系統設計實踐(02)- 文本存儲服務
前言
系統設計實踐篇的文章將會根據《系統設計面試的萬金油》為前置模板,講解數十個常見系統的設計思路。
前置閱讀:
設計目標
讓我們設計一個類似於Pastebin的網站,用戶可以在其中存儲純文本。該服務的用戶將輸入一段文本,並獲得一個隨機生成的URL來訪問它。
一. 什麼是Pastebin?
Pastebin是一個文本存儲的網站,用戶可以在網站上儲存(粘貼)純文本 ,例如程式碼片段,生成一個網址,打開該網址就可以看到對應的文字。可以選擇文字的類型(程式碼所屬的程式語言)、文字保存的時間(1天、7天、30天、閱後即焚等等)、文字分享者的昵稱等資訊。因為第一個文本分享網站叫 //pastebin.com,所以文本存儲網站也常被稱為Pastebin。
二. 系統的需求與目標
Pastebin服務應滿足以下要求:
功能性需求
- 用戶應該能夠上傳或粘貼他們的文本數據,並獲得訪問它的唯一URL。
- 用戶只能上傳文本。
- 數據和鏈接地址將在特定時間間隔後自動過期; 用戶可以指定過期時間。
- 用戶可以為他們的文本內容選擇一個自定義的別名。
非功能性需求
- 系統應該是高度可靠的,任何上傳的數據都不應該丟失。
- 系統應該是高度可用的。這是必須的,因為如果我們的服務關閉,用戶將無法訪問他們的粘貼內容。
- 用戶應該能夠以最小的延遲實時訪問他們的粘貼。
- 粘貼鏈接地址不應該是可猜測的(不可預測的)。
擴展需求
- 分析,例如,粘貼地址被訪問多少次
- 我們的服務也應該可以通過REST API被其他服務訪問。
三. 系統相似性
Pastebin與上一篇《系統設計實踐(01) – 短鏈服務》有很多相似性的地方,所以我建議在開始閱讀前再去讀一讀短鏈服務那篇文章,此外還有一些額外的設計注意事項。
用戶一次可以粘貼的文本數量的限制是什麼?
我們可以限制用戶的粘貼不超過10MB,以防止濫用服務。
我們應該對自定義url施加大小限制嗎?
由於我們的服務支援自定義URL,用戶可以自定義他們喜歡URL,但提供自定義URL不是強制性的。然而,對自定義URL施加大小限制是合理的(通常也是可取的),這樣我們就有了一致的URL資料庫。
四. 容量估算與約束
與短鏈服務類似,我們的服務讀請求會更多,與創建新的粘貼相比,將有更多的讀取請求。我們可以假設讀和寫的比例是5:1。
流量估計
我們假設系統每天有100萬新粘貼生成, 這樣我們每天就有500萬次讀取。
每秒新粘貼
1M / (24 hours * 3600 seconds) ~= 12 pastes/sec
粘貼每秒讀取:
5M / (24 hours * 3600 seconds) ~= 58 reads/sec
存儲估計
用戶最多可以上傳10MB的數據; 通常,Pastebin之類的服務用於共享源程式碼、配置或日誌。這樣的文本並不大,所以我們假設每個粘貼平均包含10KB。
按照這個速度,我們每天將存儲10GB的數據。
1M * 10KB => 10 GB/day
如果我們想將這些數據存儲10年,我們需要36TB的總存儲容量。
每天有 100 萬個粘貼,我們將在 10 年內擁有 36 億個粘貼。 我們需要生成並存儲密鑰以唯一標識這些粘貼。 如果我們使用 base64 編碼([A-Z, a-z, 0-9, ., -]),我們將需要六個字母字元串:
64^6 ~= 68.7 billion unique strings
如果存儲一個字元需要一個位元組,那麼存儲3.6B鍵所需的總大小將是
3.6B * 6 => 22 GB
與36TB相比,22GB可以忽略不計。為了保持一定的餘量,我們將採用70%容量模型(即任何時候都不希望使用超過70%的總存儲容量),從而將存儲容量增加到51.4TB。
頻寬估計
對於寫請求,我們預計每秒12個新粘貼,每秒會有120KB的輸入。
12 * 10KB => 120 KB/s
至於讀取請求,我們預計每秒有 58 個請求。 因此,總數據出口(發送給用戶)將為 0.6 MB/s。
58 * 10KB => 0.6 MB/s
雖然總入口和出口不是很大,但我們在設計服務時應該記住這些數字
記憶體估計
我們可以快取一些經常訪問的熱粘貼。遵循80-20規則,即20%的熱點粘貼會產生80%的流量,我們希望快取這20%的粘貼,因為我們每天有5M的讀請求,要快取這些請求的20%,我們需要
0.2 * 5M * 10KB ~= 10 GB
五. 系統API設計
我們可以使用 SOAP 或 REST API 來公開我們服務的功能。 以下可能是用於創建/檢索/刪除粘貼的 API 的定義:
addPaste(api_dev_key, paste_data, custom_url=None, user_name=None, paste_name=None, expire_date=None)
參數
- api_dev_key (string): 註冊帳戶的API開發者密鑰.
- paste_data (string): 粘貼的文本內容.
- custom_url (string): 可選的用戶指定url.
- user_name (string): 可選的用戶嗎,用於生成URL.
- paste_name (string): 可選的粘貼名稱.
- expire_date (string): 可選的過期時間.
返回
成功將返回可以訪問粘貼的URL,否則將返回錯誤程式碼。
getPaste(api_dev_key, api_paste_key)
其中api粘貼鍵是一個字元串,表示要檢索的粘貼鍵。這個API將返回粘貼的文本數據。
deletePaste(api_dev_key, api_paste_key)
成功刪除返回true,否則返回false。
六. 資料庫設計
關於我們正在存儲的數據的性質的一些觀察
- 我們需要存儲數十億條記錄。
- 我們存儲的每個元數據對象都很小(小於100位元組)
- 我們存儲的每個粘貼對象可以是中等大小(可以是幾MB)。
- 記錄之間沒有關係,除非我們想要存儲哪個用戶創建了什麼粘貼。
- 我們的服務讀請求很多
資料庫選型
我們需要兩張表,一個用於存儲關於paste的資訊,另一個用於存儲用戶數據。
| Paste | User |
|---|---|
| [PK] URL Hash: varchar(16) | [PK] UserID: int |
| ContentKey: varchar(512) | Name: varchar(20) |
| CreationDate: datetime | Email: varchar(20) |
| ExpirationDate: datatime | CreationDate: datetime |
| LastLoginDate: datetime |
在這裡,URl Hash是TinyURL的URL等價物,ContentKey是存儲粘貼內容的對象鍵。
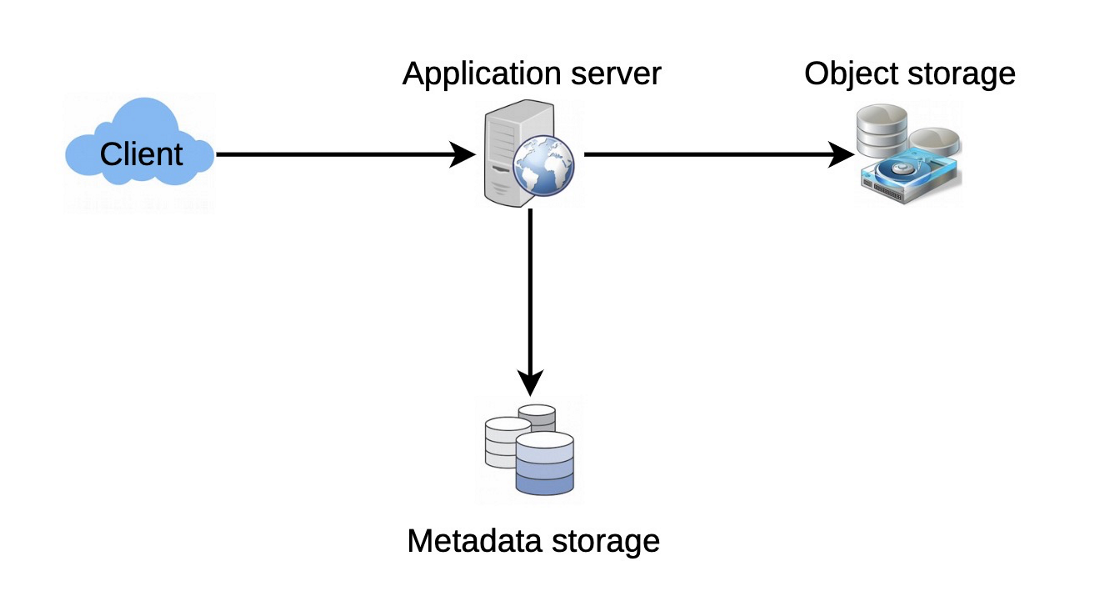
七. 高級設計
在更高的層次上,我們需要一個應用程式層來服務於所有的讀寫請求。應用層將與存儲層通訊以存儲和檢索數據。我們可以隔離存儲層,一個資料庫存儲與每個粘貼、用戶等相關的元數據,而另一個資料庫將粘貼內容存儲在某些對象存儲中(如Amazon S3)。這種數據劃分也將允許我們對它們進行單獨的縮放。
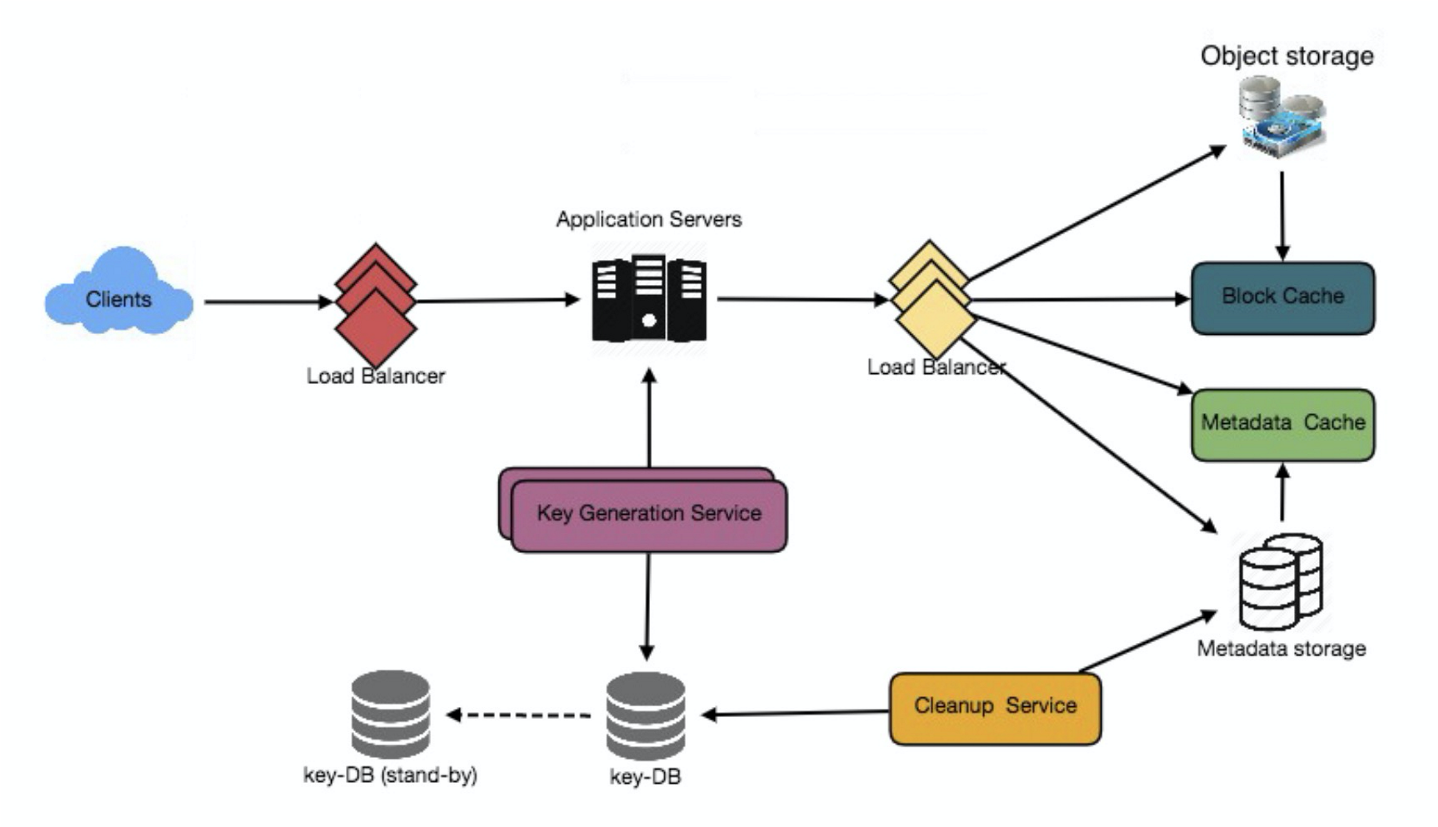
八. 組件設計
應用層
我們的應用層將處理所有傳入和傳出的請求。應用伺服器將與後端數據存儲組件通訊來處理請求。
如何處理寫請求?
在接收到寫請求時,我們的應用伺服器將生成一個6個字母的隨機字元串,它將作為粘貼的密鑰(如果用戶沒有提供自定義密鑰)。然後,應用程式伺服器將在資料庫中存儲粘貼的內容和生成的鍵。成功插入後,伺服器可以將密鑰返回給用戶。這裡的一個可能問題是,由於密鑰重複,插入失敗。因為我們生成了一個隨機密鑰,所以新生成的密鑰有可能與現有密鑰匹配。在這種情況下,我們應該重新生成一個新的密鑰並再試一次,直到沒有發現因為重複密鑰。如果用戶提供的自定義鍵已經存在於資料庫中,則應該向用戶返回一個錯誤。
上述問題的另一個解決方案是運行一個獨立的密鑰生成服務(KGS),它事先生成隨機的6個字母字元串,並將它們存儲在一個資料庫中(我們稱之為Key-db)。每當我們想要存儲一個新的粘貼時,我們只需要一個已經生成的鍵並使用它。這種方法將使事情變得非常簡單和快速,因為我們不需要擔心重複或碰撞。KGS將確保插入到key-DB中的所有鍵是唯一的。KGS可以使用兩個表來存儲鍵,一個用於尚未使用的鍵,另一個用於所有已使用的鍵。一旦KGS嚮應用伺服器提供了一些鍵,它就可以將這些鍵移動到所使用的鍵表中。KGS可以在記憶體中保存一些密鑰,以便每當伺服器需要它們時,它可以快速提供它們。一旦KGS在記憶體中載入了一些鍵,它就可以將它們移動到已使用的鍵表中,這樣我們就可以確保每個伺服器獲得唯一的鍵。如果KGS在使用記憶體中載入的所有鍵之前宕機,這些鍵會被浪費,不過可以忽略,因為KGS中6個字母可生成的字元串足夠多。
KGS不是單點故障嗎?
是的。為了解決這個問題,我們可以有一個KGS的備用副本,每當主伺服器死亡時,它可以接管生成並提供密鑰。
每個應用伺服器是否可以從key-DB中快取一些key?
是的,這肯定能加快響應速度。儘管在這種情況下,如果應用伺服器在使用所有密鑰之前就掛掉了,我們最終會丟失這些密鑰。這是可以接受的,因為我們有68B唯一的6個字母的鑰匙,這比我們需要的多得多。
它如何處理粘貼讀請求?
在接收到讀粘貼請求後,應用程式服務層請求數據存儲。數據存儲搜索密鑰,如果找到,返回粘貼的內容。否則,返回錯誤程式碼。
數據層
我們可以講數據存儲劃為兩層。
- 元數據資料庫:我們可以使用關係資料庫如MySQL或分散式鍵值存儲如Dynamo或Cassandra。
- 對象存儲:可以像Amazon S3一樣將內容存儲在對象存儲中。當我們想要在內容存儲上達到最大容量時,我們可以通過添加更多伺服器來輕鬆增加容量。