Spring系列之集成Druid連接池及監控配置
前言
前一篇文章我們熟悉了HikariCP連接池,也了解到它的性能很高,今天我們講一下另一款比較受歡迎的連接池:Druid,這是阿里開源的一款資料庫連接池,它官網上聲稱:為監控而生!他可以實現頁面監控,看到SQL的執行次數、時間和慢SQL資訊,也可以對資料庫密碼資訊進行加密,也可以對監控結果進行日誌的記錄,以及可以實現對敏感操作實現開關,杜絕SQL注入,下面我們詳細講一下它如何與Spring集成,並且順便了解一下它的監控的配置。
文章要點:
- Spring集成Druid
- 監控Filters配置(stat、wall、config、log)
- HiKariCP和Druid該如何選擇
如何集成Druid
1、增加相關依賴
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.6</version>
</dependency>
2、配置DataSource
@Configuration
public class DataSourceConfiguration {
@ConfigurationProperties(prefix = "spring.datasource.druid")
@Bean
public DataSource dataSource(){
return new DruidDataSource();
}
}
3、配置項參數application.properties
# 或spring.datasource.url
spring.datasource.druid.url=jdbc:mysql://localhost:3306/chenrui
# 或spring.datasource.username
spring.datasource.druid.username=root
# 或spring.datasource.password
spring.datasource.druid.password=root
#初始化時建立物理連接的個數。初始化發生在顯示調用init方法,或者第一次getConnection時
spring.datasource.druid.initial-size=5
#最大連接池數量
spring.datasource.druid.max-active=20
#最小連接池數量
spring.datasource.druid.min-idle=5
#獲取連接時最大等待時間,單位毫秒。配置了maxWait之後,預設啟用公平鎖,並發效率會有所下降,如果需要可以通過配置useUnfairLock屬性為true使用非公平鎖
spring.datasource.druid.max-wait=500
#是否快取preparedStatement,也就是PSCache。PSCache對支援游標的資料庫性能提升巨大,比如說oracle。在mysql下建議關閉。
spring.datasource.druid.pool-prepared-statements=false
#要啟用PSCache,必須配置大於0,當大於0時,poolPreparedStatements自動觸發修改為true。在Druid中,不會存在Oracle下PSCache佔用記憶體過多的問題,可以把這個數值配置大一些,比如說100
spring.datasource.druid.max-pool-prepared-statement-per-connection-size=-1
#用來檢測連接是否有效的sql,要求是一個查詢語句,常用select 'x'。如果validationQuery為null,testOnBorrow、testOnReturn、testWhileIdle都不會起作用。
spring.datasource.druid.validation-query=select 'x'
#單位:秒,檢測連接是否有效的超時時間。底層調用jdbc Statement對象的void setQueryTimeout(int seconds)方法
spring.datasource.druid.validation-query-timeout=1
#申請連接時執行validationQuery檢測連接是否有效,做了這個配置會降低性能。
spring.datasource.druid.test-on-borrow=true
#歸還連接時執行validationQuery檢測連接是否有效,做了這個配置會降低性能。
spring.datasource.druid.test-on-return=true
#建議配置為true,不影響性能,並且保證安全性。申請連接的時候檢測,如果空閑時間大於timeBetweenEvictionRunsMillis,執行validationQuery檢測連接是否有效
spring.datasource.druid.test-while-idle=true
#有兩個含義:默認1分鐘
#1) Destroy執行緒會檢測連接的間隔時間,如果連接空閑時間大於等於minEvictableIdleTimeMillis則關閉物理連接。
#2) testWhileIdle的判斷依據,詳細看testWhileIdle屬性的說明
spring.datasource.druid.time-between-eviction-runs-millis=60000
# 連接保持空閑而不被驅逐的最小時間
spring.datasource.druid.min-evictable-idle-time-millis=600000
# 連接保持空閑而不被驅逐的最大時間
spring.datasource.druid.max-evictable-idle-time-millis=900000
#配置多個英文逗號分隔
spring.datasource.druid.filters=stat,wall
# WebStatFilter配置
# 是否啟用StatFilter默認值false
spring.datasource.druid.web-stat-filter.enabled=true
# 匹配的url
spring.datasource.druid.web-stat-filter.url-pattern=/*
# 排除一些不必要的url,比如.js,/jslib/等等
spring.datasource.druid.web-stat-filter.exclusions=*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico,/druid/*
# 你可以關閉session統計功能
spring.datasource.druid.web-stat-filter.session-stat-enable=true
# 默認sessionStatMaxCount是1000個,你也可以按需要進行配置
spring.datasource.druid.web-stat-filter.session-stat-max-count=1000
# 使得druid能夠知道當前的session的用戶是誰
spring.datasource.druid.web-stat-filter.principal-session-name=cross
# 如果你的user資訊保存在cookie中,你可以配置principalCookieName,使得druid知道當前的user是誰
spring.datasource.druid.web-stat-filter.principal-cookie-name=aniu
# 配置profileEnable能夠監控單個url調用的sql列表
spring.datasource.druid.web-stat-filter.profile-enable=
# 配置_StatViewServlet配置,用於展示Druid的統計資訊
#是否啟用StatViewServlet(監控頁面)默認值為false(考慮到安全問題默認並未啟動,如需啟用建議設置密碼或白名單以保障安全)
spring.datasource.druid.stat-view-servlet.enabled=true
spring.datasource.druid.stat-view-servlet.url-pattern=/druid/*
#允許清空統計數據
spring.datasource.druid.stat-view-servlet.reset-enable=true
#監控頁面登陸的用戶名
spring.datasource.druid.stat-view-servlet.login-username=root
# 登陸監控頁面所需的密碼
spring.datasource.druid.stat-view-servlet.login-password=1234
# deny優先於allow,如果在deny列表中,就算在allow列表中,也會被拒絕。
# 如果allow沒有配置或者為空,則允許所有訪問
#允許的IP
# spring.datasource.druid.stat-view-servlet.allow=
#拒絕的IP
#spring.datasource.druid.stat-view-servlet.deny=127.0.0.1
#指定xml文件所在的位置
mybatis.mapper-locations=classpath:mapper/*Mapper.xml
#開啟資料庫欄位和類屬性的映射支援駝峰
mybatis.configuration.map-underscore-to-camel-case=true
4、程式碼相關
資料庫腳本
create table user_info
(
id bigint unsigned auto_increment
primary key,
user_id int not null comment '用戶id',
user_name varchar(64) not null comment '真實姓名',
email varchar(30) not null comment '用戶郵箱',
nick_name varchar(45) null comment '昵稱',
status tinyint not null comment '用戶狀態,1-正常,2-註銷,3-凍結',
address varchar(128) null
)
comment '用戶基本資訊';
初始化數據
INSERT INTO chenrui.user_info (id, user_id, user_name, email, nick_name, status, address) VALUES (1, 80001, '張三丰', '[email protected]', '三哥', 1, '武當山');
INSERT INTO chenrui.user_info (id, user_id, user_name, email, nick_name, status, address) VALUES (2, 80002, '張無忌', '[email protected]', '', 1, null);
mapper.xml文件編寫
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"//mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.springdataSourcedruid.dao.UserInfoDAO">
<select id="findAllUser" resultType="com.example.springdataSourcedruid.entity.UserInfo">
select * from user_info
</select>
<select id="getUserById" resultType="com.example.springdataSourcedruid.entity.UserInfo">
select * from user_info where id = #{id}
</select>
<select id="getUserByIdEqualOne" resultType="com.example.springdataSourcedruid.entity.UserInfo">
select * from user_info where id =1
</select>
<select id="getUserByIdEqualTwo" resultType="com.example.springdataSourcedruid.entity.UserInfo">
select * from user_info where id =2
</select>
</mapper>
編寫DAO介面
public interface UserInfoDAO {
List<UserInfo> findAllUser();
UserInfo getUserById(@Param("id") int id);
UserInfo getUserByIdEqualOne();
UserInfo getUserByIdEqualTwo();
}
測試controller
@RestController
@Slf4j
public class UserInfoController {
@Resource
private UserInfoDAO userInfoDAO;
@GetMapping(path = "/all")
public List<UserInfo> getAllUser(){
return userInfoDAO.findAllUser();
}
@GetMapping(path = "/getUser/{id}")
public UserInfo getById(@PathVariable int id){
return userInfoDAO.getUserById(id);
}
@GetMapping(path = "/getUser/one")
public UserInfo getById1(){
return userInfoDAO.getUserByIdEqualOne();
}
@GetMapping(path = "/getUser/two")
public UserInfo getById2(){
return userInfoDAO.getUserByIdEqualTwo();
}
}
啟動類
@SpringBootApplication
@MapperScan(basePackages = "com.example.springdataSourcedruid.dao")
public class SpringDataSourceDruidApplication {
public static void main(String[] args) {
SpringApplication.run(SpringDataSourceDruidApplication.class, args);
}
}
5、啟動驗證
訪問://127.0.0.1:8080/druid/ ,彈出登陸介面,用戶和密碼對應我們的配置文件中設置的用戶名和密碼
登陸進去可以看到裡面有很多監控,這裡我們只看我們本次所關心的,數據源,SQL監控,URL監控,其他的可以自行研究。
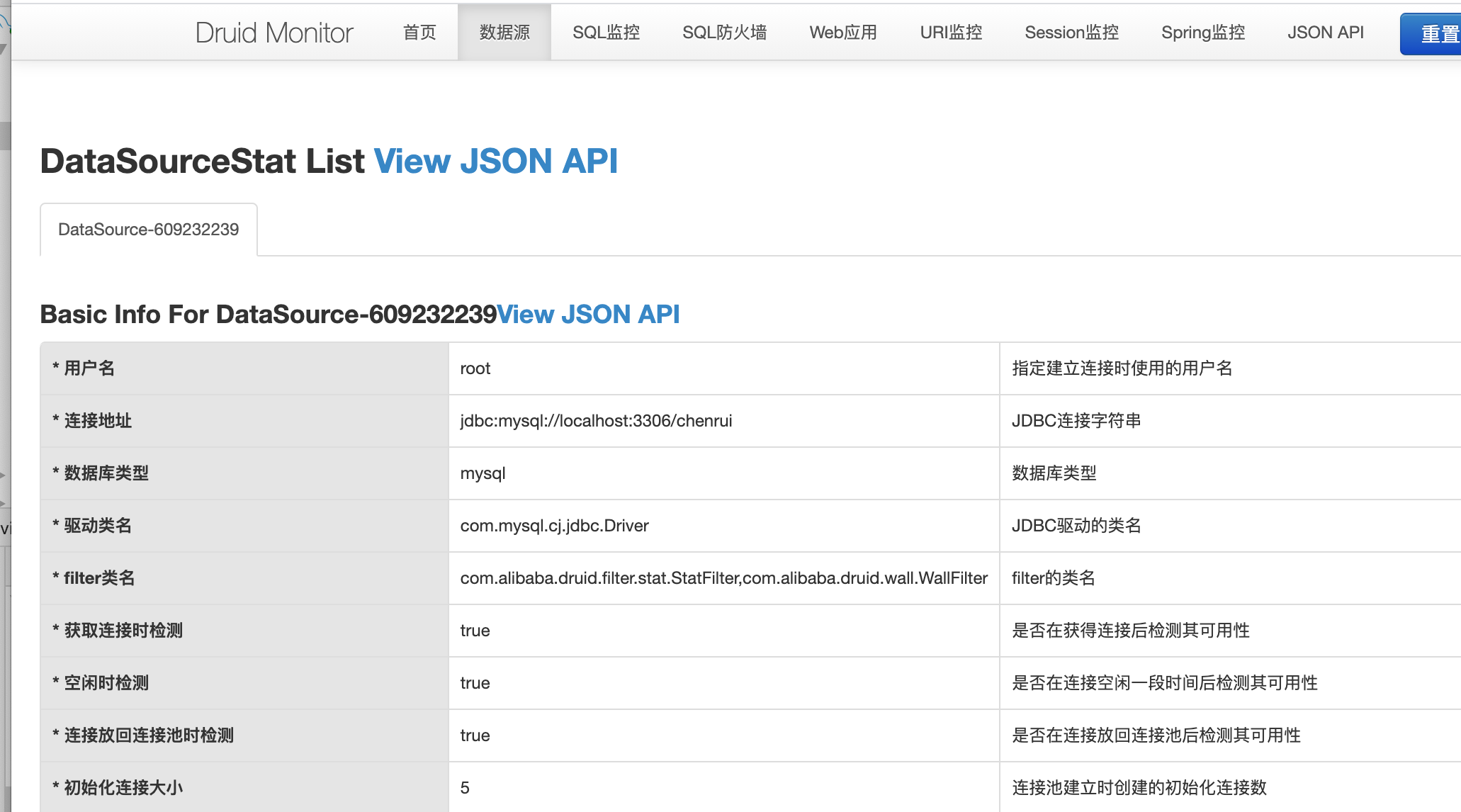
上面我們看到數據源裡面的資訊和我們在application.properties中配置的一致
下面我們分別執行幾次,我們準備好的驗證介面
//127.0.0.1:8080/all
//127.0.0.1:8080/getUser/1
//127.0.0.1:8080/getUser/2
//127.0.0.1:8080/getUser/one
//127.0.0.1:8080/getUser/two
然後看一下的各項監控資訊長什麼樣子
SQL監控
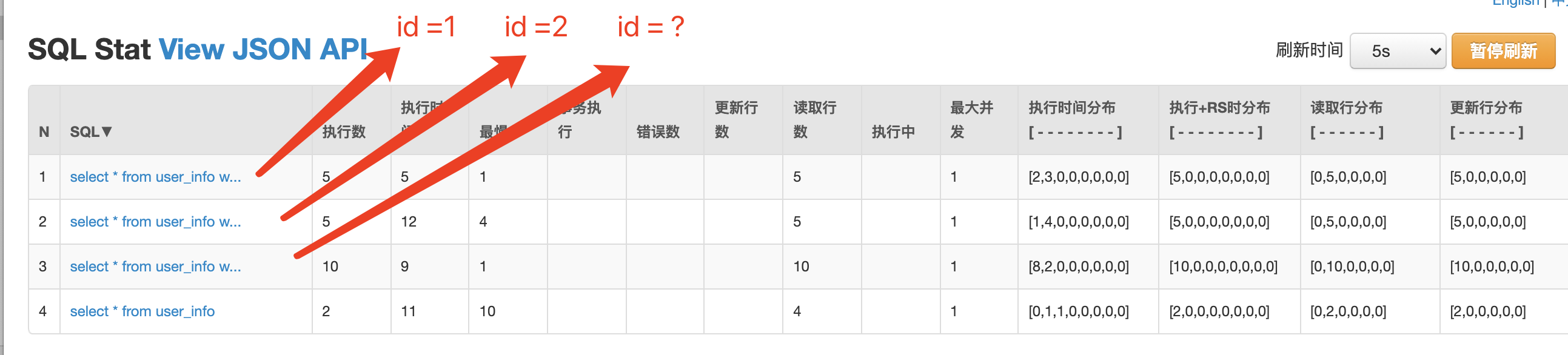
上面我們看到我們總共四個語句,以及四個語句的運行情況
SQL監控項上,執行時間、讀取行數、更新行數都有區間分布,將耗時分布成8個區間:
- 0 – 1 耗時0到1毫秒的次數
- 1 – 10 耗時1到10毫秒的次數
- 10 – 100 耗時10到100毫秒的次數
- 100 – 1,000 耗時100到1000毫秒的次數
- 1,000 – 10,000 耗時1到10秒的次數
- 10,000 – 100,000 耗時10到100秒的次數
- 100,000 – 1,000,000 耗時100到1000秒的次數
- 1,000,000 – 耗時1000秒以上的次數
這裡你可能會有疑問 ,id =1和id=2怎麼還是分開的,如果我id有一億個,難道要在監控頁面上有一億條記錄嗎?不是應該都應該是id=?的形式嗎?這裡後面會講到,涉及到sql合併的監控配置
URL監控
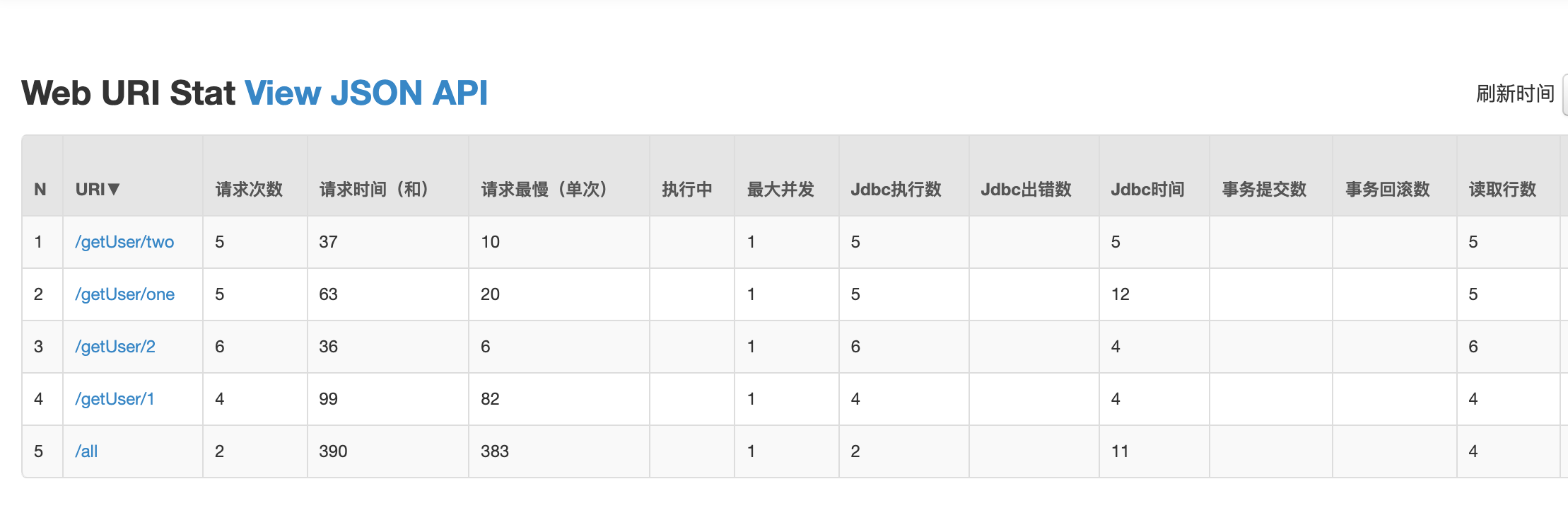
這裡可以很清晰的看到,每個url涉及到的資料庫執行的資訊
druid的內置filters
在druid的jar中,META-INF/druid-filter.properties中有其內置的filter,內容如下:
druid.filters.default=com.alibaba.druid.filter.stat.StatFilter
druid.filters.stat=com.alibaba.druid.filter.stat.StatFilter
druid.filters.mergeStat=com.alibaba.druid.filter.stat.MergeStatFilter
druid.filters.counter=com.alibaba.druid.filter.stat.StatFilter
druid.filters.encoding=com.alibaba.druid.filter.encoding.EncodingConvertFilter
druid.filters.log4j=com.alibaba.druid.filter.logging.Log4jFilter
druid.filters.log4j2=com.alibaba.druid.filter.logging.Log4j2Filter
druid.filters.slf4j=com.alibaba.druid.filter.logging.Slf4jLogFilter
druid.filters.commonlogging=com.alibaba.druid.filter.logging.CommonsLogFilter
druid.filters.commonLogging=com.alibaba.druid.filter.logging.CommonsLogFilter
druid.filters.wall=com.alibaba.druid.wall.WallFilter
druid.filters.config=com.alibaba.druid.filter.config.ConfigFilter
druid.filters.haRandomValidator=com.alibaba.druid.pool.ha.selector.RandomDataSourceValidateFilter
default、stat、wall等是filter的別名,可以在application.properties中可以通過spring.datasource.druid.filters屬性指定別名來開啟相應的filter,也可以在Spring中通過屬性注入方式來開啟,接下來介紹一下比較常用的filter
攔截器stat(default、counter)
在spring.datasource.druid.filters配置中包含stat,代表開啟監控統計資訊,在上面內容中,我們已經看到包含執行次數、時間、最慢SQL等資訊。也提到因為有的sql是非參數話的,這樣會導致在監控頁面有很多監控的sql都是一樣的,只是參數不一樣,我們這時候需要將合約sql配置打開;
只需要在application.properties增加配置:
#為監控開啟SQL合併,將慢SQL的時間定為2毫秒,記錄慢SQL日誌
spring.datasource.druid.connection-properties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=2;druid.stat.logSlowSql=true
看一下運行結果:
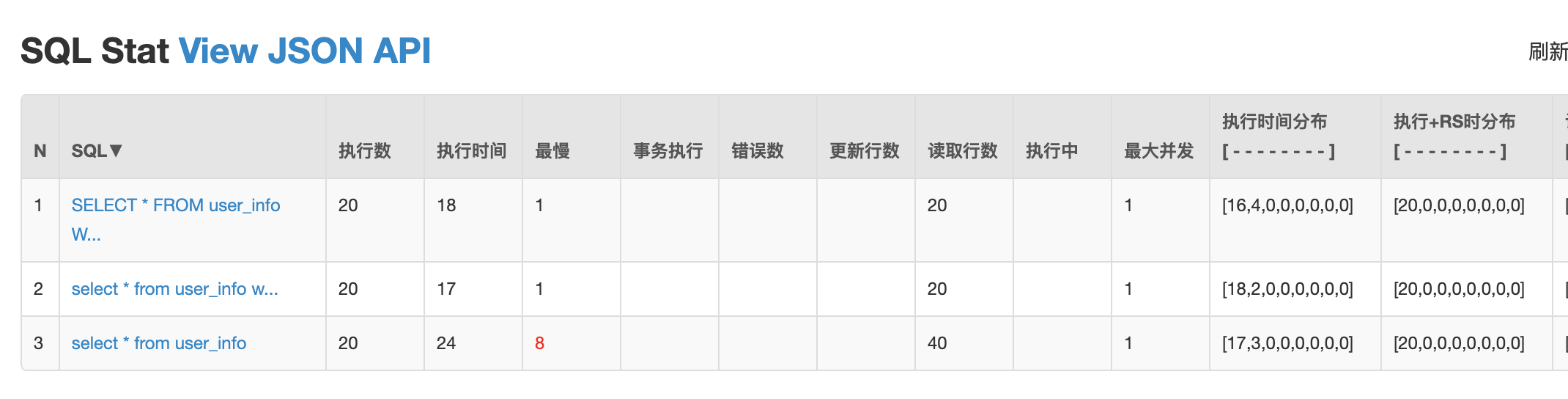
1、下面2個語句在監控頁面被合併了:
select * from user_info where id=1
select * from user_info where id=2
// 合併後的結果是:
SELECT * FROM user_info WHERE id = ?
2、超過2ms的語句,在監控頁面紅色展示出來
3、慢SQL在日誌中會被體現出來

攔截器mergeStat
繼承stat,基本特性和stat是一樣的,不做延伸
攔截器encoding
由於歷史原因,一些資料庫保存數據的時候使用了錯誤編碼,需要做編碼轉換。
可以用下面的方式開啟:
spring.datasource.druid.filters=stat,encoding
#配置客戶端的編碼UTF-8,服務端的編碼是ISO-8859-1,這樣存在資料庫中的亂碼查詢出來就不是亂碼了。
spring.datasource.druid.connection-properties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=2;druid.stat.logSlowSql=true;clientEncoding=UTF-8;serverEncoding=ISO-8859-1
攔截器 log4j(log4j2、slf4j、commonlogging、commonLogging)
Druid內置提供了四種LogFilter(Log4jFilter、Log4j2Filter、CommonsLogFilter、Slf4jLogFilter),用於輸出JDBC執行的日誌
#這裡使用log4j2為例
spring.datasource.druid.filters=stat,log4j2
#druid.log.conn記錄連接、druid.log.stmt記錄語句、druid.log.rs記錄結果集、druid.log.stmt.executableSql記錄可執行的SQL
spring.datasource.druid.connection-properties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=2;druid.stat.logSlowSql=true;druid.log.conn=true;druid.log.stmt=true;druid.log.rs=true;druid.log.stmt.executableSql=true
#為方便驗證,我們開啟以下loggerName為DEBUG
logging.level.druid.sql.Statement=DEBUG
logging.level.druid.sql.ResultSet=DEBUG
logging.level.druid.sql.Connection=DEBUG
logging.level.druid.sql.DataSource=DEBUG
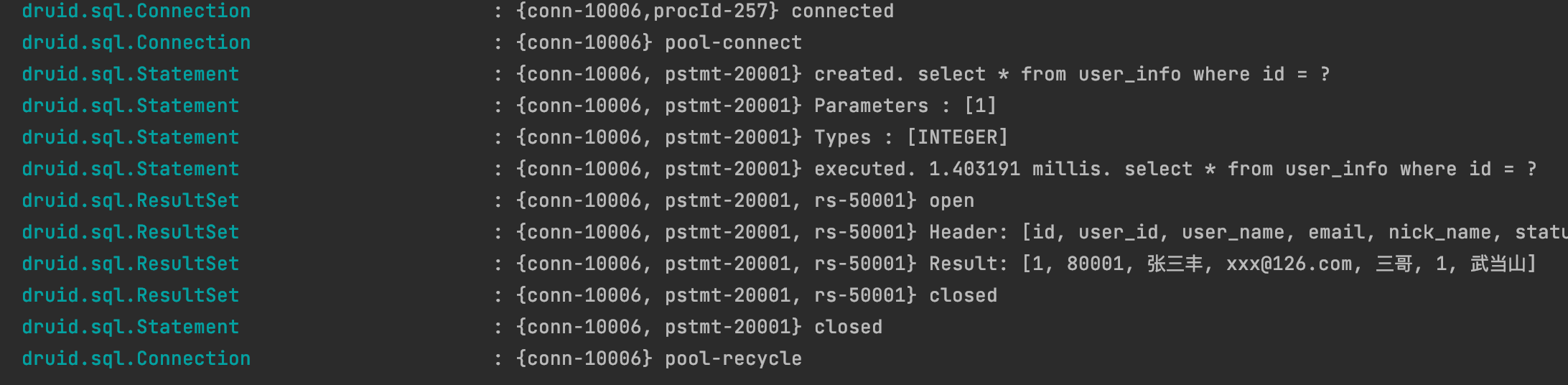
我們可以看到執行SQL的整個過程,開啟連接>從連接池獲取一個連接>組裝SQL語句>執行>結果集返回>連接池回收連接
這裡只用了log4j2這一種類型,其他可以自行去驗證。
攔截器wall
WallFilter的功能是防禦SQL注入攻擊。它是基於SQL語法分析,理解其中的SQL語義,然後做處理的,智慧,準確,誤報率低。減少風險的發生,wall攔截器還是很重要的。比如說不允許使用truncate,不允許物理刪除,這時候wall就用得上了。配置方式有兩種:
第一種:預設配置
spring.datasource.druid.filters=stat,wall,log4j2
這種配置是默認配置,而且大多數都不會攔截,可能不符合特定的場景,默認屬性值參照://www.bookstack.cn/read/Druid/ffdd9118e6208531.md
第二種:屬性指定配置
這種方式的好處是:我們可以針對特定場景進行限定,比如說不能用存儲過程,不能物理刪除,是否允許語句中有注釋等等。
//在DruidDataSource生成前注入WallFilter
@ConfigurationProperties(prefix = "spring.datasource.druid")
@Bean
public DataSource dataSource(){
DruidDataSource dataSource = new DruidDataSource();
dataSource.getProxyFilters().add(wallFilter());
return dataSource;
}
@Bean
@ConfigurationProperties("spring.datasource.druid.filter.wall.config")
public WallConfig wallConfig(){
return new WallConfig();
}
@Bean
public WallFilter wallFilter(){
WallFilter filter = new WallFilter();
filter.setConfig(wallConfig());
filter.setDbType("mysql");
return filter;
}
#不允許物理刪除語句
spring.datasource.druid.filter.wall.config.delete-allow=false
執行一下試試效果:

可以看到日誌顯示,不允許刪除,這樣可以避免一些同學不按照公司開發規範來開發程式碼,減少風險。其他配置自己可以試驗一下。
攔截器Config
Config作用:從配置文件中讀取配置;從遠程http文件中讀取配置;為資料庫密碼提供加密功能
實際上前兩項作用意義不大,最關鍵的是第三項作用,因為資料庫密碼直接寫在配置中,對運維安全來說,是一個很大的挑戰。Druid為此提供一種資料庫密碼加密的手段ConfigFilter
如何使用:
#在application.properties的鏈接屬性配置項中增加config.file,可以是本地文件,也可以是遠程文件,比如config.file=//127.0.0.1/druid-pool.properties
spring.datasource.druid.connection-properties=config.file=file:///Users/chenrui/druid-pool.properties
加密我們的資料庫密碼
使用下面的命令生成資料庫密碼的密文和秘鑰對
java -cp druid-1.0.16.jar com.alibaba.druid.filter.config.ConfigTools you_password

druid-pool.properties文件內容

資料庫密碼配置項的值改為密文
spring.datasource.druid.password=kPYuT1e6i6M929mNvKfvhyBx3eCI+Fs0pqA3n7GQYIoo76OaWVg3KALr7EdloivFVBSeF0zo5IGIfpbGtAKa+Q==
自己啟動一下試試,發現一切正常,資訊安全問題也解決了。
Druid和HikariCP如何選擇
網路上有這麼一個圖,可以看到Druid是和其聲明的一致(為監控而生),但是目前市面上有很多監控相關的中間件和技術,HikariCP可以通過這些技術彌補監控方面的不足
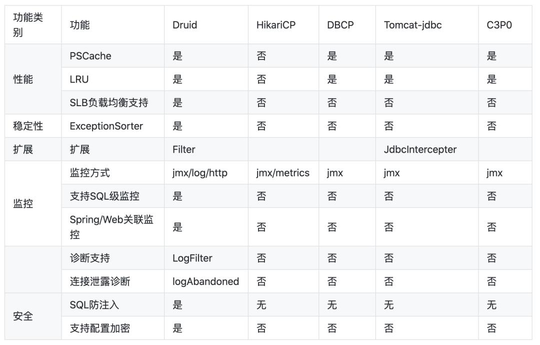
HikariCP則說自己是性能最好的連接池,但是Druid也經受住了阿里雙11的大考,實際上性能也是很好的
選擇哪一款就見仁見智了,不過兩款都是開源產品,阿里的Druid有中文的開源社區,交流起來更加方便,並且經過阿里多個系統的實驗,想必也是非常的穩定,而Hikari是SpringBoot2.0默認的連接池,全世界使用範圍也非常廣,對於大部分業務來說,使用哪一款都是差不多的,畢竟性能瓶頸一般都不在連接池。大家可根據自己的喜好自由選擇


