SQL學習筆記
作者: Grey
原文地址:SQL學習筆記
SQL基礎
註:本文中的SQL語句如果用到了特定方言,都是基於MySQL資料庫。
關於DDL
DDL 的英文全稱是 Data Definition Language,中文是數據定義語言。它定義了資料庫的結構和數據表的結構。在 DDL 中,我們常用的功能是增刪改,分別對應的命令是 CREATE、DROP 和 ALTER。
需要注意的是:在執行 DDL 的時候,不需要 COMMIT,就可以完成執行任務。
排序規則是utf8_general_ci,代表對大小寫不敏感,如果設置為utf8_bin,代表對大小寫敏感。
DISTINCT
DISTINCT 其實是對後面所有列名的組合進行去重
SELECT DISTINCT attack_range, name FROM heros
其實是對(attack_range,name)這個組合去重。
LIMIT
另外在查詢過程中,我們可以約束返回結果的數量,使用 LIMIT 關鍵字。
SELECT name, hp_max FROM heros ORDER BY hp_max DESC LIMIT 5
在不同的 DBMS 中使用的關鍵字可能不同。在 MySQL、PostgreSQL、MariaDB 和 SQLite 中使用 LIMIT 關鍵字,而且需要放到 SELECT 語句的最後面。如果是 SQL Server 和 Access,需要使用 TOP 關鍵字,比如:
SELECT TOP 5 name, hp_max FROM heros ORDER BY hp_max DESC
如果是 DB2,使用FETCH FIRST 5 ROWS ONLY這樣的關鍵字:
SELECT name, hp_max FROM heros ORDER BY hp_max DESC FETCH FIRST 5 ROWS ONLY
如果是 Oracle,你需要基於 ROWNUM 來統計行數:
SELECT name, hp_max FROM heros WHERE ROWNUM <=5 ORDER BY hp_max DESC
需要說明的是,這條語句是先取出來前 5 條數據行,然後再按照 hp_max 從高到低的順序進行排序, 如果這樣寫:
SELECT name, hp_max FROM (SELECT name, hp_max FROM heros ORDER BY hp_max) WHERE ROWNUM <=5
就表示先執行查詢結果,再來過濾結果中的前五條。
WHERE語句中 AND 和 OR優先順序
WHERE 子句中同時出現 AND 和 OR 操作符的時候,你需要考慮到執行的先後順序,也就是兩個操作符執行的優先順序。一般來說 () 優先順序最高,其次優先順序是 AND,然後是 OR。
SQL中的命名規範
MySQL 在 Linux 的環境下,資料庫名、表名、變數名是嚴格區分大小寫的,而欄位名是忽略大小寫的。
而 MySQL 在 Windows 的環境下全部不區分大小寫。
SQL編寫的一個規範:
- 資料庫名、表名、表別名、欄位名、欄位別名等都小寫
- SQL保留字、函數名、綁定變數等都大寫
- 數據表的欄位名推薦採用下劃線命名
- SQL語句必須以分號結尾
COUNT(欄位) , COUNT( * ) 和 COUNT(1)
COUNT(欄位)會忽略欄位值值為 NULL 的數據行,而 COUNT( * ) 和 COUNT(1) 只是統計數據行數,不管某個欄位是否為 NULL。
AVG、MAX、MIN 等聚集函數會自動忽略值為 NULL 的數據行。
關聯子查詢和非關聯子查詢
可以依據子查詢是否執行多次,從而將子查詢劃分為關聯子查詢和非關聯子查詢。子查詢從數據表中查詢了數據結果,如果這個數據結果只執行一次,然後這個數據結果作為主查詢的條件進行執行,那麼這樣的子查詢叫做非關聯子查詢。同樣,如果子查詢需要執行多次,即採用循環的方式,先從外部查詢開始,每次都傳入子查詢進行查詢,然後再將結果回饋給外部,這種嵌套的執行方式就稱為關聯子查詢
一個非關聯子查詢的例子:
SELECT player_name, height FROM player WHERE height = (SELECT max(height) FROM player)
一個關聯子查詢的例子:
SELECT player_name, height, team_id FROM player AS a WHERE height > (SELECT avg(height) FROM player AS b WHERE a.team_id = b.team_id)
(NOT) EXISTS子查詢
SELECT player_id, team_id, player_name FROM player WHERE EXISTS (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id)
IN VS EXISTS
SELECT * FROM A WHERE cc IN (SELECT cc FROM B)
SELECT * FROM A WHERE EXIST (SELECT cc FROM B WHERE B.cc=A.cc)
實際上在查詢過程中,在我們對 cc 列建立索引的情況下,我們還需要判斷表 A 和表 B 的大小。在這裡例子當中,表 A 指的是 player 表,表 B 指的是 player_score 表。如果表 A 比表 B 大,那麼 IN 子查詢的效率要比 EXIST 子查詢效率高,因為這時 B 表中如果對 cc 列進行了索引,那麼 IN 子查詢的效率就會比較高。同樣,如果表 A 比表 B 小,那麼使用 EXISTS 子查詢效率會更高,因為我們可以使用到 A 表中對 cc 列的索引,而不用從 B 中進行 cc 列的查詢。
當 A 小於 B 時,用 EXISTS。因為 EXISTS 的實現,相當於外表循環,實現的邏輯類似於:
for i in A
for j in B
if j.cc == i.cc then ...
當 B 小於 A 時用 IN,因為實現的邏輯類似於:
for i in B
for j in A
if j.cc == i.cc then ...
哪個表小就用哪個表來驅動,A 表小就用 EXISTS,B 表小就用 IN。
其他一些子查詢的關鍵字:EXISTS、IN、ANY、ALL 和 SOME
函數
一個簡單的函數例子:Leetcode 177. Nth Highest Salary
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
SET N = N - 1;
RETURN (
SELECT DISTINCT Salary FROM Employee GROUP BY Salary
ORDER BY Salary DESC LIMIT 1 OFFSET N
);
END
Employee表數據如下:
+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
函數調用:
SELECT getNthHighestSalary(3);
結果:
+------------------------+
| getNthHighestSalary(3) |
+------------------------+
| 100 |
+------------------------+
存儲過程
DELIMITER //
CREATE PROCEDURE `add_num`(IN n INT)
BEGIN
DECLARE i INT;
DECLARE sum INT;
SET i = 1;
SET sum = 0;
WHILE i <= n DO
SET sum = sum + i;
SET i = i +1;
END WHILE;
SELECT sum;
END //
DELIMITER ;
調用
CALL add_num(10);
另一個例子
CREATE PROCEDURE `get_hero_scores`(
OUT max_max_hp FLOAT,
OUT min_max_mp FLOAT,
OUT avg_max_attack FLOAT,
s VARCHAR(255)
)
BEGIN
SELECT MAX(hp_max), MIN(mp_max), AVG(attack_max) FROM heros WHERE role_main = s INTO max_max_hp, min_max_mp, avg_max_attack;
END
調用
CALL get_hero_scores(@max_max_hp, @min_max_mp, @avg_max_attack, '戰士');
SELECT @max_max_hp, @min_max_mp, @avg_max_attack;
自動提交(autocommit)
set autocommit =0; //關閉自動提交
set autocommit =1; //開啟自動提交
CREATE TABLE test(name varchar(255), PRIMARY KEY (name)) ENGINE=InnoDB;
BEGIN;
INSERT INTO test SELECT '關羽';
COMMIT;
BEGIN;
INSERT INTO test SELECT '張飛';
INSERT INTO test SELECT '張飛';
ROLLBACK;
SELECT * FROM test;
“張飛”這條記錄,如果資料庫未開啟自動提交,則不會入庫,如果開啟了自動提交,則第二個」張飛「輸入會回滾不插入,但是第一條」張飛「數據依然會插入。
completion_type
CREATE TABLE test(name varchar(255), PRIMARY KEY (name)) ENGINE=InnoDB;
SET @@completion_type = 1;
BEGIN;
INSERT INTO test SELECT '關羽';
COMMIT;
INSERT INTO test SELECT '張飛';
INSERT INTO test SELECT '張飛';
ROLLBACK;
SELECT * FROM test;
MySQL 中 completion_type 這個參數有 3 種可能:
- completion=0,這是默認情況。也就是說當我們執行 COMMIT 的時候會提交事務,在執行下一個事務時,還需要我們使用 START TRANSACTION 或者 BEGIN 來開啟。
- completion=1,這種情況下,當我們提交事務後,相當於執行了 COMMIT AND CHAIN,也就是開啟一個鏈式事務,即當我們提交事務之後會開啟一個相同隔離級別的事務(隔離級別會在下一節中進行介紹)。
- completion=2,這種情況下 COMMIT=COMMIT AND RELEASE,也就是當我們提交後,會自動與伺服器斷開連接。
事務並發可能產生的異常
- 臟讀(Dirty Read)
讀到了其他事務還沒有提交的數據。
- 不可重複讀(Nnrepeatable Read)
對某數據進行讀取,發現兩次讀取的結果不同,也就是說沒有讀到相同的內容。這是因為有其他事務對這個數據同時進行了修改或刪除。
- 幻讀(Phantom Read)
事務 A 根據條件查詢得到了 N 條數據,但此時事務 B 更改或者增加了 M 條符合事務 A 查詢條件的數據,這樣當事務 A 再次進行查詢的時候發現會有 N+M 條數據,產生了幻讀。
SQL-92 標準還定義了 4 種隔離級別來解決這些異常情況。這些隔離級別能解決的異常情況如下表所示:
| 臟讀 | 不可重複讀 | 幻讀 | |
|---|---|---|---|
| 讀未提交(READ UNCOMMITTED) | 允許 | 允許 | 允許 |
| 讀已提交(READ COMMITTED) | 禁止 | 允許 | 允許 |
| 可重複讀(REPEATABLE READ) | 禁止 | 禁止 | 允許 |
| 可串列化(SERIALIZABLE | 禁止 | 禁止 | 禁止 |
- 讀未提交,也就是允許讀到未提交的數據,這種情況下查詢是不會使用鎖的,可能會產生臟讀、不可重複讀、幻讀等情況。
- 讀已提交就是只能讀到已經提交的內容,可以避免臟讀的產生,屬於 RDBMS 中常見的默認隔離級別(比如說 Oracle 和 SQL Server),但如果想要避免不可重複讀或者幻讀,就需要我們在 SQL 查詢的時候編寫帶加鎖的 SQL 語句
- 可重複讀,保證一個事務在相同查詢條件下兩次查詢得到的數據結果是一致的,可以避免不可重複讀和臟讀,但無法避免幻讀。MySQL 默認的隔離級別就是可重複讀。
- 可串列化,將事務進行串列化,也就是在一個隊列中按照順序執行,可串列化是最高級別的隔離等級,可以解決事務讀取中所有可能出現的異常情況,但是它犧牲了系統的並發性。
查看隔離級別
SHOW VARIABLES LIKE 'transaction_isolation';
配置隔離級別
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
如何使用游標
CREATE PROCEDURE `calc_hp_max`()
BEGIN
-- 創建接收游標的變數
DECLARE hp INT;
-- 創建總數變數
DECLARE hp_sum INT DEFAULT 0;
-- 創建結束標誌變數
DECLARE done INT DEFAULT false;
-- 定義游標
DECLARE cur_hero CURSOR FOR SELECT hp_max FROM heros;
-- 指定游標循環結束時的返回值
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true;
OPEN cur_hero;
read_loop:LOOP
FETCH cur_hero INTO hp;
-- 判斷游標的循環是否結束
IF done THEN
LEAVE read_loop;
END IF;
SET hp_sum = hp_sum + hp;
END LOOP;
CLOSE cur_hero;
SELECT hp_sum;
END
更複雜的一個例子
CREATE PROCEDURE `alter_attack_growth`()
BEGIN
-- 創建接收游標的變數
DECLARE temp_id INT;
DECLARE temp_growth, temp_max, temp_start, temp_diff FLOAT;
-- 創建結束標誌變數
DECLARE done INT DEFAULT false;
-- 定義游標
DECLARE cur_hero CURSOR FOR SELECT id, attack_growth, attack_max, attack_start FROM heros;
-- 指定游標循環結束時的返回值
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true;
OPEN cur_hero;
FETCH cur_hero INTO temp_id, temp_growth, temp_max, temp_start;
REPEAT
IF NOT done THEN
SET temp_diff = temp_max - temp_start;
IF temp_growth < 5 THEN
IF temp_diff > 200 THEN
SET temp_growth = temp_growth * 1.1;
ELSEIF temp_diff >= 150 AND temp_diff <=200 THEN
SET temp_growth = temp_growth * 1.08;
ELSEIF temp_diff < 150 THEN
SET temp_growth = temp_growth * 1.07;
END IF;
ELSEIF temp_growth >=5 AND temp_growth <=10 THEN
SET temp_growth = temp_growth * 1.05;
END IF;
UPDATE heros SET attack_growth = ROUND(temp_growth,3) WHERE id = temp_id;
END IF;
FETCH cur_hero INTO temp_id, temp_growth, temp_max, temp_start;
UNTIL done = true END REPEAT;
CLOSE cur_hero;
END
關於資料庫調優
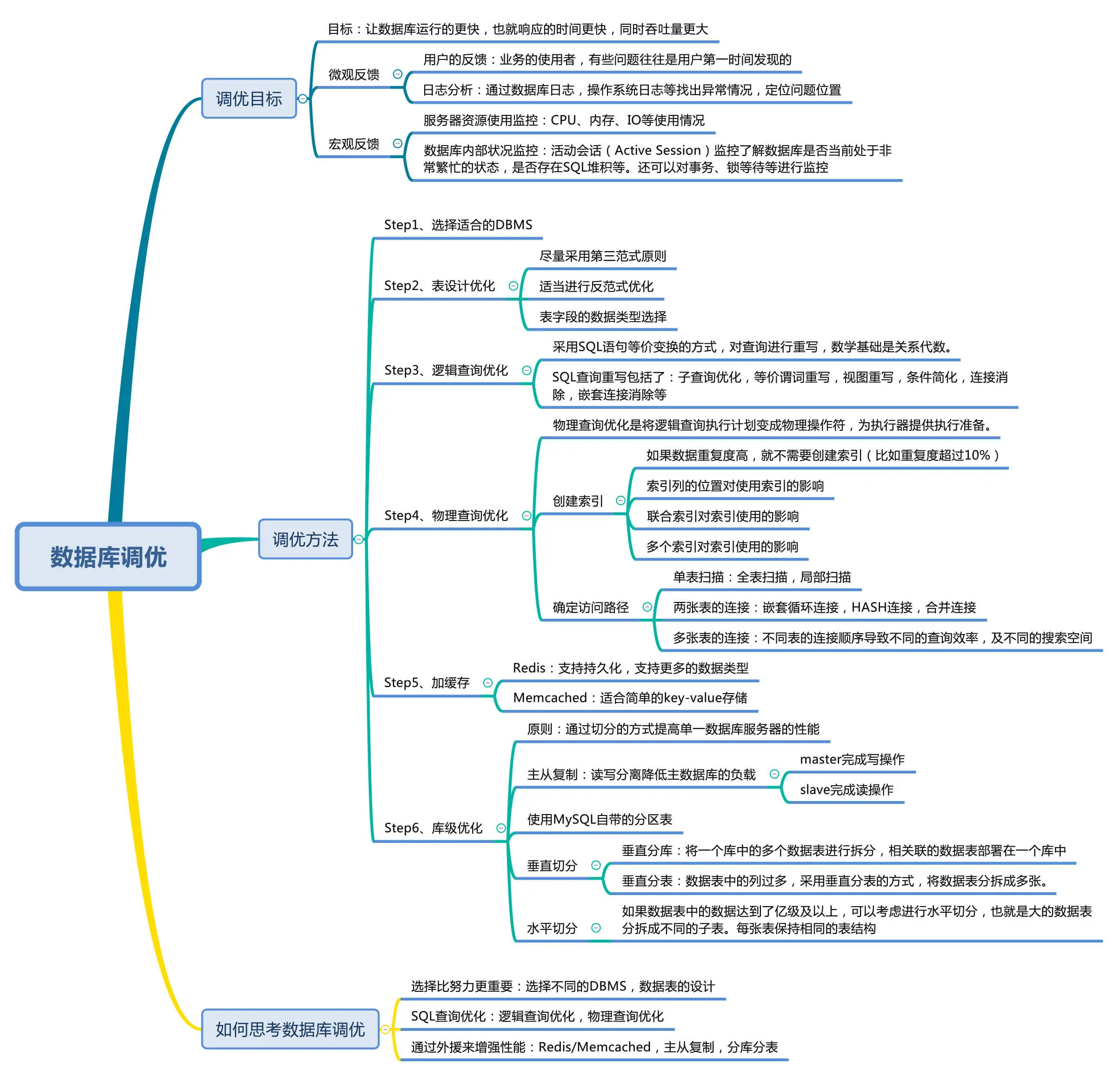
導圖引用自20丨當我們思考資料庫調優的時候,都有哪些維度可以選擇?
關於各種範式
1NF 指的是資料庫表中的任何屬性都是原子性的,不可再分。
2NF 指的數據表裡的非主屬性都要和這個數據表的候選鍵有完全依賴關係。所謂完全依賴不同於部分依賴,也就是不能僅依賴候選鍵的一部分屬性,而必須依賴全部屬性。
一個沒有滿足 2NF 的例子,
一張球員比賽表 player_game,裡面包含球員編號、姓名、年齡、比賽編號、比賽時間和比賽場地等屬性,
這裡候選鍵和主鍵都為:
(球員編號,比賽編號),
我們可以通過候選鍵來決定如下的關係:
(球員編號, 比賽編號) → (姓名, 年齡, 比賽時間, 比賽場地,得分)
上面這個關係說明球員編號和比賽編號的組合決定了球員的姓名、年齡、比賽時間、比賽地點和該比賽的得分數據。
但是這個數據表不滿足第二範式,因為數據表中的欄位之間還存在著如下的對應關係:
(球員編號) → (姓名,年齡)
(比賽編號) → (比賽時間, 比賽場地)
也就是說候選鍵中的某個欄位決定了非主屬性。
插入異常:如果我們想要添加一場新的比賽,但是這時還沒有確定參加的球員都有誰,那麼就沒法插入。
刪除異常:如果我要刪除某個球員編號,如果沒有單獨保存比賽表的話,就會同時把比賽資訊刪除掉。
更新異常:如果我們調整了某個比賽的時間,那麼數據表中所有這個比賽的時間都需要進行調整,否則就會出現一場比賽時間不同的情況。
3NF 在滿足 2NF 的同時,對任何非主屬性都不傳遞依賴於候選鍵。也就是說不能存在非主屬性 A 依賴於非主屬性 B,非主屬性 B 依賴於候選鍵的情況。比如:
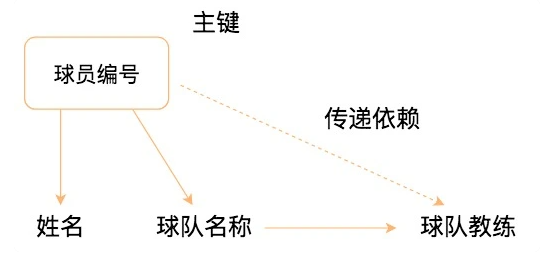
你能看到球員編號決定了球隊名稱,同時球隊名稱決定了球隊主教練,非主屬性球隊主教練就會傳遞依賴於球員編號,因此不符合 3NF 的要求。
索引的分類
功能上分:普通索引,唯一索引,主鍵索引,全文索引
物理結構上:聚集索引(順序)和非聚集索引(非順序),類比鏈表和數組的區別。
欄位上分:單一索引和聯合索引(最左匹配原則)
-
聚集索引的葉子節點存儲的就是我們的數據記錄,非聚集索引的葉子節點存儲的是數據位置。非聚集索引不會影響數據表的物理存儲順序。
-
一個表只能有一個聚集索引,因為只能有一種排序存儲的方式,但可以有多個非聚集索引,也就是多個索引目錄提供數據檢索。
-
使用聚集索引的時候,數據的查詢效率高,但如果對數據進行插入,刪除,更新等操作,效率會比非聚集索引低。實驗 3:使用聚集索引和非聚集


