Spark Ignite踩坑記錄
Ignite spark 踩坑記錄
簡述
ignite訪問數據有兩種模式:
- Thin Jdbc模式;
- Jdbc 模式和Ignite client模式;
- shell客戶端輸出問題,不能輸出全列;
針對上述三個問題,我們一一說明一下
詳述
Thin Jdbc
瘦客戶端的模式是官網介紹的模式,這種模式類似關係型資料庫jdbc的訪問模式,有兩個參數
- ignite.jdbc.distributedJoins 啟用分散式join的開關
- ignite.jdbc.enforceJoinOrder 在查詢中強製表join順序的開關
這兩個開關默認都是false,如需開啟在URL中添加參數直接指定即可,這部分基本沒什麼好說的
注意:schema大小寫不敏感
Jdbc client
這種方式區別於瘦客戶端,我們姑且叫他胖客戶端吧,最開始ignite有直接JDBC的模式,但這種方式現在已經廢棄了,現在IgniteJdbcDriver這個類提供的其實就ignite client的這種訪問模式,裡面可以指定多個參數,包含cache、local等,大家看下這個類的源碼,在類的注釋部分有說明。
這種方式會在ignite集群的topo結構中看出連接集群的client節點。
但我要說的是,這個中方式最後會拼接出一個h2的鏈接,坑的是這個h2的鏈接中會包含一個h2都解析不了的參數,導致鏈接報錯,報錯的第一個參數是MULTIPLE_THREAD,還把這個URL申明成final的,導致調試的時候都不能手動指定value,坑啊,後面參數不知道還有沒有未知參數,得改改ignite的源碼了;
連接超時
這個問題更坑,客戶端模式去連接集群時,會有個達到超時的時間,但這個設置是寫死在程式里的,不可配置的,在win下連接集群的話,我們的環境通常2s是連不上的,下面是類和我在我本地做的鏈接測試:
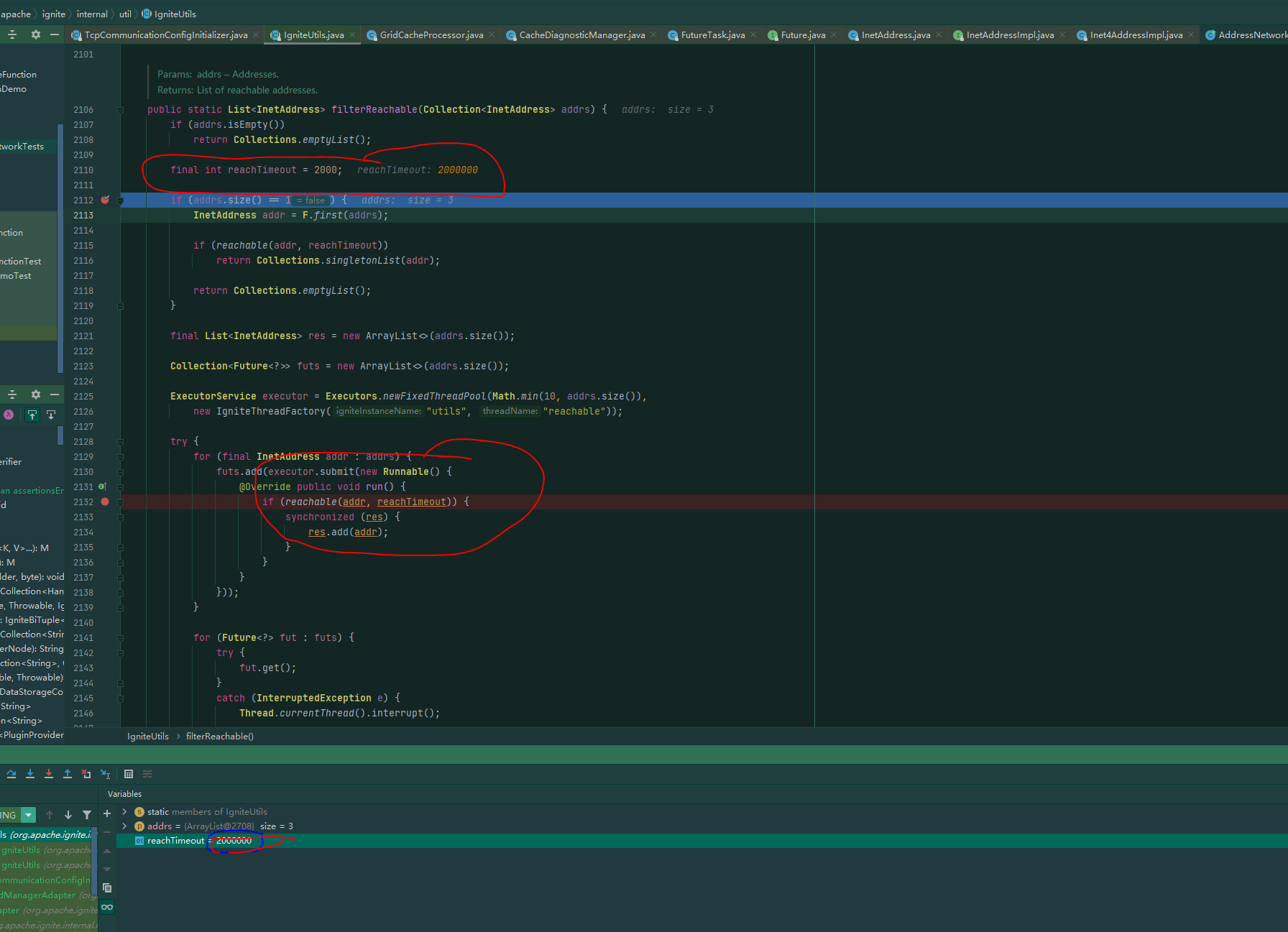
所用的時間:
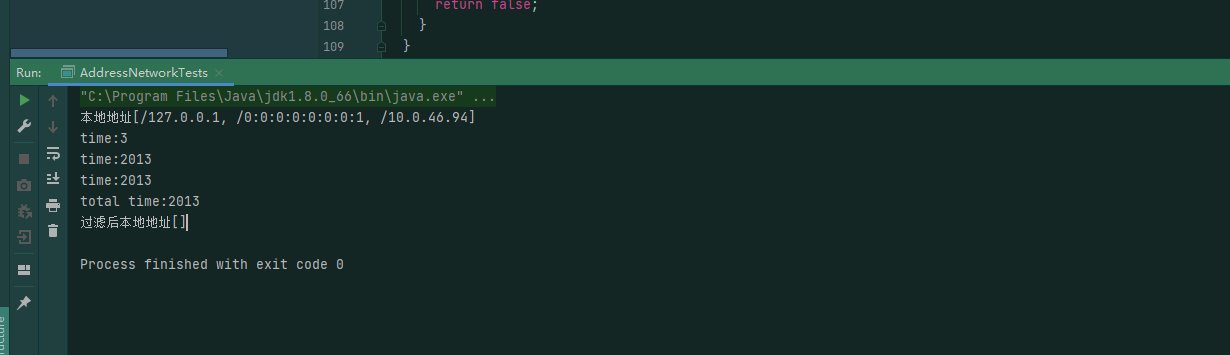
這個用起來讓人感覺十分難受,要不就修改源碼,把這個時間改大點,要不就每次程式走到這,斷點,然後去給這個變數在執行緒中去set value,難受。
ignite shell 客戶端
在使用ignite shell客戶端時,如果列數比較多的話,直接給把後面的列顯示給切斷了,如果剛好切成了整列,你還以為導數的時候後面的列沒導進去,產生錯覺,難受;
與spark集成
這段時間一直在做ignite 與spark的集成測試,找了好幾個數據集,也按照官網的方式試了幾種方式,但沒有出現性能提升,這個原因可能是我spark集群和ignite集群沒有完全安裝在相同的伺服器導致的,也可能是ignite的原因,這個還需要再進行定位。
最後
Ignite這個組件雖然是Java寫的,但是官網的介紹很簡略,只是說明的了下,怎麼操作,怎麼配置,對其存儲的原理,裡面的設計細節以及實現並沒有詳細的說明,而且網上的資料很少,遇到問題只能是追程式碼、看源碼,不想Hadoop、spark這種組件我對起裡面的存儲、計算的實現也是清晰的,用起來感覺有點彆扭;而且和spark這種明星組件集成,可以官方給出個性能的測試的,現在大數據環境都有基準的測試包,從2018年提供了這種集成能力之後,再也沒有關於這部分的更新,spark版本只支援2.3、2.4,在ignite3.0(開發)中會對spark3.0有支援,希望到時候能有個官方的測試說明吧,完畢。


