MapReduce原理深入理解(一)
1.MapReduce概念
1)MapReduce是一種分散式計算模型,由Google提出,主要用於搜索領域,解決海量數據的計算問題.
2)MapReduce是分散式運行的,由兩個階段組成:Map和Reduce,Map階段是一個獨立的程式,有很多個節點同時運行,每個節點處理一部分數據。Reduce階段是一個獨立的程式,有很多個節點同時運行,每個節點處理一部分數據【在這先把reduce理解為一個單獨的聚合程式即可】。
3)MapReduce框架都有默認實現,用戶只需要覆蓋map()和reduce()兩個函數,即可實現分散式計算,非常簡單。
4)兩個函數的形參和返回值都是<key、value>,使用的時候一定要注意構造<k,v>。
2.MapReduce核心思想
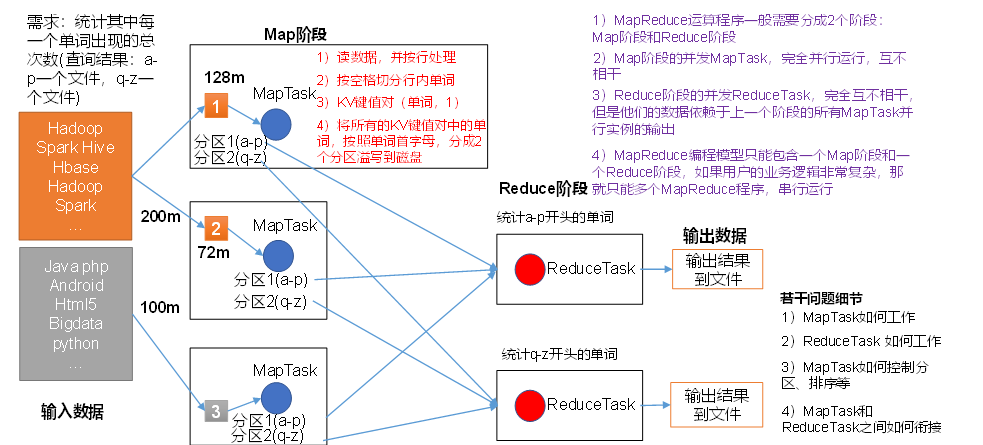
(1)分散式的運算程式往往需要分成至少2個階段。
(2)第一個階段的MapTask並發實例,完全並行運行,互不相干。
(3)第二個階段的ReduceTask並發實例互不相干,但是他們的數據依賴於上一個階段的所有MapTask並發實例的輸出。
(4)MapReduce編程模型只能包含一個Map階段和一個Reduce階段,如果用戶的業務邏輯非常複雜,那就只能多個MapReduce程式,串列運行。
總結:分析WordCount數據流走向深入理解MapReduce核心思想。

3. MapReduce 中的shuffle

4.Mapreduce程式碼
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCount {
//分割任務
// 第一對kv,是決定數據輸入的格式
// 第二隊kv 是決定數據輸出的格式
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
/*map階段數據是一行一行過來的
每一行數據都需要執行程式碼*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
LongWritable longWritable = new LongWritable(1);
String s = value.toString();
context.write(new Text(s), longWritable);
}
}
//接收Map端數據
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
/* reduce 聚合程式 每一個k都會調用一次
* 默認是一個節點
* key:每一個單詞
* values:map端 當前k所對應的所有的v
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//設置統計的初始值為0
long sum = 0l;
for (LongWritable value : values) {
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
}
/**
* 是當前mapreduce程式入口
* 用來構建mapreduce程式
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//創建一個job任務
Job job=Job.getInstance();
//指定job名稱
job.setJobName("第一個mr程式");
//構建mr
//指定當前main所在類名(識別具體的類)
job.setJarByClass(WordCount.class);
//指定map端類
// 指定map輸出的kv類型
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//指定reduce端類
//指定reduce端輸出的kv類型
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 指定輸入路徑
Path in = new Path("/word");
FileInputFormat.addInputPath(job,in);
//輸出路徑指定
Path out = new Path("/output");
FileSystem fs = FileSystem.get(new Configuration());
//如果文件存在
if(fs.exists(out)){
fs.delete(out,true);
}
//存在
FileOutputFormat.setOutputPath(job,out);
//啟動
job.waitForCompletion(true);
System.out.println("MapReduce正在執行");
}
}


