這裡並行化訓練——如果我們這樣做了,那麼大批量訓練的訓練速度可能與小批量訓練一樣快。
如果我們並行化訓練運行會發生什麼?為了回答這個問題,我們使用 TensorFlow 中的 MirroredStrategy 在四個 GPU 上並行訓練:
with tf.distribute.MirroredStrategy().scope():
# Create, compile, and fit model
# ...![]()
MirroredStrategy 將模型的所有變數複製到每個 GPU,並將前向/後向傳遞計算批量分發到所有 GPU。然後,它使用 all-reduce 組合來自每個 GPU 的梯度,然後將結果應用於每個 GPU 的模型副本。本質上,它正在劃分批次並將每個塊分配給 GPU。
我們發現並行化使每個 epoch 的小批量訓練速度稍慢,而它使大批量訓練速度更快——對於 256 批大小,每個 epoch 需要 3.97 秒,低於 7.70 秒。然而,即使有 per-epoch 加速,它也無法在總訓練時間方面匹配批量大小 32——當我們乘以總訓練時間 (958) 時,我們得到大約 3700 秒的總訓練時間,即 仍然遠大於批大小 32 的 1915 秒。

![]()
當跨 4 個 GPU 並行時,每個 epoch 的平均時間。
到目前為止,大批量訓練看起來並不值得,因為它們需要更長的時間來訓練,並且訓練和驗證損失更嚴重。為什麼會這樣?有什麼辦法可以縮小性能差距嗎?
為什麼較小的批量性能更好?
Keskar 等人對小批量和大批量之間的性能差距提出了一種解釋:使用小批量的訓練傾向於收斂到平坦的極小化,該極小化在極小化的小鄰域內僅略有變化,而大批量則收斂到尖銳的極小化,這變化很大。平面minimizers 傾向於更好地泛化,因為它們對訓練集和測試集之間的變化更加魯棒 。

![]()
取自 Keskar 等人 的平坦和尖銳最小值的概念圖。
此外,他們發現與大批量訓練相比,小批量訓練可以找到距離初始權重更遠的最小值。他們解釋說,小批量訓練可能會為訓練引入足夠的雜訊,以退出銳化minimizers 的損失池,而是找到可能更遠的平坦minimizers 。
讓我們驗證這些假設。
假設 1:與大批量最小化器相比,小批量minimizers 離初始權重更遠。
我們首先測量初始權重和每個模型找到的最小值之間的歐幾里德距離。

![]()
Distance from initial weights

![]()
按層與初始權重的距離,批大小 32 和 256 的比較
事實上,我們發現一般來說,批量越大,最小值越接近初始權重。(除了批量大小 128 比批量大小 64 離初始權重更遠)。我們還在圖 11 中看到,模型中的不同層都是如此。
為什麼大批量訓練最終更接近初始權重?是否採取較小的更新步驟?讓我們通過測量epoch距離——即epoch i 中的最終權重與epoch i 中的初始權重之間的距離——找出批量大小 32 和 256 的原因。
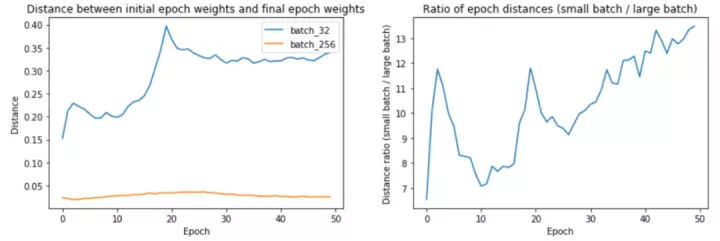
![]()
左圖:按批次大小劃分的epoch距離。右:epoch距離的比率。
上面的第一幅圖顯示,較大的批次大小確實確實在每個 epoch 中遍歷的距離更短。第 32 批訓練的 epoch 距離從 0.15 到 0.4 不等,而第 256 批訓練的距離約為 0.02–0.04。事實上,正如我們在第二個圖中所看到的,epoch距離的比率隨著時間的推移而增加!
但是為什麼大批量訓練每個 epoch 遍歷的距離更短呢?是因為我們的批次較少,因此每個 epoch 的更新較少嗎?還是因為每次批量更新遍歷的距離更短?或者,答案是兩者的結合?
為了回答這個問題,讓我們測量每個批量更新的大小。

![]()
Distribution of batch update sizes
Median batch update norm for batch size 32: 3.3e-3
Median batch update norm for batch size 256: 1.5e-3![]()
我們可以看到,當批大小較大時,每次批更新較小。為什麼會這樣?
為了理解這種行為,讓我們設置一個虛擬場景,其中我們有兩個梯度向量 a 和 b,每個表示一個訓練示例的梯度。讓我們考慮一下批量大小 = 1 的平均批量更新大小與批量大小 = 2 的情況相比如何。

![]()
批量大小 1 (a+b) 和批量大小 2 ((a+b)/2) 之間更新步驟的比較
如果我們使用 1 的批量大小,我們將在 a 的方向上邁出一步,然後是 b,最終在 a+b 表示的點上。(從技術上講,b 的梯度將在應用 a 後重新計算,但我們現在先忽略它)。這導致平均批量更新大小為 (|a|+|b|)/2 — 批量更新大小的總和除以批量更新的數量。
但是,如果我們使用批量大小為 2,批量更新將改為由向量 (a+b)/2 表示 — 圖 12 中的紅色箭頭。因此,平均批量更新大小為 |(a+b)/ 2| / 1 = |a+b|/2。
現在,讓我們比較兩個平均批量更新大小:

![]()
批量大小 1 和批量大小 2 的平均批量更新大小的比較。
在最後一行中,我們使用三角不等式來表明批量大小 1 的平均批量更新大小始終大於或等於批量大小 2 的平均批量更新大小。
換句話說,為了使批量大小 1 和批量大小 2 的平均批量大小相等,向量 a 和 b 必須指向相同的方向,因為那是 |a| 的時候。+ |b| = |a+b|。我們可以將此參數擴展到 n 個向量——只有當所有 n 個向量都指向同一方向時,batch size=1 和 batch size=n 的平均批量更新大小才相同。然而,這幾乎從來都不是這樣的,因為梯度向量不太可能指向完全相同的方向。

![]()
Minibatch update equation
如果我們回到圖 16 中的小批量更新方程,我們在某種意義上說,當我們擴大批量大小 |B_k| 時,梯度總和的大小相對較慢地擴大。這是因為梯度向量指向不同的方向,因此將批量大小(即要加在一起的梯度向量的數量)加倍並不會使生成的梯度向量總和的大小加倍。同時,我們除以分母 |B_k|這是兩倍大,導致整體更新步驟更小。
這可以解釋為什麼更大批量的批量更新往往更小——梯度向量的總和變得更大,但不能完全抵消更大的分母|B_k|。
假設 2:小批量訓練找到更平坦的最小值
現在讓我們測量兩個minimizers的銳度,並評估小批量訓練找到更平坦的minimizers的說法。(請注意,第二個假設可以與第一個假設共存——它們並不相互排斥。)為此,我們從 Keskar 等人那裡借用了兩種方法。
在第一個中,我們沿著小批量minimizers(批量大小 32)和大批量minimizers(批量大小 256)之間的線繪製訓練和驗證損失。這條線由以下等式描述:

![]()
小批量minimizers和大批量minimizers之間的線性插值
其中 x_l* 是大批量minimizers,x_s* 是小批量minimizers,alpha 是一個介於 -1 和 2 之間的係數。

![]()
小批量minimizers (alpha=0) 和大批量minimizers (alpha=1) 之間的插值。大批量最小化器「更清晰」。
正如我們在圖中所見,小批量minimizers (alpha=0) 比大批量minimizers (alpha=1) 平坦得多,後者的變化更加劇烈。
請注意,這是一種相當簡單的銳度測量方法,因為它只考慮一個方向。因此,Keskar 等人提出了一個銳度度量,用于衡量損失函數在最小值附近的鄰域內的變化程度。首先,我們定義鄰域如下:

![]()
最大化損失的約束框。
其中 epsilon 是定義鄰域大小的參數,x 是最小值(權重)。
然後,我們將銳度度量定義為最小值附近的最大損失:

![]()
銳度度量定義。
其中 f 是損失函數,輸入是權重。
使用上面的定義,讓我們計算各種批量大小下的最小化器的銳度,epsilon 值為 1e-3:

![]()
按批次大小的銳度得分
這表明大批量最小化器確實更清晰,正如我們在插值圖中看到的那樣。
最後,讓我們嘗試用 Li 等人制定的過濾器歸一化損失可視化來繪製最小化器。這種類型的圖選擇兩個與模型權重具有相同維度的隨機方向,然後將每個卷積濾波器(或神經元,在 FC 層的情況下)歸一化為與模型權重中的相應濾波器具有相同的範數。這確保了最小化器的銳度不受其權重大小的影響。然後,它沿著這兩個方向繪製損失,圖的中心是我們希望表徵的最小值。

![]()
批量大小為 32(左)和 256(右)的二維濾波器歸一化圖
同樣,我們可以從等高線圖中看到,對於大批量最小化器,損失變化更加劇烈。
通過提高學習率可以提高大批量的性能嗎
在假設 1 中,我們看到大批量的更新大小和每個 epoch 的更新頻率都較低,而在假設 2 中,我們看到大批量無法探索與小批量一樣大的區域。知道了這一點,我們是否可以通過簡單地提高學習率來使大批量訓練表現更好?
這種方法以前曾被建議過,例如 Goyal 等人提出:「線性縮放規則:當 minibatch 大小乘以 k 時,將學習率乘以 k。」
讓我們試試這個,批量大小為 32、64、128 和 256。我們將對批量大小 32 使用 0.01 的基本學習率,並相應地縮放其他批量大小。

![]()
不同批次大小的訓練和驗證損失,調整學習率

![]()
批量大小的最小訓練和驗證損失
事實上,我們發現調整學習率確實消除了小批量和大批量之間的大部分性能差距。現在,批量大小 256 的驗證損失為 0.352 而不是 0.395——更接近批量大小 32 的損失 0.345。
提高學習率如何影響訓練時間?由於大批量訓練現在可以在與小批量訓練大致相同的迭代次數中收斂,如圖 25 中的左圖所示,現在總體訓練時間更短——批量大小 256 為 2197 秒,而批量為 3156 大小為 32。如果我們跨 4 個 GPU 並行化,則加速更加明顯。

![]()
左:直到驗證損失收斂的訓練時期數。右圖:直到收斂的總訓練時間。
這是否意味著大批量現在正在收斂到平面minimizers?如果我們繪製銳度分數,我們可以看到調整學習率確實使大批量最小化器更平坦:

![]()
有無學習率調整的銳度對比
有趣的是,雖然調整學習率使大批量minimizers更平坦,但它們仍然比最小批量最小化器更銳利(4-7 與 1.14 相比)。為什麼會這樣仍然是未來調查的問題。
較大批量的訓練運行現在是否與小批量的初始權重相差甚遠?

![]()
調整前後按批次大小與初始權重的距離
大多數情況下,答案是肯定的。如果我們看上面的圖,調整學習率有助於縮小批量大小 32 與其他批量大小之間在與初始權重的距離方面的差距。(請注意,128 似乎是一個異常,其中增加學習率會降低距離——為什麼會出現這種情況,有待未來調查。)
小批量訓練總是優於大批量訓練嗎?
鑒於上述觀察和文獻,如果我們保持學習率不變,我們可能會期望小批量訓練總是優於大批量訓練。事實上,事實並非如此,正如我們在使用學習率 0.08 時所看到的:

![]()
更高學習率下批量大小的驗證損失
在這裡,我們看到批量大小 64 實際上優於批量大小 32!這是因為學習率和批量大小密切相關——小批量在較小的學習率下表現最好,而大批量在較大的學習率下表現最好。我們可以在下面看到這種現象:

![]()
學習率對不同批次大小的 val 損失的影響。
我們看到,0.01 的學習率對於批大小 32 是最好的,而 0.08 對於其他批大小是最好的。
因此,如果您注意到大批量訓練在相同學習率下優於小批量訓練,這可能表明學習率大於小批量訓練的最佳值。
結論
那麼,這意味著什麼?我們可以從這些實驗中得到什麼?
線性縮放規則:當 minibatch 大小乘以 k 時,將學習率乘以 k。儘管我們最初發現大批量性能更差,但我們能夠通過提高學習率來縮小大部分差距。我們看到這是由於較大的批次大小應用了較小的批次更新,這是由於批次內梯度向量之間的梯度競爭。
選擇合適的學習率時,較大的批量尺寸可以更快地訓練,特別是在並行化時。對於大批量,我們不受 SGD 更新的順序性質的限制,因為我們不會遇到與將許多小批量順序載入到記憶體中相關的開銷。我們還可以跨訓練示例並行化計算。
然而,當學習率沒有針對較大的批量大小向上調整時,大批量訓練可能比小批量訓練花費的時間更長,因為它需要更多的訓練時期來收斂。因此,您需要調整學習率以實現更大批量和並行化的加速。
大批量,即使調整了學習率,在我們的實驗中表現稍差,但需要更多的數據來確定更大的批量是否總體上表現更差。我們仍然觀察到最小批量大小(val loss 0.343)和最大批量大小(val loss 0.352)之間的輕微性能差距。一些人認為小批量具有正則化效果,因為它們將雜訊引入更新,幫助訓練擺脫次優局部最小值的吸引力 。然而,這些實驗的結果表明,性能差距相對較小,至少對於這個數據集。這表明,只要您為批量大小找到合適的學習率,您就可以專註於可能對性能產生更大影響的其他方面的訓練。
作者:Daryl Chang和Apurva Pathak
翻譯:CV技術指南
歡迎關注公眾號 CV技術指南 ,專註於電腦視覺的技術總結、最新技術跟蹤、經典論文解讀。
在公眾號中回復關鍵字 「技術總結」可獲取公眾號原創技術總結文章的匯總pdf。

![]()
其它文章

