Kubernetes的基本概念和術語
- 2021 年 8 月 5 日
- 筆記
- Kubernetes
Kubernetes中的大部分概念如Node、Pod、Replication Controller、 Service等都可以被看作一種資源對象,幾乎所有資源對象都可以通過 Kubernetes提供的kubectl工具(或者API編程調用)執行增、刪、改、查 等操作並將其保存在etcd中持久化存儲。從這個角度來看,Kubernetes 其實是一個高度自動化的資源控制系統,它通過跟蹤對比etcd庫里保存 的「資源期望狀態」與當前環境中的「實際資源狀態」的差異來實現自動控制和自動糾錯的高級功能。
Kubernetes中重要的資源對象
1.1 Master
Kubernetes里的Master指的是集群控制節點,在每個Kubernetes集群里都需要有一個Master來負責整個集群的管理和控制,基本上 Kubernetes的所有控制命令都發給它,它負責具體的執行過程,我們後面執行的所有命令基本都是在Master上運行的。Master通常會佔據一個獨立的伺服器(高可用部署建議用3台伺服器),主要原因是它太重要了,是整個集群的「首腦」,如果它宕機或者不可用,那麼對集群內容器應用的管理都將失效。
Master上運行著以下關鍵進程
-
Kubernetes API Server(kube-apiserver):提供了HTTP Rest介面的關鍵服務進程,是Kubernetes里所有資源的增、刪、改、查等操作的唯一入口,也是集群控制的入口進程。
-
Kubernetes Controller Manager(kube-controller-manager):Kubernetes里所有資源對象的自動化控制中心,可以將其理解為資源對象的「大總管」。
-
Kubernetes Scheduler(kube-scheduler):負責資源調度(Pod調度)的進程,相當於公交公司的「調度室」。
1.2 Node
除了Master,Kubernetes集群中的其他機器被稱為Node,在較早的 版本中也被稱為Minion。與Master一樣,Node可以是一台物理主機,也 可以是一台虛擬機。Node是Kubernetes集群中的工作負載節點,每個 Node都會被Master分配一些工作負載(Docker容器),當某個Node宕機 時,其上的工作負載會被Master自動轉移到其他節點上。
每個Node上都運行著以下關鍵進程
- kubelet:負責Pod對應的容器的創建、啟停等任務,同時與 Master密切協作,實現集群管理的基本功能。
- kube-proxy:實現Kubernetes Service的通訊與負載均衡機制的重要組件。
- Docker Engine(docker):Docker引擎,負責本機的容器創建 和管理工作。
Node可以在運行期間動態增加到Kubernetes集群中,前提是在這個 節點上已經正確安裝、配置和啟動了上述關鍵進程,在默認情況下 kubelet會向Master註冊自己,這也是Kubernetes推薦的Node管理方式。 一旦Node被納入集群管理範圍,kubelet進程就會定時向Master彙報自身 的情報,例如作業系統、Docker版本、機器的CPU和記憶體情況,以及當 前有哪些Pod在運行等,這樣Master就可以獲知每個Node的資源使用情 況,並實現高效均衡的資源調度策略。而某個Node在超過指定時間不上 報資訊時,會被Master判定為「失聯」,Node的狀態被標記為不可用 (Not Ready),隨後Master會觸發「工作負載大轉移」的自動流程。
從創建 deployment 開始

deployment 是用於編排 pod 的一種控制器資源,我們會在後面做介紹。這裡以 deployment 為例,來看看架構中的各組件在創建 deployment 資源的過程中都幹了什麼。
- 1.首先是 kubectl 發起一個創建 deployment 的請求
- 2.apiserver 接收到創建 deployment 請求,將相關資源寫入 etcd;之後所有組件與 apiserver/etcd 的交互都是類似的
- 3.deployment controller list/watch 資源變化並發起創建 replicaSet 請求
- 4.replicaSet controller list/watch 資源變化並發起創建 pod 請求
- 5.scheduler 檢測到未綁定的 pod 資源,通過一系列匹配以及過濾選擇合適的 node 進行綁定
- 6.kubelet 發現自己 node 上需創建新 pod,負責 pod 的創建及後續生命周期管理
- 7.kube-proxy 負責初始化 service 相關的資源,包括服務發現、負載均衡等網路規則
至此,經過 kubenetes 各組件的分工協調,完成了從創建一個 deployment 請求開始到具體各 pod 正常運行的全過程。
Pod
在 kubernetes 眾多的 api 資源中,pod 是最重要和基礎的,是最小的部署單元。
首先我們要考慮的問題是,我們為什麼需要 pod?pod 可以說是一種容器設計模式,它為那些」超親密」關係的容器而設計,我們可以想像 servelet 容器部署 war 包、日誌收集等場景,這些容器之間往往需要共享網路、共享存儲、共享配置,因此我們有了 pod 這個概念。
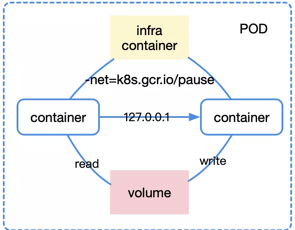
對於 pod 來說,不同 container 之間通過 infra container 的方式統一識別外部網路空間,而通過掛載同一份 volume 就自然可以共享存儲了,比如它對應宿主機上的一個目錄。
容器編排
容器編排是 kubernetes 的看家本領了,所以我們有必要了解一下。kubernetes 中有諸多編排相關的控制資源,例如編排無狀態應用的 deployment,編排有狀態應用的 statefulset,編排守護進程 daemonset 以及編排離線業務的 job/cronjob 等等。
我們還是以應用最廣泛的 deployment 為例。deployment、replicatset、pod 之間的關係是一種層層控制的關係。簡單來說,replicaset 控制 pod 的數量,而 deployment 控制 replicaset 的版本屬性。這種設計模式也為兩種最基本的編排動作實現了基礎,即數量控制的水平擴縮容、版本屬性控制的更新/回滾。
水平擴縮容

水平擴縮容非常好理解,我們只需修改 replicaset 控制的 pod 副本數量即可,比如從 2 改到 3,那麼就完成了水平擴容這個動作,反之即水平收縮。
滾動更新
我們更新應用,pod 總是一個一個升級,並且最小有 2 個 pod 處於可用狀態,最多有 4 個 pod 提供服務。這種」滾動更新」的好處是顯而易見的,一旦新的版本有了 bug,那麼剩下的 2 個 pod 仍然能夠提供服務,同時方便快速回滾。
在實際應用中我們可以通過配置 RollingUpdateStrategy 來控制滾動更新策略,maxSurge 表示 deployment 控制器還可以創建多少個新 Pod;而 maxUnavailable 指的是,deployment 控制器可以刪除多少箇舊 Pod。
kubernetes 中的網路
我們了解了容器編排是怎麼完成的,那麼容器間的又是怎麼通訊的呢?
講到網路通訊,kubernetes 首先得有」三通」基礎:
- node 到 pod 之間可以通
- node 的 pod 之間可以通
- 不同 node 之間的 pod 可以通

簡單來說,不同 pod 之間通過 cni0/docker0 網橋實現了通訊,node 訪問 pod 也是通過 cni0/docker0 網橋通訊即可。
而不同 node 之間的 pod 通訊有很多種實現方案,包括現在比較普遍的 flannel 的 vxlan/hostgw 模式等。flannel 通過 etcd 獲知其他 node 的網路資訊,並會為本 node 創建路由表,最終使得不同 node 間可以實現跨主機通訊。
微服務—service
在了解接下來的內容之前,我們得先了解一個很重要的資源對象:service。
我們為什麼需要 service 呢?在微服務中,pod 可以對應實例,那麼 service 對應的就是一個微服務。而在服務調用過程中,service 的出現解決了兩個問題:
- pod 的 ip 不是固定的,利用非固定 ip 進行網路調用不現實
- 服務調用需要對不同 pod 進行負載均衡
service 通過 label 選擇器選取合適的 pod,構建出一個 endpoints,即 pod 負載均衡列表。實際運用中,一般我們會為同一個微服務的 pod 實例都打上類似app=xxx的標籤,同時為該微服務創建一個標籤選擇器為app=xxx的 service。
kubernetes 中的服務發現與網路調用
在有了上述」三通」的網路基礎後,我們可以開始微服務架構中的網路調用在 kubernetes 中是怎麼實現的了。
這部分內容其實在說說 Kubernetes 是怎麼實現服務發現的已經講得比較清楚了,比較細節的地方可以參考上述文章,這裡做一個簡單的介紹。
服務間調用
首先是東西向的流量調用,即服務間調用。這部分主要包括兩種調用方式,即 clusterIp 模式以及 dns 模式。
clusterIp 是 service 的一種類型,在這種類型模式下,kube-proxy 通過 iptables/ipvs 為 service 實現了一種 VIP(虛擬 ip)的形式。只需要訪問該 VIP,即可負載均衡地訪問到 service 背後的 pod。

上圖是 clusterIp 的一種實現方式,此外還包括 userSpace 代理模式(基本不用),以及 ipvs 模式(性能更好)。
dns 模式很好理解,對 clusterIp 模式的 service 來說,它有一個 A 記錄是 service-name.namespace-name.svc.cluster.local,指向 clusterIp 地址。所以一般使用過程中,我們直接調用 service-name 即可。
服務外訪問

南北向的流量,即外部請求訪問 kubernetes 集群,主要包括三種方式:nodePort、loadbalancer、ingress。
nodePort 同樣是 service 的一種類型,通過 iptables 賦予了調用宿主機上的特定 port 就能訪問到背後 service 的能力。
loadbalancer 則是另一種 service 類型,通過公有雲提供的負載均衡器實現。
我們訪問 100 個服務可能需要創建 100 個 nodePort/loadbalancer。我們希望通過一個統一的外部接入層訪問內部 kubernetes 集群,這就是 ingress 的功能。ingress 提供了統一接入層,通過路由規則的不同匹配到後端不同的 service 上。ingress 可以看做是」service 的 service」。ingress 在實現上往往結合 nodePort 以及 loadbalancer 完成功能。

