Fluid + GooseFS 助力雲原生數據編排與加速快速落地
前言
Fluid 作為基於 Kubernetes 開發的面向雲原生存算分離場景下的數據調度和編排加速框架,已於近期完成了 v0.6.0 版本的正式發布。騰訊雲容器 TKE 團隊一直致力於參與 Fluid 社區建設,在最新版本中貢獻了以下兩大特性:快取引擎高可用運行時、新增數據快取引擎實現 GooseFSRuntime 。
什麼是存算分離?雲原生背景下為什麼需要數據編排?Fluid 和 GooseFSRuntime 又是什麼?別擔心!針對這些問題,我們帶你一一探索。本文將首先介紹 Fluid 技術的誕生背景以及與 GooseFS 之間的關係;其次通過在 TKE 集群上的實際操練讓大家體驗 Fluid v0.6.0 的兩大特性;最後我們將和大家一起探討 Fluid 社區的未來發展。希望通過這篇文章能讓大家進一步了解雲原生應用場景下的數據編排能力,期待有興趣的你一起參與 Fluid 的社區建設。
現狀和挑戰
什麼是存算分離架構?
「存算分離」是當前網路技術發展和社會經濟進步的時代產物,是最適合當前時代發展需求的一種架構。公有雲環境為了滿足用戶按需服務、無限拓展的需求,常使用塊存儲、文件存儲和對象存儲來取代本地存儲,例如在創建 TKE 集群時,會根據單盤的最大吞吐量、IOPS 等指標選擇掛載高性能雲硬碟、SSD 或增強型 SSD。這些不同規格的存儲載體本質上都是雲硬碟,且需要不定量地消耗網路頻寬。但是隨著雲廠商在技術上的不斷推動,以及用戶對成本、擴展性以及性能的極致追求,計算和存儲分離已然成為了雲原生架構的發展趨勢。
CNCF 發布的 《2020年中國雲原生報告》 指出,容器應用相對於兩年前達到了 240% 的驚人增長,容器編排實施標準 Kubernetes 在生產中的比例也從 72% 上升到 82%。Kubernetes 作為雲原生時代的底座,憑藉便捷的可移植性、豐富的可擴展性以及編排調度的自動化能力,已然成為公有雲、私有雲還有混合雲的首選。而目前很多 AI 和大數據的業務也在積極的向 Kubernetes 靠攏,例如開源機器學習平台 Kubeflow;大數據計算框架 Spark 也推出 Spark-operator 以滿足基於 Kubernetes 構建大數據計算平台的需求。雲原生應用向存儲計算分離架構演進的趨勢日益增長。
雲原生存算分離架構面臨的挑戰?
從 Adrian Cockcroft 於2013年介紹 Netflix 在 AWS 上基於 Cloud Native 的成功應用,到2015年 Pivotal 的 Matt Stine 定義雲原生架構以及雲原生計算基金會 CNCF 的成立,雲原生價值已經得到了企業用戶的廣泛接受。雖然雲原生正在加速向垂直行業的滲透,但存算分離的公有雲場景仍然讓雲原生業務的發展面臨著諸多挑戰:
- 雲平台存算分離架構導致數據訪問延時高。隨著高速網路設備和負載的大規模使用,所有的數據都依賴網路 IO 到計算節點計算和匯總,尤其是數據密集型應用,大概率網路會成為瓶頸(沒有銀彈)。IO 的瓶頸最終會導致計算和存儲的資源無法充分的利用,將會背離利用雲來實現降本增效的初衷。
- 混合雲場景下跨存儲系統的聯合分析困難。大多數公司的業務線可能會分為不同的小組,不同的小組針對不同的 Workload 使用的計算框架也各有不同,而框架支援的存儲也各有特點。例如 HDFS 針對大數據領域、Lustre 針對超頻領域等等。當需要聯合數據進行綜合性分析時,數據副本數增加、數據轉換的成本增加,都必然導致資源(即人力)的成本增高、業務迭代的效率降低等風險。
- 雲中數據安全治理與多維度管理日趨複雜。數據是很多公司的生命線,數據泄露、誤操作、生命周期管理不當都會造成巨大損失。如何在雲原生環境中保障數據隔離,保護好用戶的數據生命周期,都存在較大挑戰。
Fluid 能做什麼?
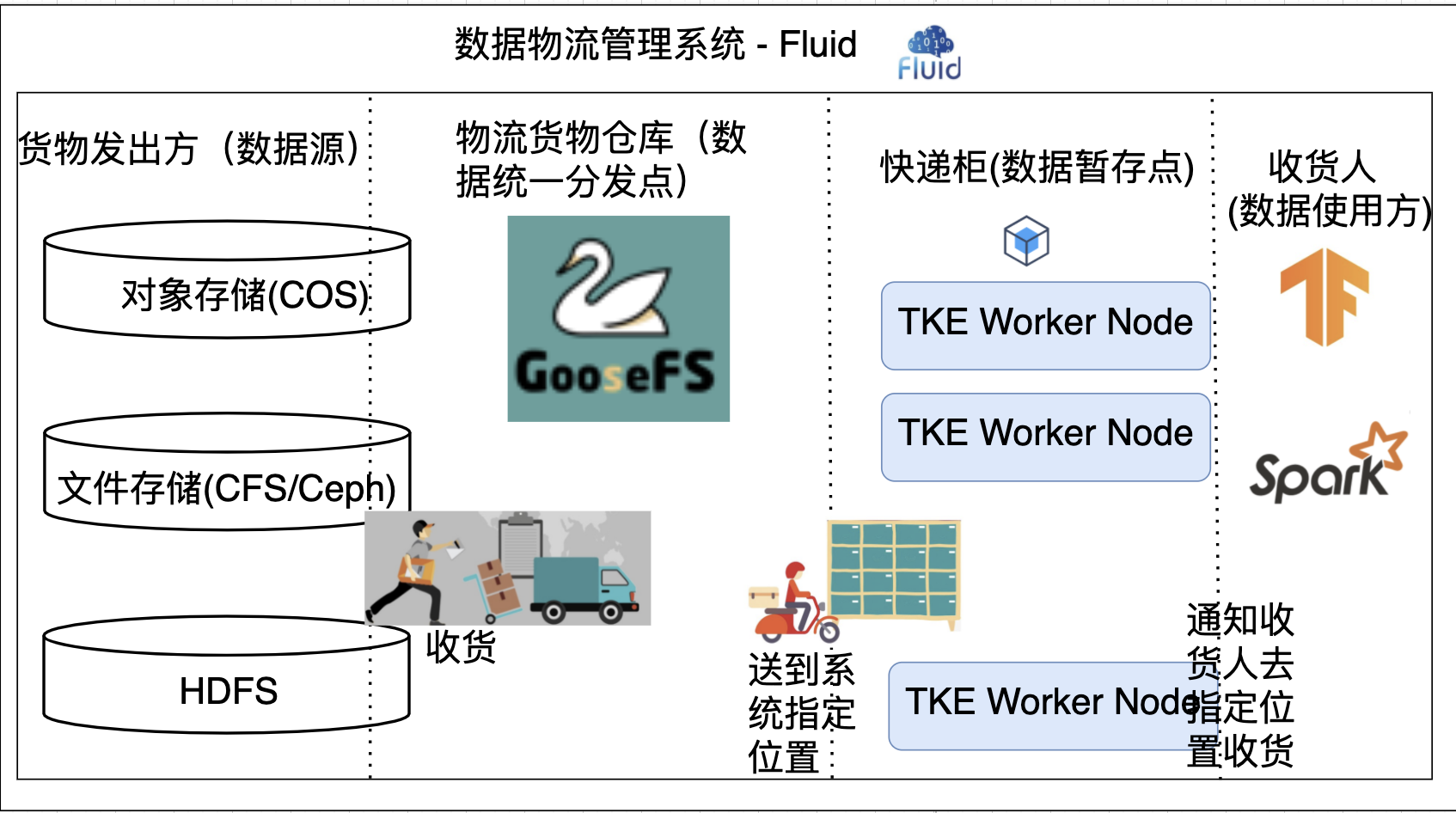
Fluid 類似雲原生世界的「物流管理系統」,物流的發出方是各種數據源,例如 COS、HDFS、Ceph 以及 Lustre 等;此外,還要有具備存儲不同貨物(即聚合不同數據源)能力的物流倉庫,如 GooseFS;而物流的收貨地址就是用戶期望數據被使用的計算節點。
Fluid 的設計目標就是為了將貨物(數據)高效、準確的投放到用戶手中。在實際生活中,我們常以快遞櫃的形式進行快遞的分發,即在貨物到達指定快遞櫃後希望用戶主動領取快遞。這樣可以避免快遞積壓,用戶也可以彈性規劃快遞的領取時間。其實設計理念體現到雲計算場景就類似運算元下推,將更多的計算下推到存儲層完成,減少所需傳輸的數據量。希望在最後一公里實現,「移動計算到存儲」而不是「移動存儲到計算」。
GooseFS & Fluid 探究
雲原生數據湖加速器 GooseFS
數據湖加速器(Data Lake Accelerator Goose FileSystem,GooseFS),是由騰訊雲推出的高可靠、高可用、彈性的數據湖加速服務。依靠對象存儲(Cloud Object Storage,COS)作為數據湖存儲底座的成本優勢,為數據湖生態中的計算應用提供統一的數據湖入口,加速海量數據分析、機器學習、人工智慧等業務訪問存儲的性能;採用了分散式集群架構,具備彈性、高可靠、高可用等特性,為上層計算應用提供統一的命名空間和訪問協議,方便用戶在不同的存儲系統管理和流轉數據。
分散式數據編排和加速框架 Fluid
Fluid 是 CNCF Sandbox 開源的分散式數據編排和加速框架,是學術界(南京大學等)原創研究和工業界落地實踐的結合開源項目。在計算和存儲分離的大背景驅動下,Fluid 的目標是為 AI 與大數據云原生應用提供一層高效便捷的數據抽象,將數據從存儲抽象出來,以便達到:
- 通過數據親和性調度和分散式快取引擎加速,實現數據和計算之間的融合,從而加速計算對數據的訪問;
- 將數據獨立於存儲進行管理,並且通過 Kubernetes 的命名空間進行資源隔離,實現數據的安全隔離;
- 將來自不同存儲的數據聯合起來進行運算,從而有機會打破不同存儲的差異性帶來的數據孤島效應。
從用戶角度來說,用戶聲明數據來源後,Fluid 將自動調度數據到最合適的節點,並向外暴露 kubernetes 原生持久化數據卷。用戶應用例如大數據應用 hadoop、spark 或 AI 應用 Pytorch、Tensorflow 等只需要掛載數據卷,Fluid 就可以通過親和性調度讓應用達到數據加速和統一訪問的目的。Fluid 項目開源短短半年多時間內發展迅速,吸引了眾多大廠的專家和工程師的關注與貢獻,項目 Adoptor 包括騰訊、微博、奇虎 360、中國電信、BOSS 直聘、第四範式等多家大型知名 IT 和互聯網企業。
理清 TKE、Fluid 和 GooseFS 之間的關係
Fluid 與騰訊雲 TKE 融合的架構如下所示,根據不同的視圖分為計算調度層、存儲層以及任務層,下面我們將對該架構剝繭抽絲,帶你快速理清 Fluid、TKE、GooseFS 三者之間的關係。
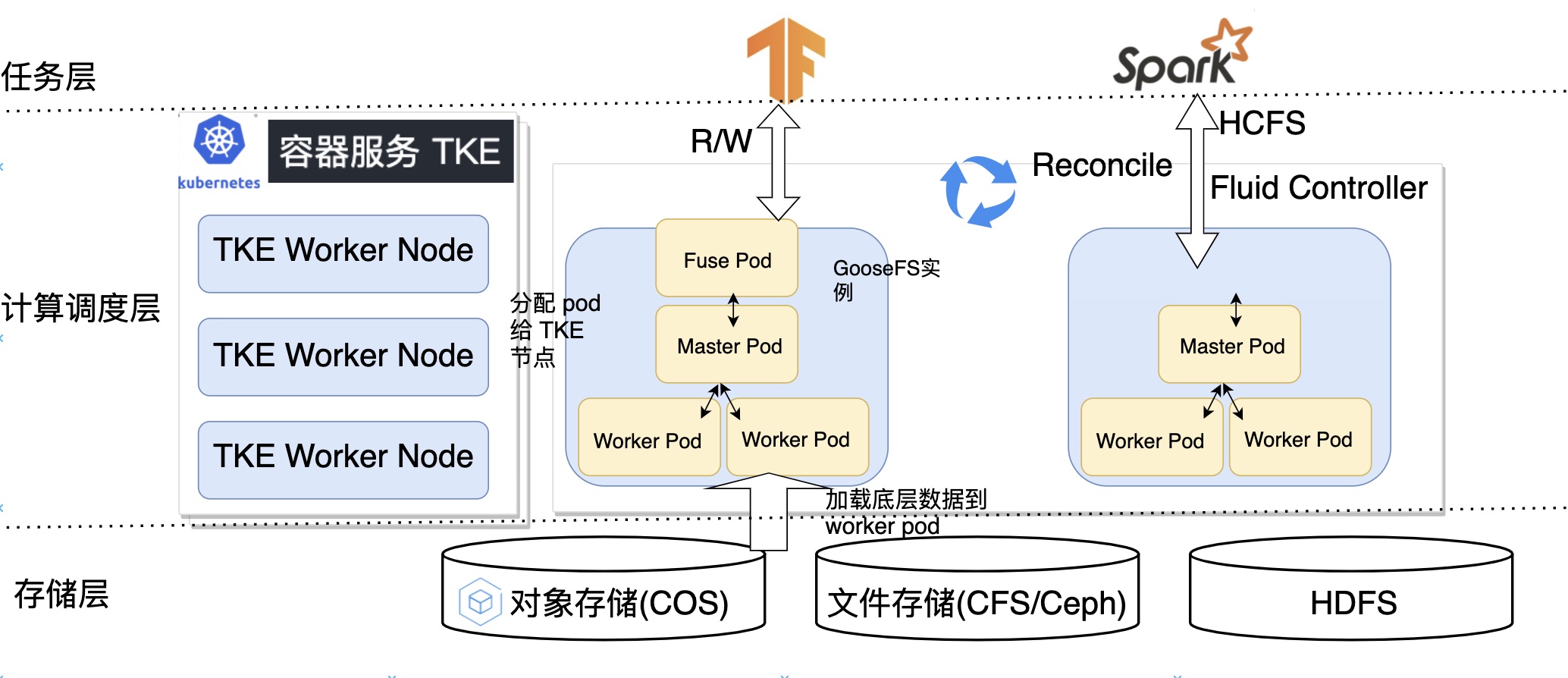
- 計算調度層:TKE 以 Kubernetes 環境為底座提供了容器應用的部署平台,Fluid GooseFS 控制器將控制 GooseFS 實例中的 Master Pod、Worker Pod 以及 Fuse Pod 創建在最合適的 TKE Worker 節點。
- 存儲層:控制器會根據用戶指定的數據來源將底層存儲例如 COS、HDFS 的數據快取到 Worker Pod 中。
- 任務層:任務 pod 指定持久化存儲卷,控制器 webhook 會注入親和性資訊,以實現將使用快取任務優先調度到有快取節點以及將不使用快取任務先調度到沒有快取節點的目標。
總體來說,Fluid 通過雲原生的架構,在數據最後一公里,通過「移動計算到存儲」的理念解決了 AI/大數據 存算分離場景下的諸多痛點。
Fluid v0.6.0 特性體驗
以下特性均由騰訊雲 TKE 團隊設計貢獻
「快取引擎高可用運行時」
在 GooseFS 分散式快取文件系統中,高可用性包含兩層,一是整個文件系統的可用性,二是數據的完整和一致性。Master 作為全局元數據管理組件,通過 Master High-Availability 保證文件系統的高可用;通過 Raft 演算法實現選主、狀態機同步等操作保證日誌和元數據的完整和一致性。在真實業務場景下如果單個 master 出現故障,會直接影響業務的正常運行,這就要求 Fluid 需要支援快取引擎多 master 來保證容錯率。
「新增數據快取引擎實現 GooseFSRuntime」
為了支援騰訊雲 TKE 上的計算任務對快取系統的需求,我們在新版本中新增了一種支撐 Fluid Dataset 數據管理和快取的執行引擎實現。用戶可以在 Fluid 中通過 GooseFSRuntime 使用 GooseFS 快取能力進行騰訊雲 COS 文件的訪問和快取。在 Fluid 上使用和部署 GooseFSRuntime 流程簡單、兼容原生 K8s 環境、開箱即用,配合騰訊雲 TKE 食用更佳。
特性 Demo
本文檔將向你簡單地展示上述特性
前提條件
在運行該示例之前,請參考安裝文檔完成安裝,並檢查 Fluid 各組件正常運行:
$ kubectl get pod -n fluid-system
goosefsruntime-controller-5b64fdbbb-84pc6 1/1 Running 0 8h
csi-nodeplugin-fluid-fwgjh 2/2 Running 0 8h
csi-nodeplugin-fluid-ll8bq 2/2 Running 0 8h
csi-nodeplugin-fluid-dhz7d 2/2 Running 0 8h
dataset-controller-5b7848dbbb-n44dj 1/1 Running 0 8h
通常來說,你會看到一個名為dataset-controller的 pod、一個名為 goosefsruntime-controller 的 pod 和多個名為csi-nodeplugin的 pod 正在運行。其中,csi-nodeplugin這些 pod 的數量取決於你的 Kubernetes 集群中結點的數量。
新建工作環境
$ mkdir <any-path>/demo
$ cd <any-path>/demo
查看全部節點
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.1.145 Ready <none> 7d14h v1.18.4-tke.13
192.168.1.146 Ready <none> 7d14h v1.18.4-tke.13
192.168.1.147 Ready <none> 7d14h v1.18.4-tke.13
創建 Dataset 資源
cat >> dataset.yaml <<EOF
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:
name: hbase
spec:
mounts:
- mountPoint: //mirrors.tuna.tsinghua.edu.cn/apache/hbase/stable/
name: hbase
EOF
$ kubectl create -f dataset.yaml
dataset.data.fluid.io/hbase created
mountPoint 這裡為了方便用戶進行實驗使用的是 Web UFS, 使用 COS 作為 UFS 可見 加速 COS。
創建並查看 GooseFSRuntime 資源
cat >> runtime.yaml <<EOF
apiVersion: data.fluid.io/v1alpha1
kind: GooseFSRuntime
metadata:
name: hbase
spec:
replicas: 3
tieredstore:
levels:
- mediumtype: MEM
path: /dev/shm
quota: 2G
high: "0.8"
low: "0.7"
master:
replicas: 3
EOF
$ kubectl create -f runtime.yaml
goosefsruntime.data.fluid.io/hbase created
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
hbase-fuse-4v9mq 1/1 Running 0 84s
hbase-fuse-5kjbj 1/1 Running 0 84s
hbase-fuse-tp2q2 1/1 Running 0 84s
hbase-master-0 1/1 Running 0 104s
hbase-master-1 1/1 Running 0 102s
hbase-master-2 1/1 Running 0 100s
hbase-worker-cx8x7 1/1 Running 0 84s
hbase-worker-fjsr6 1/1 Running 0 84s
hbase-worker-fvpgc 1/1 Running 0 84s
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
hbase Bound default-hbase 100Gi ROX fluid 12h
$ kubectl get goosefsruntime
NAME MASTER PHASE WORKER PHASE FUSE PHASE AGE
hbase Ready Ready Ready 15m
$ kubectl exec -ti hbase-master-0 bash
# 可以看到其中一個節點是 LEADER 其餘兩個是 FOLLOWER
$ goosefs fs masterInfo
current leader master: hbase-master-0:26000
All masters: [hbase-master-0:26000, hbase-master-1:26000, hbase-master-2:26000]
我們這裡主要關注三個地方:
- 到這裡,我們已經創建了可以供計算任務訪問的分散式快取引擎 GooseFS,計算任務的 pod 只需要指定
persistentVolumeClaim.name為 hbase 即可獲取快取加速的能力。 - 同時只需要通過指定
spec.master.replicas=n,這裡 n 為大於等於 3 的奇數,就可以直接開啟 Master HA 模式。 - 只需要指定
spec.replicas=n,控制器將為 GooseFS 快取系統創建 3 個 worker pod 以及 3 fuse pod
數據預熱和加速
// 不使用快取情況下任務時間
$ cat >> nginx.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- mountPath: /data
name: hbase-vol
volumes:
- name: hbase-vol
persistentVolumeClaim:
claimName: hbase # 掛載 pvc claimName 和 dataset 一致
EOF
$ kubectl create -f nginx.yaml
$ kubectl exec -it nginx /bin/bash
$ root@nginx:/# time cp -r /data/hbase /
real 1m9.031s
user 0m0.000s
sys 0m2.101s
$ kubectl delete -f nginx.yaml
// 使用快取加速
// 創建 Dataload 資源
$ cat >> dataload.yaml <<EOF
apiVersion: data.fluid.io/v1alpha1
kind: DataLoad
metadata:
name: hbase-dataload
spec:
dataset:
name: hbase
namespace: default
target:
- path: /
replicas: 1
EOF
$ kubectl create -f dataload.yaml
// 查看快取預熱進度
$ kubectl get dataset hbase --watch
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
hbase 545.32MiB 545.32MiB 5.59GiB 100.0% Bound 16m
$ kubectl create -f nginx.yaml
$ kubectl exec -it nginx /bin/bash
$ root@nginx:/# time cp -r /data/hbase /
real 0m0.278s
user 0m0.000s
sys 0m0.273s
這種大幅度的加速效果(1m9s -> 0.278s 加速248倍) 歸因於 GooseFS 所提供的強大的快取能力。總結下來,通過 GooseFSRuntime 將用戶定義的數據源統一管理,通過快取來加速應用的訪問。
這裡主要展示 v0.6.0 的兩大功能:快取引擎高可用運行時以及新增數據快取引擎實現 GooseFSRuntime ,不涉及 Fluid 其他功能,其他功能可見 使用文檔。
Fluid Roadmap
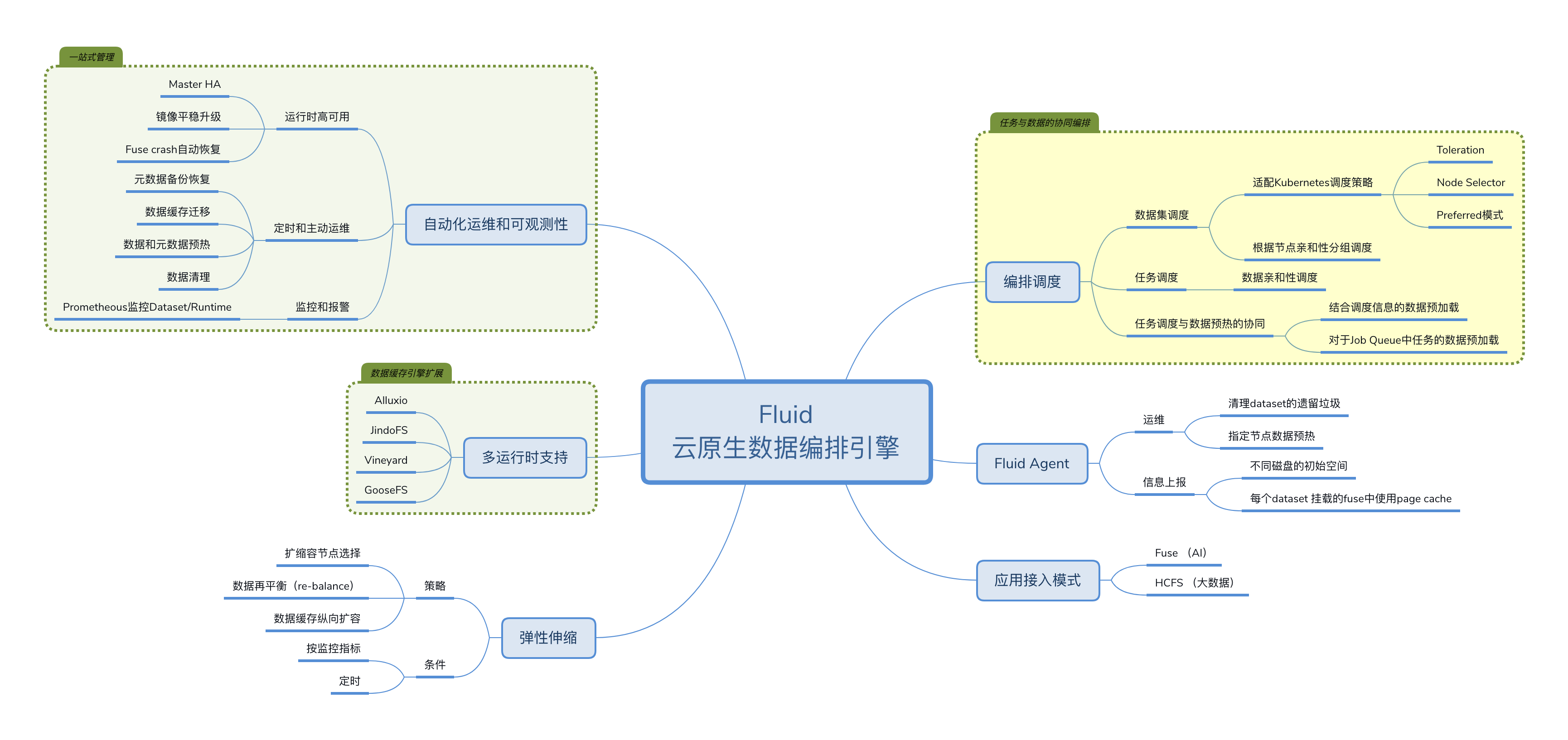
上圖為 Fluid 社區現規劃的 Roadmap, 主要分為六個方面:自動化運維和可觀測性、多運行時支援、數據彈性伸縮、編排調度優化、Fluid Agent 以及接入模式。目前自動化運維、多運行時支援以及接入模式基本實現,後期社區主要關注以下三個方面:
- 彈性拓展方面,目前已經支援基於自定義指標對快取 Worker 進行 HPA(Horizontal Pod Autoscaler) 以及針對業務波峰波谷的 CronHPA 。但是由於快取引擎數據再平衡(re-balance)功能的缺失,目前無法利用擴縮容達到降本增效的目的,這個也是社區後期重點關注的特性。
- Fluid Agent 方面,通過 agent push 模式,上報一些關鍵的運維指標例如是否有殘留需要清理、節點是否有快取等;同時不同節點上的系統資訊例如 cpu/memory 使用量、磁碟使用量、page cache 使用資訊等,通過這些資訊可以指導 fluid 調度器對數據集進行最優調度。
- 調度策略方面,目前主要涉及三個方面的調度:
- 數據集調度:目前已經適配 kubernetes 調度,例如 Toleration、Node Selector、Preferred 調度;後期我們希望以 Scheduling Framework 的方式通過 Filter、Scoring、Binding 等操作實現數據集最優調度。
- 任務調度:目前已經可以通過 webhook 自動對指定 namespace 下的負載加入親和性和反親和性標籤進行任務調度;
- 任務調度和數據預熱協同調度:通過調度資訊對 Job Queue 中 Job 使用的數據進行預載入,達到流水線優化的目的。
總結與展望
本文首先介紹了 Fluid 技術的誕生背景以及數據編排功能如何在存算分離場景下解決雲原生業務對”移動計算到存儲」的需求痛點;其次通過簡要分析 Fluid 的架構,理清了 Fluid、GooseFS、TKE 三者的關係,並通過簡單的 Demo 展示了 v0.6.0 的兩大基礎功能;最後通過 Fluid Roadmap 總結了目前社區已經完成的工作以及未來的發展規劃。
總的來說,在公有雲實現計算和存儲的極致彈性才是增效降本的前提。只有讓我們的業務更好的使用彈性的能力,獲取雲原生乃至雲計算最大的紅利,才能讓應用生於雲、長於雲。

