系統調研450篇文獻,微軟亞洲研究院推出超詳盡語音合成綜述
- 2021 年 8 月 13 日
- AI

作者 | 譚旭
文本到語音合成旨在從文本合成高可懂度和自然度的語音,很久以來一直是語言、語音、深度學習、人工智慧等領域熱門的研究方向,受到了學術界和工業界的廣泛關注。近年來,隨著深度學習的發展,基於神經網路的語音合成極大地提高了合成語音的品質。儘管語音合成技術的研究已有幾十年的歷史,基於神經網路的語音合成技術也有近十年的發展,領域內產出了大量的優質研究成果,但針對不同研究方向的整合型綜述論文卻十分匱乏。
因此,微軟亞洲研究院的研究員們發表了一篇綜述論文 「A Survey on Neural Speech Synthesis」,全面梳理、總結了神經語音合成領域的發展現狀以及未來發展方向。該文章可謂是迄今為止語音合成領域幾乎最為詳盡的綜述論文。研究員們共調研了450多篇文獻,分別從語音合成的核心模組(文本分析、聲學模型、聲碼器)以及進階主題(快速語音合成、低資源語音合成、魯棒語音合成、富有表現力的語音合成、可適配語音合成)兩大方面對該領域的工作進行了梳理總結。同時,研究員們還收集了語音合成領域的相關資源(數據集、開源實現、演講教程等)並且討論了未來研究方向。

論文鏈接://arxiv.org/pdf/2106.15561.pdf
論文從兩個方面對神經語音合成領域的發展現狀進行了梳理總結(邏輯框架如圖1所示):
-
核心模組:分別從文本分析(textanalysis)、聲學模型(acoustic model)、聲碼器(vocoder)、完全端到端模型(fully end-to-end model)等方面進行介紹。
-
進階主題:分別從快速語音合成(fast TTS)、低資源語音合成(low-resourceTTS)、魯棒語音合成(robust TTS)、富有表現力的語音合成(expressive TTS)、可適配語音合成(adaptive TTS)等方面進行介紹。

圖1:論文邏輯框架
1
TTS核心模組
研究員們根據神經語音合成系統的核心模組提出了一個分類體系。每個模組分別對應特定的數據轉換流程:
1)文本分析模組將文本字元轉換成音素或語言學特徵;
2)聲學模型將語言學特徵、音素或字元序列轉換成聲學特徵;
3)聲碼器將語言學特徵或聲學特徵轉換成語音波形;
4)完全端到端模型將字元或音素序列轉換成語音波形。


圖2:(a)TTS核心框架,(b)數據轉換流程
文本分析
文章總結了文本分析模組幾個常見的任務,包括文本歸一化、分詞、詞性標註、韻律預測、字形轉音形以及多音字消歧等。

表1:文本分析模組中的常見任務
聲學模式
在聲學模型部分,文章首先簡要介紹了在統計參數合成里用到的基於神經網路的聲學模型,然後重點介紹了端到端模型的神經聲學模型,包括基於 RNN、CNN 和Transformer 的聲學模型以及其它基於 Flow、GAN、VAE、Diffusion 的聲學模型。

表2:不同聲學模型及其特徵
聲碼器
聲碼器的發展分為兩個階段,包括傳統參數合成里的聲碼器如 STRAIGHT和 WORLD,以及基於神經網路的聲碼器。論文重點介紹了基於神經網路的聲碼器,並把相關工作分為以下幾類,包括:
1)自回歸聲碼器(WaveNet,SampleRNN,WaveRNN,LPCNet 等);
2)基於 Flow 的聲碼器(WaveGlow,FloWaveNet,WaveFlow,Par. WaveNet 等);
3)基於 GAN 的聲碼器(WaveGAN,GAN-TTS,MelGAN,Par. WaveGAN,HiFi-GAN,VocGAN,GED,Fre-GAN 等);
4)基於 VAE 的聲碼器(WaveVAE等);
5)基於 Diffusion 的聲碼器(DiffWave,WaveGrad,PriorGrad 等)。
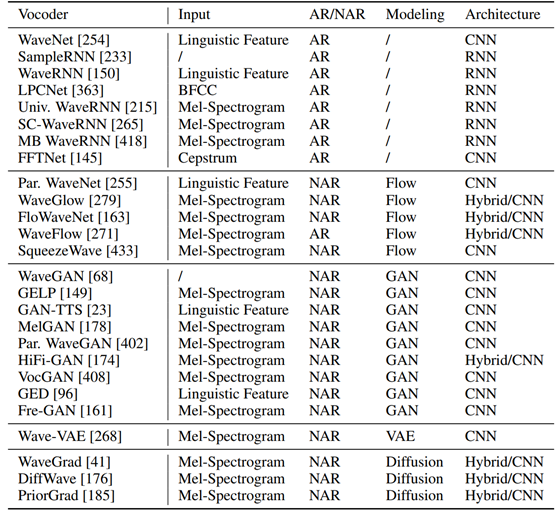
表3:不同聲碼器及其特徵
本文還針對基於 Flow 和 GAN 的聲碼器做了詳細分析,如表4和表5所示。


表5:基於GAN的聲碼器
最後研究員們還統一分析、比較了基於不同生成模型的聲碼器的優缺點,如表6所示。

表6:基於不同生成模型的聲碼器分析結果
完全端到端模型
端到端模型的發展經歷了以下幾個階段:
階段0:在統計參數合成方法中,使用文本分析、聲學模型和聲碼器三個模組級聯;
階段1:在統計參數合成方法中,將前兩個模組合起來形成一個聲學模型;
階段2:直接從語言學特徵生成最終的波形,例如 WaveNet;
階段3:聲學模型直接從字元或音素生成聲學模型,然後利用神經聲碼器生成波形;
階段4:完全端到端的神經網路模型。

圖3:端到端模型發展過程
其它分類體系
除了上述按照 TTS 模型的核心模組進行分類的方法,論文中還有從其它角度對 TTS 模型進行分類的方法,如圖4所示,包括:1)自回歸 vs 非自回歸;2)生成模型的類型;3)網路結構的類型。

圖4:從其它角度對TTS模型進行分類
同時,本文還繪製了相關 TTS 工作隨著時間變化的關係圖,方便讀者更直觀地理解各個 TTS 模型及其在 TTS 發展中的位置。

圖5:相關 TTS 工作隨時間演化的關係圖
2
TTS 進階課題
研究員們還針對 TTS 面臨的各種挑戰,介紹了相關的進階課題,包括快速語音合成(fast TTS)、低資源語音合成(low-resource TTS)、魯棒語音合成(robust TTS)、富有表現力的語音合成(expressive TTS)、可適配語音合成(adaptive TTS)等。

圖6:TTS 相關的進階課題
快速語音合成
為了實現快速語音合成,常用的技術一般有以下幾種:1)並行生成;2)輕量級模型設計;3)利用領域知識進行加速。其中,並行生成技術的分類以及相關工作可見表7。

表7:並行生成技術的分類以及相關工作
低資源語音合成
低資源語音合成相關技術以及相關工作,如表8所示。

表8:低資源語音合成相關技術以及相關工作
魯棒語音合成
魯棒語音合成相關技術分類,可見表9。

表9:魯棒語音合成相關技術分類
富有表現力的語音合成
富有表現力的語音合成的關鍵在於對可變資訊的建模,表10從不同角度總結了可變資訊建模的相關工作。

表10:富有表現力的語音合成
可適配語音合成
可適配語音合成相關的技術分類見表11。

表11:可適配語音合成
最後,研究員們還收集了 TTS 領域相關的資源,包括開源程式碼、TTS 教程、公開比賽以及數據集等。同時,文章也指出了 TTS 領域的潛在研究挑戰,並且根據 TTS 要實現的最終遠景和目標,將其分為兩個大方向:高品質的語音合成以及高效率的語音合成。
在高品質的語音合成方面,包括以下研究課題:更加強大的生成模型,更好的面向文本和語音的表徵學習,魯棒的語音合成,富有表現力/可控/風格可遷移的語音合成,更符合人類表達風格的語音合成。在更高效的語音合成方面,包括在數據、模型參數、計算等方面設計更高效、利用資源更少的語音合成系統。
相關鏈接:
//www.microsoft.com/en-us/research/project/text-to-speech/
//speechresearch.github.io/
//www.microsoft.com/en-us/research/people/xuta/


