利用元數據提高 SQLFlow 血緣分析結果準確率
- 2021 年 9 月 1 日
- 筆記
- sqlflow, SQLFlow 血緣關係 job 數據流 數據分析
一、SQLFlow–數據治理專家的一把利器
數據血緣屬於數據治理中的一個概念,是在數據溯源的過程中找到相關數據之間的聯繫,它是一個邏輯概念。數據治理里經常提到的一個詞就是血緣分析,血緣分析是保證數據融合的一個手段,通過血緣分析實現數據融合處理的可追溯。大數據治理分析師常常需要對各種複雜場景下的SQL語句進行溯源分析,而限於環境因素,往往只能提供SQL語句給SQLFlow進行分析處理,SQL語句的製造者往往為了簡便行事,會產生一些資料庫可執行但SQLFlow無法正確識別的一類語句,本文聚焦此處,為各位專家介紹SQLFlow官方對這類問題的解決方案。
SQLFlow官方入口: //sqlflow.gudusoft.com
二、SQLFlow的Orphan Column Error
隨著SQLFlow的使用,你會發現在分析部分SQL 數據血緣時,會遇到SQLFlow的orphan column錯誤提示,如下圖所示:

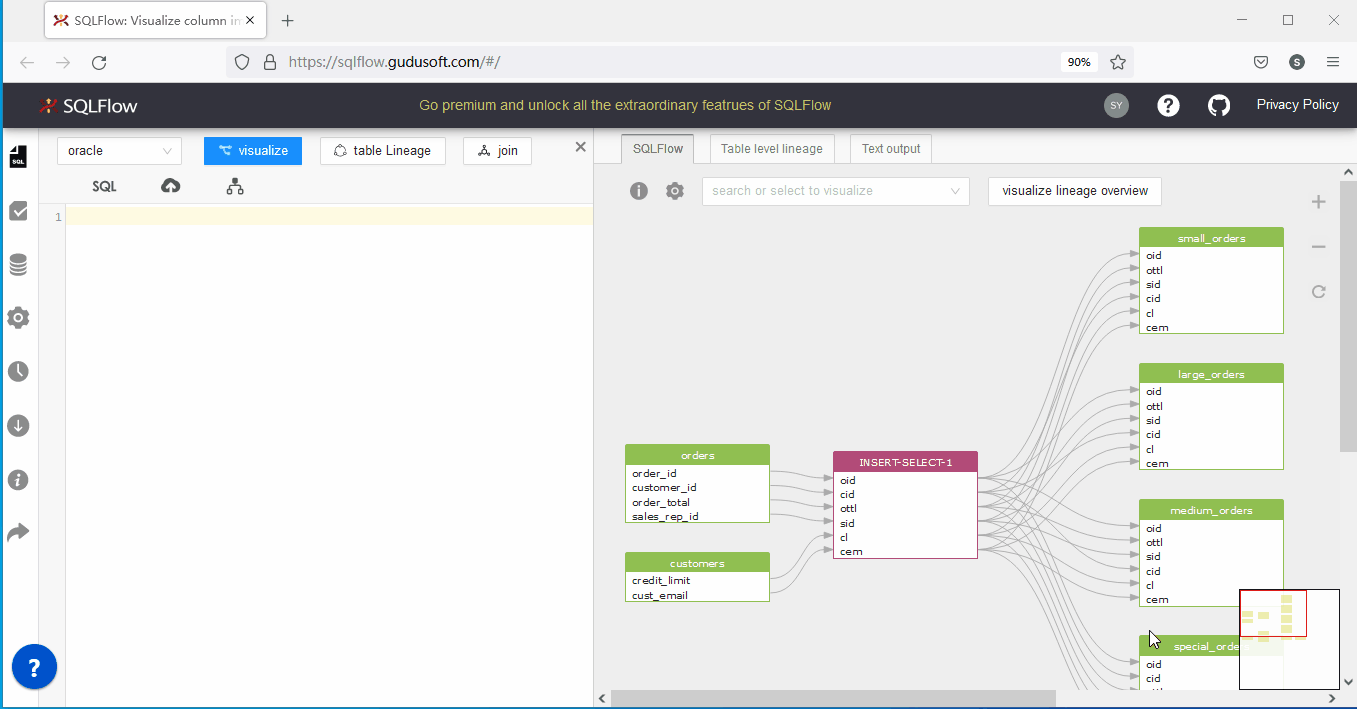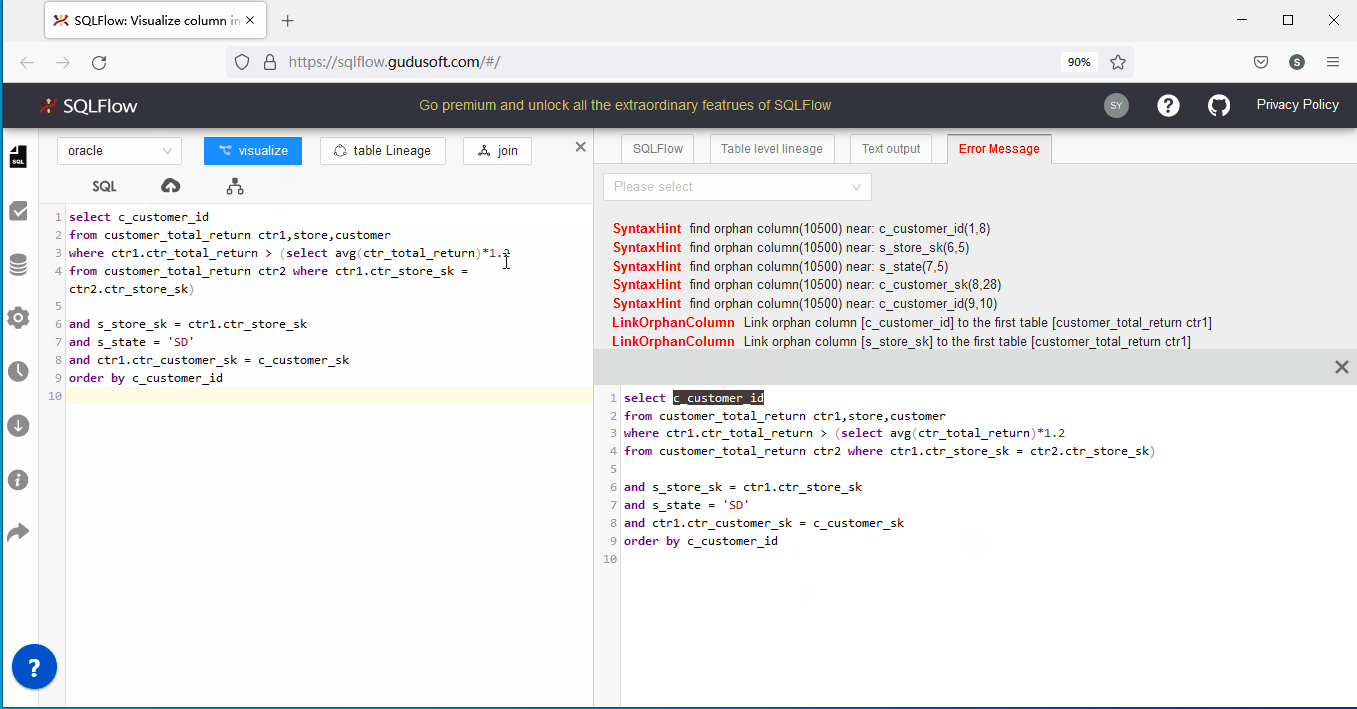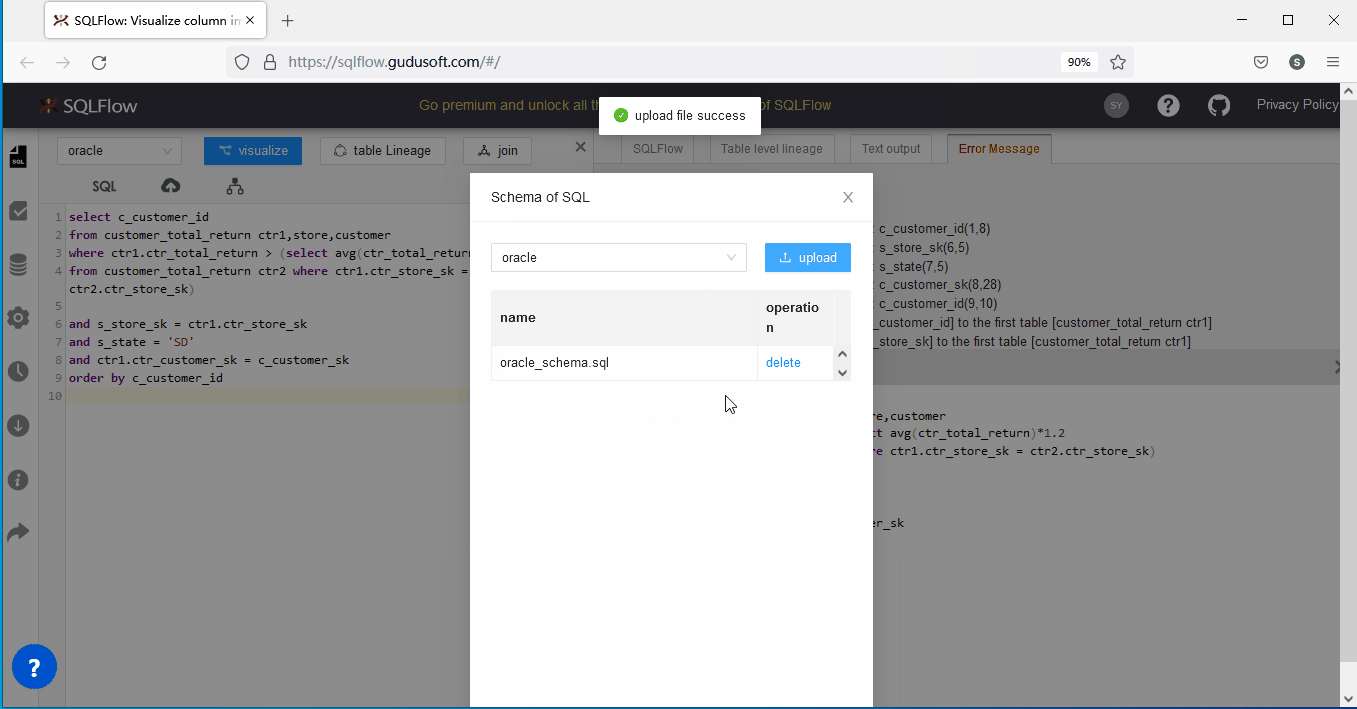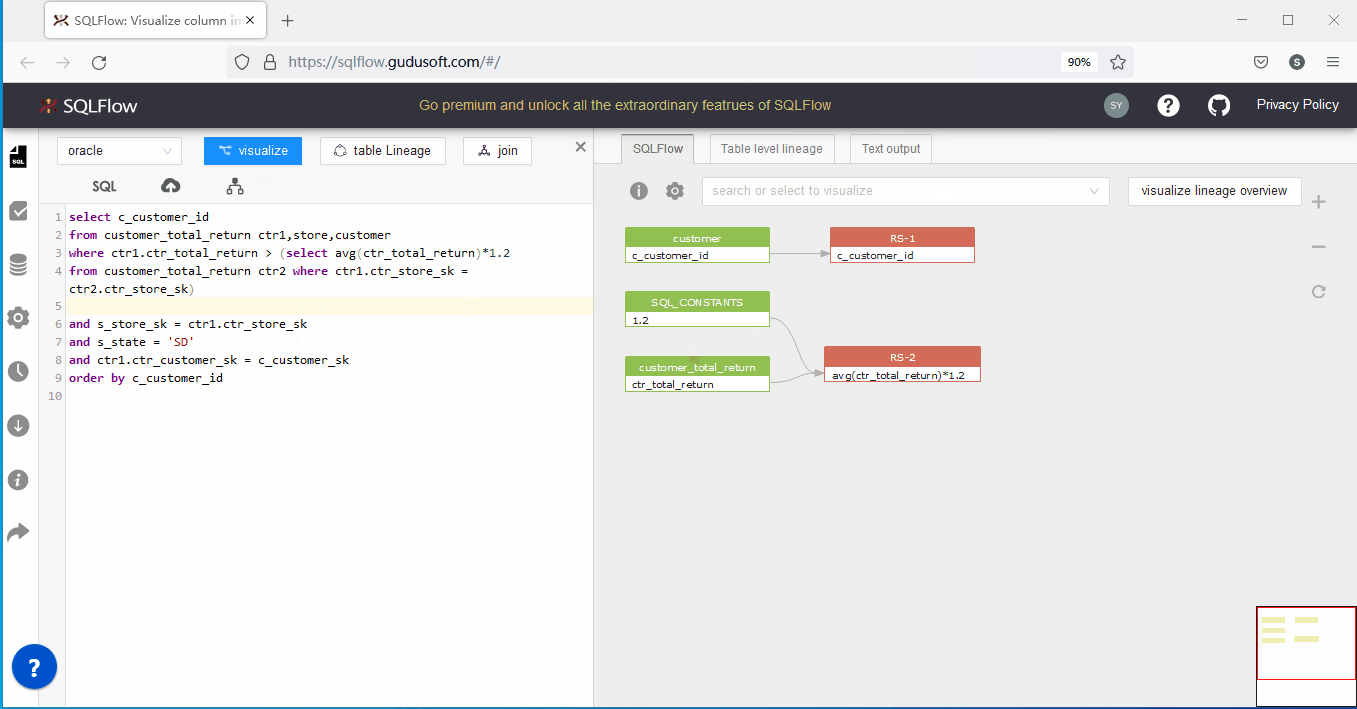
如果您是SQLFlow的新用戶,您可能會有我的SQL語句明明是正確可執行的為啥會報這個錯誤,這主要是因為SQLFlow目前的模式是未連接數據源狀態,即僅從SQL語句進行血緣分析。orphan column error是提示正在分析的SQL語句存在『孤兒列』,什麼是孤兒列?孤兒列就是在多表join的情形下某個返回列或條件列沒有指定具體所屬表對象,即SQLFlow沒有依據判斷該列到底是來源於哪裡。
示例:
select c_customer_id
from customer_total_return ctr1,store,customer
where ctr1.ctr_total_return > (select avg(ctr_total_return)*1.2
from customer_total_return ctr2 where ctr1.ctr_store_sk = ctr2.ctr_store_sk)
and s_store_sk = ctr1.ctr_store_sk
and s_state = 'SD'
and ctr1.ctr_customer_sk = c_customer_sk
order by c_customer_id
上述語句是一個3表(customer_total_return ,store,customer)關聯的簡單語句,它的運算結果是返回複合條件的c_customer_id列集合。不難看出,關聯條件(and s_store_sk = ctr1.ctr_store_sk and s_state = ‘SD’ and ctr1.ctr_customer_sk = c_customer_sk)中s_store_sk 、s_state 、c_customer_sk等三個列並沒有指定來源。該語句之所以在Oracle查詢分析器中沒有錯誤,是因為查詢分析器可以拿到三個表定義進行遍歷對比,如果上述未指定來源表的列恰好都只屬於某個表,此時查詢分析器便能正常解析並執行該語句。
相反,SQLFlow只有SQL語句,而沒法獲取表定義,所以就會出現orphan column error。那我們應該如何解決』孤兒列』的問題呢?目前有以下兩個可行方案:
1、完善SQL語句,由簡變繁
select ctr1.c_customer_id
from customer_total_return ctr1,store s,customer c
where ctr1.ctr_total_return > (select avg(ctr_total_return)*1.2
from customer_total_return ctr2 where ctr1.ctr_store_sk = ctr2.ctr_store_sk)
and s.s_store_sk = ctr1.ctr_store_sk
and s.s_state = 'SD'
and ctr1.ctr_customer_sk = c.c_customer_sk
order by c.c_customer_id
上述程式碼將返回列、條件列中所有未指定來源表的列進行了完善,執行SQLFlow分析後,能夠成功分析:

上圖能夠成功分析並且右側顯示窗口中已經沒有錯誤資訊。
2、為SQLFlow上傳schema 文件
SQLFlow廠商為解決上述問題,為用戶提供了一個可以手工上傳schema DDL文件的方法來解決上述問題。
還以上述SQL語句為例,我們可以將對應的缺失列的Table DDL以文件方式上傳提供給SQLFlow後,具體的table DDL定義如下:
create table customer
(
c_customer_sk integer not null,
c_customer_id char(16) not null,
c_current_cdemo_sk integer ,
c_current_hdemo_sk integer ,
c_current_addr_sk integer ,
c_first_shipto_date_sk integer ,
c_first_sales_date_sk integer ,
c_salutation char(10) ,
c_first_name char(20) ,
c_last_name char(30) ,
c_preferred_cust_flag char(1) ,
c_birth_day integer ,
c_birth_month integer ,
c_birth_year integer ,
c_birth_country varchar(20) ,
c_login char(13) ,
c_email_address char(50) ,
c_last_review_date char(10) ,
primary key (c_customer_sk)
);
create table store
(
s_store_sk integer not null,
s_store_id char(16) not null,
s_rec_start_date date ,
s_rec_end_date date ,
s_closed_date_sk integer ,
s_store_name varchar(50) ,
s_number_employees integer ,
s_floor_space integer ,
s_hours char(20) ,
s_manager varchar(40) ,
s_market_id integer ,
s_geography_class varchar(100) ,
s_market_desc varchar(100) ,
s_market_manager varchar(40) ,
s_division_id integer ,
s_division_name varchar(50) ,
s_company_id integer ,
s_company_name varchar(50) ,
s_street_number varchar(10) ,
s_street_name varchar(60) ,
s_street_type char(15) ,
s_suite_number char(10) ,
s_city varchar(60) ,
s_county varchar(30) ,
s_state char(2) ,
s_zip char(10) ,
s_country varchar(20) ,
s_gmt_offset decimal(5,2) ,
s_tax_precentage decimal(5,2) ,
primary key (s_store_sk)
);
由於第一張表customer_total_return所使用/返回的列均在SQL語句中顯示指定,所以這裡不需要額外提供它的定義資訊,只需要提供其他兩張表的定義,如果您的語句中存在所有表均有上述情況,則需要將所有表的定義提供給SQLFlow供分析。
實際操作如下:
關於SQLFlow官方提供的上傳schema解決方案的幾點補充:
-
一個用戶可以上傳一個或多個schema文件,也支援打包zip格式上傳,SQLFlow會自動遍歷所有文件進行分析;
-
用戶可以對已上傳的文件進行刪除;
三、參考網站
SQLFlow官方入口:
SQLFlow 架構文檔:
//github.com/sqlparser/sqlflow_public/blob/master/sqlflow_architecture.md