Web安全-資訊收集
資訊收集
前言:在滲透測試過程中,資訊收集是非常重要的一個環節,此環節的資訊將影響到後續成功幾率,掌握資訊的多少將決定發現漏洞的機會的大小,換言之決定著是否能完成目標的測試任務。也就是說:滲透測試的思路就是從資訊收集開始,你與大牛的差距也是這裡開始的。
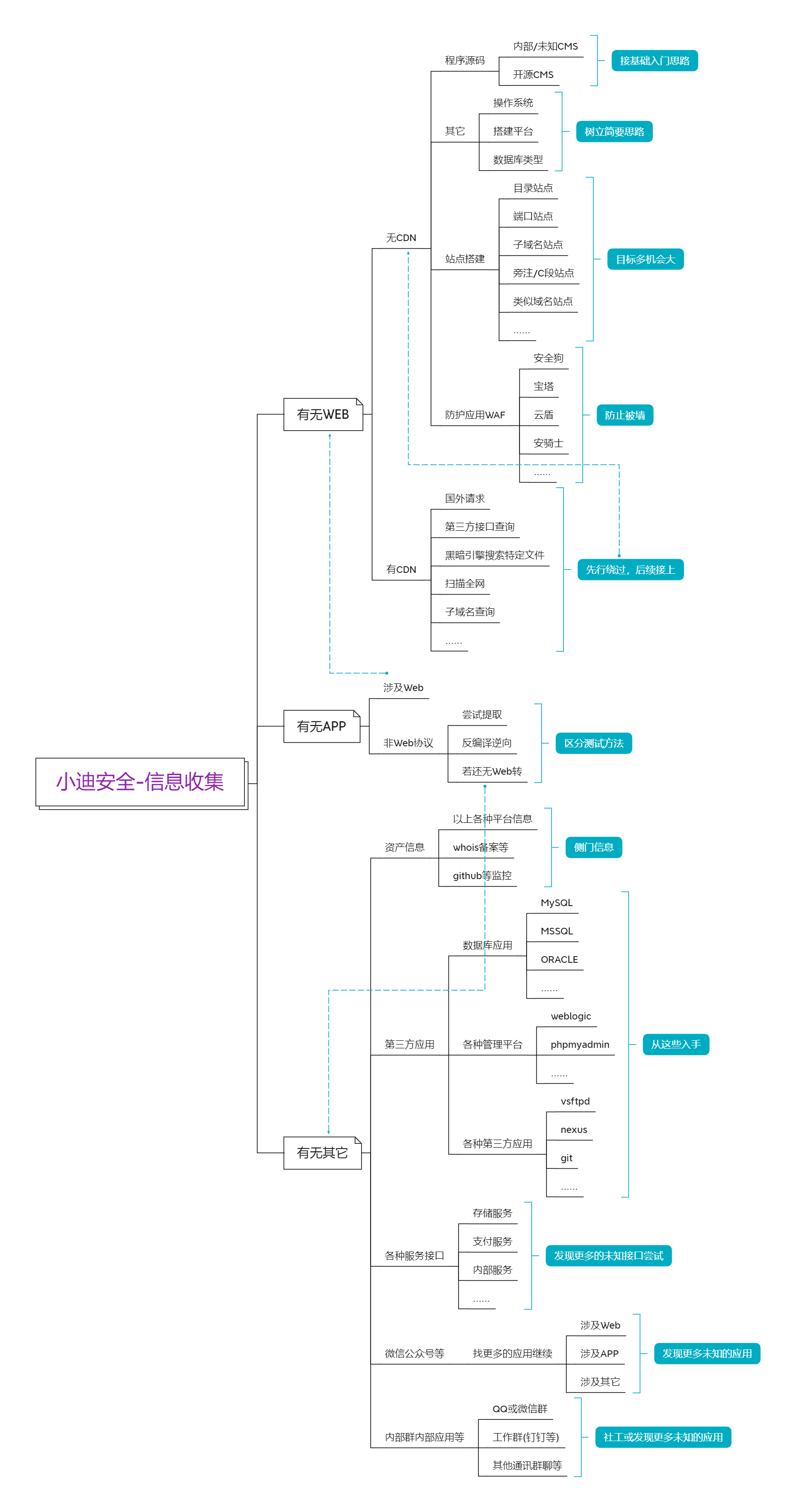
Part1:資訊收集-架構、搭建、WAF等
# CMS識別技術
網上有現成的CMS識別平台
# 源碼獲取技術
# 架構資訊獲取
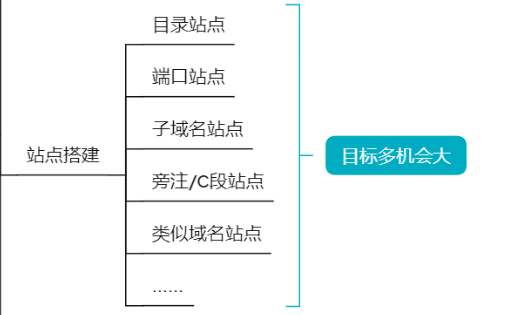
# 站點搭建分析
搭建習慣-目錄型站點
搭建習慣-埠類站點
搭建習慣-子域名站點
搭建習慣-類似域名站點
搭建習慣-旁註[同伺服器不同站點,又稱同IP站點查詢],C段站點[C段查詢]
搭建習慣-搭建軟體特徵站點
# WAF 防護分析
什麼是WAF應用?
如何快速識別WAF?
識別WAF對於安全測試的意義
案例演示:
▲sti.blcu-bbs-目錄型站點分析
sti.blcu.edu.cn/ 和 sti.blcu.edu.cn/bbs 這兩個站點的區別僅僅在於一個目錄,任意一個出現問題就都得遭殃
▲web.0516jz-8080-埠類站點分析
不同的埠對應不同的站點,但是歸根到底他們兩個還是在同一台伺服器上,任意一個站點出現安全問題都會導致伺服器出現安全問題。
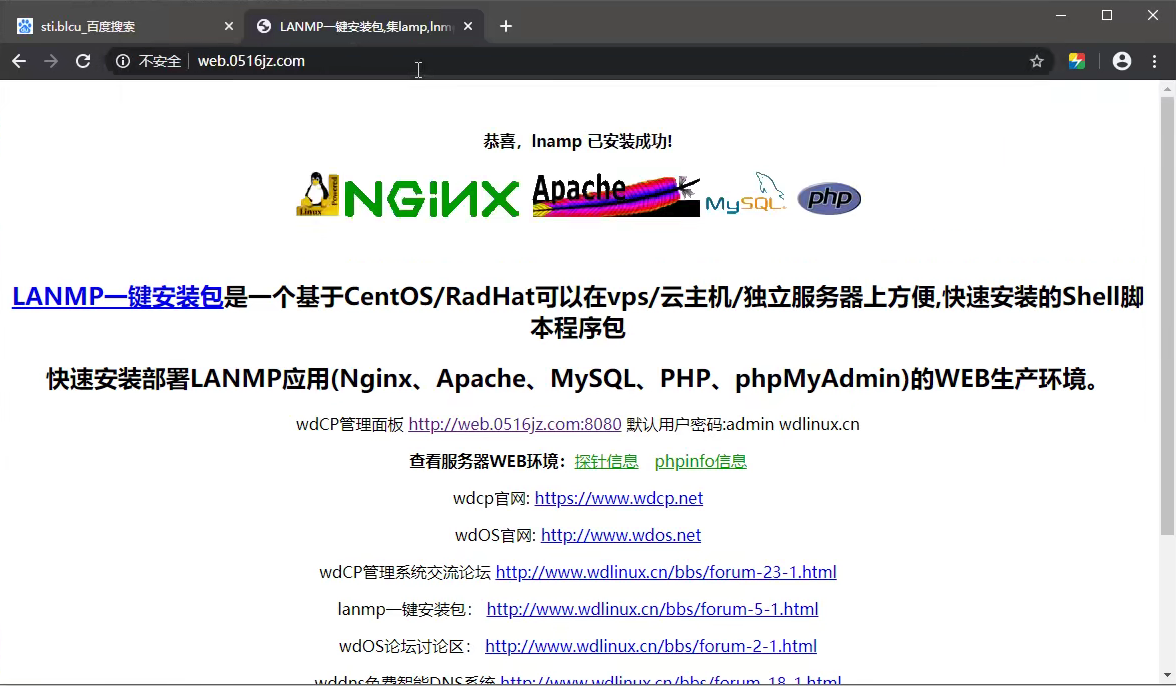
▲goodlift-www.bbs-子域名兩套 CMS
主站 www.goodlift.net 和子域名 bbs.goodlift.net 是用不同的CMS搭建的,這個時候就存在了一個問題,這兩個網站就有可能不在同一台伺服器上面。
▲jmlsd-cn.com.net等-各種常用域名後綴
▲weipan-qqyewu-查詢靶場同伺服器站點[同IP站點查詢]
▲weipan-phpstudy-查詢特定軟體中間件等
我們用phpstudy搭建的在F12這裡查看到的Server資訊是一樣的,我們就可以去佛法搜索Server資訊,然後查到的就都是用phpstudy搭建的。【其它中間件也類似】
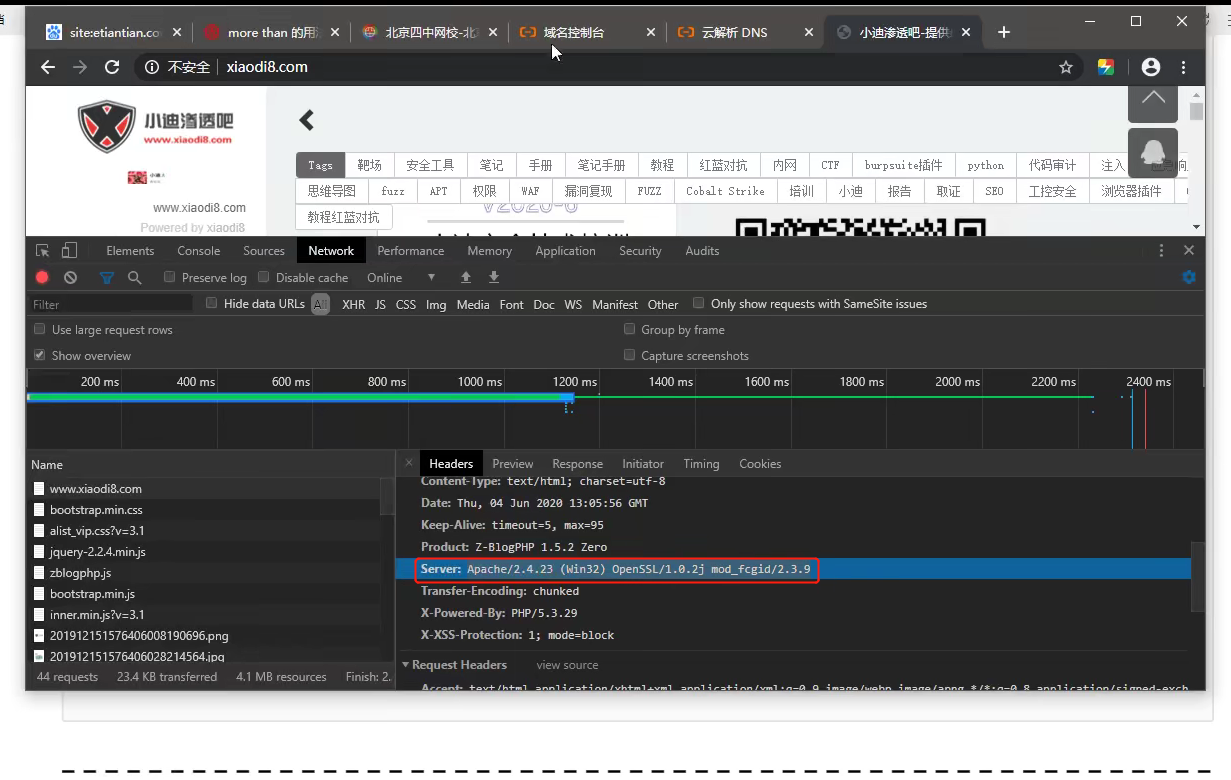
wafw00f-shodan(X-Powered-By: WAF)-147.92.47.120
識別WAF方法:
①按F12查詢到數據包中出現 X-Powered-By: WAF 的,基本上就是有WAF
②用工具wafw00f
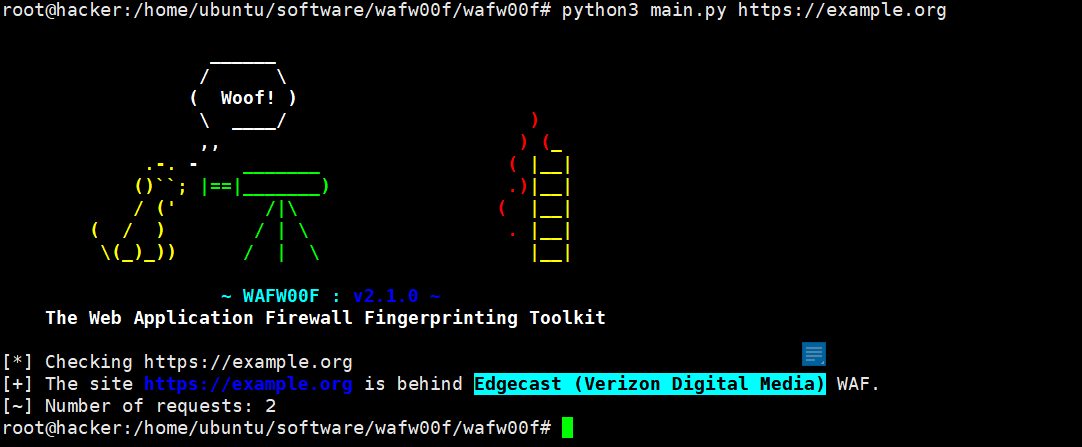
使用教程://www.cnblogs.com/qingchengzi/articles/13451885.html
涉及資源:
//github.com/EnableSecurity/wafw00f
Part2:資訊收集-APP及其他資產
前言:在安全測試中,若 Web無法取得進展,或者無WAF的情況下,我們需要藉助APP或者其他資產再進行資訊收集,從而開始後續滲透,那麼其中的資訊收集就尤為重要,接下來我們就用案例講解試試吧。
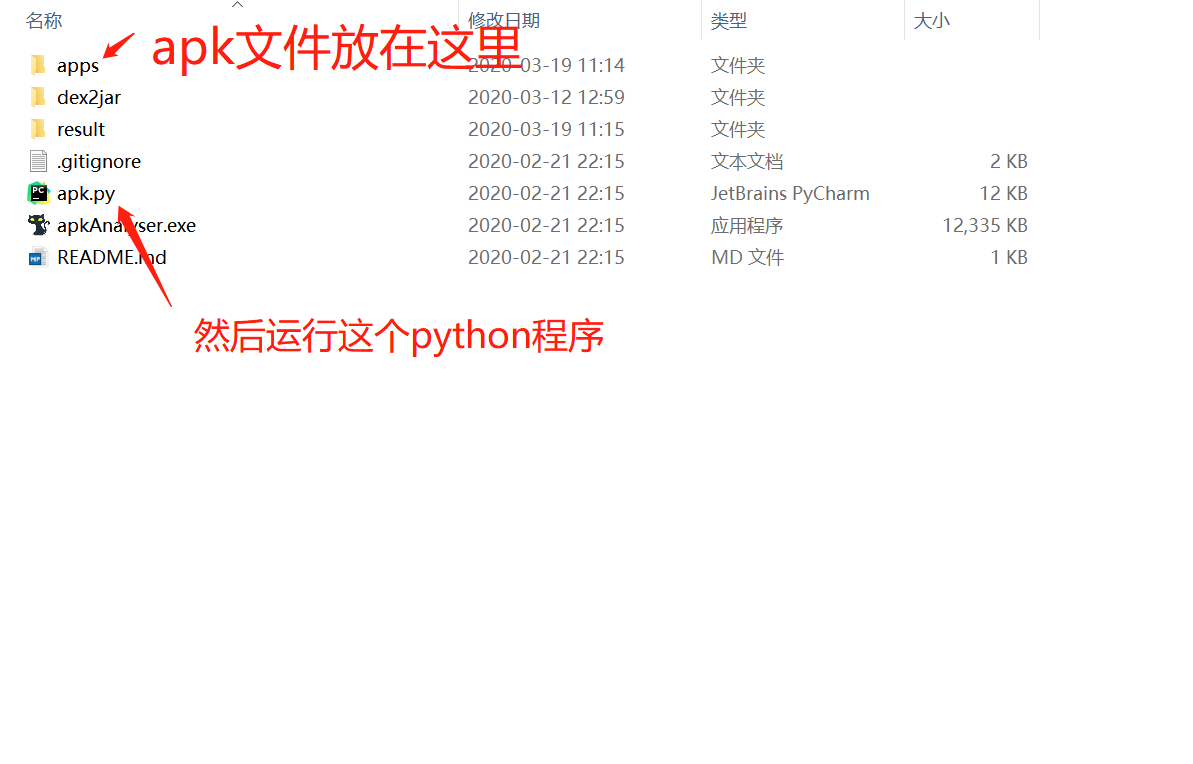
# APP 提取一鍵反編譯提取【工具:漏了個大洞】
# APP 抓數據包進行工具配合【模擬器+Burp】
# 各種第三方應用相關探針技術
# 各種服務介面資訊相關探針技術
案例演示:
APP 提取及抓包及後續配合
某APK一鍵提取反編譯
利用Burp歷史抓更多URL
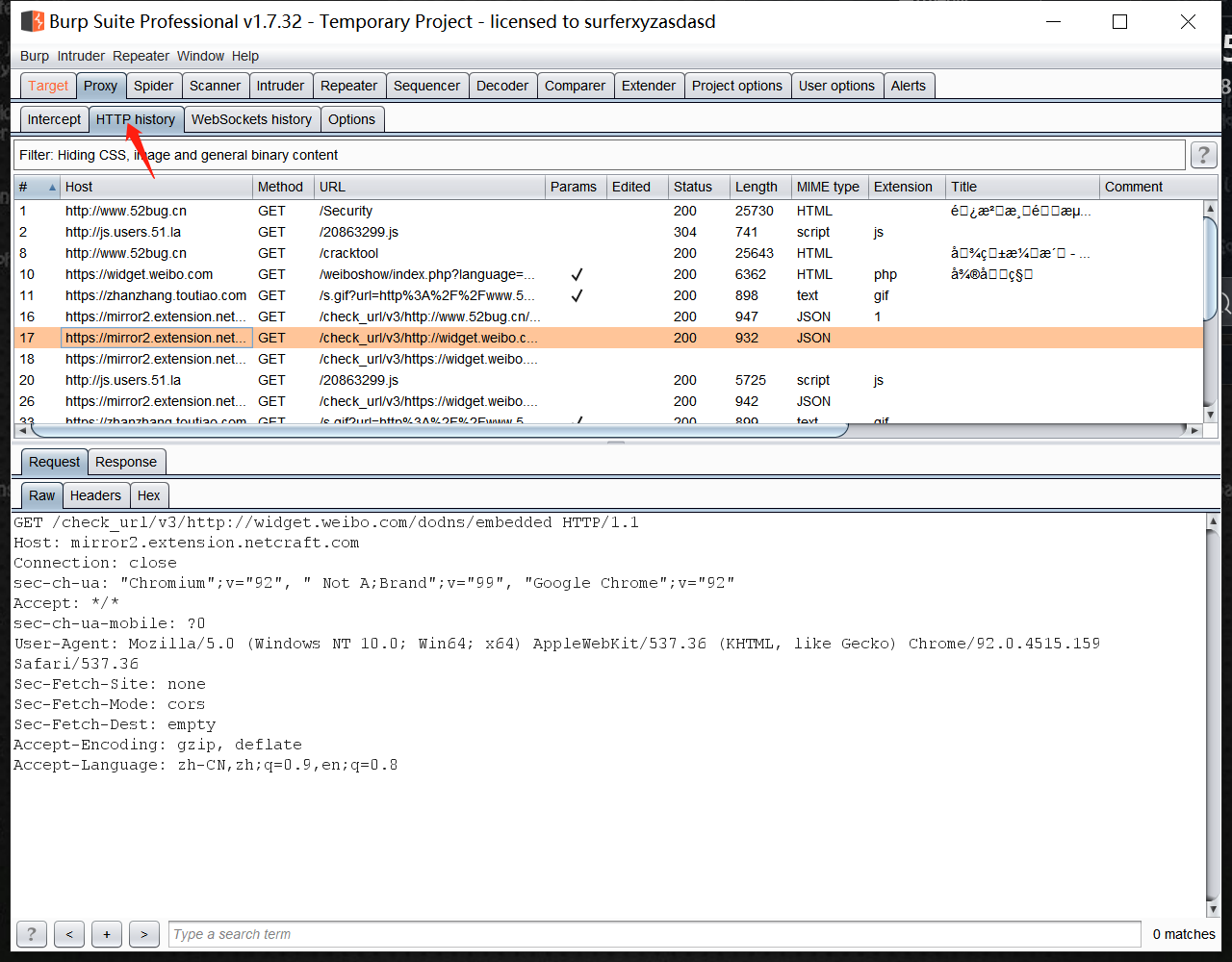
實際案例Web服務測試【//www.caredaily.com/】

從網站表面看存在漏洞的可能性比較小,因為這個網站上面的功能都比較簡單
那麼我們接下來就從這5個方面開始進行資訊收集
我們直接去fofa、shodan、zoomeye進行域名搜索
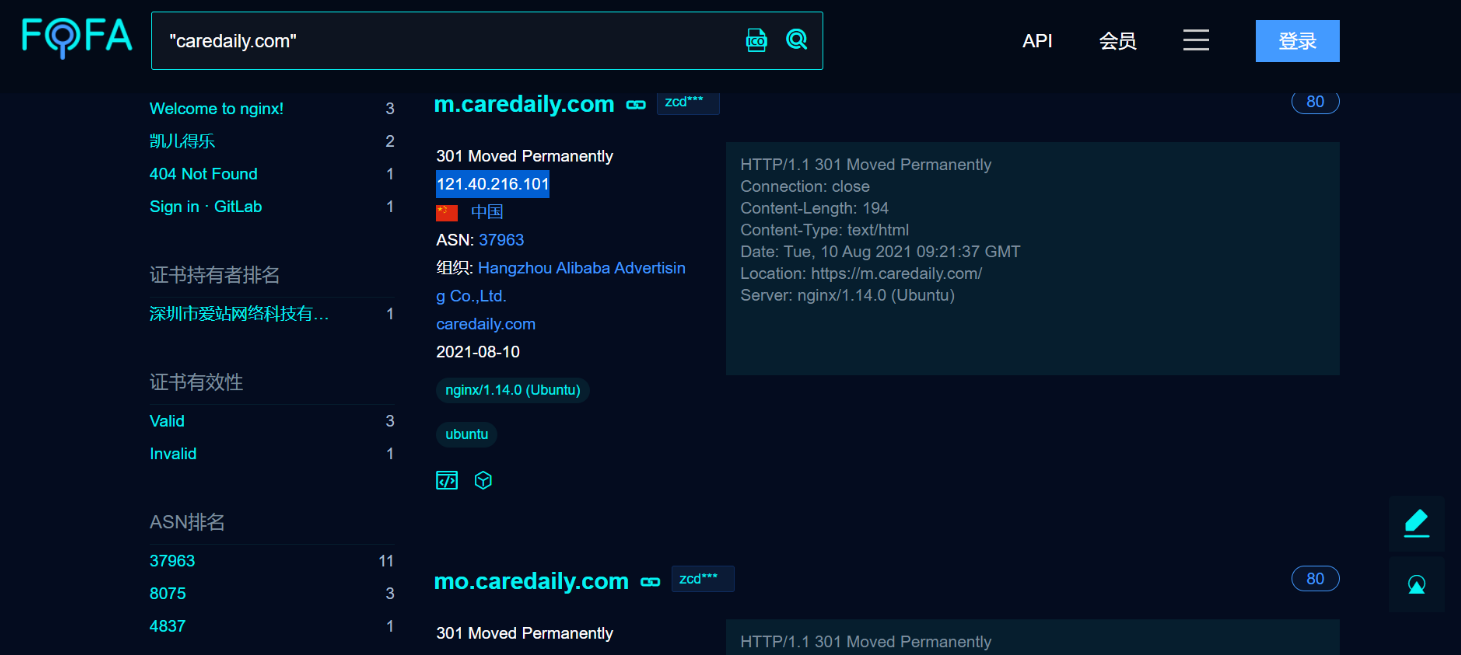
我們注意到這裡8000埠出現了OpenSSH服務,我們就可以去搜對應版本存在的漏洞,去驗證

我們又注意到他這27017開了MongoDB,那麼就可能存在MongoDB資料庫相關的漏洞,我們也可以去進行嘗試

這個地方又可以成為一個攻擊點。其他埠也類似,埠代表著服務,有服務就代表可能存在相應的服務的漏洞,我們就可以先記錄下來,然後最後統一對各個點進行攻擊。
我們還可以搜索它的目錄站點、子域名站點、旁註/C段站點進一步擴大我們的攻擊面【利用工具:7kbScan御劍掃描、Layer子域名挖掘機、同IP站點查詢】
最後講一下類似域名怎麼找?
我們可以用介面查,第①步就是查找備案資訊【需要VIP】
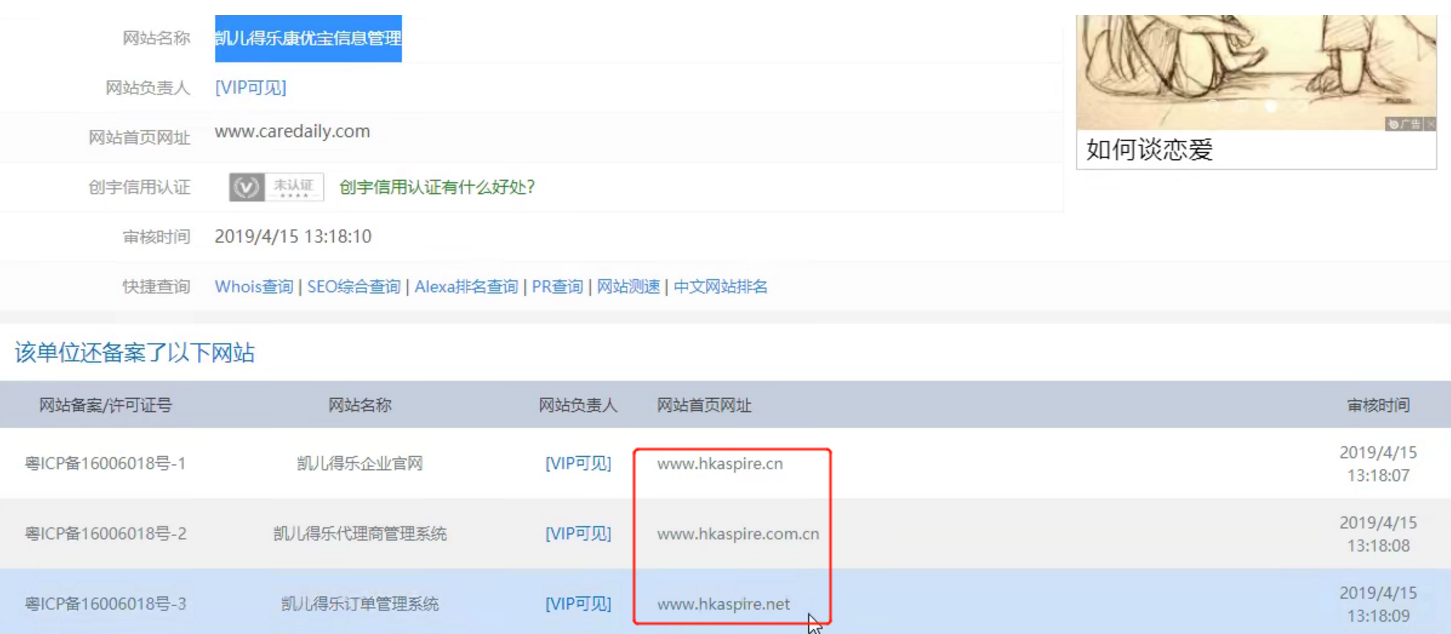
通過對備案公司的查詢,我們可以查到該公司還註冊了幾個別的域名:
//hkaspire.net/ 和 //hkaspire.cn/
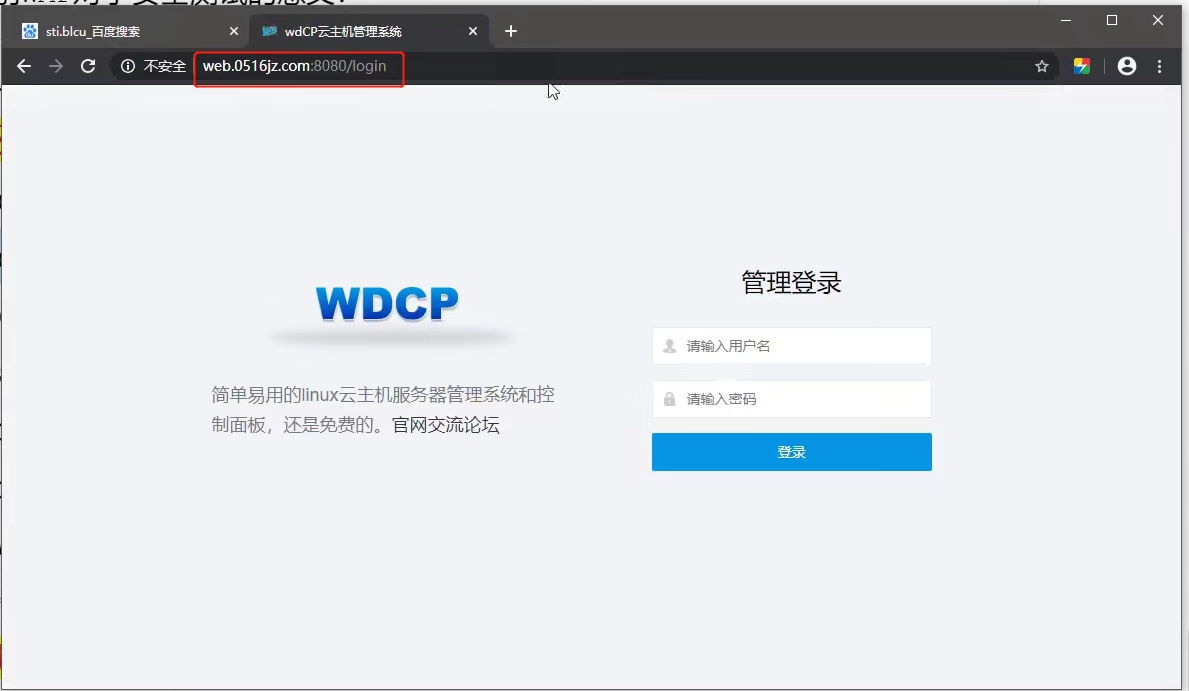
在 //hkaspire.net/ 這個網站我們發現這裡可以點擊,點擊之後跳轉到一個新的頁面 //hkaspire.net:8080/login
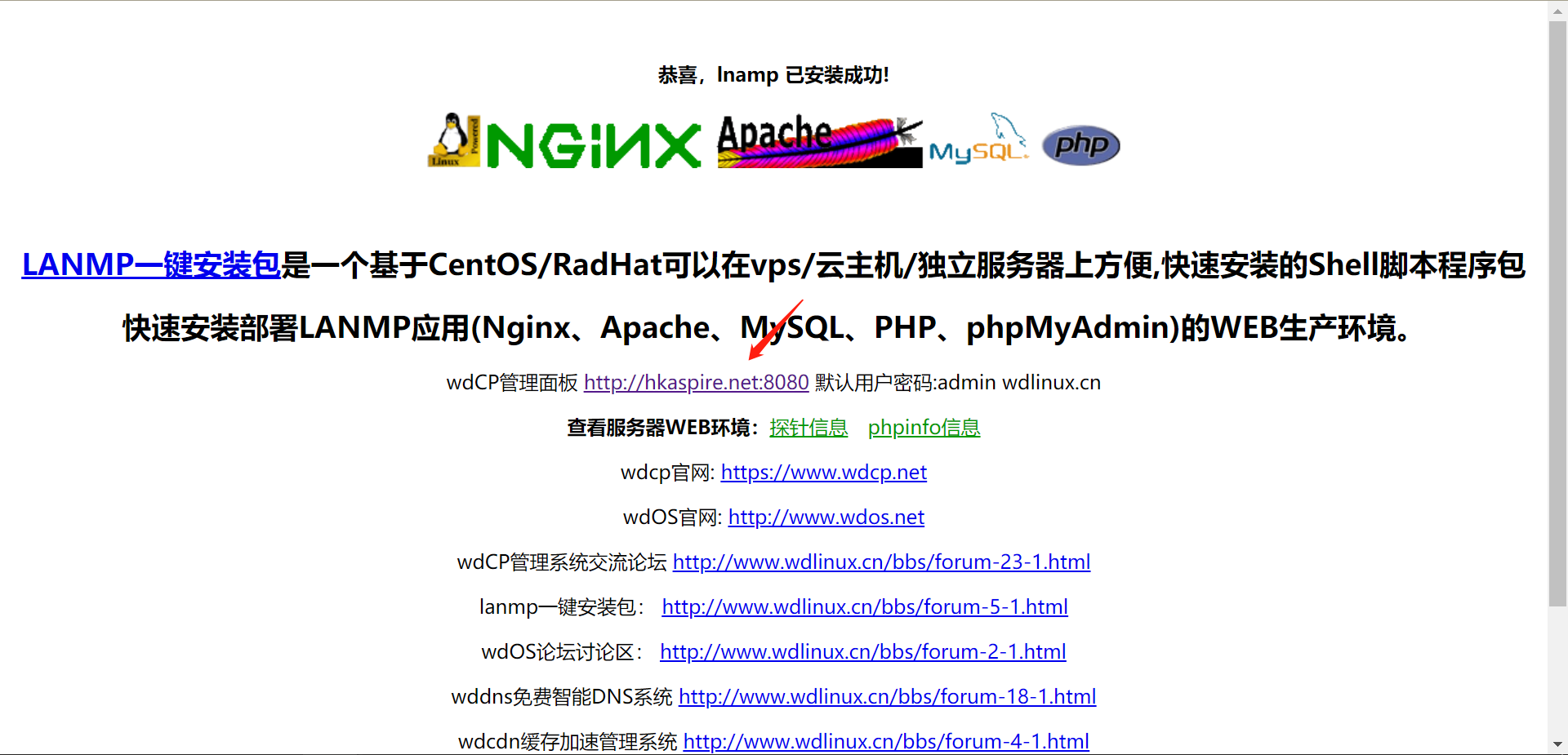
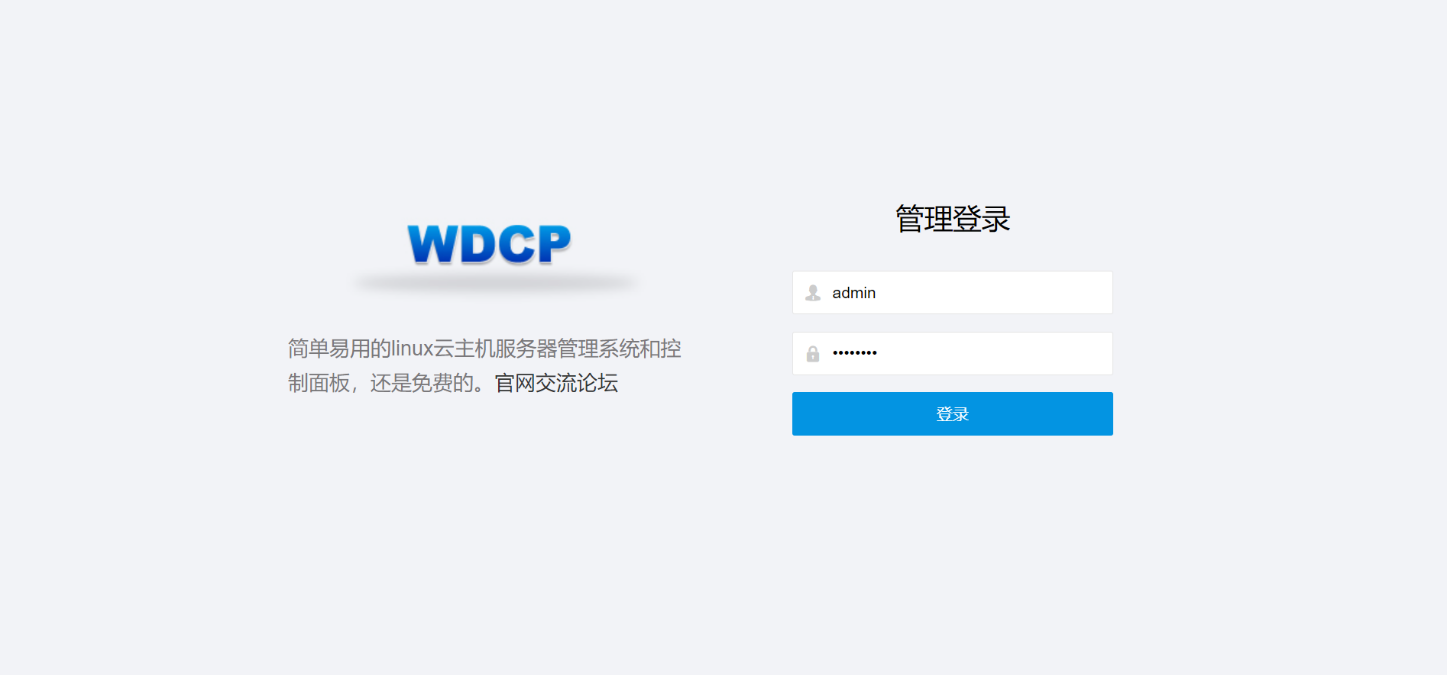
這其實也是可以成為一個攻擊面的
他這裡其實還暴露了很多,類似於探針資訊,phpinfo資訊
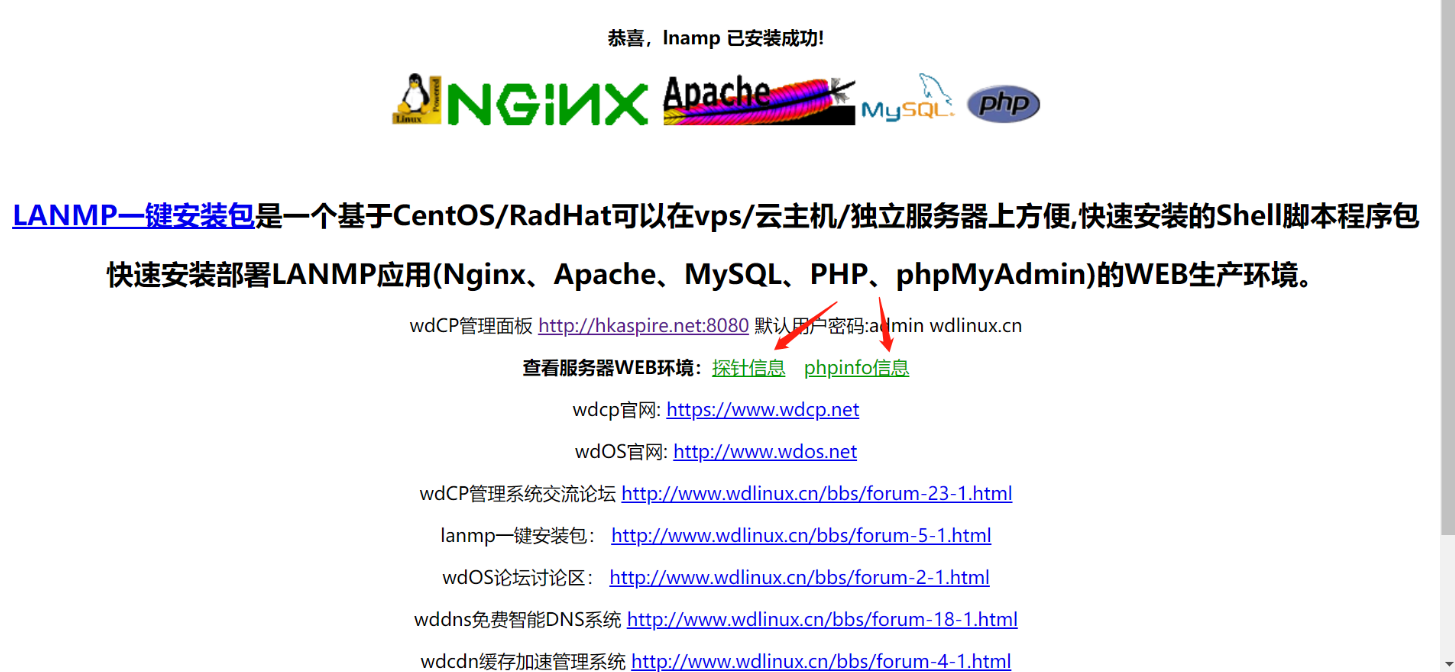
針對這個WDCP登陸系統,我們也可以直接在網上搜漏洞,進行漏洞測試
針對這個 //hkaspire.cn/ 網站,這也是個系統,我們也可以進行漏洞測試
與此同時,這個域名//hkaspire.cn/也涉及到新的IP地址,我們也可以針對這個IP地址進行測試【進行fofa的搜索】
同樣進行這5步的測試
所以能做的事情是很多的
這樣還沒完,我們可以拿這種網站的標題去百度|Google搜索
像是域名差不多的都可以進行測試
我們還可以去搜索域名的關鍵字【盡量用Google去搜索】
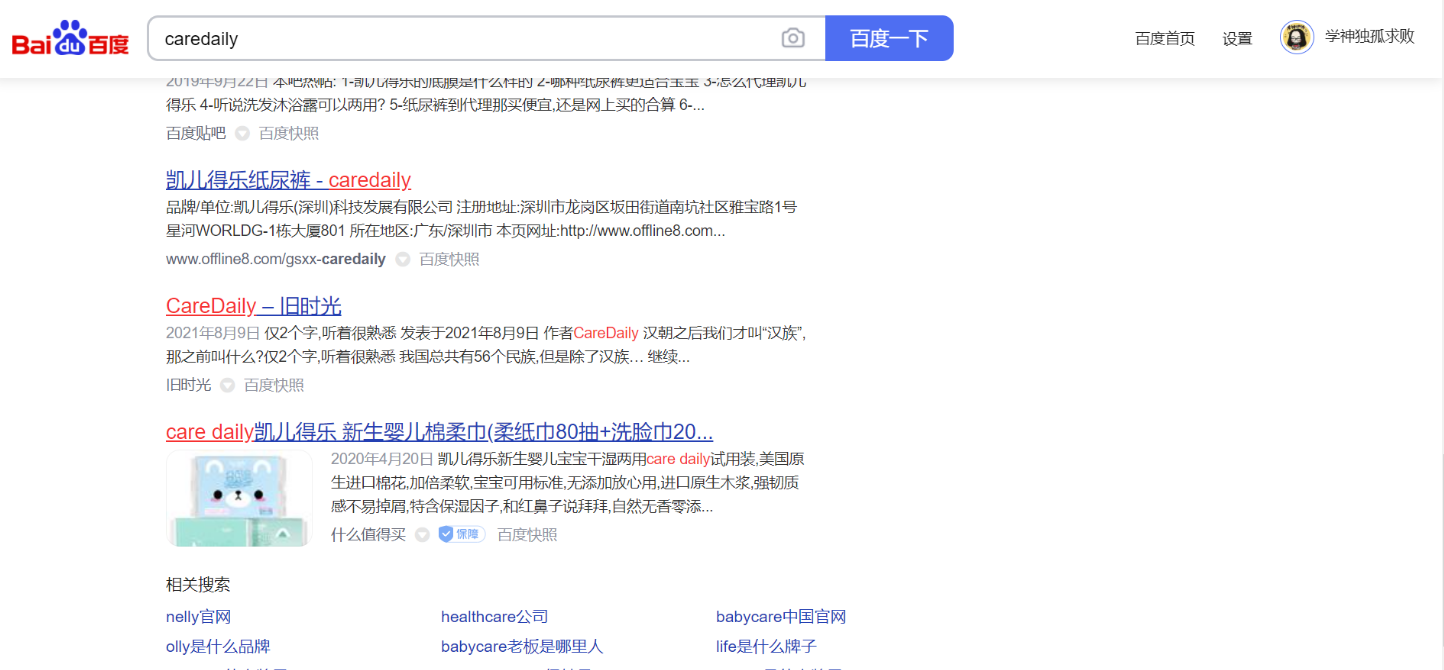
這個是我們通過Google搜到的 //caredaily.xyz/
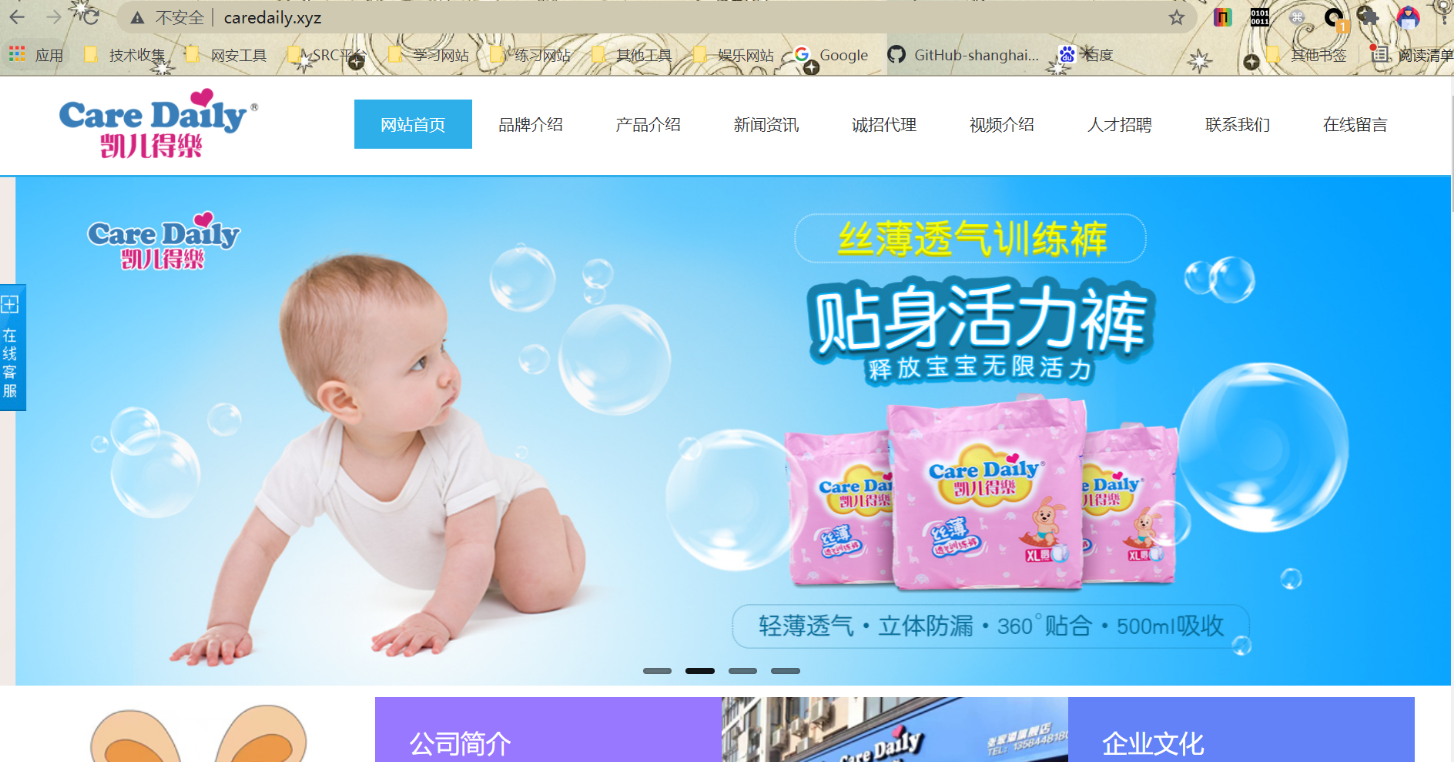
我們查看其robots.txt可以查到其一些路徑
我們進這個Install看看
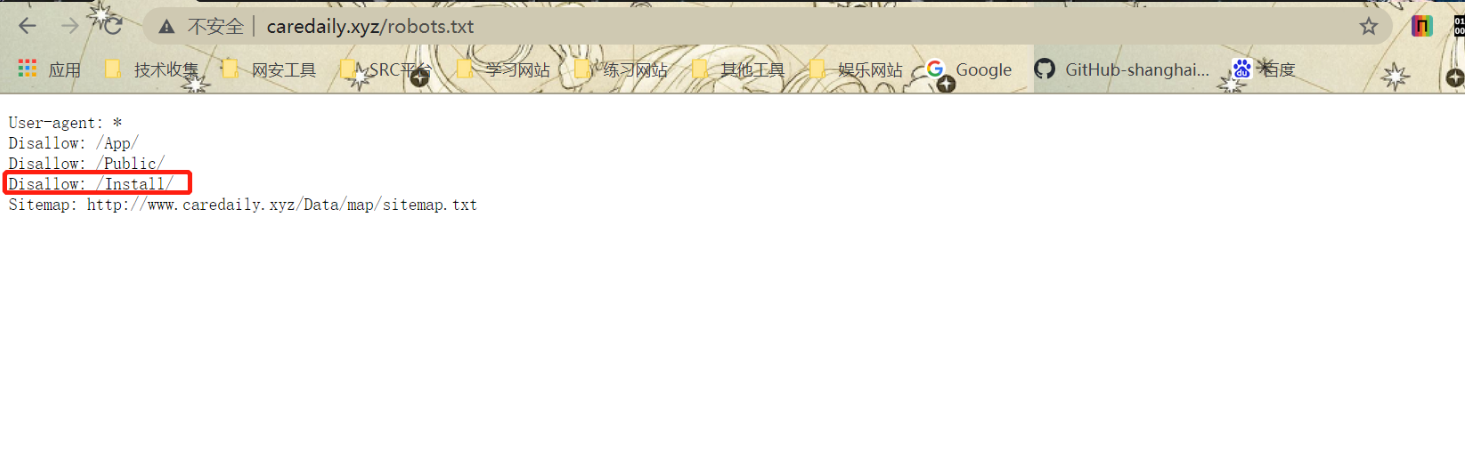
然後我們發現它使用youdiancms搭建的
然後我們就又可以去百度搜索youdiancms漏洞
這搜到的資訊已經足夠多了,而且我們每個得到的域名對應的每個IP,每個埠都要掃,我們會拿到相當多資訊,足夠我們進行滲透測試
涉及資源
Part3:資訊收集-資產監控拓展
# Github監控
便於收集整理最新的EXP和POC
便於發現相關測試目標的資產
# 各種子域名查詢
# 全球節點請求CDN
枚舉爆破或解析子域名對應
便於發現管理員相關的註冊資訊
# 黑暗引擎相關搜索
fofa,shodan,zoomeye
# 微信公眾號介面獲取
# 內部群|內部應用|內部介面
▲各種子域名查詢方法

▲監控最新的 EXP 發布及其他
# Title: wechat push CVE-2020
# Date: 2020-5-9
# Exploit Author: weixiao9188
# Version: 4.0
# Tested on: Linux,windows
# coding:UTF-8
import requests
import json
import time
import os
import pandas as pd
time_sleep = 20 #每隔20秒爬取一次
while(True):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"}
#判斷文件是否存在
datas = []
response1=None
response2=None
if os.path.exists("olddata.csv"):
#如果文件存在則每次爬取10個
df = pd.read_csv("olddata.csv", header=None)
datas = df.where(df.notnull(),None).values.tolist()#將提取出來的數據中的nan轉化為None
response1 = requests.get(url="//api.github.com/search/repositories?q=CVE-2020&sort=updated&per_page=10",
headers=headers)
response2 = requests.get(url="//api.github.com/search/repositories?q=RCE&ssort=updated&per_page=10",
headers=headers)
else:
#不存在爬取全部
datas = []
response1 = requests.get(url="//api.github.com/search/repositories?q=CVE-2020&sort=updated&order=desc",headers=headers)
response2 = requests.get(url="//api.github.com/search/repositories?q=RCE&ssort=updated&order=desc",headers=headers)
data1 = json.loads(response1.text)
data2 = json.loads(response2.text)
for j in [data1["items"],data2["items"]]:
for i in j:
s = {"name":i['name'],"html":i['html_url'],"description":i['description']}
s1 =[i['name'],i['html_url'],i['description']]
if s1 not in datas:
#print(s1)
#print(datas)
params = {
"text":s["name"],
"desp":" 鏈接:"+str(s["html"])+"\n簡介"+str(s["description"])
}
print("當前推送為"+str(s)+"\n")
print(params)
requests.get("//sc.ftqq.com/XXXX.send",params=params,timeout=10)
#time.sleep(1)#以防推送太猛
print("推送完成!")
datas.append(s1)
else:
pass
#print("數據已處在!")
pd.DataFrame(datas).to_csv("olddata.csv",header=None,index=None)
time.sleep(time_sleep)
▲ 黑暗引擎實現域名埠等收集
▲ 全自動域名收集枚舉優秀腳本使用
工具:teemo和Layer子域名挖掘機
以xxxxxx為例,從標題,域名等收集
以xxxxxx為例,全自動腳本使用收集
teemo.py
▲ SRC中的資訊收集全覆蓋
Part4:資訊收集-補充部分
資訊收集過程中需要收集的其他資訊:
1.whois資訊【域名註冊時留下的資訊】
網址: //whois.chinaz.com/(站長之家)
//www.whois.com/(國外網站)
通過whois我們可以找到更多的域名,一般來說主站的安全是比較強的,我們可以去搞分站,而且我們還有可能查到郵箱,通過郵箱我們也可以做很多的事。
2.CMS指紋識別
//s.threatbook.cn/
//finger.tidesec.com/ 潮汐指紋【推薦】
常見埠和服務對應關係:
445-區域網文件共享服務【永恆之藍】
3389-遠程桌面
80-web搭建默認埠
3306-MySQL默認埠
21-Ftp
22-SSH服務
1433-SQL Server默認埠
6379-Redis資料庫默認埠
8888-寶塔默認埠
nmap的使用:
nmap+ip #最簡單的使用方法
nmap+ip/24 #C段探測
nmap -p [port1,port2,...] [ip] #探測指定埠
nmap -p 1-65535 [ip] #全埠掃描
nmap -v [ip] #執行命令的同時顯示每一步具體做了什麼
nmap -Pn [ip] #目標禁ping時可以使用
nmap -h #查看所有命令
nmap -O [ip] #探測主機是什麼作業系統
nmap -A [ip] #最強指令,把所有的掃描|探測方法都用上
網站狀態碼對應資訊:
200-網站正常訪問
302-重定向
404-頁面不存在
403-許可權不足,但是頁面存在
502-伺服器內部錯誤
Googlehacking語法:
filetype:指定文件類型
inurl:指定url包含內容
site:指定域名
intitle:指定title包含內容
intext:指定內容
inurl:/admin/index #這種很容易找到別人的後台
inurl:/admin.php #這種就很容易找到admin.php的內容
site:edu.cn inurl:.php?id=123 #找SQL注入站點時可以這麼找