k8s核心資源之namespace與pod污點容忍度生命周期進階篇(四)
註:因編輯器的問題yaml語法格式可能顯示不正確
1、命名空間namespace
1.1 什麼是命名空間?
Kubernetes 支援多個虛擬集群,它們底層依賴於同一個物理集群。 這些虛擬集群被稱為命名空間。
命名空間namespace是k8s集群級別的資源,可以給不同的用戶、租戶、環境或項目創建對應的命名空間,例如,可以為test、devlopment、production環境分別創建各自的命名空間。
1.2 namespace應用場景
命名空間適用於存在很多跨多個團隊或項目的用戶的場景。對於只有幾到幾十個用戶的集群,根本不需要創建或考慮命名空間。
1、查看名稱空間及其資源對象
k8s集群默認提供了幾個名稱空間用於特定目的,例如,kube-system主要用於運行系統級資源,存放k8s一些組件的。而default則為那些未指定名稱空間的資源操作提供一個默認值。
使用kubectl get namespace可以查看namespace資源,使用kubectl describe namespace $NAME可以查看特定的名稱空間的詳細資訊。
2、管理namespace資源
namespace資源屬性較少,通常只需要指定名稱即可創建,如「kubectl create namespace qa」。namespace資源的名稱僅能由字母、數字、下劃線、連接線等字元組成。刪除namespace資源會級聯刪除其包含的所有其他資源對象。
1.3 namespacs常用指令
① 創建一個test命名空間
# kubectl create ns test
② 切換命名空間
# kubectl config set-context --current --namespace=kube-system
#切換命名空間後,kubectl get pods 如果不指定-n,查看的就是kube-system命名空間的資源了。
#查看哪些資源屬於命名空間級別的
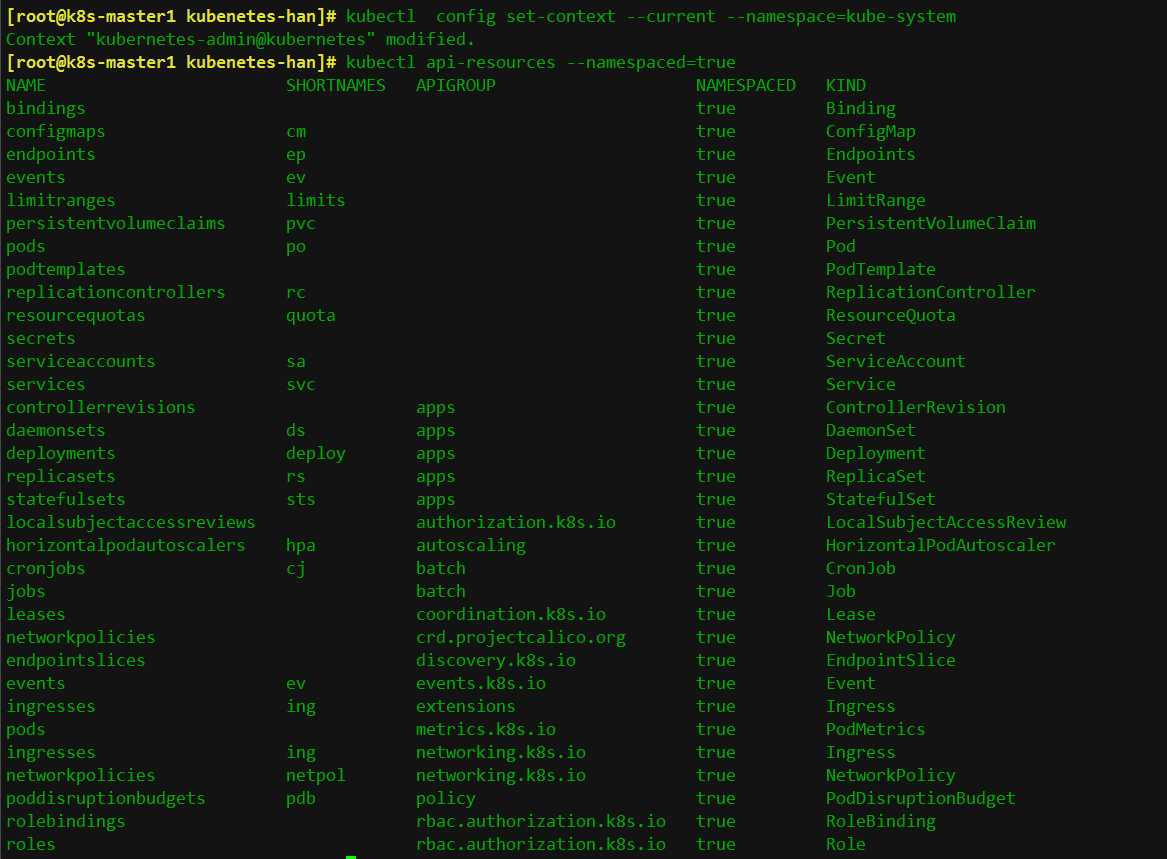
1.4 namespace資源限額
namespace是命名空間,裡面有很多資源,那麼我們可以對命名空間資源做個限制,防止該命名空間部署的資源超過限制。
如何對namespace資源做限額呢?
# vim namespace-quota.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-quota
namespace: test
spec:
hard:
requests.cpu: "2"
requests.memory: 2Gi
limits.cpu: "4"
limits.memory: 4Gi
#創建的ResourceQuota對象將在test名字空間中添加以下限制:
每個容器必須設置記憶體請求(memory request),記憶體限額(memory limit),cpu請求(cpu request)和cpu限額(cpu limit)。
所有容器的記憶體請求總額不得超過2GiB。
所有容器的記憶體限額總額不得超過4 GiB。
所有容器的CPU請求總額不得超過2 CPU。
所有容器的CPU限額總額不得超過4CPU。
#創建pod時候必須設置資源限額,否則創建失敗,如下:
# vim pod-test.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-test
namespace: test
labels:
app: tomcat-pod-test
spec:
containers:
- name: tomcat-test
ports:
- containerPort: 8080
image: hxu/tomcat-8.5-jre8:v1
imagePullPolicy: IfNotPresent
[root@k8s-master1 ~]# kubectl apply -f pod-test.yaml
[root@k8s-master1 kubenetes-han]# kubectl get pod -n test
NAME READY STATUS RESTARTS AGE
pod-test 1/1 Running 0 67s
2、標籤
2.1 什麼是標籤?
標籤其實就一對 key/value ,被關聯到對象上,比如Pod,標籤的使用我們傾向於能夠表示對象的特殊特點,就是一眼就看出了這個Pod是幹什麼的,標籤可以用來劃分特定的對象(比如版本,服務類型等),標籤可以在創建一個對象的時候直接定義,也可以在後期隨時修改,每一個對象可以擁有多個標籤,但是,key值必須是唯一的。創建標籤之後也可以方便我們對資源進行分組管理。如果對pod打標籤,之後就可以使用標籤來查看、刪除指定的pod。
在k8s中,大部分資源都可以打標籤。
2.2 如何給pod資源打標籤
顯示如下,顯示如下,說明標籤達成功了;
[root@k8s-master1 kubenetes-han]# kubectl get pods pod-test -n test --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod-test 1/1 Running 0 3m55s app=tomcat-pod-test
# 1、對已經存在的pod打標籤,release=v1
[root@k8s-master1 kubenetes-han]# kubectl label pods pod-test release=v1 -n test
pod/pod-test labeled
# 2、查看標籤是否打成功:
[root@k8s-master1 kubenetes-han]# kubectl get pods pod-test -n test --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod-test 1/1 Running 0 4m40s app=tomcat-pod-test,release=v1
2.3 查看資源標籤
查看默認名稱空間下所有pod資源的標籤
[root@k8s-master1 kubenetes-han]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
demo-pod 1/1 Running 0 15d app=myapp,env=dev
nginx-test-57f9f5b6d7-8zt7x 1/1 Running 0 38m app=nginx,pod-template-hash=57f9f5b6d7
nginx-test-57f9f5b6d7-fxsw5 1/1 Running 0 8d app=nginx,pod-template-hash=57f9f5b6d7
test-nginx-67b6d886b6-ccrvd 1/1 Running 0 13d k8s-app=test-nginx,pod-template-hash=67b6d886b6
test-nginx-67b6d886b6-qgjdh 1/1 Running 0 13d k8s-app=test-nginx,pod-template-hash=67b6d886b6
用法示例:
# 查看默認名稱空間下指定pod具有的所有標籤
kubectl get pods pod-first --show-labels
# 列出默認名稱空間下標籤key是release的pod,不顯示標籤
kubectl get pods -l release
#列出默認名稱空間下標籤key是release、值是v1的pod,不顯示標籤
kubectl get pods -l release=v1
#列出默認名稱空間下標籤key是release的所有pod,並列印對應的標籤值
kubectl get pods -L release
#查看所有名稱空間下的所有pod的標籤
kubectl get pods --all-namespaces --show-labels
kubectl get pods -l release=v1 -L release
3、node節點選擇器
我們在創建pod資源的時候,pod會根據schduler進行調度,那麼默認會調度到隨機的一個工作節點,如果我們想要pod調度到指定節點或者調度到一些具有相同特點的node節點,怎麼辦呢?
可以使用pod中的nodeName或者nodeSelector欄位指定要調度到的node節點
1、nodeName:
指定pod節點運行在哪個具體node上
先來編寫一個yaml文件,指定調度節點為k8s-node1節點,我這裡只有一個虛擬機所以看不出來效果,如有多個虛擬機可以指定其他的node節點的主機名!
[root@k8s-master1 kubenetes-han]# cat pod-node.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
namespace: default
labels:
app: myapp
env: dev
spec:
nodeName: k8s-node1 #此處指定調度到哪個節點,寫node的主機名
containers:
- name: tomcat-pod-java
ports:
- containerPort: 8080
image: tomcat:8.5-jre8-alpine
imagePullPolicy: IfNotPresent
- name: busybox
image: busybox:latest
command:
- "/bin/sh"
- "-c"
- "sleep 3600"
# kubectl apply -f pod-node.yaml
查看pod調度到哪個節點
[root@k8s-master1 kubenetes-han]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
demo-pod 2/2 Running 0 2m 10.244.1.21 k8s-node1 <none> <none>
4、nodeSelector:
指定pod調度到具有哪些標籤的node節點上
給node節點打標籤,打個具有disk=ceph的標籤
# kubectl label nodes k8s-node2 disk=ceph
node/k8s-node2 labeled
# 定義pod的時候指定要調度到具有disk=ceph標籤的node上
編輯一個yaml文件
[root@k8s-master1 kubenetes-han]# cat pod-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo-pod-1
namespace: default
labels:
app: myapp
env: dev
spec:
nodeSelector: # 加上nodeselector
disk: ceph # 値
containers:
- name: tomcat-pod-java
ports:
- containerPort: 8080
image: tomcat:8.5-jre8-alpine
imagePullPolicy: IfNotPresent
讀取yaml文件並創建pod
[root@k8s-master1 kubenetes-han]# kubectl apply -f pod-1.yaml
pod/demo-pod-1 created
[root@k8s-master1 kubenetes-han]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
demo-pod 2/2 Running 68 2d21h 10.244.1.21 k8s-node1 <none> <none>
demo-pod-1 0/1 ContainerCreating 0 3s <none> k8s-node2 # 調度到了node2上 <none> <none>
nginx-test-57f9f5b6d7-8zt7x 1/1 Running 0 2d22h 10.244.1.19 k8s-node1 <none> <none>
nginx-test-57f9f5b6d7-fxsw5 1/1 Running 0 11d 10.244.1.16 k8s-node1 <none> <none>
test-nginx-67b6d886b6-ccrvd 1/1 Running 0 15d 10.244.1.8 k8s-node1 <none> <none>
test-nginx-67b6d886b6-qgjdh 1/1 Running 0 15d 10.244.1.9 k8s-node1 <none> <none>
5、親和性
5.1 node節點親和性
node節點親和性調度:nodeAffinity
# kubectl explain pods.spec.affinity
KIND: Pod
VERSION: v1
RESOURCE: affinity <Object>
DESCRIPTION:
If specified, the pod's scheduling constraints
Affinity is a group of affinity scheduling rules.
FIELDS:
nodeAffinity <Object>
podAffinity <Object>
podAntiAffinity <Object>
# kubectl explain pods.spec.affinity.nodeAffinity
KIND: Pod
VERSION: v1
RESOURCE: nodeAffinity <Object>
DESCRIPTION:
Describes node affinity scheduling rules for the pod.
Node affinity is a group of node affinity scheduling rules.
FIELDS:
preferredDuringSchedulingIgnoredDuringExecution <[]Object>
requiredDuringSchedulingIgnoredDuringExecution <Object>
prefered表示有節點盡量滿足這個位置定義的親和性,這不是一個必須的條件,軟親和性
require表示必須有節點滿足這個位置定義的親和性,這是個硬性條件,硬親和性
# kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution
KIND: Pod
VERSION: v1
RESOURCE: requiredDuringSchedulingIgnoredDuringExecution <Object>
DESCRIPTION:
FIELDS:
nodeSelectorTerms <[]Object> -required-
Required. A list of node selector terms. The terms are ORed.
# kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms
KIND: Pod
VERSION: v1
RESOURCE: nodeSelectorTerms <[]Object>
DESCRIPTION:
Required. A list of node selector terms. The terms are ORed.
A null or empty node selector term matches no objects. The requirements of
them are ANDed. The TopologySelectorTerm type implements a subset of the
NodeSelectorTerm.
FIELDS:
matchExpressions <[]Object>
matchFields <[]Object>
matchExpressions:匹配表達式的
matchFields: 匹配欄位的
# kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms.matchFields
KIND: Pod
VERSION: v1
RESOURCE: matchFields <[]Object>
DESCRIPTION:
FIELDS:
key <string> -required-
values <[]string>
# kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms.matchExpressions
KIND: Pod
VERSION: v1
RESOURCE: matchExpressions <[]Object>
DESCRIPTION:
FIELDS:
key <string> -required-
operator <string> -required-
values <[]string>
key:檢查label
operator:做等值選則還是不等值選則
values:給定值
5.1.1 硬親和性
例1:使用requiredDuringSchedulingIgnoredDuringExecution硬親和性
#把myapp-v1.tar.gz上傳到兩個node主機中並load -i
在master節點編輯yaml文件
# cat pod-nodeaffinity-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-node-affinity-demo
namespace: default
labels:
app: myapp
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: In
values:
- foo
- bar
我們檢查當前節點中有任意一個節點擁有zone標籤的值是foo或者bar,就可以把pod調度到這個node節點的foo或者bar標籤上的節點上
[root@k8s-master1 kubenetes-han]# kubectl apply -f pod-nodeaffinity-demo.yaml
pod/pod-node-affinity-demo created
[root@k8s-master1 kubenetes-han]# kubectl get pods -o wide | grep pod-node
pod-node-affinity-demo 0/1 Pending 0 2s <none>
status的狀態是pending,上面說明沒有完成調度,因為沒有一個擁有zone的標籤的值是foo或者bar,而且使用的是硬親和性,必須滿足條件才能完成調度
[root@k8s-master1 kubenetes-han]# kubectl label nodes k8s-node2 zone=foo
node/k8s-node2 labeled
[root@k8s-master1 kubenetes-han]# kubectl get pods -o wide | grep pod-node
pod-node-affinity-demo 1/1 Running 0 78s 10.244.2.3 k8s-node2
5.1.2 軟親和性
例2:使用preferredDuringSchedulingIgnoredDuringExecution軟親和性
# cat pod-nodeaffinity-demo-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-node-affinity-demo-2
namespace: default
labels:
app: myapp
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
matchExpressions:
- key: zone1
operator: In
values:
- foo1
- bar1
weight: 60
[root@k8s-master1 kubenetes-han]# kubectl apply -f pod-nodeaffinity-demo-2.yaml
pod/pod-node-affinity-demo-2 created
[root@k8s-master1 kubenetes-han]# kubectl get pods -o wide |grep demo-2
pod-node-affinity-demo-2 1/1 Running 0 2s 10.244.2.4 k8s-node2
上面說明軟親和性是可以運行這個pod的,儘管沒有運行這個pod的節點定義的zone1標籤
Node節點親和性針對的是pod和node的關係,Pod調度到node節點的時候匹配的條件
5.2 Pod節點親和性
pod自身的親和性調度有兩種表示形式
podaffinity:pod和pod更傾向膩在一起,把相近的pod結合到相近的位置,如同一區域,同一機架,這樣的話pod和pod之間更好通訊,比方說有兩個機房,這兩個機房部署的集群有1000台主機,那麼我們希望把nginx和tomcat都部署同一個地方的node節點上,可以提高通訊效率;
podunaffinity:pod和pod更傾向不膩在一起,如果部署兩套程式,那麼這兩套程式更傾向於反親和性,這樣相互之間不會有影響。
第一個pod隨機選則一個節點,做為評判後續的pod能否到達這個pod所在的節點上的運行方式,這就稱為pod親和性;我們怎麼判定哪些節點是相同位置的,哪些節點是不同位置的;我們在定義pod親和性時需要有一個前提,哪些pod在同一個位置,哪些pod不在同一個位置,這個位置是怎麼定義的,標準是什麼?以節點名稱為標準,這個節點名稱相同的表示是同一個位置,節點名稱不相同的表示不是一個位置。
幫助:
# kubectl explain pods.spec.affinity.podAffinity
KIND: Pod
VERSION: v1
RESOURCE: podAffinity <Object>
DESCRIPTION:
Describes pod affinity scheduling rules (e.g. co-locate this pod in the
same node, zone, etc. as some other pod(s)).
Pod affinity is a group of inter pod affinity scheduling rules.
FIELDS:
preferredDuringSchedulingIgnoredDuringExecution <[]Object>
requiredDuringSchedulingIgnoredDuringExecution <[]Object>
requiredDuringSchedulingIgnoredDuringExecution: 硬親和性
preferredDuringSchedulingIgnoredDuringExecution:軟親和性
# kubectl explain pods.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution
KIND: Pod
VERSION: v1
RESOURCE: requiredDuringSchedulingIgnoredDuringExecution <[]Object>
DESCRIPTION:
FIELDS:
labelSelector <Object>
namespaces <[]string>
topologyKey <string> -required-
topologyKey:
位置拓撲的鍵,這個是必須欄位
怎麼判斷是不是同一個位置:
rack=rack1
row=row1
使用rack的鍵是同一個位置
使用row的鍵是同一個位置
labelSelector:
我們要判斷pod跟別的pod親和,跟哪個pod親和,需要靠labelSelector,通過labelSelector選則一組能作為親和對象的pod資源
namespace:
labelSelector需要選則一組資源,那麼這組資源是在哪個名稱空間中呢,通過namespace指定,如果不指定namespaces,那麼就是當前創建pod的名稱空間
# kubectl explain pods.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution.labelSelector
KIND: Pod
VERSION: v1
RESOURCE: labelSelector <Object>
DESCRIPTION:
A label query over a set of resources, in this case pods.
A label selector is a label query over a set of resources. The result of
matchLabels and matchExpressions are ANDed. An empty label selector matches
all objects. A null label selector matches no objects.
FIELDS:
matchExpressions <[]Object>
matchLabels <map[string]string>
5.2.1 pod節點親和性
例1:
定義兩個pod,第一個pod做為基準,第二個pod跟著它走
# cat pod-required-affinity-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-first
labels:
app2: myapp2
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
---
apiVersion: v1
kind: Pod
metadata:
name: pod-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- {key: app2, operator: In, values: ["myapp2"]}
topologyKey: kubernetes.io/hostname
#上面表示創建的pod必須與擁有app=myapp標籤的pod在一個節點上
# kubectl apply -f pod-required-affinity-demo.yaml
kubectl get pods -o wide 顯示如下:
[root@k8s-master1 kubenetes-han]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-first 1/1 Running 0 24s 10.244.2.5 k8s-node2
pod-second 1/1 Running 0 24s 10.244.2.6 k8s-node2
上面說明第一個pod調度到哪,第二個pod也調度到哪,這就是pod節點親和性
注意:查看node節點的標籤可以使用–show-labels查看
kubectl get nodes –show-labels
5.2.2 Pod節點反親和性
例2:
定義兩個pod,第一個pod做為基準,第二個pod跟它調度節點相反
在master節點編輯yaml文件
# cat pod-required-anti-affinity-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-first
labels:
app1: myapp1
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
---
apiVersion: v1
kind: Pod
metadata:
name: pod-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- {key: app1, operator: In, values: ["myapp1"]}
topologyKey: kubernetes.io/hostname
# kubectl apply -f pod-required-anti-affinity-demo.yaml
# 顯示兩個pod不在一個node節點上,這就是pod節點反親和性
[root@k8s-master1 kubenetes-han]# kubectl get pods -o wide
pod-first 1/1 Running 0 4s 10.244.2.7 k8s-node2
pod-second 1/1 Running 0 4s 10.244.1.22 k8s-node1
# kubectl delete -f pod-required-anti-affinity-demo.yaml
例3:換一個topologykey
[root@k8s-master1 kubenetes-han]# kubectl label nodes k8s-node1 zone=foo
[root@k8s-master1 kubenetes-han]# kubectl label nodes k8s-node2 zone=foo --overwrite
# cat pod-first-required-anti-affinity-demo-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-first
labels:
app3: myapp3
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
# cat pod-second-required-anti-affinity-demo-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- {key: app3 ,operator: In, values: ["myapp3"]}
topologyKey: zone
[root@k8s-master1 kubenetes-han]# kubectl apply -f pod-first-required-anti-affinity-demo-1.yaml
pod/pod-first created
[root@k8s-master1 kubenetes-han]# kubectl apply -f pod-second-required-anti-affinity-demo-1.yaml
pod/pod-second created
[root@k8s-master1 kubenetes-han]# kubectl get pod -o wide顯示如下:
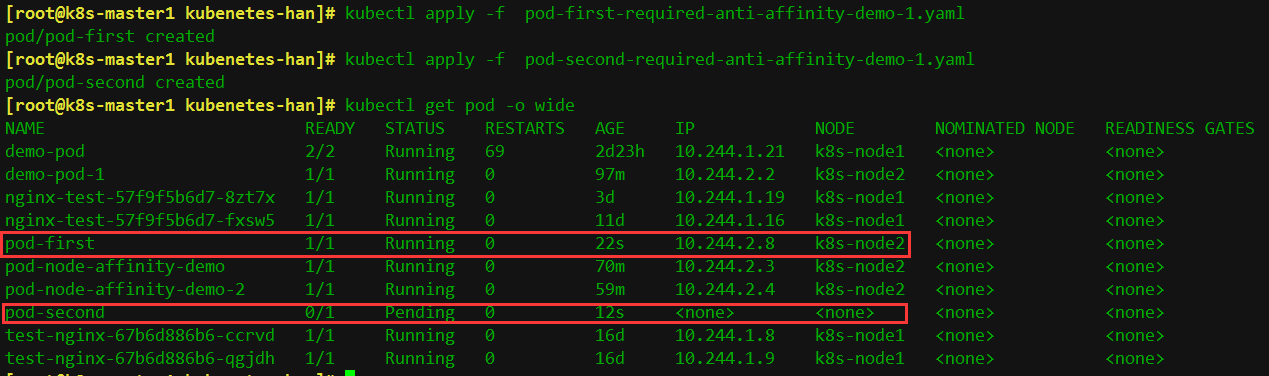
第二個pod現在是pending,因為兩個節點是同一個位置,現在沒有不是同一個位置的了,而且我們要求反親和性,所以就會處於pending狀態,如果在反親和性這個位置把required改成preferred,那麼也會運行。
podaffinity:pod節點親和性,pod傾向於哪個pod
nodeaffinity:node節點親和性,pod傾向於哪個node
6、污點、容忍度
給了節點選則的主動權,我們給節點打一個污點,不容忍的pod就運行不上來,污點就是定義在節點上的鍵值屬性數據,可以定決定拒絕那些pod;
taints是鍵值數據,用在節點上,定義污點;
tolerations是鍵值數據,用在pod上,定義容忍度,能容忍哪些污點
pod親和性是pod屬性;但是污點是節點的屬性,污點定義在nodeSelector上
# kubectl describe nodes k8s-master1
Taints: node-role.kubernetes.io/master:NoSchedule
# kubectl explain node.spec.taints
KIND: Node
VERSION: v1
RESOURCE: taints <[]Object>
DESCRIPTION:
If specified, the node's taints.
The node this Taint is attached to has the "effect" on any pod that does
not tolerate the Taint.
FIELDS:
effect <string> -required-
key <string> -required-
timeAdded <string>
value <string>
taints的effect用來定義對pod對象的排斥等級(效果):
NoSchedule:
僅影響pod調度過程,當pod能容忍這個節點污點,就可以調度到當前節點,後來這個節點的污點改了,加了一個新的污點,使得之前調度的pod不能容忍了,那這個pod會怎麼處理,對現存的pod對象不產生影響
NoExecute:
既影響調度過程,又影響現存的pod對象,如果現存的pod不能容忍節點後來加的污點,這個pod就會被驅逐
PreferNoSchedule:
最好不,也可以,是NoSchedule的柔性版本
在pod對象定義容忍度的時候支援兩種操作:
1.等值密鑰:key和value上完全匹配
2.存在性判斷:key和effect必須同時匹配,value可以是空
在pod上定義的容忍度可能不止一個,在節點上定義的污點可能多個,需要琢個檢查容忍度和污點能否匹配,每一個污點都能被容忍,才能完成調度,如果不能容忍怎麼辦,那就需要看pod的容忍度了
# kubectl describe nodes k8s-master1
查看master這個節點是否有污點,顯示如下:
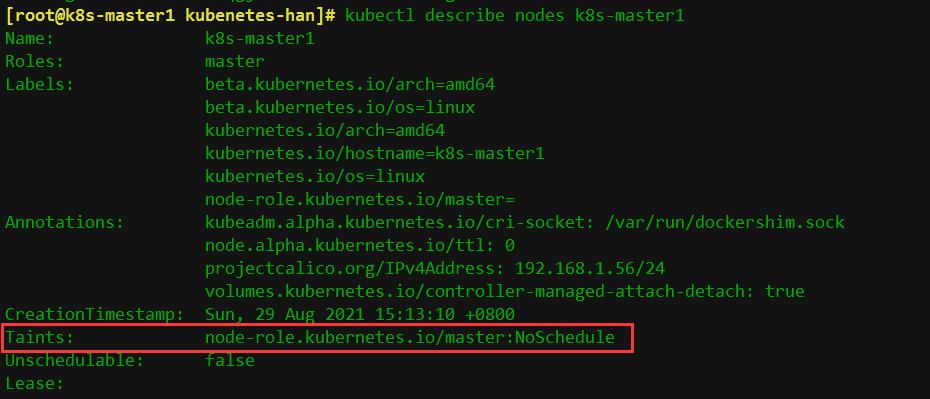
上面可以看到master這個節點的污點是Noschedule
所以我們創建的pod都不會調度到master上,因為我們創建的pod沒有容忍度
kubectl describe pods kube-apiserver-k8s-master1 -n kube-system
顯示如下

可以看到這個pod的容忍度是NoExecute,則可以調度到k8s-master1上
6.1 管理節點污點
[root@k8s-master1]# kubectl taint –help
例1:把k8s-node2當成是生產環境專用的,其他node是測試的,先打個污點
[root@k8s-master1 taint]# kubectl taint node k8s-node2 node-type=production:NoSchedule
node/k8s-node2 tainted
[root@k8s-master1 taint]# cat pod-taint.yaml
apiVersion: v1
kind: Pod
metadata:
name: taint-pod
namespace: default
labels:
tomcat: tomcat-pod
spec:
containers:
- name: taint-pod
ports:
- containerPort: 8080
image: tomcat:8.5-jre8-alpine
imagePullPolicy: IfNotPresent
查看一下pod唄調度到哪個節點了
[root@k8s-master1 taint]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint-pod 1/1 Running 0 20s 10.244.1.23 k8s-node1
可以看到都被調度到k8s-node1上了,因為k8s-node2這個節點打了污點,而我們在創建pod的時候沒有容忍度,所以k8s-node2上不會有pod調度上去的
例2:給k8s-node1也打上污點
[root@k8s-master1 taint]# kubectl taint node k8s-node1 node-type=dev:NoExecute
node/k8s-node1 tainted
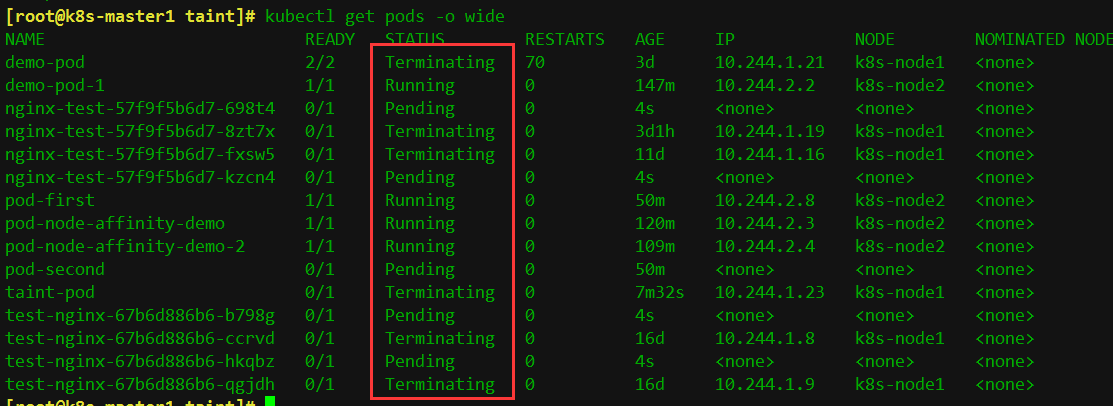
[root@k8s-master1 taint]# kubectl get pods -o wide
如下圖,可以看到node1已經存在的pod節點都被攆走了
[root@k8s-master1 taint]# cat pod-demo-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: myapp-deploy
namespace: default
labels:
app: myapp
release: canary
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80
tolerations:
- key: "node-type"
operator: "Equal"
value: "production"
effect: "NoExecute"
tolerationSeconds: 3600
myapp-deploy 1/1 Pending 0 11s k8s-node2
還是顯示pending,因為我們使用的是equal(等值匹配),所以key和value,effect必須和node節點定義的污點完全匹配才可以,把上面配置effect: “NoExecute”變成
effect: “NoSchedule”成;
tolerationSeconds: 3600這行去掉
先delete掉上面創建的pod後在修改,修改後重新應用。
上面就可以調度到k8s-node2上了,因為在pod中定義的容忍度能容忍node節點上的污點
例3:再次修改
修改如下部分:
tolerations:
- key: "node-type"
operator: "Exists"
value: ""
effect: "NoSchedule"
只要對應的鍵是存在的,exists,其值被自動定義成通配符
# kubectl delete -f pod-demo-1.yaml
# kubectl apply -f pod-demo-1.yaml
# kubectl get pods
發現還是調度到k8s-node2上
myapp-deploy 1/1 running 0 11s k8s-node2
最後刪除污點:
[root@k8s-master1 taint]#kubectl taint nodes k8s-node1 node-type:NoExecute-
node/k8s-node1 untainted
[root@k8s-master1 taint]# kubectl taint nodes k8s-node2 node-type:NoSchedule-
node/k8s-node2 untainted
7、Pod常見的狀態和重啟策略
7.1 常見的pod狀態
Pod的status定義在PodStatus對象中,其中有一個phase欄位。它簡單描述了Pod在其生命周期的階段。熟悉Pod的各種狀態對我們理解如何設置Pod的調度策略、重啟策略是很有必要的。下面是 phase 可能的值,也就是pod常見的狀態:
掛起(Pending):我們在請求創建pod時,條件不滿足,調度沒有完成,沒有任何一個節點能滿足調度條件,已經創建了pod但是沒有適合它運行的節點叫做掛起,調度沒有完成,處於pending的狀態會持續一段時間:包括調度Pod的時間和通過網路下載鏡像的時間。
運行中(Running):Pod已經綁定到了一個節點上,Pod 中所有的容器都已被創建。至少有一個容器正在運行,或者正處於啟動或重啟狀態。
成功(Succeeded):Pod 中的所有容器都被成功終止,並且不會再重啟。
失敗(Failed):Pod 中的所有容器都已終止了,並且至少有一個容器是因為失敗終止。也就是說,容器以非0狀態退出或者被系統終止。
未知(Unknown):未知狀態,所謂pod是什麼狀態是apiserver和運行在pod節點的kubelet進行通訊獲取狀態資訊的,如果節點之上的kubelet本身出故障,那麼apiserver就連不上kubelet,得不到資訊了,就會看Unknown
擴展:還有其他狀態,如下:
Evicted狀態:出現這種情況,多見於系統記憶體或硬碟資源不足,可df-h查看docker存儲所在目錄的資源使用情況,如果百分比大於85%,就要及時清理下資源,尤其是一些大文件、docker鏡像。
CrashLoopBackOff:容器曾經啟動了,但可能又異常退出了
Error 狀態:Pod 啟動過程中發生了錯誤
7.2 pod重啟策略
Pod的重啟策略(RestartPolicy)應用於Pod內的所有容器,並且僅在Pod所處的Node上由kubelet進行判斷和重啟操作。當某個容器異常退出或者健康檢查失敗時,kubelet將根據 RestartPolicy 的設置來進行相應的操作。
Pod的重啟策略包括 Always、OnFailure和Never,默認值為Always。
Always:當容器失敗時,由kubelet自動重啟該容器。
OnFailure:當容器終止運行且退出碼不為0時,由kubelet自動重啟該容器。
Never:不論容器運行狀態如何,kubelet都不會重啟該容器。
[root@k8s-master1 ~]# vim pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
namespace: default
labels:
app: myapp
spec:
restartPolicy: Always
containers:
- name: tomcat-pod-java
ports:- containerPort: 8080
image: tomcat:8.5-jre8-alpine
imagePullPolicy: IfNotPresent
- containerPort: 8080
8、Pod生命周期
概念圖
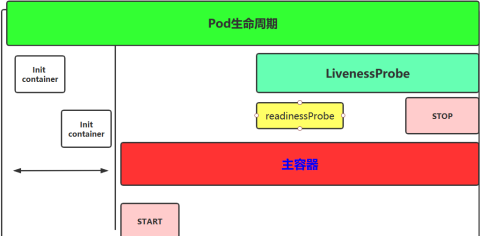
8.1 Init容器
Pod 裡面可以有一個或者多個容器,部署應用的容器可以稱為主容器,在創建Pod時候,Pod 中可以有一個或多個先於主容器啟動的Init容器,這個init容器就可以成為初始化容器,初始化容器一旦執行完,它從啟動開始到初始化程式碼執行完就退出了,它不會一直存在,所以在主容器啟動之前執行初始化,初始化容器可以有多個,多個初始化容器是要串列執行的,先執行初始化容器1,在執行初始化容器2等,等初始化容器執行完初始化就退出了,然後再執行主容器,主容器一退出,pod就結束了,主容器退出的時間點就是pod的結束點,它倆時間軸是一致的;
Init容器就是做初始化工作的容器。可以有一個或多個,如果多個按照定義的順序依次執行,只有所有的初始化容器執行完後,主容器才啟動。由於一個Pod里的存儲卷是共享的,所以Init Container里產生的數據可以被主容器使用到,Init Container可以在多種K8S資源里被使用到,如Deployment、DaemonSet, StatefulSet、Job等,但都是在Pod啟動時,在主容器啟動前執行,做初始化工作。
Init容器與普通的容器區別是:
1、Init 容器不支援 Readiness,因為它們必須在Pod就緒之前運行完成
2、每個Init容器必須運行成功,下一個才能夠運行
3、如果 Pod 的 Init 容器失敗,Kubernetes 會不斷地重啟該 Pod,直到 Init 容器成功為止,然而,如果Pod對應的restartPolicy值為 Never,它不會重新啟動。
初始化容器的官方地址:
//kubernetes.io/docs/concepts/workloads/pods/init-containers/#init-containers-in-use
訪問官方文檔
在本機也編輯一個yaml
[root@k8s-master1 init-pod]# cat init-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
- name: init-mydb
image: busybox:1.28
command: ['sh', '-c', "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done"]
更新yaml文件,此文件一直處於初始化階段
[root@k8s-master1 init-pod]# kubectl get pod
NAME READY STATUS RESTARTS AGE
myapp-pod 0/1 Init:0/2 0 3m17s
可以通過kubectl describe pod myapp-pod查看一下pod相關資訊
有兩個容器需要先進行初始化後才能繼續,
kubectl logs myapp-pod -c init-myservice # Inspect the first init container
kubectl logs myapp-pod -c init-mydb # Inspect the second init container
yaml文件中定義的需要解析db的服務,因為我們還沒有創建所以一直卡在這,按著官網文檔先進行創建一個
\---
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
\---
apiVersion: v1
kind: Service
metadata:
name: mydb
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9377
8.2 主容器
1、容器鉤子
初始化容器啟動之後,開始啟動主容器,在主容器啟動之前有一個post start hook(容器啟動後鉤子)和pre stop hook(容器結束前鉤子),無論啟動後還是結束前所做的事我們可以把它放兩個鉤子,這個鉤子就表示用戶可以用它來鉤住一些命令,來執行它,做開場前的預設,結束前的清理,如awk有begin,end,和這個效果類似;
postStart:該鉤子在容器被創建後立刻觸發,通知容器它已經被創建。如果該鉤子對應的hook handler執行失敗,則該容器會被殺死,並根據該容器的重啟策略決定是否要重啟該容器,這個鉤子不需要傳遞任何參數。
preStop:該鉤子在容器被刪除前觸發,其所對應的hook handler必須在刪除該容器的請求發送給Docker daemon之前完成。在該鉤子對應的hook handler完成後不論執行的結果如何,Docker daemon會發送一個SGTERN訊號量給Docker daemon來刪除該容器,這個鉤子不需要傳遞任何參數。
在k8s中支援兩類對pod的檢測,第一類叫做livenessprobe(pod存活性探測):
存活探針主要作用是,用指定的方式檢測pod中的容器應用是否正常運行,如果檢測失敗,則認為容器不健康,那麼Kubelet將根據Pod中設置的 restartPolicy來判斷Pod 是否要進行重啟操作,如果容器配置中沒有配置 livenessProbe,Kubelet 將認為存活探針探測一直為成功狀態。
第二類是狀態檢readinessprobe(pod就緒性探測):用於判斷容器中應用是否啟動完成,當探測成功後才使Pod對外提供網路訪問,設置容器Ready狀態為true,如果探測失敗,則設置容器的Ready狀態為false。
8.3 創建pod需要經過哪些階段?
當用戶創建pod時,這個請求給apiserver,apiserver把創建請求的狀態保存在etcd中;
接下來apiserver會請求scheduler來完成調度,如果調度成功,會把調度的結果(如調度到哪個節點上了,運行在哪個節點上了,把它更新到etcd的pod資源狀態中)保存在etcd中,一旦存到etcd中並且完成更新以後,如調度到k8s-master1上,那麼k8s-master1節點上的kubelet通過apiserver當中的狀態變化知道有一些任務被執行了,所以此時此kubelet會拿到用戶創建時所提交的清單,這個清單會在當前節點上運行或者啟動這個pod,如果創建成功或者失敗會有一個當前狀態,當前這個狀態會發給apiserver,apiserver在存到etcd中;在這個過程中,etcd和apiserver一直在打交道,不停的交互,scheduler也參與其中,負責調度pod到合適的node節點上,這個就是pod的創建過程
pod在整個生命周期中有非常多的用戶行為:
1、初始化容器完成初始化
2、主容器啟動後可以做啟動後鉤子
3、主容器結束前可以做結束前鉤子
4、在主容器運行中可以做一些健康檢測,如liveness probe,readness probe


