深入淺出 BPF TCP 擁塞演算法實現原理
本文地址://www.ebpf.top/post/ebpf_struct_ops
1. 前言
eBPF 的飛輪仍然在快速轉動,自從 Linux 內核 5.6 版本支援 eBPF 程式修改 TCP 擁塞演算法能力,可通過在用戶態修改內核中擁塞函數結構指針實現;在 5.13 版本中該功能又被進一步優化,增加了該類程式類型直接調用部分內核程式碼的能力,這避免了在 eBPF 程式中需要重複實現內核中使用的 TCP 擁塞演算法相關的函數。
這兩個功能的實現,為 Linux 從宏內核向智慧化的微內核提供的演進,雖然當前只是聚焦在 TCP 擁塞演算法的控制,但是這兩個功能的實現卻具有非常好的想像空間。這是因為 Linux 內核中的諸多功能都是基於結構體指針的方式,當我們具有在用戶編寫的 eBPF 程式完成內核結構體中函數的重定向,則可以實現內核的靈活擴展和功能的增強,再配合內核函數直接的調用能力,等同於為普通用戶提供了訂製內核的能力。儘管這只是 eBPF 一小步,後續卻可能會稱為內核生態的一大步。
本文先聚焦在 5.6 版本為 TCP 擁塞演算法訂製而提供的 STRUCT_OPS 的能力,對於該類型 eBPF 程式調用 Linux 內核函數的能力,我們會在下一篇進行詳細介紹。
2. eBPF 賦能 TCP 擁塞控制演算法
為了支援通過 eBPF 程式可以修改 TCP 擁塞控制演算法的能力,來自於 Facebook 的工程師 Martin KaFai Lau 於 2020-01-08 號提交了一個有 11 個小 Patch 組成的 提交 。實現為 eBPF 增加了 BPF_MAP_TYPE_STRUCT_OPS 新的 map 結構類型和 BPF_PROG_TYPE_STRUCT_OPS 的程式類型,當前階段只支援對於內核中 TCP 擁塞結構 tcp_congestion_ops 的修改。
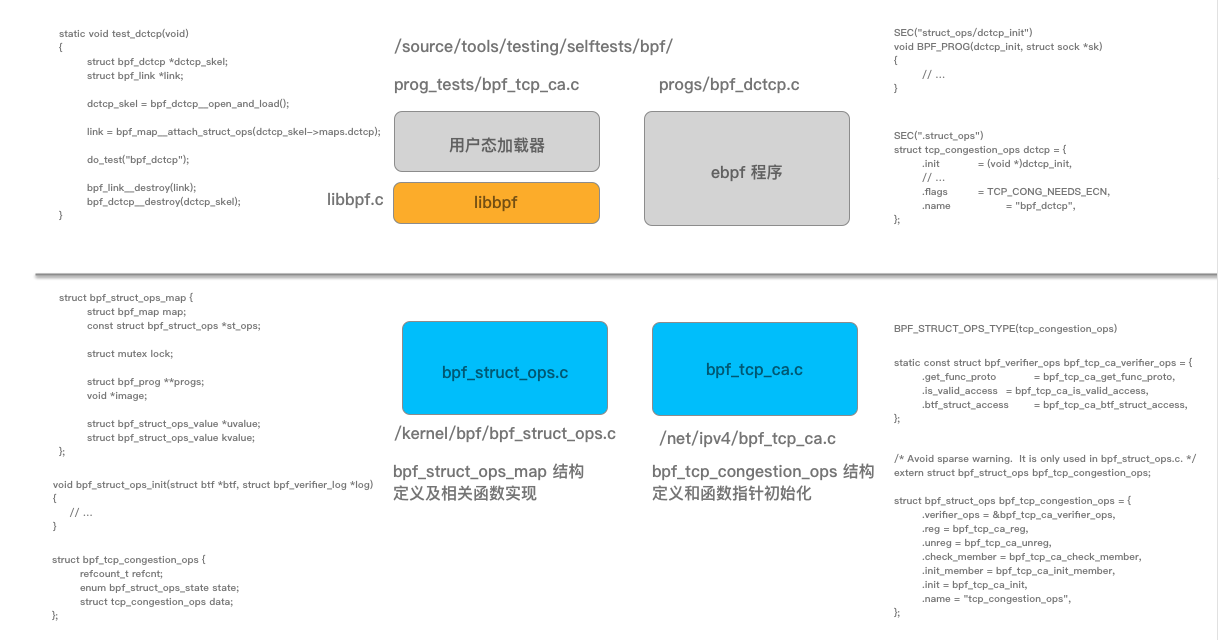
圖 1 整體實現的相關結構和程式碼片段
首先我們從如何使用樣常式序入手(完整程式碼實現參見 這裡 ),這裡我們省略與功能介紹不相干的內容:
SEC("struct_ops/dctcp_init")
void BPF_PROG(dctcp_init, struct sock *sk)
{
const struct tcp_sock *tp = tcp_sk(sk);
struct dctcp *ca = inet_csk_ca(sk);
ca->prior_rcv_nxt = tp->rcv_nxt;
ca->dctcp_alpha = min(dctcp_alpha_on_init, DCTCP_MAX_ALPHA);
ca->loss_cwnd = 0;
ca->ce_state = 0;
dctcp_reset(tp, ca);
}
SEC("struct_ops/dctcp_ssthresh")
__u32 BPF_PROG(dctcp_ssthresh, struct sock *sk)
{
struct dctcp *ca = inet_csk_ca(sk);
struct tcp_sock *tp = tcp_sk(sk);
ca->loss_cwnd = tp->snd_cwnd;
return max(tp->snd_cwnd - ((tp->snd_cwnd * ca->dctcp_alpha) >> 11U), 2U);
}
// ....
SEC(".struct_ops")
struct tcp_congestion_ops dctcp_nouse = {
.init = (void *)dctcp_init,
.set_state = (void *)dctcp_state,
.flags = TCP_CONG_NEEDS_ECN,
.name = "bpf_dctcp_nouse",
};
SEC(".struct_ops")
struct tcp_congestion_ops dctcp = { // bpf 程式定義的結構與內核中使用的結構不一定相同
// 可為必要欄位的組合
.init = (void *)dctcp_init,
.in_ack_event = (void *)dctcp_update_alpha,
.cwnd_event = (void *)dctcp_cwnd_event,
.ssthresh = (void *)dctcp_ssthresh,
.cong_avoid = (void *)tcp_reno_cong_avoid,
.undo_cwnd = (void *)dctcp_cwnd_undo,
.set_state = (void *)dctcp_state,
.flags = TCP_CONG_NEEDS_ECN,
.name = "bpf_dctcp",
};
這裡注意到兩點:
- tcp_congestion_ops 結構體並非內核頭文件里的對應結構體,它只包含了內核對應結構體里 TCP CC 演算法用到的欄位,它是內核對應同名結構體的子集。
- 有些結構體(如 tcp_sock)會看到 preserve_access_index 屬性表示 eBPF 位元組碼在載入的時候,會對這個結構體里的欄位進行重定向,滿足當前內核版本的同名結構體欄位的偏移。
其中需要注意的是在 BPF 程式中定義的 tcp_congestion_ops 結構(也被稱為 bpf-prg btf 類型),該類型可以與內核中定義的結構體完全一致(被稱為 btf_vmlinux btf 類型),也可為內核結構中的部分必要欄位,結構體定義的順序可以不需內核中的結構體一致,但是名字,類型或者函數聲明必須一致(比如參數和返回值)。因此可能需要從 bpf-prg btf 類型到 btf_vmlinux btf 類型的一個翻譯過程,這個轉換過程使用到的主要是 BTF 技術,目前主要是通過成員名稱、btf 類型和大小等資訊進行查找匹配,如果不匹配 libbpf 則會返回錯誤。整個轉換過程與 Go 語言類型中的反射機制類似,主要實現在函數 bpf_map__init_kern_struct_ops 中(見原理章節詳細介紹)。
在 eBPF 程式中增加 section 名字聲明為 .struct_ops,用於 BPF 實現中識別要實現的 struct_ops 結構,例如當前實現的 tcp_congestion_ops 結構。
在 SEC(“.struct_ops”) 下支援同時定義多個 struct_ops 結構。每個 struct_ops 都被定義為 SEC(“.struct_ops”) 下的一個全局變數。libbpf 為每個變數創建了一個 map,map 的名字為定義變數的名字,本例中為 bpf_dctcp_nouse 和 dctcp。
用戶態完整程式碼參見 這裡 ,生成的腳手架相關程式碼參見 這裡 ,與 dctcp 相關的核心程式程式碼如下:
static void test_dctcp(void)
{
struct bpf_dctcp *dctcp_skel;
struct bpf_link *link;
// 腳手架生成的函數
dctcp_skel = bpf_dctcp__open_and_load();
if (CHECK(!dctcp_skel, "bpf_dctcp__open_and_load", "failed\n"))
return;
// bpf_map__attach_struct_ops 增加了註冊一個 struct_ops map 到內核子系統
// 這裡為我們上面定義的 struct tcp_congestion_ops dctcp 變數
link = bpf_map__attach_struct_ops(dctcp_skel->maps.dctcp);
if (CHECK(IS_ERR(link), "bpf_map__attach_struct_ops", "err:%ld\n",
PTR_ERR(link))) {
bpf_dctcp__destroy(dctcp_skel);
return;
}
do_test("bpf_dctcp");
# 銷毀相關的數據結構
bpf_link__destroy(link);
bpf_dctcp__destroy(dctcp_skel);
}
詳細流程解釋如下:
-
在 bpf_object__open 階段,libbpf 將尋找 SEC(“.struct_ops”) 部分,並找出 struct_ops 所實現的 btf 類型。 需要注意的是,這裡的 btf-type 指的是 bpf_prog.o 的 btf 中的一個類型。 “struct bpf_map” 像其他 map 類型一樣, 通過 bpf_object__add_map() 進行添加。 然後 libbpf 會收集(通過 SHT_REL)bpf progs 的位置(使用 SEC(“struct_ops/xyz”) 定義的函數),這些位置是 func ptrs 所指向的地方。 在 open 階段並不需要 btf_vmlinux。
-
在 bpf_object__load 階段,map 結構中的欄位(賴於 btf_vmlinux) 通過
bpf_map__init_kern_struct_ops()初始化。在載入階段,libbpf 還會設置 prog->type、prog->attach_btf_id 和 prog->expected_attach_type 屬性。 因此,程式的屬性並不依賴於它的 section 名稱。目前,bpf_prog btf-type ==> btf_vmlinux btf-type 匹配過程很簡單:成員名匹配 + btf-kind 匹配 + 大小匹配。
如果這些匹配條件失敗,libbpf 將拒絕。目前的目標支援是 “struct tcp_congestion_ops”,其中它的大部分成員都是函數指針。
bpf_prog 的 btf-type 的成員排序可以不同於 btf_vmlinux 的 btf-type。然後,所有 obj->maps 像往常一樣被創建(在 bpf_object__create_maps())。一旦 map 被創建,並且 prog 的屬性都被設置好了,libbpf 就會繼續執行。libbpf 將繼續載入所有的程式。
-
bpf_map__attach_struct_ops() 是用來註冊一個 struct_ops map 到內核子系統中。
關於支援 TCP 擁塞控制演算法的完整 PR 程式碼參見 這裡 。
3. 腳手架程式碼相關實現
關於生成腳手架的樣例過程如下:(腳手架的提交 commit 參見 這裡 ,可以在 這裡 搜索相關關鍵詞查看)。
$ cd tools/bpf/runqslower && make V=1 # 整個過程如下
$ .output/sbin/bpftool btf dump file /sys/kernel/btf/vmlinux format c > .output/vmlinux.h
clang -g -O2 -target bpf -I.output -I.output -I/home/vagrant/linux-5.8/tools/lib -I/home/vagrant/linux-5.8/tools/include/uapi \
-c runqslower.bpf.c -o .output/runqslower.bpf.o && \
$ llvm-strip -g .output/runqslower.bpf.o
$ .output/sbin/bpftool gen skeleton .output/runqslower.bpf.o > .output/runqslower.skel.h
$ cc -g -Wall -I.output -I.output -I/home/vagrant/linux-5.8/tools/lib -I/home/vagrant/linux-5.8/tools/include/uapi -c runqslower.c -o .output/runqslower.o
$ cc -g -Wall .output/runqslower.o .output/libbpf.a -lelf -lz -o .output/runqslower
4. bpf struct_ops 底層實現原理
在上述的過程中對於用戶態程式碼與內核中的主要實現流程已經給與了說明,如果你對內核底層實現原理不感興趣,可以跳過該部分。
4.1 內核中的 ops 結構(bpf_tcp_ca.c)
如圖 1 所示,為了實現該功能,需要在內核程式碼中提供基礎能力支撐,內核中結構對應的操作對象結構(ops 結構)為 bpf_tcp_congestion_ops,定義在 /net/ipv4/bpf_tcp_ca.c 文件中,實現參見 這裡 :
/* Avoid sparse warning. It is only used in bpf_struct_ops.c. */
extern struct bpf_struct_ops bpf_tcp_congestion_ops;
struct bpf_struct_ops bpf_tcp_congestion_ops = {
.verifier_ops = &bpf_tcp_ca_verifier_ops,
.reg = bpf_tcp_ca_reg,
.unreg = bpf_tcp_ca_unreg,
.check_member = bpf_tcp_ca_check_member,
.init_member = bpf_tcp_ca_init_member,
.init = bpf_tcp_ca_init,
.name = "tcp_congestion_ops",
};
bpf_tcp_congestion_ops 結構中的各個函數說明如下:
- init() 函數將被首先調用,以進行任何需要的全局設置;
- init_member() 則驗證該結構中任何欄位的確切值。特別是,init_member() 可以驗證非函數欄位(例如,標誌欄位);
- check_member() 確定目標結構的特定成員是否允許在 BPF 中實現;
- reg() 函數在檢查通過後實際註冊了替換結構;在擁塞控制的情況下,它將把 tcp_congestion_ops 結構(帶有用於函數指針的適當的 BPF 蹦床(trampolines ))安裝在網路堆棧將使用它的地方;
- unreg() 撤銷註冊;
- verifier_ops 結構有一些函數,用於驗證各個替換函數是否可以安全執行;
其中 verfier_ops 結構主要用於驗證器(verfier)的判斷,其中定義的函數如下:
static const struct bpf_verifier_ops bpf_tcp_ca_verifier_ops = {
.get_func_proto = bpf_tcp_ca_get_func_proto,// 驗證器使用的函數原型,用於驗證是否允許在 eBPF 程式中的
// BPF_CALL 內核內的輔助函數,並在驗證後調整 BPF_CALL 指令中的 imm32 域。
.is_valid_access = bpf_tcp_ca_is_valid_access, // 是否是合法的訪問
.btf_struct_access = bpf_tcp_ca_btf_struct_access, // 用於判斷 btf 中結構體是否可以被訪問
};
最後,在 kernel/bpf/bpf_struct_ops_types.h 中添加一行:
BPF_STRUCT_OPS_TYPE(tcp_congestion_ops)
4.2 內核 ops 對象結構定義和管理(bpf_struct_ops.c)
在 bpf_struct_ops.c 文件中,通過包含 “bpf_struct_ops_types.h” 文件 4 次,並分別設置 BPF_STRUCT_OPS_TYPE 宏,實現了 map 中 value 值結構的定義和內核定義 ops 對象數組的管理功能,同時也包括對應數據結構 BTF 中的定義。
/* bpf_struct_ops_##_name (e.g. bpf_struct_ops_tcp_congestion_ops) is
* the map's value exposed to the userspace and its btf-type-id is
* stored at the map->btf_vmlinux_value_type_id.
*
*/
#define BPF_STRUCT_OPS_TYPE(_name) \
extern struct bpf_struct_ops bpf_##_name; \
\
struct bpf_struct_ops_##_name { \
BPF_STRUCT_OPS_COMMON_VALUE; \
struct _name data ____cacheline_aligned_in_smp; \
};
#include "bpf_struct_ops_types.h" // ① 用於生成 bpf_struct_ops_tcp_congestion_ops 結構
#undef BPF_STRUCT_OPS_TYPE
enum {
#define BPF_STRUCT_OPS_TYPE(_name) BPF_STRUCT_OPS_TYPE_##_name,
#include "bpf_struct_ops_types.h" // ② 生成一個 enum 成員
#undef BPF_STRUCT_OPS_TYPE
__NR_BPF_STRUCT_OPS_TYPE,
};
static struct bpf_struct_ops * const bpf_struct_ops[] = {
#define BPF_STRUCT_OPS_TYPE(_name) \
[BPF_STRUCT_OPS_TYPE_##_name] = &bpf_##_name,
#include "bpf_struct_ops_types.h" // ③ 生成一個數組中的成員 [BPF_STRUCT_OPS_TYPE_tcp_congestion_ops]
// = &bpf_tcp_congestion_ops
#undef BPF_STRUCT_OPS_TYPE
};
void bpf_struct_ops_init(struct btf *btf, struct bpf_verifier_log *log)
{
/* Ensure BTF type is emitted for "struct bpf_struct_ops_##_name" */
#define BPF_STRUCT_OPS_TYPE(_name) BTF_TYPE_EMIT(struct bpf_struct_ops_##_name);
#include "bpf_struct_ops_types.h" // ④ BTF_TYPE_EMIT(struct bpf_struct_ops_tcp_congestion_ops btf 註冊
#undef BPF_STRUCT_OPS_TYPE
// ...
}
編譯完整展開後相關的結構:
extern struct bpf_struct_ops bpf_tcp_congestion_ops;
struct bpf_struct_ops_tcp_congestion_ops { // ① 作為 map 類型的 value 對象存儲
refcount_t refcnt;
enum bpf_struct_ops_state state
struct tcp_congestion_ops data ____cacheline_aligned_in_smp; // 內核中的 tcp_congestion_ops 對象
};
enum {
BPF_STRUCT_OPS_TYPE_tcp_congestion_ops // ② 序號聲明
__NR_BPF_STRUCT_OPS_TYPE,
};
static struct bpf_struct_ops * const bpf_struct_ops[] = { // ③ 作為數組變數
// 其中 bpf_tcp_congestion_ops 即為 /net/ipv4/bpf_tcp_ca.c 文件中定義的變數(包含了各種操作的函數指針)
[BPF_STRUCT_OPS_TYPE_tcp_congestion_ops] = &bpf_tcp_congestion_ops,
};
void bpf_struct_ops_init(struct btf *btf, struct bpf_verifier_log *log)
{
// #define BTF_TYPE_EMIT(type) ((void)(type *)0)
((void)(struct bpf_struct_ops_tcp_congestion_ops *)0); // ④ BTF 類型註冊
// ...
}
至此內核完成了 ops 結構的類型的生成、註冊和 ops 對象數組的管理。
4.3 map 中內核結構值初始化
該過程涉及將 bpf 程式中定義變數初始化 kernl 內核變數,該過程在 libbpf 庫中的 bpf_map__init_kern_struct_ops 函數中實現。 函數原型為:
/* Init the map's fields that depend on kern_btf */
static int bpf_map__init_kern_struct_ops(struct bpf_map *map,
const struct btf *btf,
const struct btf *kern_btf)
使用 bpf 程式結構初始化 map 結構變數的主要流程如下:
- bpf 程式載入過程中會識別出來定義的 BPF_MAP_TYPE_STRUCT_OPS map 對象;
- 獲取到 struct ops 定義的變數類型(如 struct tcp_congestion_ops dctcp)中的 tcp_congestion_ops 類型,使用獲取到 tname/type/type_id 設置到 map 結構中的 st_ops 對象中;
- 通過上一步驟設置的 tname 屬性在內核的 btf 資訊表中查找內核中 tcp_congestion_ops 類型的 type_id 和 type 等資訊,同時也獲取到 map 對象中 value 值類型 bpf_struct_ops_tcp_congestion_ops 的 vtype_id 和 vtype 類型;
- 至此已經拿到了 bpf 程式中定義的變數及 bpf_prog btf-type tcp_congestion_ops, 內核中定義的類型 tcp_congestion_ops 以及 map 值類型的 bpf_struct_ops_tcp_congestion_ops 等資訊;
- 接下來的事情就是通過特定的 btf 資訊規則(名稱、調用參數、返回類型等)將 bpf_prog btf-type 變數初始化到 bpf_struct_ops_tcp_congestion_ops 變數中,將內核中的變數初始化以後,放入到 st_ops->kern_vdata 結構中(bpf_map__attach_struct_ops() 函數會使用 st_ops->kern_vdata 更新 map 的值,map 的 key 固定為 0 值(表示第一個位置);
- 然後設置 map 結構中的 btf_vmlinux_value_type_id 為 vtype_id 共後續檢查和使用, map->btf_vmlinux_value_type_id = kern_vtype_id;
5. 總結
從表面上看,擁塞控制是 BPF 的一項重要的新功能,但是從底層的實現我們可以看到,這個功能的實現遠比該功能更加通用,相信在不久的將來還有會更加豐富的實現,在軟體中定義內核功能的實現會帶給我們不一樣的體驗。
具體來說,該基礎功能可以用來讓一個 BPF 程式取代內核中的任何使用函數指針的 ” 操作結構 “,而且內核程式碼的很大一部分是通過至少一個這樣的結構調用的。如果我們可以替換全部或部分 security_hook_heads 結構,我們就可以以任意的方式修改安全策略,例如類似於 KRSI 的建議。替換一個 file_operations 結構可以重新連接內核的 I/O 子系統的任何部分。
現在還沒有人提出要做這些事情,但是這種能力肯定會吸引感興趣的用戶。有一天,幾乎所有的內核功能都可以被用戶空間的 BPF 程式碼鉤住或替換。在這樣的世界裡,用戶將有很大的權力來改變他們系統的運行方式,但是我們認為的 “Linux 內核 ” 將變得更加無定形,因為諸多功能可能會取決於哪些程式碼從用戶空間載入。


