機器學習演算法複習手冊——SVM
- 2019 年 12 月 27 日
- 筆記
本手冊整理自機器學習各相關書籍、網路資料、個人的理解與實踐。總體編寫宗旨: ①一看就懂; ②用20%的文字,涵蓋80%的內容。 至於剩下的20%,一般屬於比較偏、難的部分,建議自行查詢相關書籍資料學習。而只用20%的文字,則代表手冊裡面幾乎沒有廢話,也只有極少數必要的例子。
手冊往期文章: 機器學習演算法複習手冊——決策樹 機器學習演算法Code Show——決策樹
下面進入正題,今天的主題是支援向量機(SVM)。
支援向量機
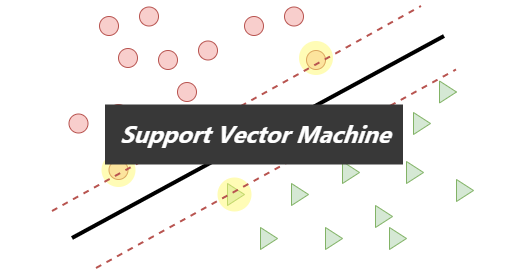
支援向量機(SVM)是一種強大的二分類器,一般我們提起機器學習,最自然想到的演算法就是SVM。它跟感知機十分類似,都是線性分類器。在學習感知機演算法的時候,我們知道,最後學得的分類器不是唯一的,因為能夠把正負樣本點分開的超平面很可能不止一條。在SVM中,我們會改進這一點,方法就是使用最大間隔的原則來尋找最優的分割超平面。
應對數據線性可分、近似線性可分、線性不可分三種不同的情形,SVM分別有硬間隔SVM、軟間隔SVM和非線性SVM。
下面的內容,我們主要複習SVM基本型(線性可分SVM)的基礎知識和訓練方法,對於軟間隔SVM以及非線性可分的,我們的介紹就會簡略一些。
1. 用「間隔最大化」定義優化問題
究竟何為間隔最大化?之前在感知機中,不就是使用誤分類樣本的和超平面的距離之和的最大化作為損失函數嗎?首先想想為何感知機的超平面可能有多個,因為當我沒有誤分類點的時候,感知機的損失就為0了,我就不更新了。現在SVM想做的事兒,就是即使我沒有誤分類點了,我還想優中選優。
那怎麼選呢?我找出所有訓練樣本點中,離超平面最近的那一個點,讓這個最小距離也儘可能地大。這樣,我最終得到的超平面,即使對於最難區分的點(離超平面最近的點),我可能很有把握地分開,那說明這個平面選擇的確實很好。
「把最小距離最大化」,就是我們所說的「間隔最大化」,寫成方程就是這樣的:
下面的約束條件的意思就是說γ是所有點中的最小的距離。其實這個距離還有一個單獨的名字——「幾何間隔」,具體我也不贅述了,可以參見李航老師的教材。上面這個方程,可以經過一系列的簡單轉化,具體我用下圖來展示:

總之就轉化成了這個方程:
這是一個凸二次規劃問題,只要是凸優化,就代表很好(用現成的軟體)求解。
2. 關於支援向量
前面講了線性可分情況下SVM是如何優化的,即通過「間隔最大化」,而間隔最大化,是挑離超平面最近的那些點來優化,這些點,也有自己特殊的名字——支援向量。從優化的過程來看,支援向量對超平面的選擇起決定性作用,這也是支援向量機名字的由來。
3. 轉化為對偶問題
其實對於優化問題,只要我們能轉化成一個凸優化問題,最難的部分就過去了,後面求解上雖然理論上也十分複雜,但是計算方法已經十分成熟,所以對於大多數人來說不是需要考慮的問題。
然而,在SVM中,一般的書上都會做進一步的討論,把上面這個問題(這裡稱為原問題)繼續轉化成對偶問題求解,這樣做的好處主要有兩個:
- 轉化之後更容易求解
- 方便後面非線性SVM中核函數的引入
轉化的思路就是通過」拉格朗日之神馬操作「,我整理成了下面這張圖:
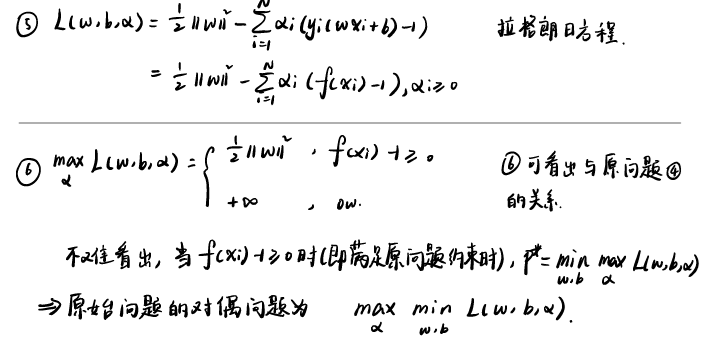

雖然圖上寫了,我再把轉化後的對偶問題寫一下:
為什麼這裡轉化後的對偶問題會更容易求解呢(其實我覺得不一定)?首先原問題的變數個數由特徵維度決定,而對偶問題只跟樣本個數有關(所以當維度遠遠大於樣本個數的時候,對偶問題明顯會簡單些,反之則不一定了);另外一點,這裡的α,只有當樣本點是支援向量時,才非零,其餘都為零。當然,這裡轉化成對偶問題,最重要的還是為了方便後面核函數的引入。
對於這裡的對偶問題怎麼求解呢?由於剛剛也提到過,這個方程的求解複雜度正比於樣本的數量,因此計算的開銷還是很大。所以這裡人們開發除了著名的SMO演算法,即序列最小優化演算法。這裡SMO演算法涉及到的內容又很多,所以這裡只簡述一下SMO演算法的基本思想:
要想對偶問題得到最優解,就要求所有的訓練樣本點都滿足KKT條件。SMO演算法,將問題轉化成一個個的二元優化問題。每次都選擇最違反KKT條件的變數,以及隨機確定的另一個變數,來構建兩個變數的二次優化問題,每一次的求解都會使得原來的問題更加接近最優解。由於各個子問題可以直接解析求解,因此速度會快很多。
求解了這個對偶問題之後,就得到了最優的α的值,則可以接著求出w和b的值:
其中這個b是根據KKT條件中得到的,α存在一個分量大於0,從而可找到一個b的等式關係進而求出b。
得到了w和b,就可以寫出最終分類模型的方程了:
4. 核函數
核函數,因其莫名其妙的名字,也是一直是一個讓很多人頭疼的玩意兒。時至今日,見到核函數相關的公式,我也忍不住打出一個草字頭來。這裡爭取跳過具體的公式,談一談核函數到底是啥,為啥。
前面的討論,都是假設訓練樣本是線性可分的。然而,事情往往,沒~那麼簡單(能聽到語音嗎),即很多時候都存在線性不可分的情況,例如「異或」這個難題。
我們的數據看起來線性不可分,那就說明我們手頭的那些特徵不足以區分出不同類別的樣本。那這個時候我們想要區分它們,能怎麼辦呢?
一種方法就是我們尋找更多有區分性的特徵,比如,我們從」性別「、」年齡「這兩個特徵上很難區分一個人的收入水平,於是我們接著找到了」學歷「,」工作經驗「這兩個特徵,加上去,一看,誒!這下我們就很好區分了,用這個四個特徵就可以很好地擬合一個分類模型了。但是,我們一般都默認,特徵都已經被我們努力發掘過了,很難再找到更多額外的有區分度的特徵了,那怎麼辦呢?
這個時候,我們就可以嘗試,把已有的特徵進行組合,內部形成更多的特徵。比方我們本來有x=(x1,x2,x3)三個特徵,我們可以試著將這三個特徵兩兩相乘,就得到x1x1,x1x2,x1x3,x2x1,x2x2,x2x3,x3x1,x3x2,x3x3這,九個特徵(可能有重複特徵,先不管這個),特徵增加了,我們就更有可能增加樣本的區分度,而且特徵維度增加的越多,我們就越有機會讓樣本線性可分。
所以,線性不可分的樣本,往往在映射到高維空間中的時候就可分了。具體多少維,我也不知道,但是有一個定理:
只要原始維度是有限的,那麼一定存在這個更高維的空間使樣本可分。
假設我們找到了的高維映射為,則新的超平面則為:
則我們在求解對偶問題的時候,把原來的x的內積替換成映射的內積即可,十分方便:
本來我們就這樣接著求解出α,w和b就完事兒了,跟之前的求解沒什麼區別,但是這裡又有了新的困難,那就是高維映射求內積十分費勁。例如,本來我們一個樣本x的特徵是三維的(x1,x2,x3),現在兩兩相乘得到了九維,那原本是3維向量求內積,現在則是九維向量求內積,複雜度陡增。
這個時候我們才正式引入「核技巧」和「核函數」的概念:
能不能找到高維映射內積與原空間中特徵的關係,從而在原特徵空間中就能求出高維映射的內積?
其實是完全可以的,為了簡便,我使用二維原特徵空間來舉例子:
可以看到,實際上,這裡的就是所謂的**「核函數」**前者的計算複雜度是4,後者是2,二者是平方關係。如果映射方式不變,原特徵空間維度為K的話,那麼使用高維映射直接計算,複雜度是,而使用核函數,複雜度只有。這就是核的威力!
所以,關鍵是我們要找到高維空間內積與原空間的關係,即核函數。核函數一旦確定,我們就可以不用關心高維映射具體是怎麼實現的,只用使用核函數計算出結果就行了。
但是核函數通常不是件容易事兒,首先如何找到一個好的高維映射就不容易,另外,如果我們先定義核函數,想據此找到映射方式也不容易。幸好,前人的研究給我們留下了很多的經驗,我們有一些常見的效果很不錯的核函數可以選擇。最常用的就是兩個核函數:多項式核,高斯核。
多項式核
多項式核公式為:。
將其展開之後,可以知道對應的高維映射空間的維度為,內積的計算複雜度為,而使用核函數的計算複雜度為。
高斯核
高斯核,又稱為徑向基函數核(RBF核),公式為:。
由於其泰勒展開是無限維,因此其高維映射空間的維度也是無限維,無限維空間我們無法描述,更無法計算內積,但是通過這個核函數,我們卻可以直接求出在無限維空間中的內積!這就是高斯核的厲害之處,因此,在情況不明確的時候,我們往往都先使用高斯核來試試水,一般情況下問題都可以很好解決。
5. 軟間隔與合頁損失函數
前面講的線性可分SVM,以及線性不可分但是通過核函數升維變為可分,本質上都是想讓訓練樣本嚴格的線性可分,也就是硬間隔。但是,即使線性可分了,那些離分割超平面很近的點,其置信度是很低的,如果因為這些點,而努力讓平面嚴格地將數據分開,可能會造成過擬合;另外,數據中也經常會出現一些噪音點、異常點,如果使用硬間隔的話,會嚴重擾亂模型的訓練。因此,為了模型的泛化能力,我們可以採用「軟間隔」。
軟間隔的意思就是,放鬆對每個樣本點函數間隔的要求,所以引入一個鬆弛變數,把之前的不等於約束變成:
但是要求降低了是需要付出代價的,所以損失函數也要修改成:
其中C>0稱為懲罰係數,這樣損失函數的意義就是「讓間隔最大化,同時誤分類點也儘可能少」。於是優化問題就變成了:
求解方法依然是轉化成對偶問題求解,此處實在不想贅述了。
在軟間隔SVM中,我們還可以使用一個新的損失函數——合頁損失函數(hinge loss),來從另一個角度描述這個問題。
上面的軟間隔下的優化問題,等價於下面這個優化問題:
對,無其他約束。
其中,就是所謂的hinge loss。

hinge loss的影像如圖所示,可以看出,對於誤分類點,即y(wx+b)<0,自然是有損失的;但是對於正確分類的點,當置信度不是很高時(0~1的範圍內),也會有損失,只有置信度很高時才為0。因此我們可以看出,使用hinge loss,我們對模型的學習有更高的要求,這樣會使得模型學習得更複雜,所以損失函數中的又可看做是一個「正則化項」,來控制模型的複雜度。
以上就是關於SVM的主要內容了,SVM這個東西還是比較複雜的,因為涉及到的數學的東西比較多。但是,裡面的很多問題具有通用性,像對偶問題的轉化和求解、核技巧,都是在其他問題中也是經常使用的,因此SVM還是有必要仔細學一學的。
本文參考資料: 1. 李航,《統計學習方法》 2. 周志華,《機器學習》 3. 鏈球選手,《我所理解的 SVM 2——核函數的應用》,https://zhuanlan.zhihu.com/p/24291579 4. 崔家華,《機器學習實戰教程(八):支援向量機原理篇之手撕線性SVM》,https://cuijiahua.com/blog/2017/11/ml_8_svm_1.html 5. 90Zeng,《簡易解說拉格朗日對偶(Lagrange duality)》,https://www.cnblogs.com/90zeng/p/Lagrange_duality.html
