Elasticsearch IK分詞器
- 2021 年 8 月 18 日
- 筆記
- elasticsearch, JAVA
Elasticsearch-IK分詞器
一、簡介
因為Elasticsearch中默認的標準分詞器(analyze)對中文分詞不是很友好,會將中文詞語拆分成一個一個中文的漢字,所以引入中文分詞器-IK。
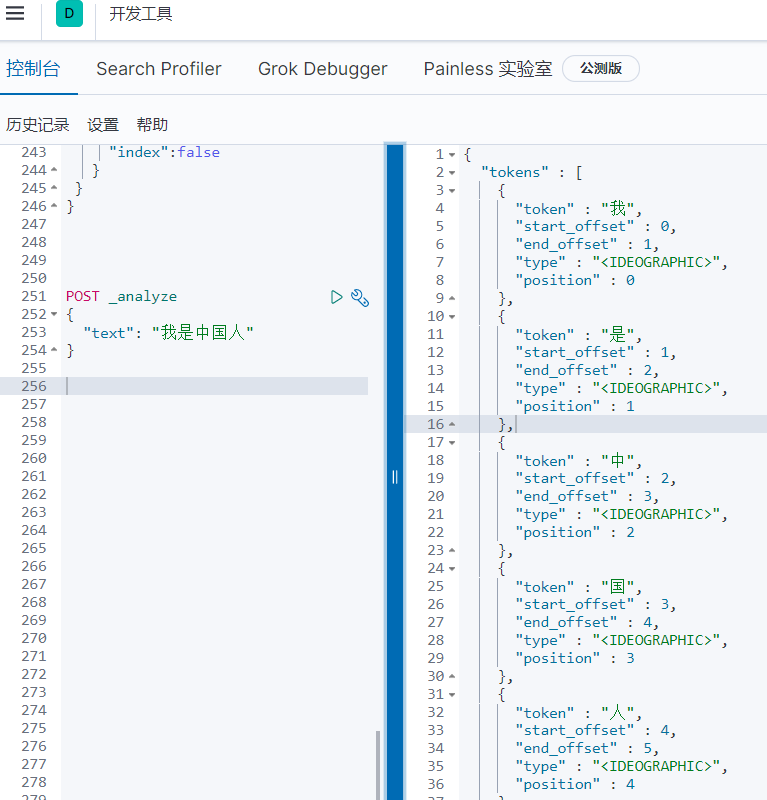
使用默認
二、安裝IK分詞器
1.先下載ik分詞器
注意 一定要下載和Elastic版本相同的IK分詞器
2.我們將ik分詞器上傳到我們的es的plugins/ik目錄下,ik文件夾需要我們自己創建
cd /usr/local/elasticsearch/plugins/ik/
unzip elasticsearch-analysis-ik-XX.zip
# windos下安裝也是一樣的操作
3.重啟
重啟的時候在日誌中就可以看到關於IK分詞器已經被載入進去了

三、測試分詞器
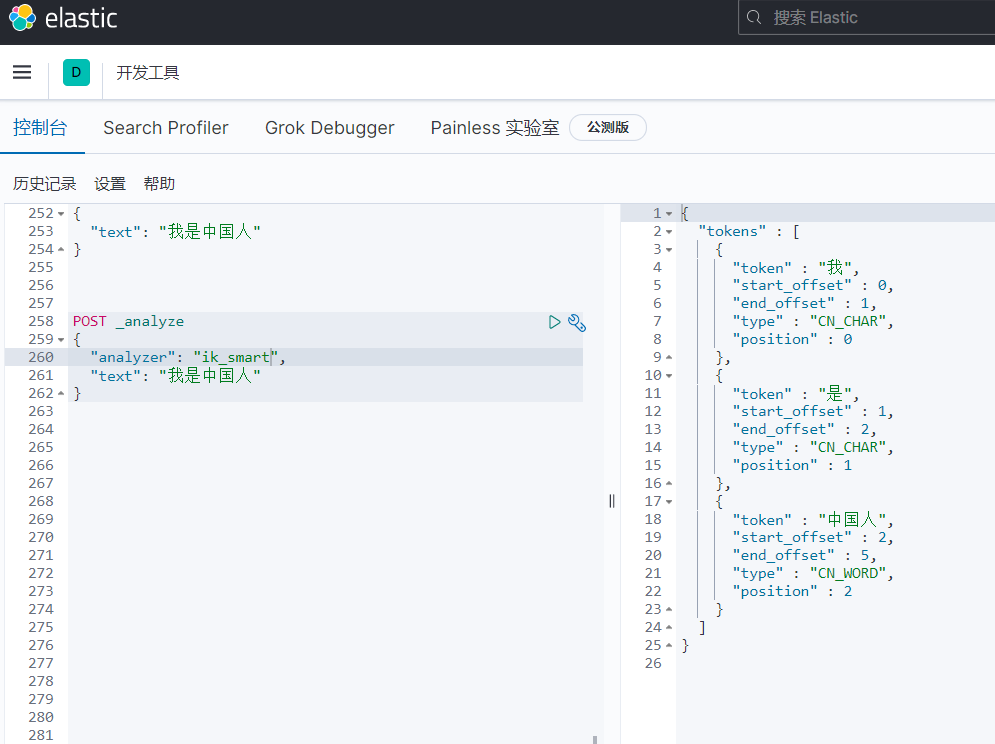
1.ik_smart
會做最粗粒度的拆分,比如會將「我是中國人」拆分為我、是、中國人。
POST _analyze
{
"analyzer": "ik_smart",
"text": "我是中國人"
}
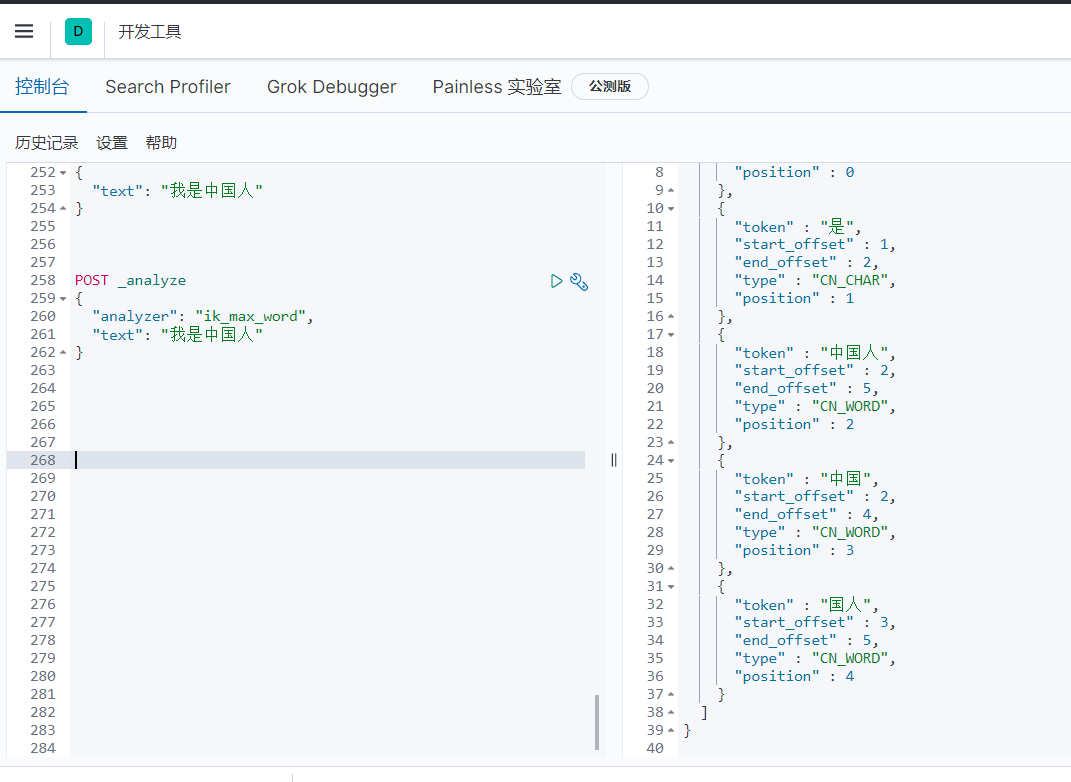
2.ik_max_word
會將文本做最細粒度的拆分,比如會將「我是中國人」拆分為「我、是、中華、中國人、中國、國人
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中國人"
}
四、自定義詞庫
使用場景
在利用ik分詞的過程中,當ik的分詞規則不滿足我們的需求了,這個時候就可以利用ik的自定義詞庫進行匹配,比如最火的常用的網路用語;我們輸入喬碧羅殿下正常的情況下,是不會識別整個詞語的,返回的都是分開的。我們識別整個詞語就需要自定義詞庫
1、自定義詞庫方式一(新建dic文件)
(1)到elasticsearch/plugins中尋找ik插件所在的目錄
(2)在ik中的config文件中添加詞庫
創建目錄 mkdir ciku
創建文件 vim test.dic
#編輯test.dic 注意每個詞語一行
(3)修改ik配置
vim /**/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
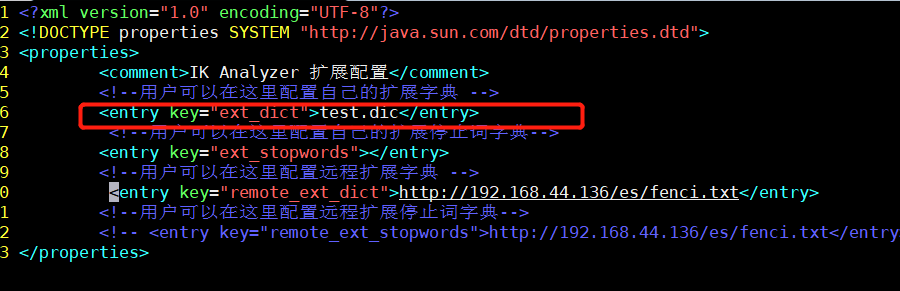
(4)重啟ElasticSearch
2、通過Nginx配置自定義詞庫
(1)安裝好nginx,到nginx的html目錄下創建分詞文件
vim fenci.txt
#每個詞語一行
(2)修改ik配置
vim /**/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
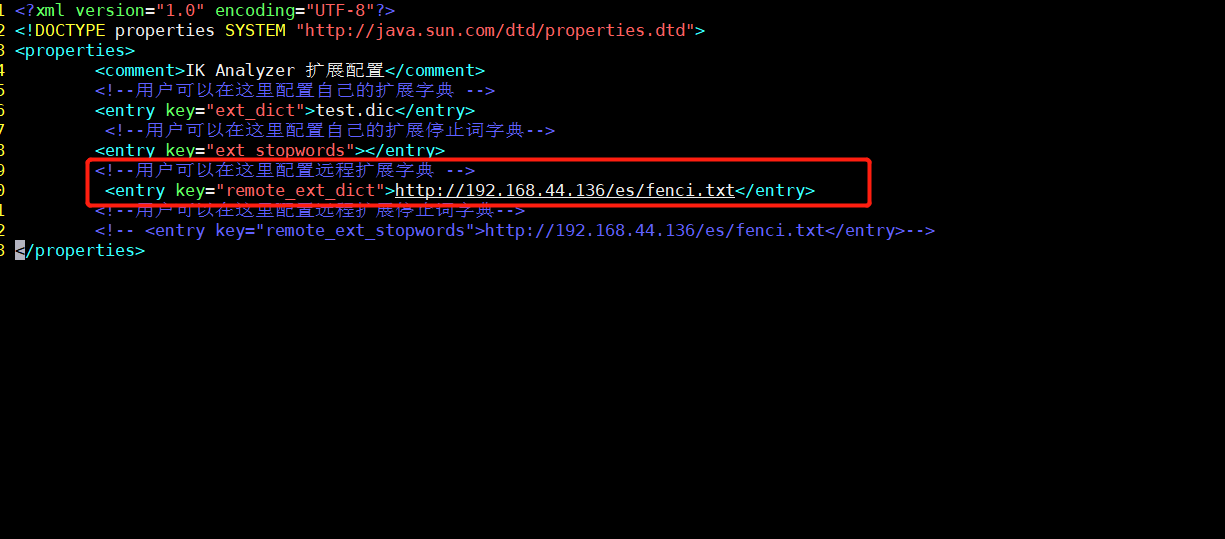
(3)重啟ElasticSearch
效果
我們輸入喬碧羅殿下正常的情況下,是不會識別整個詞語的,返回的都是分開的。當我們在詞庫文件中寫上喬碧羅殿下就會返回下面的效果



