流量錄製與回放技術實踐
文章導讀
本文主要介紹了流量錄製與回放技術在壓測場景下的應用。通過閱讀本篇文章,你將了解到開源的錄製工具如何與內部系統集成、如何進行二次開發以支援 Dubbo 流量錄製、怎樣通過 Java 類載入機制解決 jar 包版本衝突問題、以及流量錄製在自動化測試場景下的應用與價值等。文章共約 1.4 萬字,配圖17張。本篇文章是對我個人過去一年所負責的工作的總結,裡面涉及到了很多技術點,個人從中學到了很多東西,也希望這篇文章能讓大家有所收穫。當然個人能力有限,文中不妥之處也歡迎大家指教。具體章節安排如下:

1. 前言
本篇文章記錄和總結了自己過去一年所主導的項目——流量錄製與回放,該項目主要用於為業務團隊提供壓測服務。作為項目負責人,我承擔了約 70% 的工作,所以這個項目承載了自己很多的記憶。從需求提出、技術調研、選型驗證、問題處置、方案設計、兩周內上線最小可用系統、推廣使用、支援年中/終全鏈路壓測、迭代優化、支援 dubbo 流量錄製、到新場景落地產生價值。這裡列舉每一項自己都深度參與了,因此也從中學習到了很多東西。包含但不限於 go 語言、網路知識、Dubbo 協議細節,以及 Java 類載入機制等。除此之外,項目所產生的價值也讓自己很欣喜。項目上線一年,幫助業務線發現了十幾個性能問題,幫助中間件團隊發現了基礎組件多個嚴重的問題。總的來說,這個項目對於我個人來說具有非凡意義,受益良多。這裡把過去一年的項目經歷記錄下來,做個總結。本篇文章著重講實現思路,不會貼太多程式碼,有興趣的朋友可以根據思路自己訂製一套。好了,下面開始正文吧。
2. 項目背景
項目的出現源自業務團隊的一個訴求——使用線上真實的流量進行壓測,使壓測更為「真實」一些。之所以業務團隊覺得使用老的壓測平台(基於 Jmeter 實現)不真實,是因為壓測數據的多樣性不足,對程式碼的覆蓋度不夠。常規壓測任務通常都是對應用的 TOP 30 介面進行壓測,如果人工去完善這些介面的壓測數據,成本是會非常高的。基於這個需求,我們調研了一些工具,並最終選擇了 Go 語言編寫的 GoReplay 作為流量錄製和回放工具。至於為什麼選擇這個工具,接下來聊聊。
3. 技術選型與驗證
3.1 技術選型
一開始選型的時候,經驗不足,並沒有考慮太多因素,只從功能性和知名度兩個維度進行了調研。首先功能上一定要能滿足我們的需求,比如具備流量過濾功能,這樣可以按需錄製指定介面。其次,候選項最好有大廠背書,github 上有很多 star。根據這兩個要求,選出了如下幾個工具:

圖1:技術選型
第一個是選型是阿里開源的工具,全稱是 jvm-sandbox-repeater,這個工具其實是基於 JVM-Sandbox 實現的。原理上,工具通過位元組碼增強的形式,對目標介面進行攔截,以獲取介面參數和返回值,效果等價於 AOP 中的環繞通知 (Around advice)。
第二個選型是 GoReplay,基於 Go 語言實現。底層依賴 pcap 庫提供流量錄製能力。著名的 tcpdump 也依賴於 pcap 庫,所以可以把 GoReplay 看成極簡版的 tcpdump,因為其支援的協議很單一,只支援錄製 http 流量。
第三個選型是 Nginx 的流量鏡像模組 ngx_http_mirror_module,基於這個模組,可以將流量鏡像到一台機器上,實現流量錄製。
第四個選型是阿里云云效里的子產品——雙引擎回歸測試平台,從名字上可以看出來,這個系統是為回歸測試開發的。而我們需求是做壓測,所以這個服務里的很多功能我們用不到。
經過比較篩選後,我們選擇了 GoReplay 作為流量錄製工具。在分析 GoReplay 優缺點之前,先來分析下其他幾個工具存在的問題。
- jvm-sandbox-repeater 這個插件底層基於 JVM-Sandbox 實現,使用時需要把兩個項目的程式碼都載入到目標應用內,對應用運行時環境有侵入。如果兩個項目程式碼存在問題,造成類似 OOM 這種問題,會對目標應用造成很大大的影響。另外因為方向小眾,導致 JVM-Sandbox 應用並不是很廣泛,社區活躍度較低。因此我們擔心出現問題官方無法及時修復,所以這個選型待定。
- ngx_http_mirror_module 看起來是個不錯的選擇,出生「名門」。但問題也有一些。首先只能支援 http 流量,而我們以後一定會支援 dubbo 流量錄製。其次這個插件要把請求鏡像一份出去,勢必要消耗機器的 TCP 連接數、網路頻寬等資源。考慮到我們的流量錄製會持續運行在網關上,所以這些資源消耗一定要考慮。最後,這個模組沒法做到對指定介面進行鏡像,且鏡像功能開關需要修改 nginx 配置實現。線上的配置是不可能,尤其是網關這種核心應用的配置是不能隨便改動的。綜合這些因素,這個選型也被放棄了。
- 阿里雲的引擎回歸測試平台在我們調研時,自身的功能也在打磨,用起來挺麻煩的。其次這個產品屬於雲效的子產品,不單獨出售。另外這個產品主要還是用於回歸測試的,與我們的場景存在較大偏差,所以也放棄了。
接著來說一下 GoReplay 的優缺點,先說優點:
-
單體程式,除了 pcap 庫,沒有其他依賴,也無需配置,所以環境準備很簡單
-
本身是個可執行程式,可直接運行,很輕量。只要傳入合適的參數就能錄製,易使用
-
github 上的 star 數較多,知名度較大,且社區活躍
-
支援流量過濾功能、按倍速回放功能、回放時改寫介面參數等功能,功能上貼合我們的需求
-
資源消耗小,不侵入業務應用 JVM 運行時環境,對目標應用影響較小
對於以 Java 技術棧為基礎的公司來說,GoReplay 由於是 Go 語言開發的,技術棧差異很大,日後的維護和拓展是個大問題。所以單憑這一點,淘汰掉這個選型也是很正常的。但由於其優點也相對突出,綜合其他選型的優缺點考慮後,我們最終還是選擇了 GoReplay 作為最終的選型。最後大家可能會疑惑,為啥不選擇 tcpdump。原因有兩點,我們的需求比較少,用 tcpdump 有種大炮打蚊子的感覺。另一方面,tcpdump 給我們的感覺是太複雜了,駕馭不住(流下了沒有技術的眼淚😭),因此我們一開始就沒怎麼考慮過這個選型。
| 選型 | 語言 | 是否開源 | 優點 | 缺點 |
|---|---|---|---|---|
| GoReplay | Go | ✅ | 1. 開源項目,程式碼簡單,方便訂製 2. 單體持續,依賴少,無需配置,環境準備簡單 3. 工具很輕量,易使用 3. 功能相對豐富,能夠滿足我們所有的需求 4. 自帶回放功能,能夠直接使用錄製數據,無需單獨開發 5. 資源消耗少,且不侵入目標應用的 JVM 運行時環境,影響小 6. 提供了插件機制,且插件實現不限制語言,方便拓展 |
1. 應用不夠廣泛,無大公司背書,成熟度不夠 2. 問題比較多,1.2.0 版本官方直接不推薦使用 3. 接上一條,對使用者的要求較高,出問題情況下要能自己讀源碼解決,官方響應速度一般 4. 社區版只支援 HTTP 協議,不支援二進位協議,且核心邏輯與 HTTP 協議耦合了,拓展較麻煩 5. 只支援命令行啟動,沒有內置服務,不好進行集成 |
| JVM-Sandbox jvm-sandbox-repeater |
Java | ✅ | 1. 通過增強的方式,可以直接對 Java 類方法進行錄製,十分強大 2. 功能比較豐富,較為符合需求 3. 對業務程式碼透明無侵入 |
1. 會對應用運行時環境有一定侵入,如果發生問題,對應用可能會造成影響 2. 工具本身仍然偏向測試回歸,所以導致一些功能在我們的場景下沒法使用,比如不能使用它的回放功能進行高倍速壓測 3. 社區活躍度較低,有停止維護的風險 4. 底層實現確實比較複雜,維護成本也比較高。再次留下了沒有技術的眼淚😢 5. 需要搭配其他的輔助系統,整合成本不低 |
| ngx_http_mirror_module | C | ✅ | 1. nginx 出品,成熟度可以保證 2. 配置比較簡單 |
1. 不方便啟停,也不支援過濾 2. 必須和 nginx 搭配只用,因此使用範圍也比較受限 |
| 阿里雲引擎回歸測試平台 | – | ❌ | – | – |
3.2 選型驗證
選型完成後,緊接著要進行功能、性能、資源消耗等方面的驗證,測試選型是否符合要求。根據我們的需求,做了如下的驗證:
- 錄製功能驗證,驗證流量錄製的是否完整,包含請求數量完整性和請求數據準確性。以及在流量較大情況下,資源消耗情況驗證
- 流量過濾功能驗證,驗證能否過濾指定介面的流量,以及流量的完整性
- 回放功能驗證,驗證流量回放是否能如預期工作,回放的請求量是否符合預期
- 倍速回放驗證,驗證倍速功能是否符合預期,以及高倍速回放下資源消耗情況
以上幾個驗證當時在線下都通過了,效果很不錯,大家也都挺滿意的。可是倍速回放這個功能,在生產環境上進行驗證時,回放壓力死活上不去,只能壓到約 600 的 QPS。之後不管再怎麼增壓,QPS 始終都在這個水位。我們與業務線同事使用不同的錄製數據在線上測試了多輪均不行,開始以為是機器資源出現了瓶頸。可是我們看了 CPU 和記憶體消耗都非常低,TCP 連接數和頻寬也是很富餘的,因此資源是不存在瓶頸的。這裡也凸顯了一個問題,早期我們只對工具做了功能測試,沒有做性能測試,導致這個問題沒有儘早暴露出來。於是我自己在線下用 nginx 和 tomcat 搭建了一個測試服務,進行了一些性能測試,發現隨隨便便就能壓到幾千的 QPS。看到這個結果啼笑皆非,腦裂了😭。後來發現是因為線下的服務的 RT 太短了,與線上差異很大導致的。於是讓執行緒隨機睡眠幾十到上百毫秒,此時效果和線上很接近。到這裡基本上能夠大致確定問題範圍了,應該是 GoReplay 出現了問題。但是 GoReplay 是 Go 語言寫的,大家對 Go 語言都沒經驗。眼看著問題解決唾手可得,可就是無處下手,很窒息。後來大佬們拍板決定投入時間深入 GoReplay 源碼,通過分析源碼尋找問題,自此我開始了 Go 語言的學習之路。原計劃兩周給個初步結論,沒想到一周就找到了問題。原來是因為 GoReplay v1.1.0 版本的使用文檔與程式碼實現出現了很大的偏差,導致按照文檔操作就是達不到預期效果。具體細節如下:

圖2:GoReplay 使用說明
先來看看坑爹的文檔是怎麼說的,--output-http-workers 這個參數表示有多少個協程同時用於發生 http 請求,默認值是0,也就是無限制。再來看看程式碼(output_http.go)是怎麼實現的:

圖3:GoRepaly 協程並發數決策邏輯
文檔里說默認 http 發送協程數無限制,結果程式碼里設置了 10,差異太大了。為什麼 10 個協程不夠用呢,因為協程需要原地等待響應結果,也就是會被阻塞住,所以10個協程能夠打出的 QPS 是有限的。原因找到後,我們明確設定 –output-http-workers 參數值,倍速回放的 QPS 最終驗證下來能夠達到要求。
這個問題發生後,我們對 GoReplay 產生了很大的懷疑,感覺這個問題比較低級。這樣的問題都會出現,那後面是否還會出現有其他問題呢,所以用起來心裡發毛。當然,由於這個項目維護的人很少,基本可以認定是個人項目。且該項目經過沒有大規模的應用,尤其沒有大公司的背書,出現這樣的問題也能理解,沒必要太苛責。因此後面碰到問題只能見招拆招了,反正程式碼都有了,直接白盒審計吧。
3.3 總結與反思
先說說選型過程中存在的問題吧。從上面的描述上來看,我在選型和驗證過程均犯了一些較為嚴重的錯誤,被自己生動的上了一課。在選型階段,對於知名度,居然認為 star 比較多就算比較有名了,現在想想還是太幼稚了。比起知名度,成熟度其實更重要,穩定坑少下班早🤣。另外,可觀測性也一定要考慮,否則查問題時你將體驗到什麼是無助感。
在驗證階段,功能驗證沒有太大問題。但性能驗證只是象徵性的搞了一下,最終在與業務線同事一起驗證時翻車了。所以驗證期間,性能測試是不能馬虎的,一旦相關問題上線後才發現,那就很被動了。
根據這次的技術選型經歷做個總結,以後搞技術選型時再翻出來看看。選型維度總結如下:
| 維度 | 說明 |
|---|---|
| 功能性 | 1. 選型的功能是否能夠滿足需求,如果不滿足,二次開發的成本是怎樣的 |
| 成熟度 | 1. 在相關領域內,選型是否經過大範圍使用。比如 Java Web 領域,Spring 技術棧基本人盡皆知 2. 一些小眾領域的選型可能應用並不是很廣泛,那隻能自己多去看看 issue,搜索一些踩坑記錄,自行評估了 |
| 可觀測性 | 1. 內部狀態數據是否有觀測手段,比如 GoReplay 會把內部狀態數據定時列印出來 2. 方不方便接入公司的監控系統也要考慮,畢竟人肉觀察太費勁 |
驗證總結如下:
- 根據要求一項一項的去驗證選型的功能是否符合預期,可以搞個驗證的 checklist 出來,逐項確認
- 從多個可能的方面對選型進行性能測試,在此過程中注意觀察各種資源消耗情況。比如 GoReplay 流量錄製、過濾和回放功能都是必須要做性能測試的
- 對選型的長時間運行的穩定性要進行驗證,對驗證期間存在的異常情況注意觀測和分析
- 更嚴格一點,可以做一些故障測試。比如殺進程,斷網等
關於選型更詳細的實戰經驗,可以參考李運華大佬的文章:如何正確的使用開源項目。
4. 具體實踐
當技術選型和驗證都完成後,接下來就是要把想法變為現實的時候了。按照現在小步快跑,快速迭代的模式,啟動階段通常我們僅會規劃最核心的功能,保證流程走通。接下來再根據需求的優先順序進行迭代,逐步完善。接下來,我將在按照項目的迭代過程來進行介紹。
4.1 最小可用系統
4.1.1 需求介紹
| 序號 | 分類 | 需求點 | 說明 |
|---|---|---|---|
| 1 | 錄製 | 流量過濾,按需錄製 | 支援按 HTTP 請求路徑過濾流量,這樣可以錄製指定介面的流量 |
| 2 | 錄製時長可指定 | 可設定錄製時長,一般情況下都是錄製10分鐘,把流量波峰錄製下來 | |
| 3 | 錄製任務詳情 | 包含錄製狀態、錄製結果統計等資訊 | |
| 4 | 回放 | 回放時長可指定 | 支援設定 1 ~ 10 分鐘的回放時長 |
| 5 | 回放倍速可指定 | 根據錄製時的 QPS,按倍數進行流量放大,最小粒度為 1 倍速 | |
| 6 | 回放過程允許人為終止 | 在發現被壓測應用出現問題時,可人為終止回放過程 | |
| 7 | 回放任務詳情 | 包含回放狀態、回放結果統計 |
以上就是項目啟動階段的需求列表,這些都是最基本需求。只要完成這些需求,一個最小可用的系統就實現了。
4.1.2 技術方案簡介
4.1.2.1 架構圖
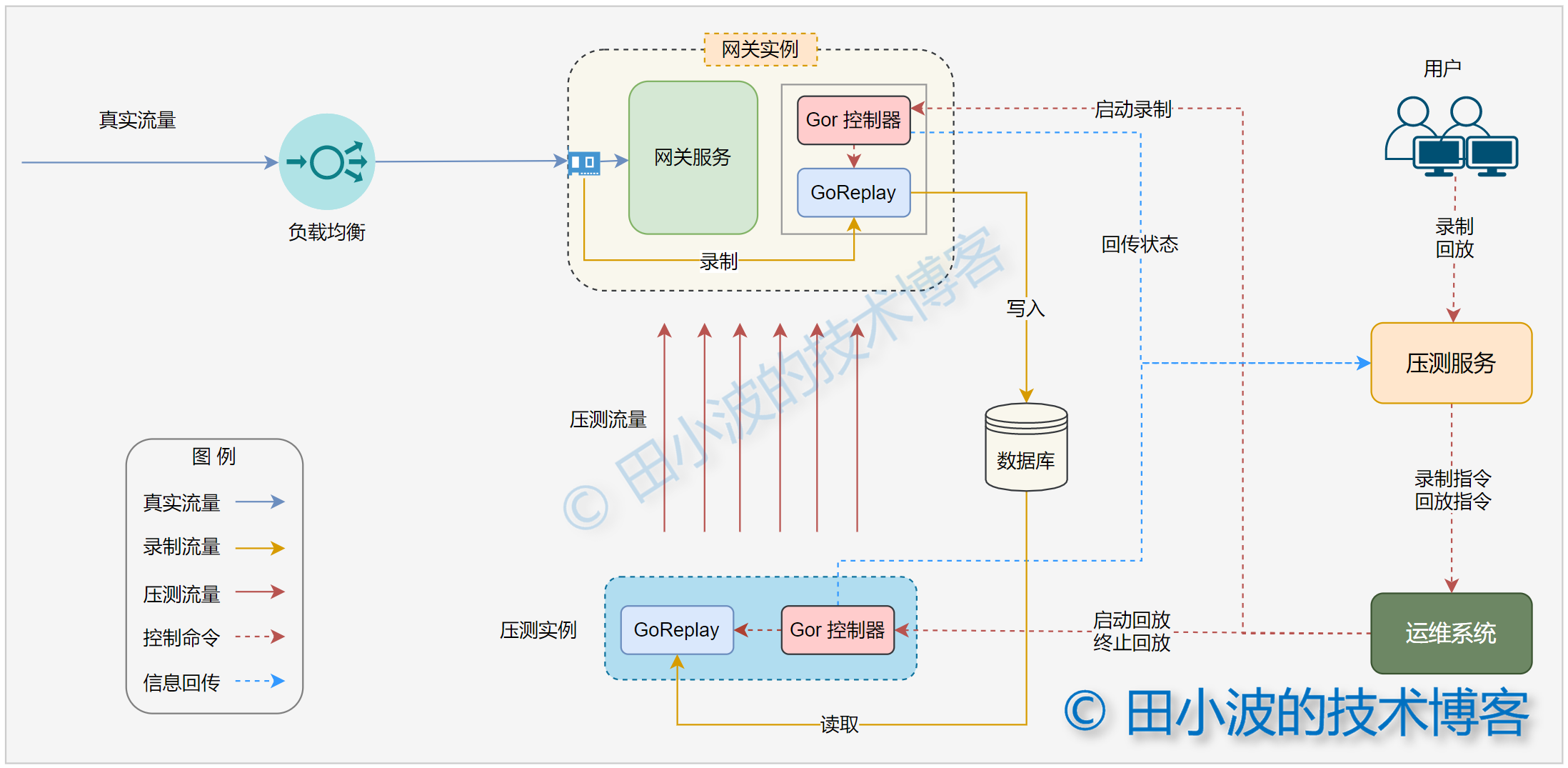
圖4:壓測系統一期架構圖
上面的架構圖經過編輯,與實際有一定差異,但不影響講解。需要說明的是,我們的網關服務、壓測機以及壓測服務都是分別由多台構成,所有網關和壓測實例均部署了 GoRepaly 及其控制器。這裡為了簡化架構圖,只畫了一台機器。下面對一些核心流程進行介紹。
4.1.2.2 Gor 控制器
在介紹其他內容之前,先說一下 Gor 控制器的用途。用一句話介紹:引入這個中間層的目的是為了將 GoReplay 這個命令行工具與我們的壓測系統進行整合。這個模組是我們自己開發,最早使用 shell 編寫的(苦不堪言😭),後來用 Go 語言重寫了。Gor 控制器主要負責下面一些事情:
- 掌握 GoRepaly 生殺大權,可以調起和終止 GoReplay 程式
- 屏蔽掉 GoReplay 使用細節,降低複雜度,提高易用性
- 回傳狀態,在 GoReplay 啟動前、結束後、其他標誌性事件結束後都會向壓測系統回傳狀態
- 對錄製和回放產生數據進行處理與回傳
- 打日誌,記錄 GoRepaly 輸出的狀態數據,便於後續排查
GoReplay 本身只提供最基本的功能,可以把其想像成一個只有底盤、輪子、方向盤和發動機等基本配件的汽車,雖然能開起來,但是比較費勁。而我們的 Gor 控制器相當於在其基礎上提供了一鍵啟停,轉向助力、車聯網等增強功能,讓其變得更好用。當然這裡只是一個近似的比喻,不要糾結合理性哈。知曉控制器的用途後,下面介紹啟動和回放的執行過程。
4.1.2.3 錄製過程介紹
用戶的錄製命令首先會發送給壓測服務,壓測服務原本可以通過 SSH 直接將錄製命令發送給 Gor 控制器的,但出於安全考慮必須繞道運維繫統。Gor 控制器收到錄製命令後,參數驗證無誤,就會調起 GoReplay。錄製結束後,Gor 控制器會將狀態回傳給壓測系統,由壓測判定錄製任務是否結束。詳細的流程如下:
- 用戶設定錄製參數,提交錄製請求給壓測服務
- 壓測服務生成壓測任務,並根據用戶指定的參數生成錄製命令
- 錄製命令經由運維繫統下發到具體的機器上
- Gor 控制器收到錄製命令,回傳「錄製即將開始」的狀態給壓測服務,隨後調起 GoReplay
- 錄製結束,GoReplay 退出,Gor 控制器回傳「錄製結束」狀態給壓測服務
- Gor 控制器回傳其他資訊給壓測系統
- 壓測服務判定錄製任務結束後,通知壓測機將錄製數據讀取到本地文件中
- 錄製任務結束
這裡說明一下,要想使用 GoReplay 倍速回放功能,必須要將錄製數據存儲到文件中。然後通過下面的參數設置倍速:
# 三倍速回放
gor --input-file "requests.gor|300%" --output-http "test.com"
4.1.2.4 回放過程介紹
回放過程與錄製過程基本相似,只不過回放的命令是固定發送給壓測機的,具體過程就不贅述了。下面說幾個不同點:
- 給回放流量打上壓測標:回放流量要與真實流量區分開,需要一個標記,也就是壓測標
- 按需改寫參數:比如把 user-agent 改為 goreplay,或者增加測試帳號的 token 資訊
- GoReplay 運行時狀態收集:包含 QPS,任務隊列積壓情況等,這些資訊可以幫助了解 GoReplay 的運行狀態
4.1.3 不足之處
這個最小可用系統在線上差不多運行了4個月,沒有出現過太大的問題,但仍然有一些不足之處。主要有兩點:
- 命令傳遞的鏈路略長,增大的出錯的概率和排查的難度。比如運維繫統的介面偶爾失敗,關鍵還沒有日誌,一開始根本沒法查問題
- Gor 控制器是用 shell 寫的,約 300 行。shell 語法和 Java 差異比較大,程式碼也不好調試。同時對於複雜的邏輯,比如生成 JSON 字元串,寫起來很麻煩,後續維護成本較高
這兩點不足一直伴隨著我們的開發和運維工作,直到後面進行了一些優化,才算是徹底解決掉了這些問題。
4.2 持續優化
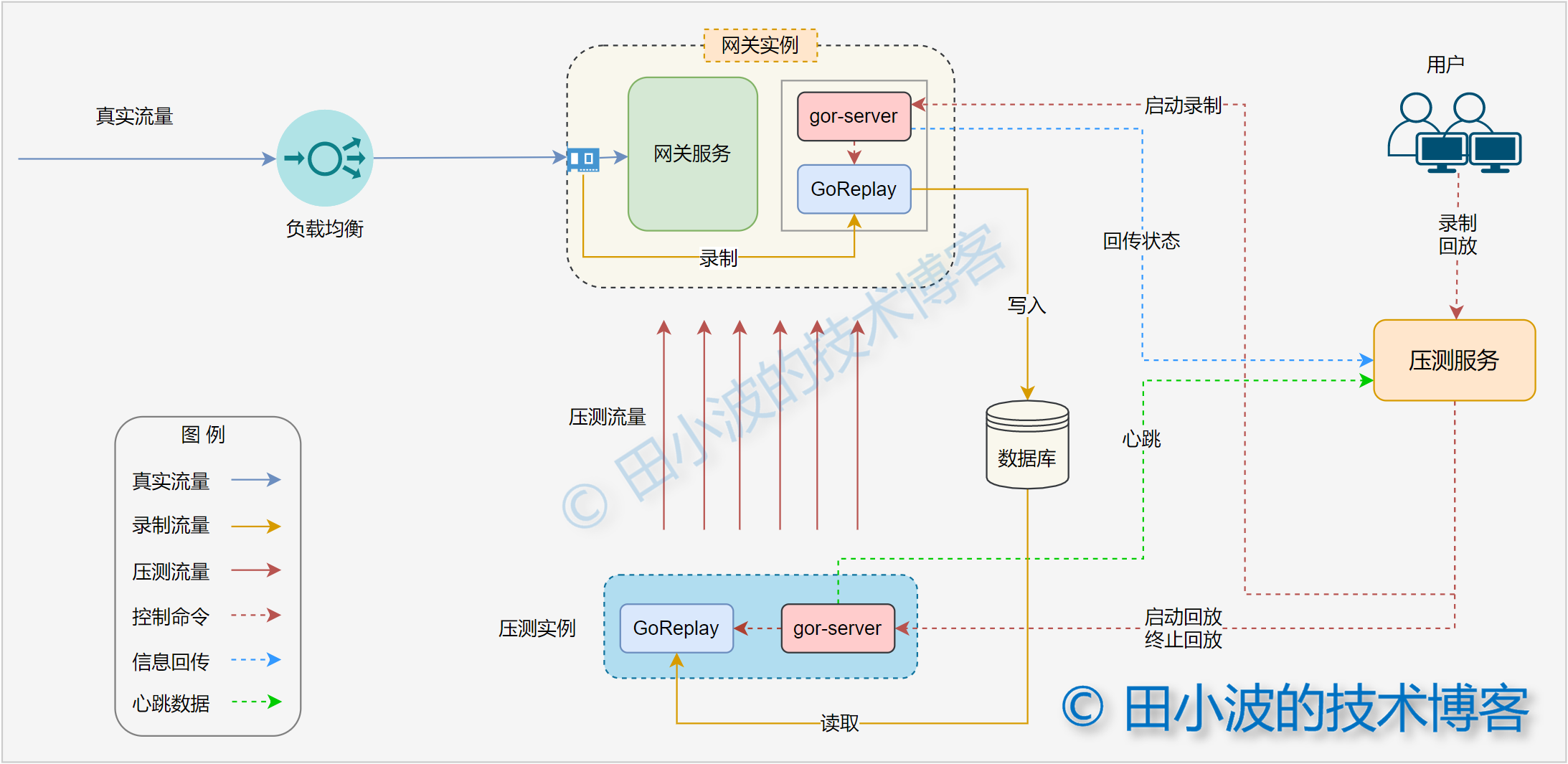
圖5:Gor 控制器優化後的架構圖
針對前面存在的痛點,我們進行了針對性的改進。重點使用 Go 語言重寫了 gor 控制器,新的控制器名稱為 gor-server。從名稱上可以看出,我們內置了一個 HTTP 服務。基於這個服務,壓測服務下發命令終於不用再繞道運維繫統了。同時所有的模組都在我們的掌控中,開發和維護的效率明顯變高了。
4.3 支援 Dubbo 流量錄製
我們內部採用 Dubbo 作為 RPC 框架,應用之間的調用均是通過 Dubbo 來完成的,因此我們對 Dubbo 流量錄製也有較大的需求。在針對網關流量錄製取得一定成果後,一些負責內部系統的同事也希望通過 GoReplay 來進行壓測。為了滿足內部的使用需求,我們對 GoReplay 進行了二次開發,以便支援 Dubbo 流量的錄製與回放。
4.3.1 Dubbo 協議介紹
要對 Dubbo 錄製進行支援,需首先搞懂 Dubbo 協議內容。Dubbo 是一個二進位協議,它的編碼規則如下圖所示:

圖6:Dubbo 協議圖示;來源:Dubbo 官方網站
下面簡單對協議做個介紹,按照圖示順序依次介紹各欄位的含義。
| 欄位 | 位數(bit) | 含義 | 說明 |
|---|---|---|---|
| Magic High | 8 | 魔數高位 | 固定為 0xda |
| Magic Low | 8 | 魔數低位 | 固定為 0xbb |
| Req/Res | 1 | 數據包類型 | 0 – Response 1 – Request |
| 2way | 1 | 調用方式 | 0 – 單向調用 1 – 雙向調用 |
| Event | 1 | 事件標識 | 比如心跳事件 |
| Serialization ID | 5 | 序列化器編號 | 2 – Hessian2Serialization 3 – JavaSerialization 4 – CompactedJavaSerialization 6 – FastJsonSerialization …… |
| Status | 8 | 響應狀態 | 狀態列表如下: 20 – OK 30 – CLIENT_TIMEOUT 31 – SERVER_TIMEOUT 40 – BAD_REQUEST 50 – BAD_RESPONSE …… |
| Request ID | 64 | 請求 ID | 響應頭中也會攜帶相同的 ID,用於將請求和響應關聯起來 |
| Data Length | 32 | 數據長度 | 用於標識 Variable Part 部分的長度 |
| Variable Part(payload) | – | 數據載荷 |
知曉了協議內容後,我們把官方的 demo 跑起來,抓個包研究一下。
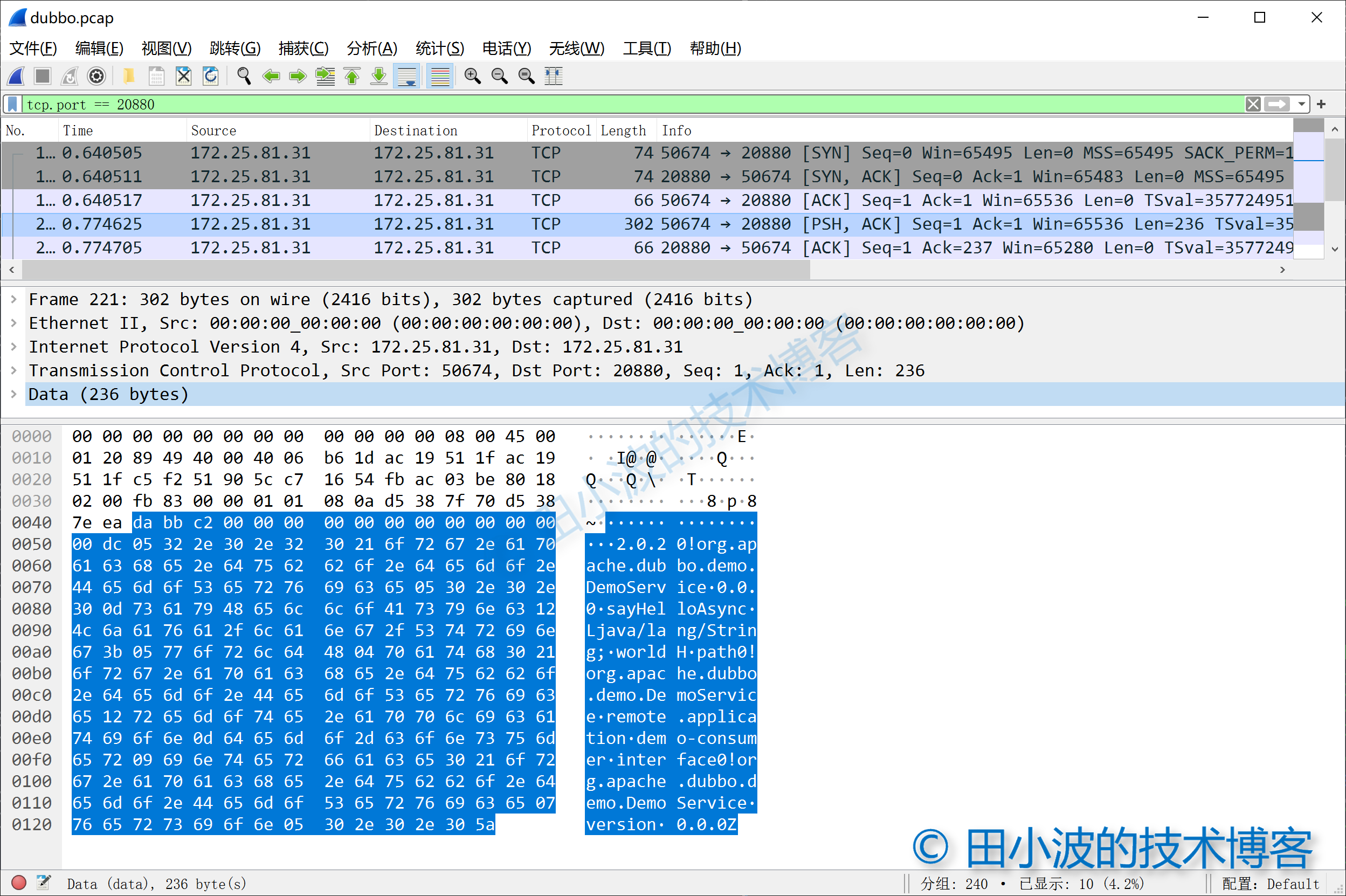
圖7:dubbo 請求抓包
首先我們可以看到佔用兩個位元組的魔數 0xdabb,接下來的14個位元組是協議頭中的其他內容,簡單分析一下:

圖8:dubbo 請求頭數據分析
上面標註的比較清楚了,這裡稍微解釋一下。從第三個位元組可以看出這個數據包是一個 Dubbo 請求,因為是第一個請求,所以請求 ID 是 0。數據的長度是 0xdc,換算成十進位為 220 個位元組。加上16個位元組的消息頭,總長度正好是 236,與抓包結果顯示的長度是一致。
4.3.2 Dubbo 協議解析
我們對 Dubbo 流量錄製進行支援,首先需要按照 Dubbo 協議對數據包進行解碼,以判斷錄製到的數據是不是 Dubbo 請求。那麼問題來了,如何判斷所錄製到的 TCP 報文段里的數據是 Dubbo 請求呢?答案如下:
- 首先判斷數據長度是不是大於等於協議頭的長度,即 16 個位元組
- 判斷數據前兩個位元組是否為魔數 0xdabb
- 判斷第17個比特位是不是 1,不為1可丟棄掉
通過上面的檢測可快速判斷出數據是否符合 Dubbo 請求格式。如果檢測通過,那接下來又如何判斷錄製到的請求數據是否完整呢?答案是通過比較錄製到的數據長度 L1 和 Data Length 欄位給出的長度 L2,根據比較結果進行後續操作。有如下幾種情況:
- L1 == L2,說明數據接收完整,無需額外的處理邏輯
- L1 < L2,說明還有一部分數據沒有接收,繼續等待餘下數據
- L1 > L2,說明多收到了一些數據,這些數據並不屬於當前請求,此時要根據 L2 來切分收到的數據
三種情況示意圖如下:
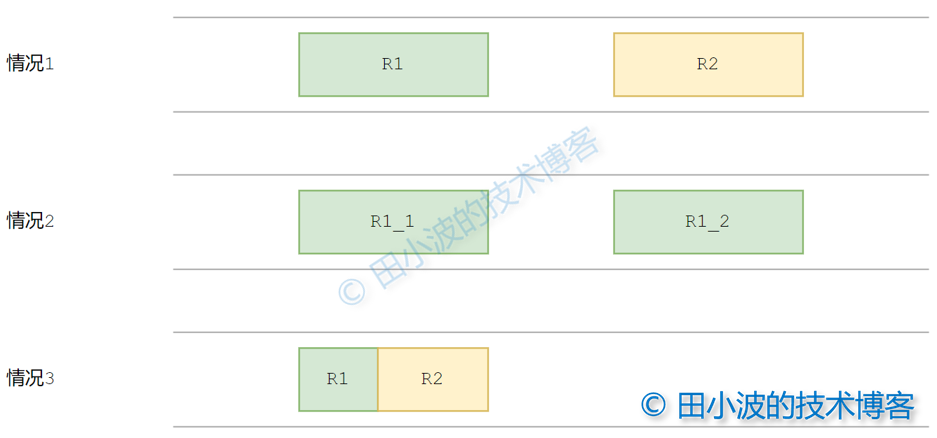
圖9:應用層接收端幾種情況
看到這裡,肯定有同學想說,這不就是典型的 TCP 「粘包」和「拆包」問題。不過我並不想用這兩個詞來說明上述的一些情況。TCP 是一個面向位元組流的協議,協議本身並不存在所謂的「粘包」和「拆包」問題。TCP 在傳輸數據過程中,並不會理會上層數據是如何定義的,在它看來都是一個個的位元組罷了,它只負責把這些位元組可靠有序的運送到目標進程。至於情況2和情況3,那是應用層應該去處理的事情。因此,我們可以在 Dubbo 的程式碼中找到相關的處理邏輯,有興趣的同學可以閱讀 NettyCodecAdapter.InternalDecoder#decode 方法程式碼。
本小節內容就到這裡,最後給大家留下一個問題。在 GoReplay 的程式碼中,並沒有對情況3進行處理。為什麼錄製 HTTP 協議流量不會出錯?
4.3.3 GoReplay 改造
4.3.3.1 改造介紹
GoReplay 社區版目前只支援 HTTP 流量錄製,其商業版支援部分二進位協議,但不支援 Dubbo。所以為了滿足內部使用需求,只能進行二次開發了。但由於社區版程式碼與 HTTP 協議處理邏輯耦合比較大,因此想要支援一種新的協議錄製,還是比較麻煩的。在我們的實現中,對 GoReplay 的改造主要包含 Dubbo 協議識別,Dubbo 流量過濾,數據包完整性判斷等。數據包的解碼和反序列化則是交給 Java 程式來實現的,序列化結果轉成 JSON 進行存儲。效果如下:
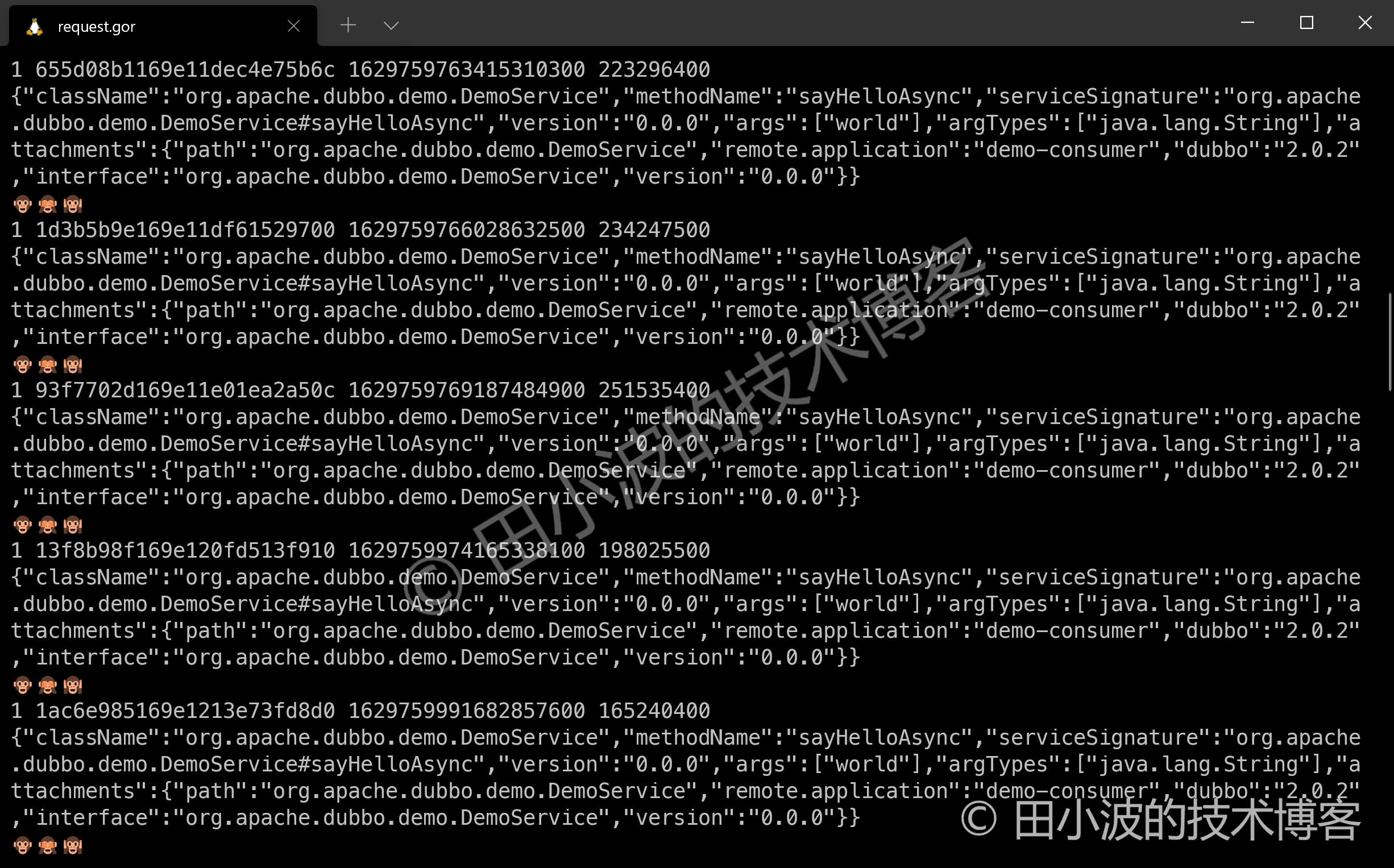
圖10:Dubbo 流量錄製效果
GoReplay 用三個猴頭 🐵🙈🙉 作為請求分隔符,第一眼看到感覺挺搞笑的。
4.3.3.2 GoReplay 插件機制介紹
大家可能很好奇 GoReplay 是怎麼和 Java 程式配合工作的,原理倒也是很簡單。先看一下怎麼開啟 GoReplay 的插件模式:
gor --input-raw :80 --middleware "java -jar xxx.jar" --output-file request.gor
通過 middleware 參數可以傳遞一條命令給 GoRepaly,GoReplay 會拉起一個進程執行這個命令。在錄製過程中,GoReplay 通過獲取進程的標準輸入和輸出與插件進程進行通訊。數據流向大致如下:
+-------------+ Original request +--------------+ Modified request +-------------+
| Gor input |----------STDIN---------->| Middleware |----------STDOUT---------->| Gor output |
+-------------+ +--------------+ +-------------+
input-raw java -jar xxx.jar output-file
4.3.3.3 Dubbo 解碼插件實現思路
Dubbo 協議的解碼還是比較容易實現的,畢竟很多程式碼 Dubbo 框架已經寫好了,我們只需要按需對程式碼進行修改訂製即可。協議頭的解析邏輯在 DubboCodec#decodeBody 方法中,消息體的解析邏輯在 DecodeableRpcInvocation#decode(Channel, InputStream) 方法中。由於 GoReplay 已經對數數據進行過解析和處理,因此在插件里很多欄位就沒必要解析了,只要解析出 Serialization ID 即可。這個欄位將指導我們進行後續的反序列化操作。
對於消息體的解碼稍微麻煩點,我們把 DecodeableRpcInvocation 這個類程式碼拷貝一份放在插件項目中,並進行了修改。刪除了不需要的邏輯,只保留了 decode 方法,將其變成了工具類。考慮到我們的插件不方便引入要錄製應用的 jar 包,所以在修改 decode 方法時,還要注意把和類型相關的邏輯移除掉。修改後的程式碼大致如下:
public class RpcInvocationCodec {
public static MyRpcInvocation decode(byte[] bytes, int serializationId) {
ObjectInput in = CodecSupport.getSerializationById(serializationId).deserialize(null, input);
MyRpcInvocation rpcInvocation = new MyRpcInvocation();
String dubboVersion = in.readUTF();
// ......
rpcInvocation.setMethodName(in.readUTF());
// 原程式碼:Class<?>[] pts = DubboCodec.EMPTY_CLASS_ARRAY;
// 修改後把 pts 類型改成 String[],泛化調用時需要用到類型列表
String[] pts = desc2className(int.readUTF());
Object[] args = new Object[pts.length];
for (int i = 0; i < args.length; i++) {
// 原程式碼:args[i] = in.readObject(pts[i]);
// 修改後不在依賴具體類型,直接反序列化成 Map
args[i] = in.readObject();
}
rpcInvocation.setArguments(args);
rpcInvocation.setParameterTypeNames(pts);
return rpcInvocation;
}
}
僅從程式碼開發的角度來說,難度並不是很大,當然前提是要對 Dubbo 的源碼有一定的了解。對我來說,時間主要花在 GoRepaly 的改造上,主要原因是對 Go 語言不熟,邊寫邊查導致效率很低。當功能寫好,調試完畢,看到結果正確輸出,確實很開心。但是,這種開心也僅維持了很短的時間。不久在與業務同事進行線上驗證的時候,插件花樣崩潰,場面一度十分尷尬。報錯資訊看的我一臉懵逼,一時半會解決不了,為了保留點臉面,趕緊終止了驗證🤪。事後排查發現,在將一些的特殊的反序列化數據轉化成 JSON 格式時,出現了死循環,造成 StackOverflowError 錯誤發生。由於插件主流程是單執行緒的,且僅捕獲了 Exception,所以造成了插件錯誤退出。
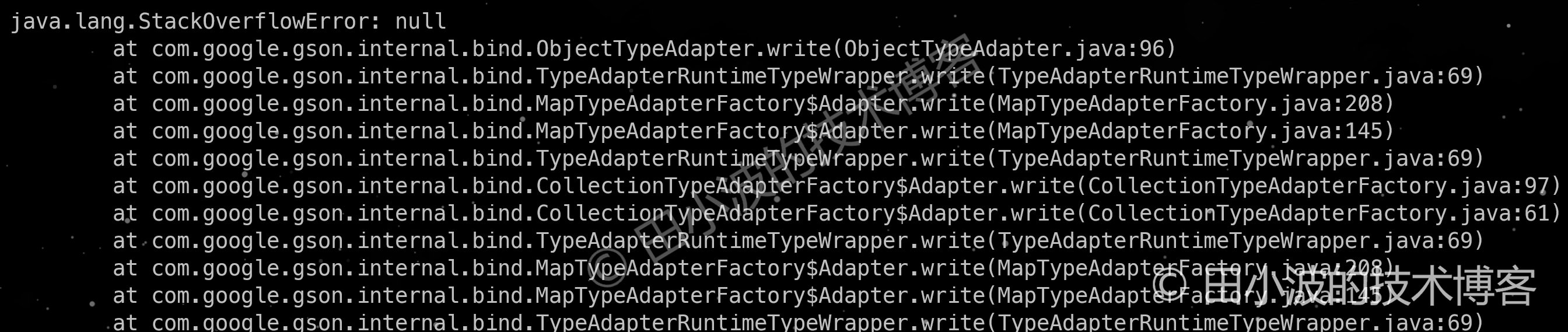
圖11:循環依賴導致 Gson 框架報錯
這個錯誤告訴我們,類之間出現了循環引用,我們的插件程式碼也確實沒有對循環引用進行處理,這個錯誤發生是合理的。但當找到造成這個錯誤的業務程式碼時,並沒找到循環引用,直到我本地調試時才發現了貓膩。業務程式碼類似的程式碼如下:
public class Outer {
private Inner inner;
public class Inner {
private Long xyz;
public class Inner() {
}
}
}
問題出在了內部類上,Inner 會隱式持有 Outer 引用。不出意外,這應該是編譯器乾的。源碼面前了無秘密,我們把內部類的 class 文件反編譯一下,一切就明了了。
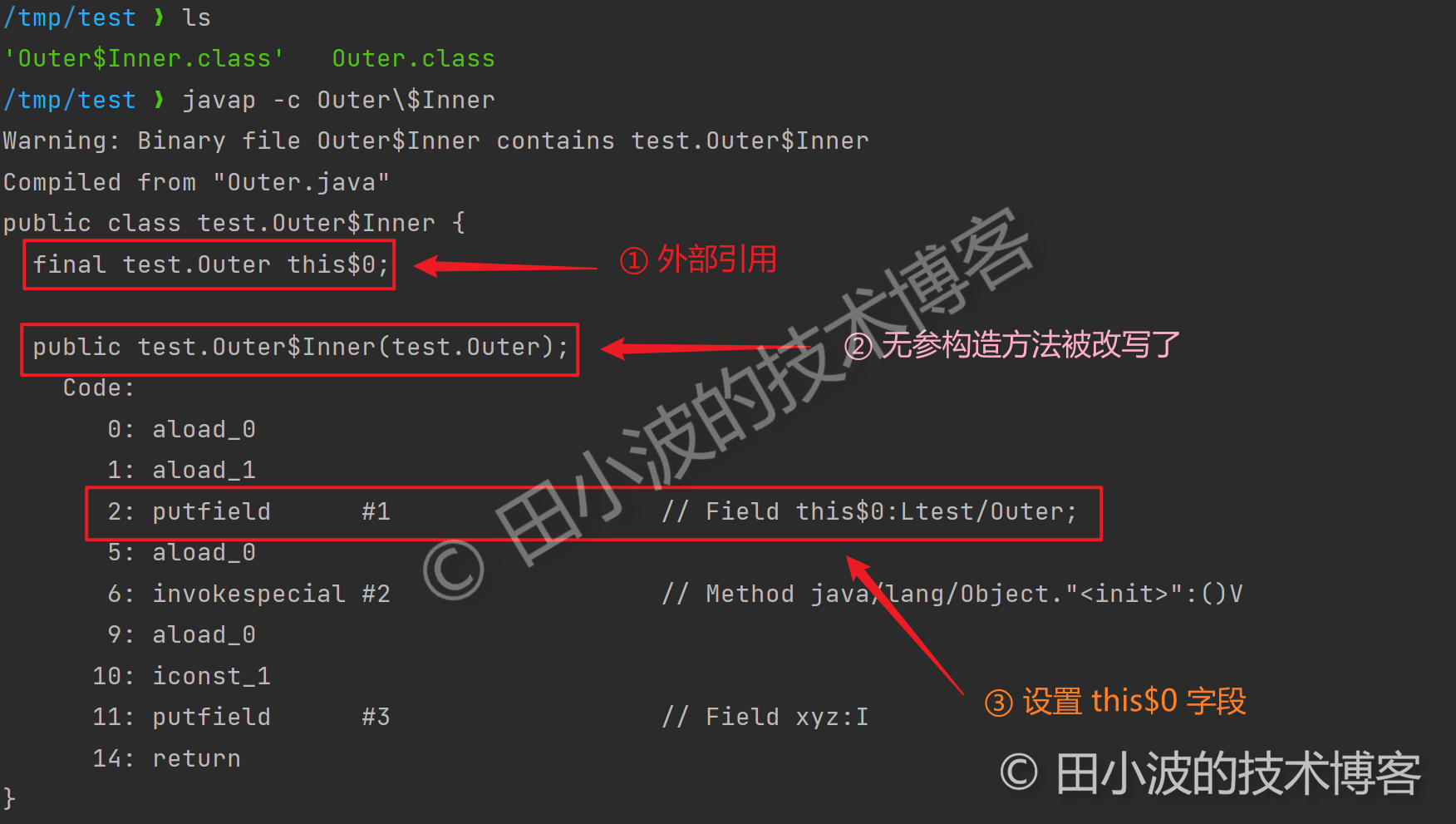
圖12:內部類反編譯結果
這應該算是 Java 基本知識了,奈何平時用的少,第一眼看到程式碼時,沒看出了隱藏在其中的循環引用。到這裡解釋很合理,這就結束了么?其實還沒有,實際上 Gson 序列化 Outer 時並不會報錯,調試發現其會排除掉 this$0 這個欄位,排除邏輯如下:
public final class Excluder
public boolean excludeField(Field field, boolean serialize) {
// ......
// 判斷欄位是否是合成的
if (field.isSynthetic()) {
return true;
}
}
}
那麼我們在把錄製的流量轉成 JSON 時為什麼會報錯呢?原因是我們的插件反序列化時拿不到介面參數的類型資訊,所以我們把參數反序列化成了 Map 對象,這樣 this$0 這個欄位和值也會作為鍵值對存儲到 Map 中。此時 Gson 的過濾規則就不生效了,沒法過濾掉 this$0 這個欄位,造成了死循環,最終導致棧溢出。知道原因後,這麼問題怎麼解決呢?下一小節展開。
4.3.3.4 直擊問題
我開始考慮是不是可以人為清洗一下 Map 里的數據,但發現好像很難搞。如果 Map 的數據結構很複雜,比如嵌套了很多層,清洗邏輯可能不好實現。還有我也不清楚這裡面會不會有其他的一些彎彎繞,所以放棄了這個思路,這種臟活累活還是丟給反序列化工具去做吧。我們要想辦法把拿到介面的參數類型,插件怎麼拿到業務應用 api 的參數類型呢?一種方式是在插件啟動時,把目標應用的 jar 包下載到本地,然後由單獨的類載入器進行載入。但這裡會有一個問題,業務應用的 api jar 包裡面也存在著一些依賴,這些依賴難道要遞歸去下載?第二種方式,則簡單粗暴點,直接在插件項目中引入業務應用 api 依賴,然後打成 fat jar。這樣既不需要搞單獨的類載入器,也不用去遞歸下載其他的依賴。唯一比較明顯的缺點就是會在插件項目 pom 中引入一些不相關的依賴,但與收益相比,這個缺點根本算不上什麼。為了方便,我們把很多業務應用的 api 都依賴了進來。一番操作後,我們得到了如下的 pom 配置:
<project>
<groupId>com.xxx.middleware</groupId>
<artifactId>DubboParser</artifactId>
<version>1.0</version>
<dependencies>
<dependency>
<groupId>com.xxx</groupId>
<artifactId>app-api-1</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>com.xxx</groupId>
<artifactId>app-api-2</artifactId>
<version>1.0</version>
</dependency>
......
<dependencies>
</project>
接著要改一下 RpcInvocationCodec#decode 方法,其實就是把程式碼還原回去😓:
public class RpcInvocationCodec {
public static MyRpcInvocation decode(byte[] bytes, int serializationId) {
ObjectInput in = CodecSupport.getSerializationById(serializationId).deserialize(null, input);
MyRpcInvocation rpcInvocation = new MyRpcInvocation();
String dubboVersion = in.readUTF();
// ......
rpcInvocation.setMethodName(in.readUTF());
// 解析介面參數類型
Class<?>[] pts = ReflectUtils.desc2classArray(desc);
Object args = new Object[pts.length];
for (int i = 0; i < args.length; i++) {
// 根據具體類型進行反序列化
args[i] = in.readObject(pts[i]);
}
rpcInvocation.setArguments(args);
rpcInvocation.setParameterTypeNames(pts);
return rpcInvocation;
}
}
程式碼調整完畢,擇日在上線驗證,一切正常,可喜可賀。但不久後,我發現這裡面存在著一些隱患。如果哪天在線上發生了,將會給排查工作帶來比較大的困難。
4.3.3.5 潛在的問題
考慮這樣的情況,業務應用 A 和應用 B 的 api jar 包同時依賴了一些內部的公共包,公共包的版本可能不一致。這時候,我們怎麼處理依賴衝突?如果內部的公共包做的不好,存在兼容性問題怎麼辦。
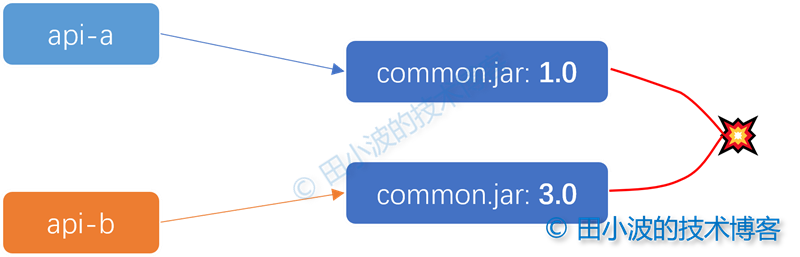
圖13:依賴衝突示意圖
比如這裡的 common 包版本衝突了,而且 3.0 不兼容 1.0,怎麼處理呢?
簡單點處理,我們就不在插件 pom 里依賴所有的業務應用的 api 包了,而是只依賴一個。但是壞處是,每次都要為不同的應用單獨構建插件程式碼,顯然我們不喜歡這樣的做法。
再進一步,我們不在插件中依賴業務應用的 api 包,保持插件程式碼乾淨,就不用每次都打包了。那怎麼獲取業務應用的 api jar 包呢?答案是為每個 api jar 專門建個項目,再把項目打成 fat jar,插件程式碼使用自定義類載入器去載入業務類。插件啟動時,根據配置去把 jar 包下載到機器上即可。每次只需要載入一個 jar 包,所以也就不存在依賴衝突問題了。做到這一步,問題就可以解決了。
更進一步,早先在閱讀阿里開源的 jvm-sandbox 項目源碼時,發現了這個項目實現了一種帶有路由功能的類載入器。那我們的插件能否也搞個類似的載入器呢?出於好奇,嘗試了一下,發現是可以的。最終的實現如下:
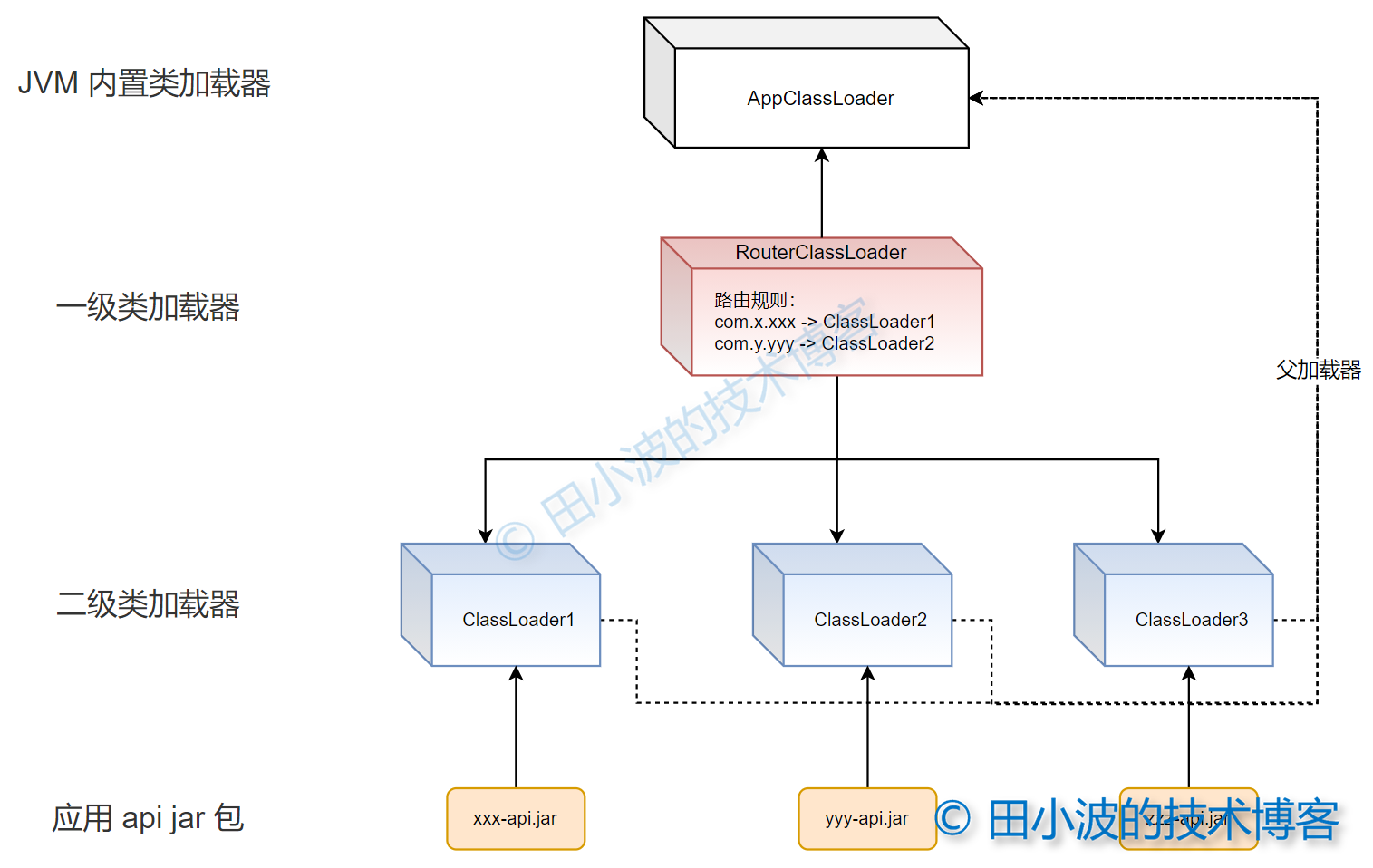
圖14:自定義類載入機制示意圖
一級類載入器具備根據包名「片段」進行路由的功能,二級類載入器負責具體的載入工作。應用 api jar 包統一放在一個文件夾下,只有二級類載入器可以進行載入。對於 JDK 中的一些類,比如 List,還是要交給 JVM 內置的類載入器進行載入。最後說明一下,搞這個帶路由功能的類載入器,主要目的是為了玩。雖然能達到目的,但在實際項目中,還是用上一種方法穩妥點。
4.4 開花結果,落地新場景
我們的流量錄製與回放系統主要的,也是當時唯一的使用場景是做壓測。系統穩定後,我們也在考慮還有沒有其他的場景可以搞。正好在技術選型階段試用過 jvm-sandbox-repeater,這個工具主要應用場景是做流量對比測試。對於程式碼重構這種不影響介面返回值結構的改動,可以通過流量對比測試來驗證改動是否有問題。由於大佬們覺得 jvm-sandbox-repeater 和底層的 jvm-sandbox 有點重,技術複雜度也比較高。加之沒有資源來開發和維護這兩個工具,因此希望我們基於流量錄製和回放系統來做這個事情,先把流程跑通。
項目由 QA 團隊主導,流量重放與 diff 功能由他們開發,我們則提供底層的錄製能力。系統的工作示意圖如下:

圖15:對比測試示意圖
我們的錄製系統為重放器提供實時的流量數據,重放器拿到數據後立即向預發和線上環境重放。重放後,重放器可以分別拿到兩個環境返回的結果,然後再把結果傳給比對模組進行後續的比對。最後把比對結果存入到資料庫中,比對過程中,用戶可以看到哪些請求比對失敗了。對於錄製模組來說,要注意過濾重放流量。否則會造成介面 QPS 倍增,重放變壓測了🤣,喜提故障一枚。
這個項目上線3個月,幫助業務線發現了3個比較嚴重的 bug,6個一般的問題,價值初現。雖然項目不是我們主導的,但是作為底層服務的提供方,我們也很開心。期望未來能為我們的系統拓展更多的使用場景,讓其成長為一棵枝繁葉茂的大樹。
5. 項目成果
截止到文章發布時間,項目上線接近一年的時間了。總共有5個應用接入使用,錄製和回放次數累計差不多四五百次。使用數據上看起來有點寒磣,主要是因為公司業務是 toB 的,對壓測的需求並沒那麼多。儘管使用數據比較低,但是作為壓測系統,還是發揮了相應價值。主要包含兩方面:
- 性能問題發現:壓測平台共為業務線發現了十幾個性能問題,幫助中間件團隊發現了6個嚴重的基礎組件問題
- 使用效率提升:新的壓測系統功能簡單易用,僅需10分鐘就能完成一次線上流量錄製。相較於以往單人半天才能完成的事情,效率至少提升了 20 倍,用戶體驗大幅提升。一個佐證就是目前 90% 以上的壓測任務都是在新平台上完成的。
可能大家對效率提升數據有所懷疑,大家可以思考一下沒有錄製工具如何獲取線上流量。傳統的做法是業務開發修改介面程式碼,加一些日誌,這要注意日誌量問題。之後,把改動的程式碼發布到線上,對於一些比較大的應用,一次發布涉及到幾十台機器,還是相當耗時的。接著,把介面參數數據從日誌文件中清洗出來。最後,還要把這些數據轉換成壓測腳本。這就是傳統的流程,每個步驟都比較耗時。當然,基建好的公司,可以基於全鏈路追蹤平台拿到介面數據。但對於大多數公司來說,可能還是要使用傳統的方式。而在我們的平台上,只需要選擇目標應用和介面、錄製時長、點擊錄製按鈕就行了,用戶操作僅限這些,所以效率提升還是很明顯的。
6. 展望未來
項目項目雖然已經上線一年,但由於人手有限,目前基本只有我一個人在開發維護,所以迭代還是比較慢的。針對目前在實踐中碰到的一些問題,這裡把幾個明顯的問題,希望未來能夠一一解決掉。
1.全鏈路節點壓力圖
目前在壓測的時候,壓測人員需要到監控平台上打開很多個應用的監控頁面,壓測期間需要在多個應用監控之間進行切換。希望未來可以把全鏈路上各節點的壓力圖展示出來,同時可以把節點的報警資訊發送給壓測人員,降低壓測的監視成本。
2.壓測工具狀態收集與可視化
壓測工具自身有一些很有用的狀態資訊,比如任務隊列積壓情況,當前的協程數等。這些資訊在壓測壓力上不去時,可以幫助我們排查問題。比如任務隊列任務數在增大,協程數也保持高位。這時候能推斷出什麼原因嗎?大概率是被壓應用壓力太大,導致 RT 變長,進而造成施壓協程(數量固定)長時間被阻塞住,最終導致隊列出現積壓情況。GoReplay 目前這些狀態資訊輸出到控制台上的,查看起來還是很不方便。同時也沒有告警功能,只能在出問題時被動去查看。所以期望未來能把這些狀態數據放到監控平台上,這樣體驗會好很多。
3.壓力感知與自動調節
目前壓測系統更沒有對業務應用的壓力進行感知,不管壓測應用處於什麼狀態,壓測系統都會按照既定的設置進行壓測。當然由於 GoReplay 並發模型的限制,這個問題目前不用擔心。但未來不排除 GoReplay 的並發模型會發生變化,比如只要任務隊列里有任務,就立即起個協程發送請求,此時就會對業務應用造成很大的風險。
還有一些問題,因為重要程度不高,這裡就不寫了。總的來說,目前我們的壓測需求還是比較少,壓測的 QPS 也不高,導致很多優化都沒法做。比如壓測機性能調優,壓測機器動態擴縮容。但想想我們就4台壓測機,默認配置完全可以滿足需求,所以這些問題都懶得去折騰🤪。當然從個人技術能力提升的角度來說,這些優化還是很有價值的,有時間可以玩玩。
7. 個人收穫
7.1 技術收穫
1. 入門 Go 語言
由於 GoReplay 是 Go 語言開發的,而且我們在使用中確實也遇到了一些問題,不得不深入源碼排查。為了更好的掌控工具,方便排查問題和二次開發,所以專門學習了 Go 語言。目前的水平處於入門階段,菜鳥水平。用 Java 用久了,剛開始學習 Go 語言還是很懵逼的。比如 Go 的方法定義:
type Rectangle struct {
Length uint32
Width uint32
}
// 計算面積
func (r *Rectangle) Area() uint32 {
return r.Length * r.Width
}
當時感覺這個語法非常的奇怪,Area 方法名前面的聲明是什麼鬼。好在我還有點 C 語言的知識,轉念一想,如果讓 C 去實現面向對象又該如何做呢?
struct Rectangle {
uint32_t length;
uint32_t width;
// 成員函數聲明
uint32_t (*Area) (struct Rectangle *rect);
};
uint32_t Area(struct Rectangle *rect) {
return rect->length * rect->width;
}
struct Rectangle *newRect(uint32_t length, uint32_t width)
{
struct Rectangle *rp = (struct Rectangle *) malloc(sizeof(struct Rectangle));
rp->length = length;
rp->width = width;
// 綁定函數
rp->Area = Area;
return rp;
}
int main()
{
struct Rectangle *rp = newRect(5, 8);
uint32_t area = rp->Area(rectptr);
printf("area: %u\n", area);
free(pr);
return 0;
}
搞懂了上面的程式碼,就知道 Go 的方法為什麼要那麼定義了。
隨著學習的深入,發現 Go 的語法特性和 C 還真的很像,居然也有指針的概念,21 世紀的 C 語言果然名不虛傳。於是在學習過程中,會不由自主的對比兩者的特性,按照 C 的經驗去學習 Go。所以當我看到下面的程式碼時,非常的驚恐。
func NewRectangle(length, width uint32) *Rectangle {
var rect Rectangle = Rectangle{length, width}
return &rect
}
func main() {
fmt.Println(NewRectangle(4, 5).Area())
}
當時預期作業系統會無情的拋個 segmentation fault 錯誤給我,但是編譯運行居然沒有問題…問..題..。難道是我錯了?再看一遍,心想沒問題啊,C 語言里不能返回棧空間的指針,Go 語言也不應該這麼操作吧。這裡就體現出兩個語言的區別了,上面的 Rectangle 看起來像是在棧空間里分配到,實際上是在堆空間里分配的,這個和 Java 倒是一樣的。
總的來說,Go 語法和 C 比較像,加之 C 語言是我的啟蒙程式語言。多以對於 Go 語言,也是感覺非常親切和喜歡的。其語法簡單,標準庫豐富易用,使用體驗不錯。當然,由於我目前還在新手村混,沒有用 Go 寫過較大的工程,所以對這個語言的認識還比較淺薄。以上有什麼不對的地方,也請大家見諒。
2. 較為熟練掌握了 GoReplay 原理
GoReplay 錄製和回放核心的邏輯基本都看了一遍,並且在內網也寫過文章分享,這裡簡單和大家聊聊這個工具。GoReplay 在設計上,抽象出了一些概念,比如用輸入和輸出來表示數據來源與去向,用介於輸入和輸出模組之間的中間件實現拓展機制。同時,輸入和輸出可以很靈活的組合使用,甚至可以組成一個集群。
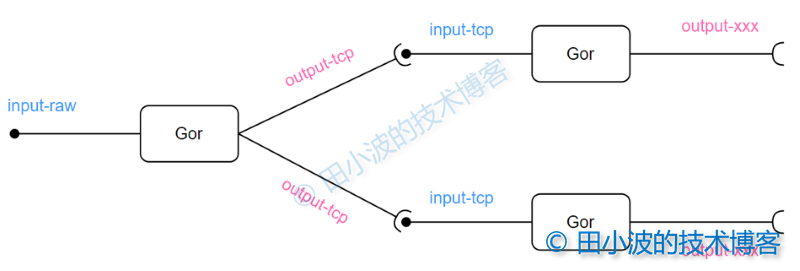
圖16:GoReplay 集群示意圖
錄製階段,每個 tcp 報文段被抽象為 packet。當數據量較大,需要分拆成多個報文段發送時,收端需要把這些報文段按順序序組合起來,同時還要處理亂序、重複報文等問題,保證向下一個模組傳遞的是一個完整無誤的 HTTP 數據。這些邏輯統封裝在了 tcp_message 中,tcp_message 與 packet 是一對多的關係。後面的邏輯會將 tcp_message 中的數據取出,打上標記,傳遞給中間件(可選)或者是輸出模組。
回放階段流程相對簡單,但仍然會按照 輸入 → [中間件] → 輸出 流程執行。通常輸入模組是 input-file,輸出模組是 output-http。回放階段一個有意思的點是倍速回放的原理,通過按倍數縮短請求間的間隔實現加速功能,實現程式碼也很簡單。
總的來說,這個工具的核心程式碼並不多,但是功能還是比較豐富的,可以體驗一下。
3. 對 Dubbo 框架和類載入機制有了更多的認知
在實現 Dubbo 流量錄製時,基本上把解碼相關的邏輯看了一遍。當然這塊邏輯以前也看過,還寫過文章。只不過這次要去訂製程式碼,還是會比單純的看源碼寫文章了解的更深入一些,畢竟要去處理一些實際的問題。在此過程中,由於需要自定義類載入器,所以對類載入機制也有了更多的認識,尤其是那個帶路由功能的類載入器,還是挺好玩的。當然,學會這些技術也沒什麼大不了的,重點還是能夠發現問題,解決問題。
4. 其他收穫
其他的收穫都是一些比較小的點,這裡就不多說了,以問題的形式留給大家思考吧。
- TCP 協議會保證向上層有序交付數據,為何工作在應用層的 GoReplay 還要處理亂序數據?
- HTTP 1.1 協議通訊過程是怎樣的?如果在一個 TCP 連接上連續發送兩個 HTTP 請求會造成什麼問題?
7.2 教訓和感想
1. 技術選型要慎重
開始搞選型沒什麼經驗,考察維度很少,不夠全面。這就導致了幾個問題,首先在驗證階段工具一直達不到預期,耽誤了不少時間。其次在後續的迭代期間,發現 GoReplay 的小問題比較多,感覺嚴謹程度不夠。比如 1.1.0 版本使用文檔和程式碼有很多處差異,使用時要小心。再比如使用過程中,發現 1.3.0-RC1 版本中存在資源泄露問題 #926,順手幫忙修復了一下 #927。當然 RC 版本有問題也很正常,但是這麼明顯的問題說實話不應該出。不過考慮到這個項目是個人維護的,也不能要求太多。但是對於使用者來說,還是要當心。這種要在生產上運行的程式,不靠譜是很鬧心的事情。所以對於我個人而言,以後選型成熟度一定會排在第一位。對於個人維護的項目,盡量不作為靠前的候選項。
2. 技術驗證要全面
初期的選型沒有進行性能測試和極限測試,這就導致問題在線上驗證時才發現。這麼明顯的問題,拖到這麼晚才發現,搞的挺尷尬的。所以對於技術驗證,要從不同的角度進行性能測試,極限測試。更嚴格一點,可以向李運華大佬在 如何正確的使用開源項目 文章中提的那樣,搞搞故障測試,比如殺進程,斷電等。把前期工作做足,避免後期被動。
3. 磨刀不誤砍柴工
這個項目涉及到不同的技術,公司現有的開發平台無法支援這種項目,所以打包和發布是個麻煩事。在開發和測試階段會頻繁的修改程式碼,如果手動進行打包,然後上傳的 FTP 伺服器上(無法直接訪問線上機器),最後再部署到具體的錄製機器上,這是一件十分機械低效的事情。於是我寫了一個自動化構建腳本,來提升構建和部署效率,實踐證明效果挺好。從此心態穩定多了😀,很少進入暴躁模式了。

圖17:自動化構建腳本效果圖
十分尷尬的是,我在項目上線後才把腳本寫好,前期沒有享受到自動化的福利。不過好在後續的迭代中,自動化腳本還是幫了很大的忙。儘早實現編譯和打包自動化工具,有助於提高工作效率。儘管我們會覺得寫工具也要花不少時間,但如果可以預料到很多事情會重複很多次,那麼這些工具帶來的收益將會遠超付出。
8. 寫在最後
非常幸運能夠參與並主導這個項目,總的來說,我個人還是從中學到了很多東西。這算是我職業生涯中第一個深度參與和持續迭代的項目,看著它的功能逐漸完善起來,穩定不間斷給大家提供服務,發揮出其價值。作為項目負責人,我還是非常開心驕傲的。但同時也有些遺憾的,由於公司的業務是 toB 的,對壓測系統的要求並不高。系統目前算是進入了穩定期,沒有太多可做的需求或者大的問題。我雖然可以私下做一些技術上的優化,但很難看出效果,畢竟現有的使用需求還沒達到系統瓶頸,提早優化並不是一個好主意。期望未來公司的業務能有大的發展,對壓測系統提出更高的要求,我也十分樂意繼續優化這個系統。另外,要感謝一起參與項目的同事,他們的強力輸出得以讓項目在緊張的工期內保質保量上線,如期為業務線提供服務。好了,本篇文章到此結束,感謝閱讀。
本文在知識共享許可協議 4.0 下發布,轉載請註明出處
作者:田小波
原創文章優先發布到個人網站,歡迎訪問://www.tianxiaobo.com

本作品採用知識共享署名-非商業性使用-禁止演繹 4.0 國際許可協議進行許可。

