一文讀懂哈希和一致性哈希演算法
- 2021 年 8 月 16 日
- 筆記

哈希 Hash 演算法介紹
哈希演算法也叫散列演算法, 不過英文單詞都是 Hash, 簡單一句話概括, 就是可以把任意長度的輸入資訊通過演算法變換成固定長度的輸出資訊, 輸出資訊也就是哈希值, 通常哈希值的格式是16進位或者是10進位, 比如下面的使用 md5 哈希演算法的示例
md5("123456") => "e10adc3949ba59abbe56e057f20f883e"
主要特點:
- 不可逆 從哈希值不能推導出原始數據, 所以Hash演算法廣泛應用在現代密碼體系中
- 無碰撞 不同的資訊進行哈希後得到的值應該是不同的, 但是從理論上來說, 哈希演算法其實是有可能發生碰撞的, 輸入的資訊是無窮的, 而輸出的哈希值長度是固定的, 所以是有限的。好比要把10個蘋果放到9個抽屜裡面, 肯定會有一個抽屜裝了多個蘋果, 只不過哈希演算法的碰撞的概率是非常小的, 比如128位的哈希值, 就有2的128次方的空間。
- 效率高 在處理比較大的原生值時, 也能能快速的計算出哈希值
- 無規律 原始輸入資訊修改一點資訊, 得到的哈希值也是大不相同的
哈希演算法的實現有很多, 常見的有 MD5, SHA-1, 還有像 C#, Java 一些語言都有直接的 GetHashCode(), hashCode() 函數可以直接來用。
分散式存儲場景
在互聯網場景中, 通常面對的都是海量的數據,海量的用戶, 那為了要滿足大量數據的寫入和查詢, 以及高可用, 一台單機的存儲伺服器肯定是不能滿足需求的, 通常需要使用多台伺服器形成分散式存儲。
場景描述:
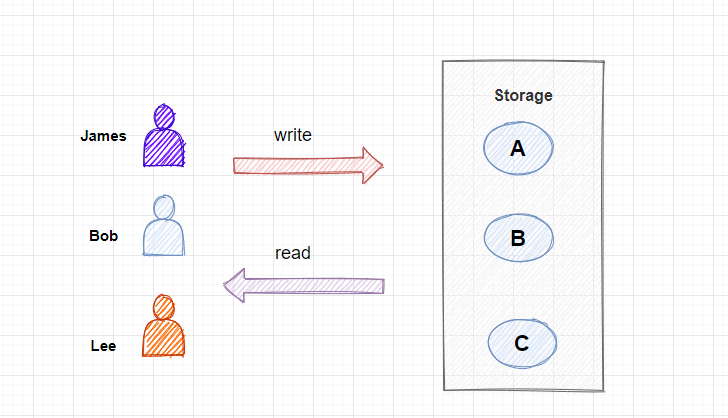
在本文中, 為了方便大家更好的理解, 這裡列出了一個簡單的例子, 有三位用戶, 分別是 James、 Bob、 Lee, 我們需要把用戶的圖片寫入到存儲伺服器節點, 這裡有ABC三個節點, 而且當查詢用戶的圖片時, 還需要快速定位到這個用戶的圖片是在哪個節點存儲的, 然後直接從這個節點進行查詢, 需要滿足高效率的查詢。
實現思路:
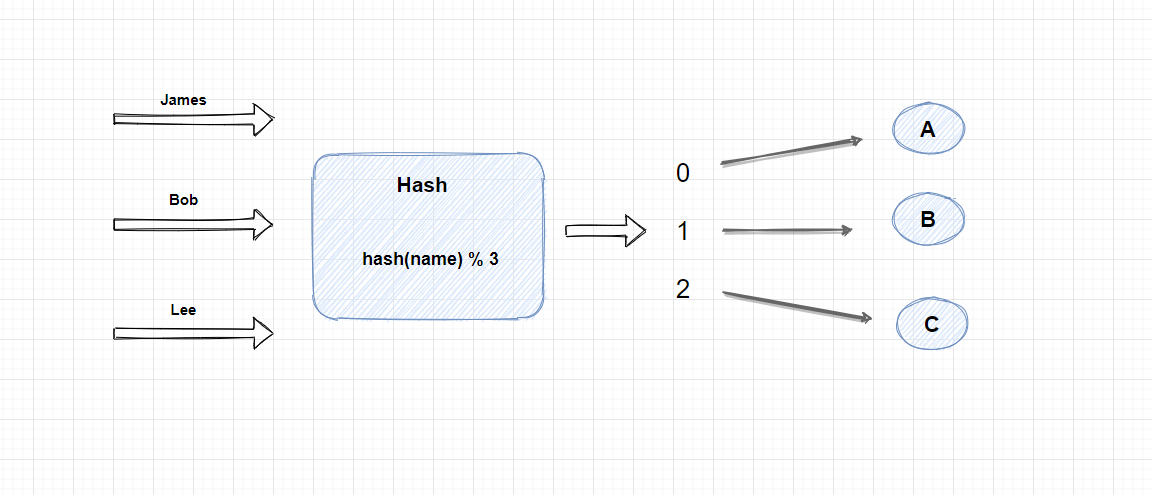
首先,我們可以對用戶標識進行 Hash 計算, 這裡我為了方便演示, 使用了用戶名作為Hash對象, 當然你還可以對用戶的IP或者是UserId 進行Hash計算, Hash計算後會生成一個int類型的數字, 然後再根據存儲節點的數量進行取模, 這裡的公式就是 hash(name) % 3, 計算得出的結果只有三種情況, 分別是 0,1,2, 然後我們再把這三種結果和三個存儲節點做一個映射, 0 ==> A, 1 ==> B, 2 == C。 因為Hash演算法對一個值多次計算後都會得到同樣的hash值, 所以上面的公式, 一個用戶的圖片每次都會固定的寫入的其中一個節點, 這樣做查詢的話, 也可以通過hash演算法快速找到這個用戶的圖片所在的節點。
缺點:
上面我們使用Hash演算法實現了負載均衡, 可以根據用戶名路由到圖片所在的節點, 但是上面的方法也有一個很大的缺點, 那就是當伺服器的數量增加或者減少時, 我們通過Hash演算法生成的路由規則就再不準確了。
試想一下, 如果新增或者減少一個節點, 上面的公式就會變成 hash(name) % 4 或者 hash(name) % 2, 這裡的關鍵點是, 我們之前用3取模, 現在變成用4或者2取模, 結果當然大概率是不一樣了, 當然如果 Hash後是12的話,用3或者4取模得到的結果都是為0, 不過這種概率比較小。
這個問題帶來的影響是, 路由規則不再準確, 大部分的查詢請求都撲了空。那麼如何解決這個問題呢?相信有的同學這時應該有了一些想法, 是的沒錯, 關鍵點就在於, 不管節點的數量怎麼變化, 都應該使用一個固定的值來進行取模! 只有這樣才能保證每次進行Hash計算後, 得出的結果是不變的!
一致性Hash演算法
同樣的,一致性Hash演算法也是利用取模的方式, 不過通常是用一個很大的數字進行求模, 你可以用整數的最大值 int.Max, 2的32次方, 當然這個並沒有要求, 不過越大的數字, 平均分配的概率就越大(後面會具體介紹這個問題)。
為了方便理解, 這裡我用 1000 來取模, 我們可以用一個長度為1000的數組表示它,就像這樣

接下來, 我們先不對用戶的圖片進行Hash處理, 而是先對每個節點進行 Hash 處理和映射, 現在的公式分別是 hash(A) % 1000, hash(B) % 1000,hash(C) % 1000, 這樣得出的結果一定是在0-999 之間, 然後把這個值映射到數組中, 在程式碼中, 你可以用一個字典集合來保存這個映射關係。
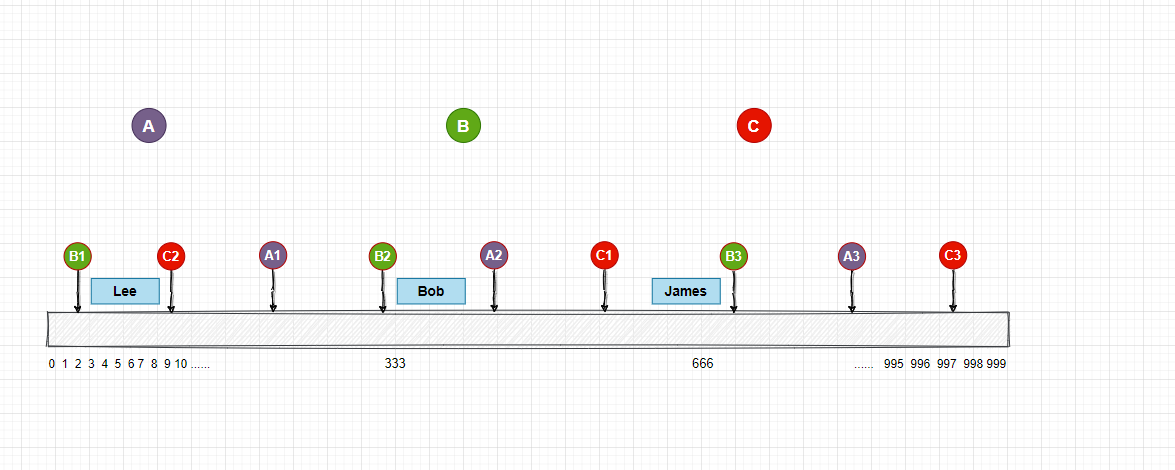
對應的存儲節點和數組的映射可能如下:
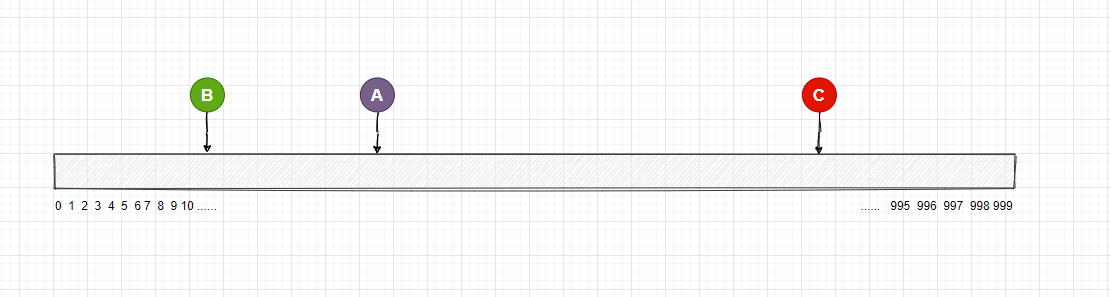
那現在用戶的圖片怎麼和存儲節點對應呢? 因為存儲節點已經映射到了數組上, 我們現在可以通過範圍區間的方式, 來找到對應的節點, 映射在數組上的圖片可以向右查找, 找到了一個節點, 那麼這個圖片就屬於這個節點, 當往右查找到最大值時,再回到最左邊從0開始。
我在圖中用不同的顏色標記了每個存儲伺服器的範圍區間, 你可以理解一下
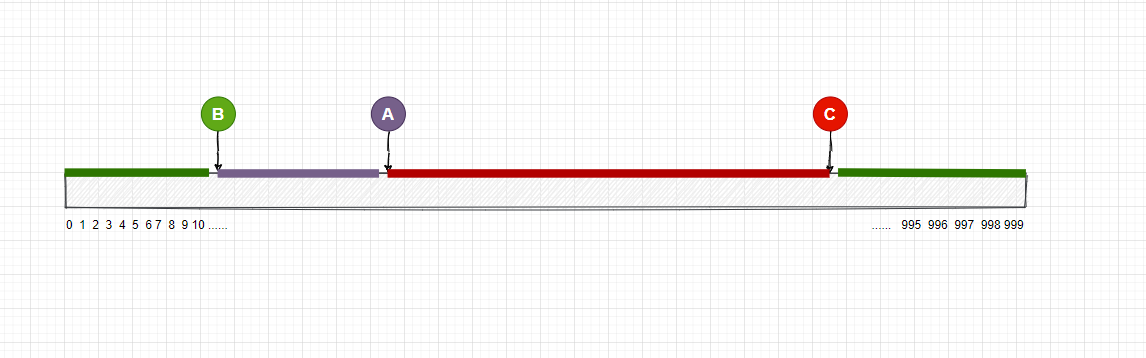
接下來, 我們就需要對用戶的圖片進行Hash計算取模,同樣的,計算結果一定還是在0-999的範圍內, 然後再把這些值映射到數組上, 映射的結果可能如下圖:
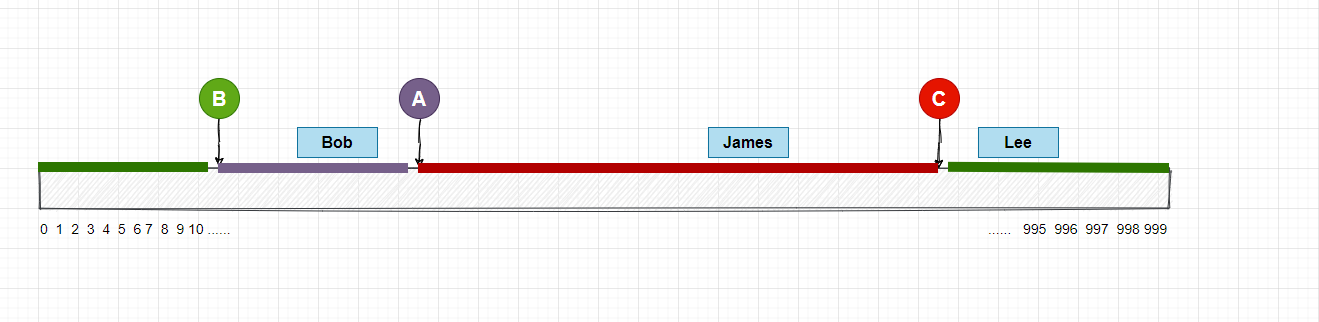
這樣就可以通過往右查找的方式, 找到用戶的圖片相對應的存儲節點! 總結下來上面做了幾件事情, 首先我們取一個固定的並且比較大的整數進行求模, 然後在對每個節點進行Hash計算求模, 這樣可以找出每個節點所對應的範圍區間, 最後再把用戶的圖片進行Hash計算求模, 最後根據範圍區間確定圖片的所在的存儲節點。
那我們看看使用了這種方式, 當存儲節點的增加和減少時會有什麼影響?
節點增加場景
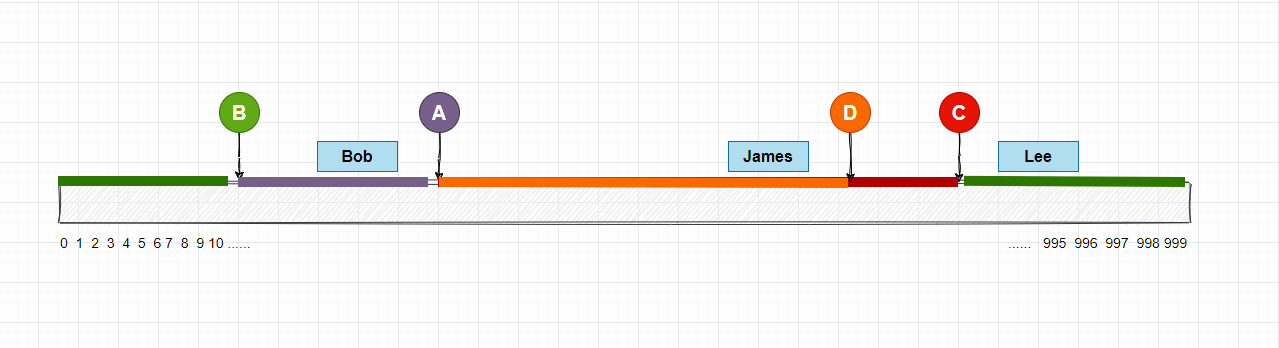
這裡我新增了一個存儲節點D, 經過Hash計算後映射在數組上, 這樣的話, 用戶 James 本來是路由到C節點的,現在被路由到了D節點, 不過我們添加了D節點後, 受到影響的也只有C節點, 其實不管D節點映射到數組哪一個位置, 都只會有一個節點會受到影響, 其他的節點可以正常使用。
那麼這種情況下, 如何做數據遷移? 我的思路是, 我們需要把C節點全部數據重新進行Hash計算, 然後根據計算結果, 一部分會移動到D節點, 一部分繼續保留在C節點。
節點減少場景

假如現在 A 節點在晚上20點宕機了, 那麼本來應該路由到A節點的數據, 現在就被路由到了節點C, 也就是圖中的 Bob的數據, 但是這種情況下, 其他的節點是不會受到節點變動的影響, 等到晚上21點時, A節點又恢復了正常。
這種情況的數據遷移的思路是, 當A節點宕機後, 數據需要全部複製到C節點, 當A節點恢復正常後, 再把C節點20:00至21:00的數據重新Hash計算, 然後根據計算的結果, 一部分會移動到A節點, 一部分繼續保留在C節點。
節點分布不均勻
因為節點是隨機的散列分布在數組上,所以有的節點的範圍比較大, 而有的節點的範圍比較小, 這樣我們的數據分布就不均勻, 有的節點伺服器會有比較大的請求壓力。
這種情況有的同學可能會說, 我可以根據數組的長度(1000)和節點(3)的個數, 求出平均值, 然後就可以平均的把節點散列到數組上, 這樣每個節點的請求壓力都是一樣的, 這種方式看起來沒什麼問題, 但是當添加節點或者移除節點的時候, 每個節點的覆蓋範圍都需要重新計算, 然後也需要遷移數據, 影響的範圍還是挺大的。
虛擬節點
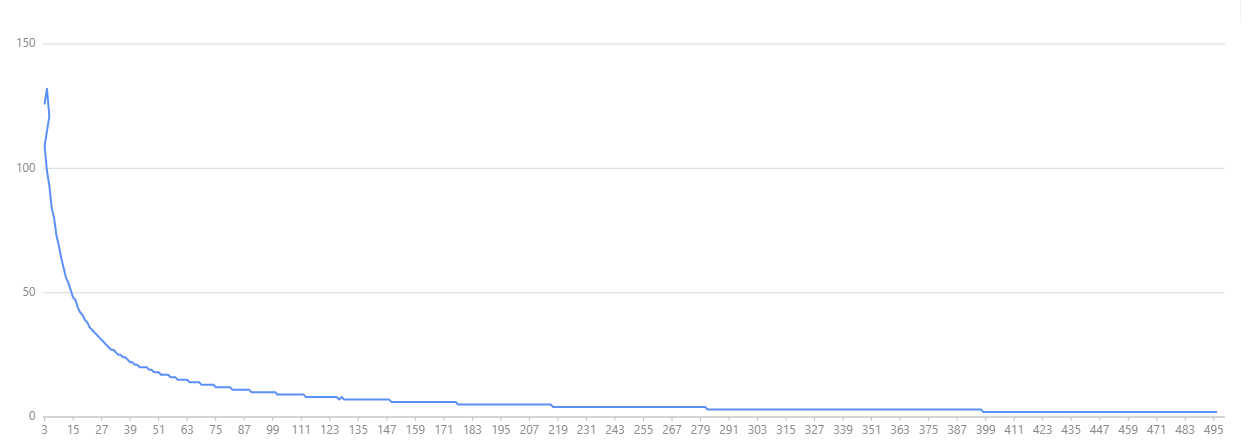
之前我們用了三個存儲節點, 發現有分布不均勻的情況, 上圖是我做了一個簡單的測試, x 軸是節點的數量, y 軸是標準偏差, 根據這個圖的趨勢得出的結論是, 節點越多的時候, 標準偏差也就越小, 節點分布的就越均勻。
實際中,伺服器節點是有限的, 增加很多節點也肯定是不現實的, 那麼就可以在伺服器節點不變的情況下, 引入虛擬節點, 也叫做影子節點。

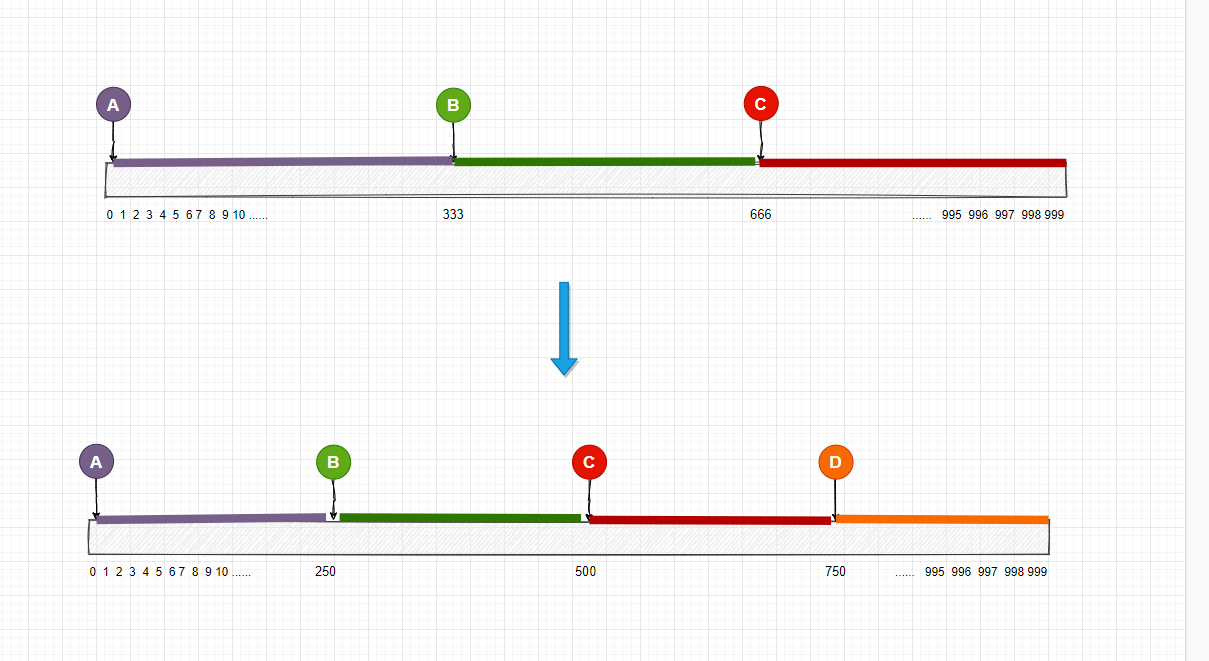
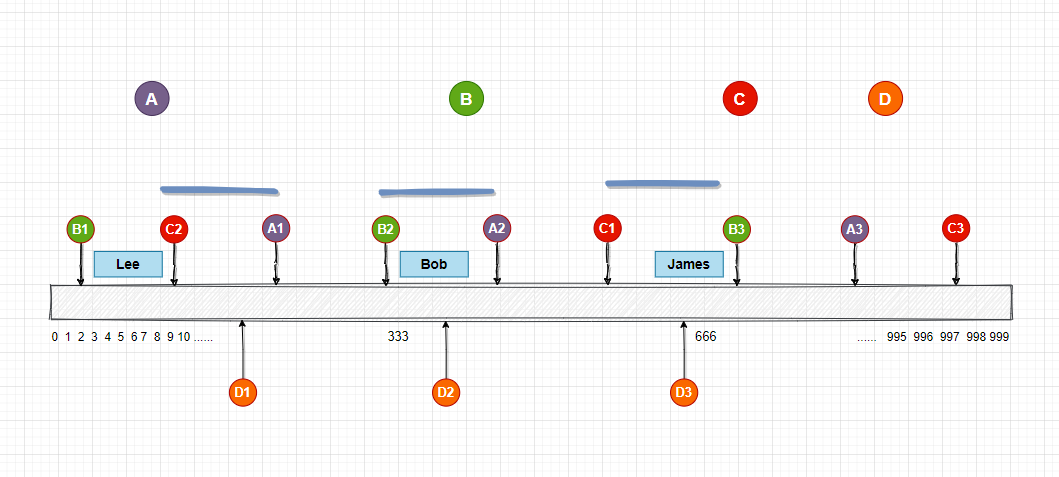
還記得我們之前是怎麼對節點做hash映射的嗎?公式是 hash(node) / 1000, 我們現在可以給A節點創建10個虛擬節點, 分別是 A1, A2,A3…, A10, 對應的虛擬節點的公式就是 hash(A1) / 1000 等等。這些虛擬節點和真實節點存在映射關係, 當圖片映射到A節點的任意一個虛擬節點上時, 我們就把這個圖片路由到A存儲節點, 現在數組上已經有了30個虛擬節點做映射, 分布也比之前更均勻了, 當然你也可以創建更多的虛擬節點, 這些真實節點和虛擬節點的映射關係要保存在記憶體中或者是資料庫中, 現在我們的映射圖如下, 這裡我給每個真實節點都添加了3個虛擬節點。
引入了虛擬節點後, 在數組的映射看起來平均很多了, 現在我們每個真實節點的請求壓力都是一樣的了, 接下來, 我們還要看下這個方案在節點的變動情況下應該怎麼處理。
增加節點
現在增加了一個節點D,按照上面的規則, 實際上是要添加 D 的虛擬節點, D1,D2,D3,然後散列映射到數組上,如下圖所示:
先看最左邊, D1 插入到了 C2 和 A1 之間, 而A1和A節點對應, D1節點和D節點對應, 也就是說A節點的一部分數據要遷移到D節點, 這裡我的思路是, 當在節點寫入數據時, 同時把虛擬節點的資訊也記錄下來,這樣就很方便做數據遷移了, 我們可以在A節點中只找出A1虛擬節點的數據, 而不是全部, 然後Hash計算映射後, 根據計算結果,一部分同步到D節點, 一部分保持不變。後邊的數據也可以按照這個思路進行數據遷移。
節點減少
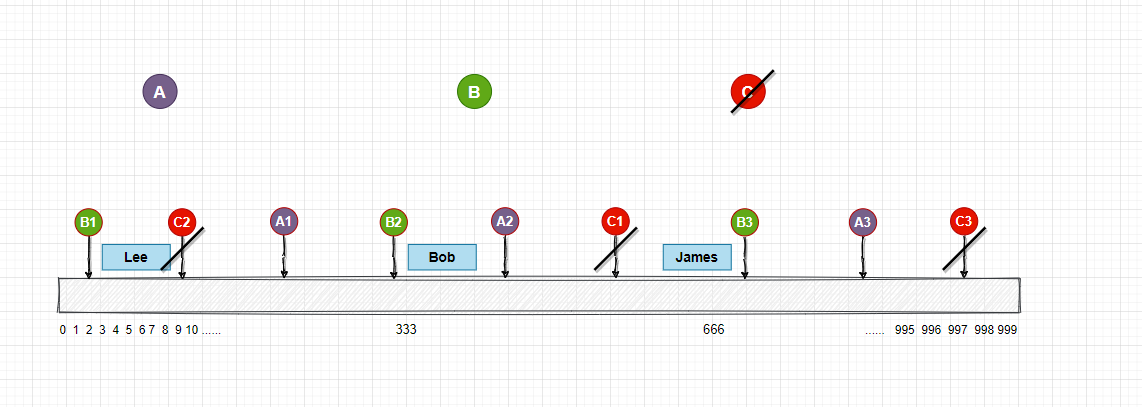
當C節點下線的時候, 我們同時要移除和C節點對應的虛擬節點,C1,C2,C3, 然後就是數據遷移的工作了, 根據圖中的表示, 可以直接把 C節點中的C2節點的數據遷移到A1節點, C1遷移到B3,C3遷移到B1中, 完成!
總結
本文介紹了哈希和一致性哈希演算法, 以及提供了一些數據遷移的思路, 回顧下這個方案, 首先需要定義一個比較大的固定值用於取模, 然後創建和真實節點對應的虛擬節點, 最後再把虛擬節點映射到數組上, 通過範圍區間的方法, 來確定圖片屬於哪一個存儲節點。
可能還有同學會說, 一致性hash也有快取失效的時候,也需要手動遷移數據。 是的, 維基百科對一致性Hash的定義是, 當節點的數量變動時,可以允許少部分的數據進行遷移, 而大部分的數據還是不變的。
上面的一致性Hash演算法其實是經典的哈希環演算法, 當然還有其他的演算法, 比如跳躍一致性哈希法, 有興趣也可以看一下, 以上內容均為個人理解, 如果錯誤, 可以指出, 希望對您有用!
![]()