終於徹底搞清楚了 MySQL spin-lock 之一次CPU問題定位過程總結
首先這個問題,我只是其中參與者之一。但這個問題很有參考意義,特記錄下來。
還有我第一次用「徹底」這個詞,不知道會不會有人噴?其實,還有一些問題,也不是特別清楚。比如說什麼是CPU流水(我又不是硬體工程師)。
問題現象
MySQL現網資料庫切換到新的物理伺服器時,出現了業務查詢超時異常問題。
詳細過程不再熬述了,總之對比新舊硬體環境的不同。初步懷疑是新伺服器CPU的問題。
定位過程
現網肯定不能不停重試,於是在本地伺服器用sysbench壓測。
查看CPU佔比,sys佔比特別高。vmstat顯示context switch高。
通過perf top查看調用棧。
調用棧如下。
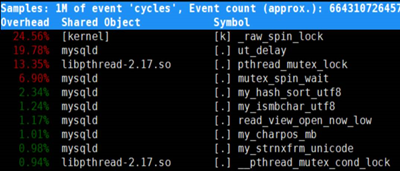
問題原因
如上,可以看到調用棧,spin_lock佔用了很大比例。
與美團的CPU原因類似。因為某些你懂的原因,具體細節就不多說了。因為我主要是講解一下何為spin lock。
而且看完全篇,你就會發現其實內容遠比你想像中的多。
//dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_spin_wait_pause_multiplier
什麼是自旋鎖
多執行緒中,對共享資源進行訪問,為了防止並發引起的相關問題,通常都是引入鎖的機制來處理並發問題。
獲取到資源的執行緒A對這個資源加鎖,其他執行緒比如B要訪問這個資源首先要獲得鎖,而此時A持有這個資源的鎖,只有等待執行緒A邏輯執行完,釋放鎖,這個時候B才能獲取到資源的鎖進而獲取到該資源。
這個過程中,A一直持有著資源的鎖,那麼沒有獲取到鎖的其他執行緒比如B怎麼辦?通常就會有兩種方式:
1. 一種是沒有獲得鎖的進程就直接進入阻塞(BLOCKING),這種就是互斥鎖
2. 另外一種就是沒有獲得鎖的進程,不進入阻塞,而是一直循環著,看是否能夠等到A釋放了資源的鎖。
自旋鎖(spin lock)是一種非阻塞鎖,也就是說,如果某執行緒需要獲取鎖,但該鎖已經被其他執行緒佔用時,該執行緒不會被掛起,而是在不斷的消耗CPU的時間,不停的試圖獲取鎖。
自旋鎖避免了進程上下文的調度開銷,因此對於執行緒只會阻塞很短時間的場合是有效的。因此作業系統的實現在很多地方往往用自旋鎖。
為什麼要使用自旋鎖
互斥鎖有一個缺點,他的執行流程是這樣的 託管程式碼 – 用戶態程式碼 – 內核態程式碼、上下文切換開銷與損耗,假如獲取到資源鎖的執行緒A立馬處理完邏輯釋放掉資源鎖,如果是採取互斥的方式,那麼執行緒B從沒有獲取鎖到獲取鎖這個過程中,就要用戶態和內核態調度、上下文切換的開銷和損耗。所以就有了自旋鎖的模式,讓執行緒B就在用戶態循環等著,減少消耗。
自旋鎖的本質
Critical Section Integration (CSI)
本質上自旋鎖產生的效果就是一個CPU core 按順序逐一執行關鍵區域的程式碼,所以在我們的優化程式碼中將關鍵區域的程式碼以函數的形式表現出來,當執行緒搶鎖的時候,如果發現有衝突,那麼就將自己的函數掛在鎖擁有者的隊列上,然後使用MCS進入spinning 狀態,而鎖擁有者在執行完自己的關鍵區域之後,會檢測是否還有其他鎖的請求,如果有那麼依次執行並且通知申請者,然後返回。可以看到通過這個方法所有的共享數據更新都是在CPU私用快取內完成,能夠大幅度減少共享數據的遷移,由於減少了遷移時間,那麼加快了關鍵區域運行時間最終也減少了衝突可能性。
提升自旋鎖spinlock的性能-pause指令
自旋鎖 pause版權看源碼的時候get的一個新的知識點,可以提升自旋鎖spinlock的性能-pause指令,看到的源碼如下:
# define UT_RELAX_CPU() asm (“pause” )
# define UT_RELAX_CPU() __asm__ __volatile__ (“pause”)
經過上網查找資料pause指令。當spinlock執行lock()獲得鎖失敗後會進行busy loop,不斷檢測鎖狀態,嘗試獲得鎖。這麼做有一個缺陷:頻繁的檢測會讓流水線上充滿了讀操作。另外一個執行緒往流水線上丟入一個鎖變數寫操作的時候,必須對流水線進行重排,因為CPU必須保證所有讀操作讀到正確的值。流水線重排十分耗時,影響lock()的性能。
自旋鎖spinlock剖析與改進Pause指令解釋(from intel):Description Improves the performance of spin-wait loops. When executing a 「spin-wait loop,」 a Pentium 4 or Intel Xeon processor suffers a severe performance penalty when exiting the loop because it detects a possible memory order violation. The PAUSE instruction provides a hint to the processor that the code sequence is a spin-wait loop. The processor uses this hint to avoid the memory order violation in most situations, which greatly improves processor performance. For this reason, it is recommended that a PAUSE instruction be placed in all spin-wait loops.
MySQL spin lock處理程式碼
MySQL關於spin lock的部分程式碼。如下程式碼可以看到MySQL默認作了30次(innodb_sync_spin_loops=30)mutex檢查後,才放棄佔用CPU資源。
rw_lock_sx_lock_func( // 加sx鎖函數 { /* Spin waiting for the lock_word to become free */ os_rmb; while (i < srv_n_spin_wait_rounds && lock->lock_word <= X_LOCK_HALF_DECR) { if (srv_spin_wait_delay) { ut_delay(ut_rnd_interval( 0, srv_spin_wait_delay)); // 加鎖失敗,調用ut_delay } i++; } spin_count += i; if (i >= srv_n_spin_wait_rounds) { os_thread_yield(); //暫停當前正在執行的執行緒對象(及放棄當前擁有的cup資源) } else { goto lock_loop; //MySQL關於spin lock的部分程式碼。如下程式碼可以看到MySQL默認作了30次(innodb_sync_spin_loops=30)mutex檢查後,才放棄佔用CPU資源。 os_thread_yield(); //暫停當前正在執行的執行緒對象(及放棄當前擁有的cup資源) } ... ulong srv_n_spin_wait_rounds = 30; ulong srv_spin_wait_delay = 6;
註:上面程式碼,執行緒中的yield()方法說明
yield 多執行緒版權Thread.yield()方法作用是:暫停當前正在執行的執行緒對象(及放棄當前擁有的cup資源),並執行其他執行緒。yield()做的是讓當前運行執行緒回到可運行狀態,以允許具有相同優先順序的其他執行緒獲得運行機會。因此,使用yield()的目的是讓相同優先順序的執行緒之間能適當的輪轉執行。
每次ut_delay默認執行pause指令300次( innodb_spin_wait_delay=6*50)
ut_delay( /*=====*/ ulint delay) /*!< in: delay in microseconds on 100 MHz Pentium */ { ulint i, j; UT_LOW_PRIORITY_CPU(); j = 0; for (i = 0; i < delay * 50; i++) { j += i; UT_RELAX_CPU(); } UT_RESUME_PRIORITY_CPU(); return(j); } # define UT_RELAX_CPU() asm ("pause" ) # define UT_RELAX_CPU() __asm__ __volatile__ ("pause")
作業系統中,SYS和USER這兩個不同的利用率代表著什麼?
作業系統中,SYS和USER這兩個不同的利用率代表著什麼?或者說二者有什麼區別?
簡單來說,CPU利用率中的SYS部分,指的是作業系統內核(Kernel)使用的CPU部分,也就是運行在內核態的程式碼所消耗的CPU,最常見的就是系統調用(SYS CALL)時消耗的CPU。而USER部分則是應用軟體自己的程式碼使用的CPU部分,也就是運行在用戶態的程式碼所消耗的CPU。比如ORACLE在執行SQL時,從磁碟讀數據到db buffer cache,需要發起read調用,這個read調用主要是由作業系統內核包括設備驅動程式的程式碼在運行,因此消耗CPU計算到SYS部分;而ORACLE在解析從磁碟中讀到的數據時,則只是ORACLE自己的程式碼在運行,因此消耗的CPU計算到USER部分。
那麼SYS部分的CPU主要會由哪些操作或是系統調用產生呢?具體如下所示。
1> I/O操作。比如讀寫文件、訪問外設、通過網路傳輸數據等。這部分操作一般不會消耗太多的CPU,因為主要的時間消耗會在1/O操作的設備上。比如從磁碟讀文件時,主要的時間在磁碟內部的操作上,而消耗的CPU時間只佔I/O操作響應時間的一少部分。只有在過高的並發I/O時才可能會使得SYS CPU 有所增加。
2> 記憶體管理。比如應用程式向作業系統申請記憶體,作業系統維護系統可用記憶體,交換空間換頁等。其實與ORACLE類似,越大的記憶體,越頻繁的記憶體管理操作,CPU的消耗會越高。
3> 進程調度。這部分CPU的使用,在於作業系統中運行隊列的長短,越長的運行隊列,表明越多的進程需要調度,那麼內核的負擔就越高。
4> 其他,包括進程間通訊、訊號量處理、設備驅動程式內部的一些活動等等。
什麼是用戶態?什麼是內核態?如何區分?
一般現代CPU都有幾種不同的指令執行級別。
在高執行級別下,程式碼可以執行特權指令,訪問任意的物理地址,這種CPU執行級別就對應著內核態。
而在相應的低級別執行狀態下,程式碼的掌控範圍會受到限制。只能在對應級別允許的範圍內活動。
舉例:
intel x86 CPU有四種不同的執行級別0-3,linux只使用了其中的0級和3級分別來表示內核態和用戶態。

系統調用與context switch
進程上下文切換,是指從一個進程切換到另一個進程運行。而系統調用過程中一直是同一個進程在運行
系統調用過程通常稱為特權模式切換,而不是上下文切換。當進程調用系統調用或者發生中斷時,CPU從用戶模式(用戶態)切換成內核模式(內核態),此時,無論是系統調用程式還是中斷服務程式,都處於當前進程的上下文中,並沒有發生進程上下文切換。
當系統調用或中斷處理程式返回時,CPU要從內核模式切換回用戶模式,此時會執行作業系統的調用程式。如果發現就需隊列中有比當前進程更高的優先順序的進程,則會發生進程切換:當前進程資訊被保存,切換到就緒隊列中的那個高優先順序進程;否則,直接返回當前進程的用戶模式,不會發生上下文切換。
system call
System calls in most Unix-like systems are processed in kernel mode, which is accomplished by changing the processor execution mode to a more privileged one, but no process context switch is necessary
context switch
Some operating systems(Not include Linux) also require a context switch to move between user mode and kernel mode tasks. The process of context switching can have a negative impact on system performance
通過vmstat查看context switch
一般vmstat工具的使用是通過兩個數字參數來完成的,第一個參數是取樣的時間間隔數,單位是秒,第二個參數是取樣的次數,如:
root@local:~# vmstat 2 1
procs ———–memory———- —swap– —–io—- -system– —-cpu—-
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 3498472 315836 3819540 0 0 0 1 2 0 0 0 100 0

context switch 高,導致的爭用其它案例
有很多種情況都會導致 context switch。MySQL 中的 mutex 和 RWlock 在獲取不成功後,短暫spin,還不成功,就會發生 context switch,sleep,等待喚醒。
在 MySQL中,mutex 和 RWlock導致的 context switch,一般在show global status,show engine innodb mutex,show engine innodb status,performance_schema等中會體現出來,針對不同的mutex和RWlock等待,可以採取不同的優化措施。
除了MySQL的mutex和RWlock,還發現一種情況,是MySQL外的mutex競爭導致context switch高。
典型癥狀:
MySQL running 高,但系統 qps、tps 低
系統context switch很高,每秒超過200K
在 MySQL 記憶體查不到mutex和RWlock競爭資訊
SYS CPU 高,USER CPU 低
並發執行的SQL中出現timestamp欄位,MySQL的time_zone設置為system
分析
對於使用 timestamp 的場景,MySQL 在訪問 timestamp 欄位時會做時區轉換,當 time_zone 設置為 system 時,MySQL 訪問每一行的 timestamp 欄位時,都會通過 libc 的時區函數,獲取 Linux 設置的時區,在這個函數中會持有mutex,當大量並發SQL需要訪問 timestamp 欄位時,會出現 mutex 競爭。
MySQL 訪問每一行都會做這個時區轉換,轉換完後釋放mutex,所有等待這個 mutex 的執行緒全部喚醒,結果又會只有一個執行緒會成功持有 mutex,其餘又會再次sleep,這樣就會導致 context switch 非常高但 qps 很低,系統吞吐量急劇下降。
解決辦法:設置time_zone=』+8:00』,這樣就不會訪問 Linux 系統時區,直接轉換,避免了mutex問題。
問題解決對策
通過修改spin lock相應參數,問題現象得到了緩解。
至於CPU硬體本身是不是有可能存在問題,這個是留待他人解決吧。
可不能走自己的路,讓他人無路可走。
總結
spin lock通過pause指令強制佔有CPU,而使自己不被換出CPU,減少context switch發生的頻率。從而實現系統的高效運行。
此例問題的原因是因為新的物理伺服器的CPU PAUSE指令周期遠小於舊的物理伺服器。導致CPU context switch顯著高於舊的伺服器,從而影響user的運行(表象為查詢超時)。
一兩句話,能說清楚的問題,我居然說了這麼多。看來,能把簡單的事情,說複雜也是一種本事。哈哈。
參考資料
實在是太多了,就不列出來了。在此感謝那些提供了資訊分享的朋友們。如引用了您的原文,但沒有指出出處,還請見諒。

