C#中List是鏈表嗎?為什麼可以通過下標訪問
使用C#的同學對List應該並不陌生,我們不需要初始化它的大小,並且可以方便的使用Add和Remove方法執行添加和刪除操作,但卻可以使用下標來訪問它的數據,它是我們常說的鏈表嗎?
List<int> ls = new List<int>();
ls.Add(1);
Console.WriteLine(ls[0]); //輸出 1
先簡單回顧一下鏈表的概念。
什麼是鏈表
鏈表是一種線性表數據結構,在記憶體中它可以是非連續的,通過在每個結點中使用指針存儲下一個結點的地址來實現邏輯順序。一個結點由兩部分組成:一個是存儲數據元素的數據域,另一個是存儲下一個結點地址的指針域。
鏈表由很多種類,常見的有:單鏈表、雙鏈表和循環鏈表,它們實現的原理差別不大,相對於單鏈表只是多添加了一些特定的功能,所以今天主要講解最簡單、最常用的單鏈表。
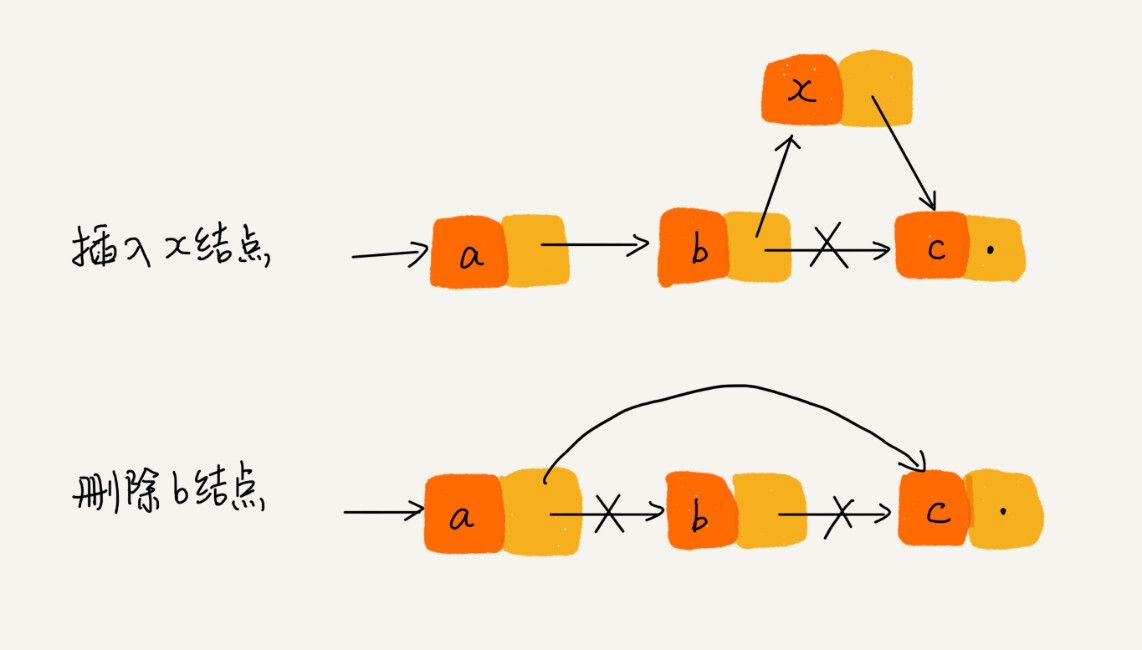
單鏈表添加、刪除結點
單鏈表查找指定結點
數組可以通過下標和定址公式使用O(1)的時間複雜度來訪問指定結點,但是由於鏈表結點在記憶體中可以是非連續的,無法通過定址公式計算對應的記憶體地址,所以要查找一個結點就只能依次遍歷,時間複雜度為O(n).
C#中的List
既然鏈表不能通過下標訪問,那上面例子中ls[0]為什麼會輸出1呢?
查看源碼,首先從它的Add方法開始,在vs中點擊f12進入,發現跳轉到List類內部的SynchronizedList類中,Add函數定義如下
public void Add(T item)
{
lock (_root)
{
_list.Add(item);
}
}
目前還沒有看出什麼問題,繼續查看 _list.Add方法
public void Add(T item)
{
if (_size == _items.Length)
{
//確保不超出容量,否則會執行擴容操作
EnsureCapacity(_size + 1);
}
_items[_size++] = item;
_version++;
}
_items[_size++] = item這句看起來是不是很眼熟,不就是向數組中添加一個元素嘛。為了嚴謹,我們再查看_items是什麼
private const int _defaultCapacity = 4;
private T[] _items;
private int _size;
private int _version;
果不其然,_items就是一個泛型數組,並且還有_size、_version等其他欄位
原來List其實並不是鏈表,在記憶體中它也是使用數組來進行存儲的,只是對添加、刪除等操作進行了封裝,並且使其能夠「自動擴容」。
LinkedList鏈表
這才是C#中真正的鏈表,不過它不是最簡單的單鏈表,而是一個雙鏈表。單鏈表只有一個指針結點指向它的下一個元素,而雙鏈表中每個結點有兩個指針結點,一個指向它的下一個元素,另一個指向它的上一個元素。

下面是LinkedListNode的部分源碼,可以看到它包含一個next指針和一個prev指針。
internal LinkedList<T> list;
internal LinkedListNode<T> next;
internal LinkedListNode<T> prev;
具體怎麼使用,這裡就不具體講解了,看官方文檔也比較容易理解。
鏈表和數組的區別
ok,現在我們對數組和鏈表都有了一定程度上的了解,那能不能歸納出它們之間有哪些區別呢?對數組有不清楚的地方,可以查看文章
-
從邏輯結構上看,它們都是屬於線性表這個數據結構
-
從記憶體上來看,數組是順序存儲,佔用一塊連續的記憶體,大小固定,擴容成本大;鏈表是鏈式存儲,也就是非連續的,並且因為它多了一個指針,所以不存在大小限制,天然支援動態擴容,但佔用的記憶體也更大。
-
訪問操作:數組可以支援「隨機訪問」,O(1)的時間複雜度;鏈表需要按順序逐個訪問,O(n)的時間複雜度.
-
添加和刪除操作:數組的時間複雜度為O(n); 鏈表的時間複雜度為O(1)
-
作業系統記憶體管理方面,藉助CPU的快取機制,可以預讀數組的內容,所以訪問效率更高,而鏈表則不行。
總結