分散式事務理論加實戰
分散式事務
為什麼需要分散式事務
隨著互聯網的快速發展,業務越來越複雜,一個完整的業務往往需要調用多個子服務,涉及的數據也越來越多。傳統的系統難以支撐,就出現了分散式系統,而分散式系統又帶來了數據一致性的問題,從而產生了分散式事務。

什麼叫分散式事務
分散式條件下,多個節點操作的整體事務一致性。
特別是在微服務場景下,業務A和業務B關聯,如果事務A成功了,事務B失敗了。由於跨系統,事務B無法通知到事務A,就造成了數據的不一致。
如何實現分散式下的一致性
-
強一致性
- XA
-
弱一致性
- 不用事務,業務側補償沖正
- 柔性事務,使用一套事務框架保證最終一致性的事務。
一、強一致性事務
1. XA分散式事務
在學習XA之前,我們先了解一下DTP模型,該模型規範了分散式事務的模型設計

- 應用程式(Application Program):定義事務邊界(即事務的開始和結束),並且在事務邊界內對資源進行操作
- 資源管理器(Resource Manager):如資料庫、文件系統等。並提供訪問資源的方式
- 事務管理器(Transaction Manager):負責分配事務唯一標識,監控事務的執行進度,並負責事務的提交、回滾等。
XA協議 是由 X/Open 組織提出的,作為資源管理器與事務管理器的介面標準.目前Oracle、DB2、MySQL的InnoDB存儲引擎都對XA進行了支援。XA介面提供資源管理器與事務管理器之間進行通訊的標準介面。XA協議包括兩套函數,以xa_開頭的及以ax_開頭的。

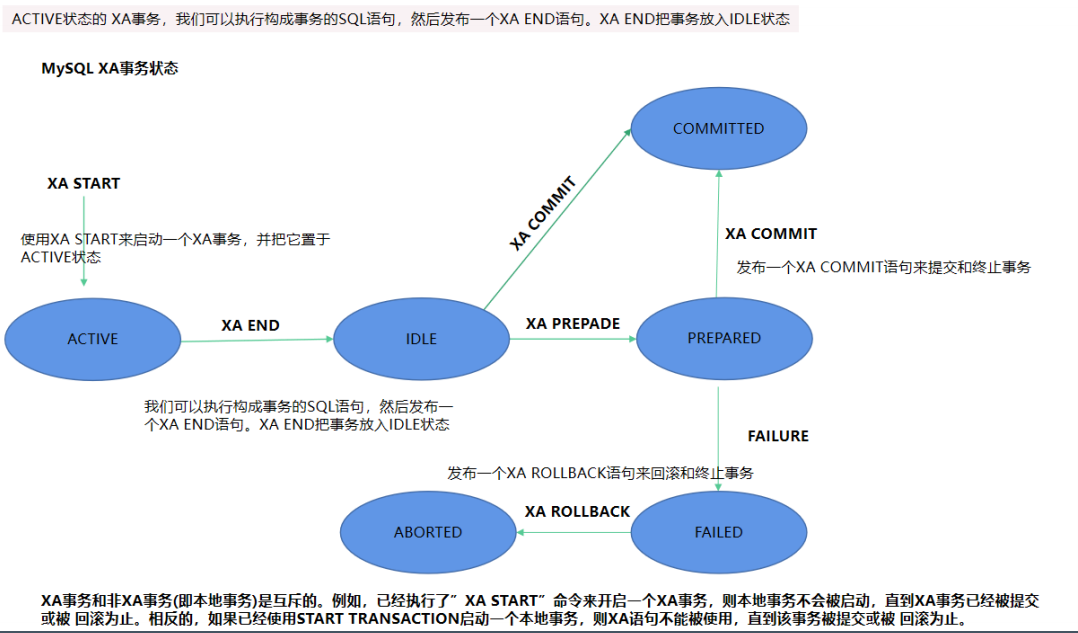
- xa_start:負責開啟或者恢復一個事務分支
- xa_end:負責取消當前執行緒和事務分支的關聯
- xa_prepare:詢問RM是否準備好提交事務分支
- xa_commit:通知RM提交事務分支
- xa_rollback:通知RM回滾事務分支
- xa_recover:列出所有prepare的XA事務
MySQL 從5.0.3開始支援 InnoDB 引擎的 XA 分散式事務,MySQL Connector/J 從5.0.0版本開始支援 XA

MySQL XA事務狀態
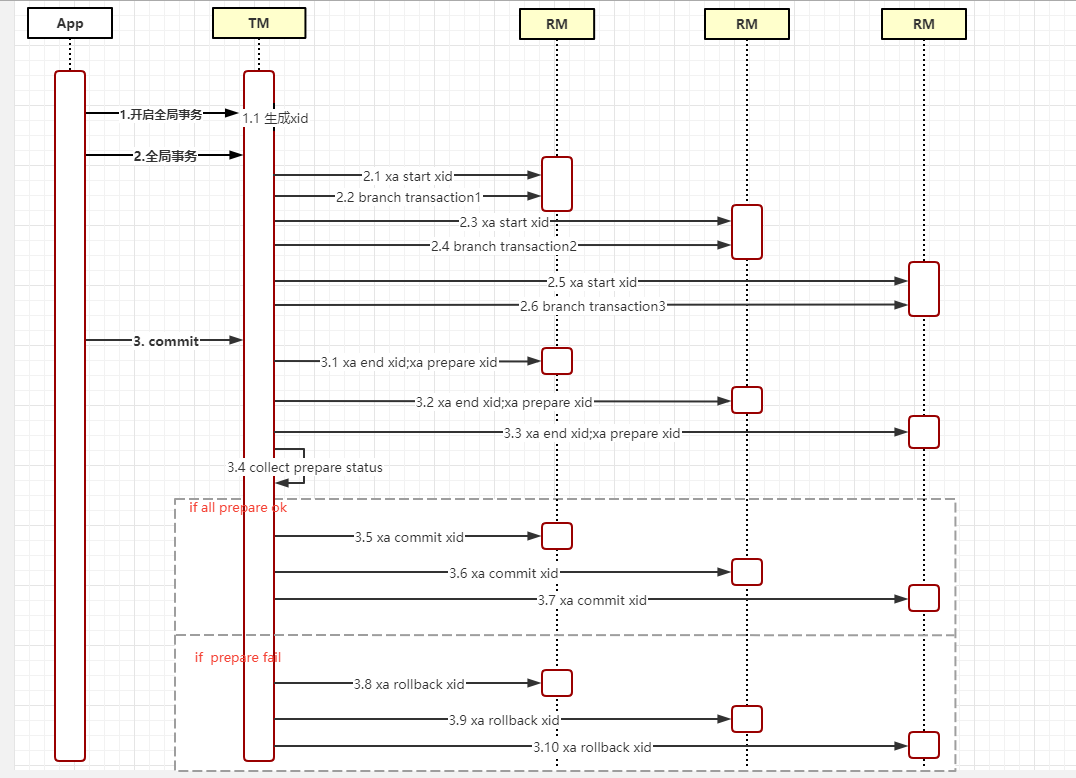
完整的XA事務流程
XA事務異常情況
- 業務SQL執行期間,某個RM崩潰怎麼處理?
答:通知回滾。
2. 全部prepare後,某個RM崩潰怎麼處理?
答:5.7以前崩潰的那個RM會丟失事務,導致別人都提交了,他被回滾了。5.7之後修復了,重連後還能繼續提交。

- commit時,某個RM崩潰了怎麼辦?
答:RM恢復之後重試,要是重試還是失敗就要發送告警,人工進行干預。
XA協議存在的問題
- 同步阻塞問題
全局事務內部包含了多個獨立的事務分支,這一組事務分支,這一組事務分支要不都成功,要不都失敗。各個事務分支的ACID特性構成了全局事務的ACID特性。那麼mysql的效率也會降低
2. 單點故障
TM是單點的,一旦TM發生故障,參與者RM會一直阻塞下去。尤其再第二階段,TM發生故障,那麼所有的RM都還處於鎖定資源的狀態中,而無法完成事務操作。成熟的XA框架需要考慮TM的高可用性。
- 數據不一致
在提交階段的時候,TM向RM發送commit請求後,發生了局部網路異常或者在發送commit請求的時候TM故障了,會導致部分RM收到commit請求並執行,而部分RM未收到commit請求則無法進行事務提交,就會造成數據不一致的情況。
支援XA的框架
XA方面的框架,比較推薦Atomikos和narayana

二、柔性事務
如果將實現了ACID的事務要素的事務稱為剛性事務的話,那麼基於BASE理論的事務則稱為柔性事務。
BASE:
- Basically Available (基本可用)
- Soft state(柔性狀態) 允許系統狀態更新有一定的延時
- Eventually consistent(最終一致性)
柔性事務常見模式
1. TCC
TCC模式將每個服務的業務操作分為兩個階段。第一個階段檢查並預留相關資源(Try),第二個階段根據Try狀態,如果都成功,則進行Comfirm操作,如果任意一個發生錯誤,則全部Cancel。
- Try:完成所有業務檢查,預留資源
- Confirm:正在執行的業務邏輯,不做業務檢查,只是要Try階段預留的業務資源。因此,只要Try成功,Confirm基本能成功。另外Confirm需要滿足冪等性。
- Cancel:釋放Try階段的資源。同樣Cancel也需要滿足冪等性。
TCC不依賴RM對分散式事務的支援,而是通過對業務邏輯的分解來實現分散式事務。對業務有侵入性
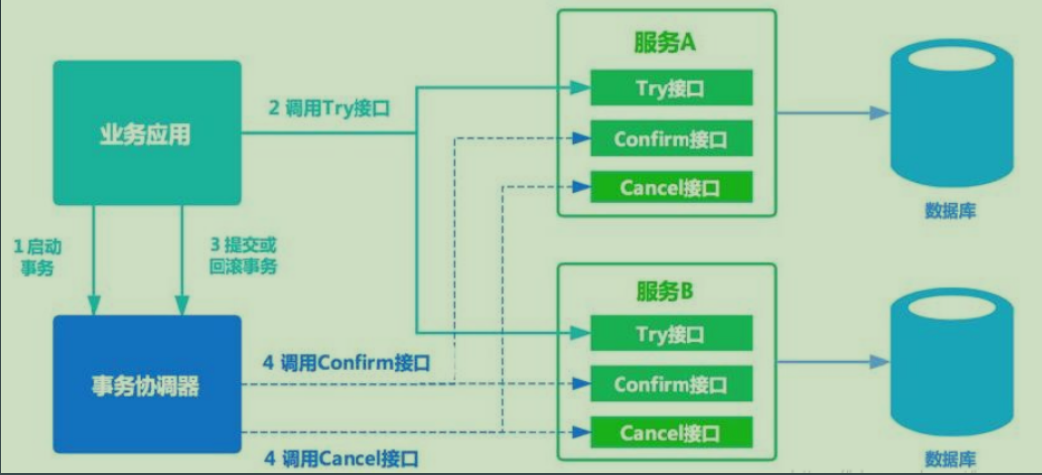
TCC需要注意的問題:
- 允許空回滾
Cancel的時候要判斷Try有沒有完成,沒完成就不做Cancel
2. 防懸掛控制
如果網路等資料庫還沒收到Try的執行命令,Cancel命令先收到了。就會導致這個Try命令就沒有相對於的Cancel操作了,會一直懸掛在那裡。
解決方法:
- 可以控制Try和Cancel的順序,讓Try在前面
- 先收到Cancel的時候,記錄一下。再收到Try的時候就知道這個操作是要取消的,那Try就沒必要執行了。
- 冪等設計
commit操作可能會被重試,所以需要冪等性。
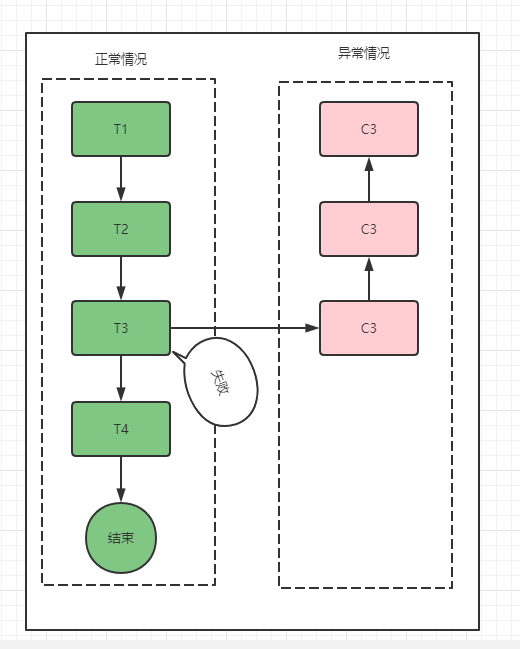
2. SAGA
Saga模式沒有Try階段,直接提交事務。複雜情況下,對回滾操作的設計要求較高。
3. AT
AT就是通過自動生成反向SQL的方式進行回滾。
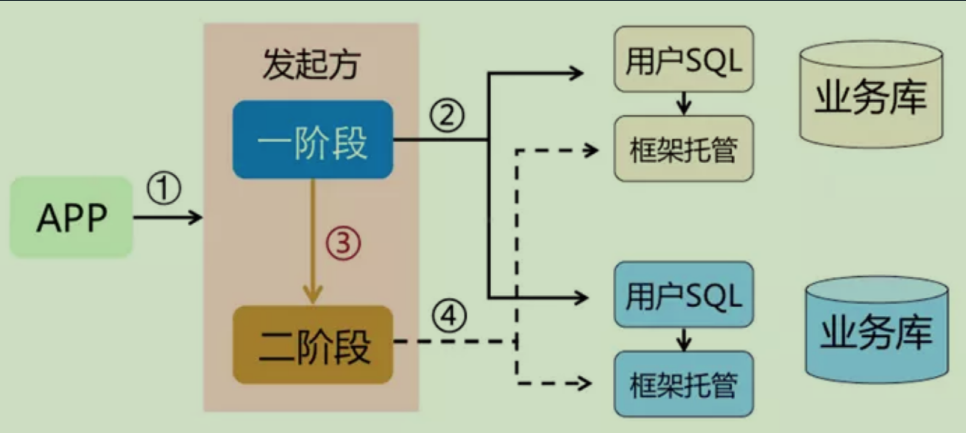
在第一階段的時候執行業務SQL,並且將SQL造成的影響保留下來。
第二階段如果發生異常,就會通過保留的影響用反向SQL恢復回去。
缺點:生成反向SQL如果是在特別複雜的情況下,可能會處理不了。
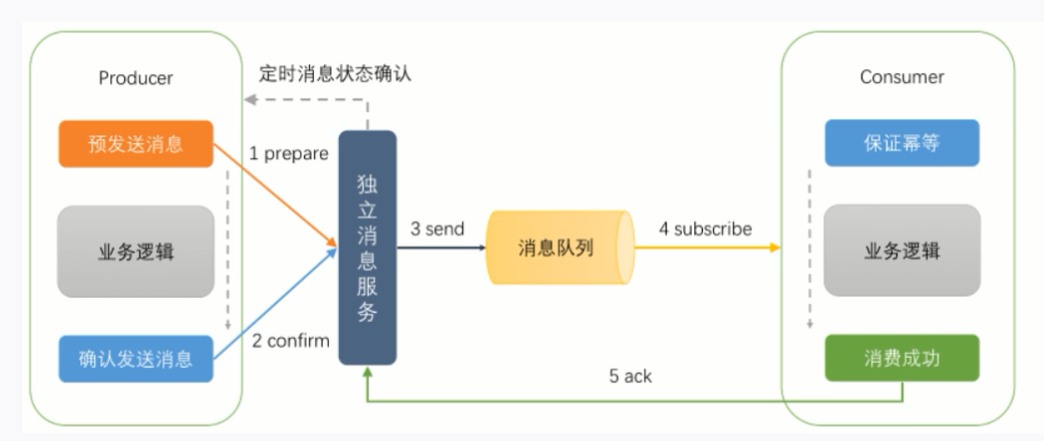
4. 可靠消息最終一致性
- 服務A發送一個prepared消息給mq,如果發送失敗則取消操作
- 消息發送成功則開始執行本地事務
- 本地事務執行成功就向mq發送確認消息,執行失敗就發送回滾消息
- 如果mq沒有接收到確認消息,mq會去輪詢未確認的prepared消息,然後去查詢服務A是否執行成功,然後確定是重試還是回滾
- 如果mq成功收到確認消息,那麼他會被服務B消費到,並且服務B可以通過ACK機制保證服務B執行成功.
- 如果服務B實在是無法執行成功,可以通知服務A回滾,或者發送報警消息讓手工補償.
5. 本地消息表
- 服務A執行業務程式碼,並往自己的消息表插入一條數據
- 服務A執行成功後,會向MQ發送一條數據,去調用服務B的方法
- 服務B收到後,先往自己的消息表插入一條數據,然後去執行業務程式碼
- 如果服務B業務程式碼執行成功,那麼更新自己的消息表的狀態並且通知服務A更新消息表狀態
- 如果服務B業務程式碼執行失敗,那麼服務B不用做什麼
- 服務A會有一個定時任務定時輪詢自己的消息表,將失敗的消息再發給MQ,讓服務B重新在執行一次(服務B保證介面冪等性)
- 通過不斷的重試,保證最終一致性
這個方案大量使用來消息表,對於高並發的場景不太友好.
6. 最大努力型通知
類似銀行的支付回調,會多次回調直到成功。
這種方案適用於允許有些事務失敗的情況,如記錄日誌等.
三、分散式事務框架
1. Seata
Seata是阿里巴巴和螞蟻金服聯合打造的分散式事務框架。其AT事務的目標是讓開發者像使用本地事務一樣使用分散式事務。
核心組件:
- TM 事務管理者:開啟提交或回滾全局事務
- TC 事務協調者:維護全局和分支事務的狀態,指示全局提交或回滾。
- RM 資源管理者:管理執行分支事務上的資源,向TC註冊分支事務、上報分支事務狀態、控制分支事務的提交或回滾。
Seata管理的分散式事務的典型聲明周期:
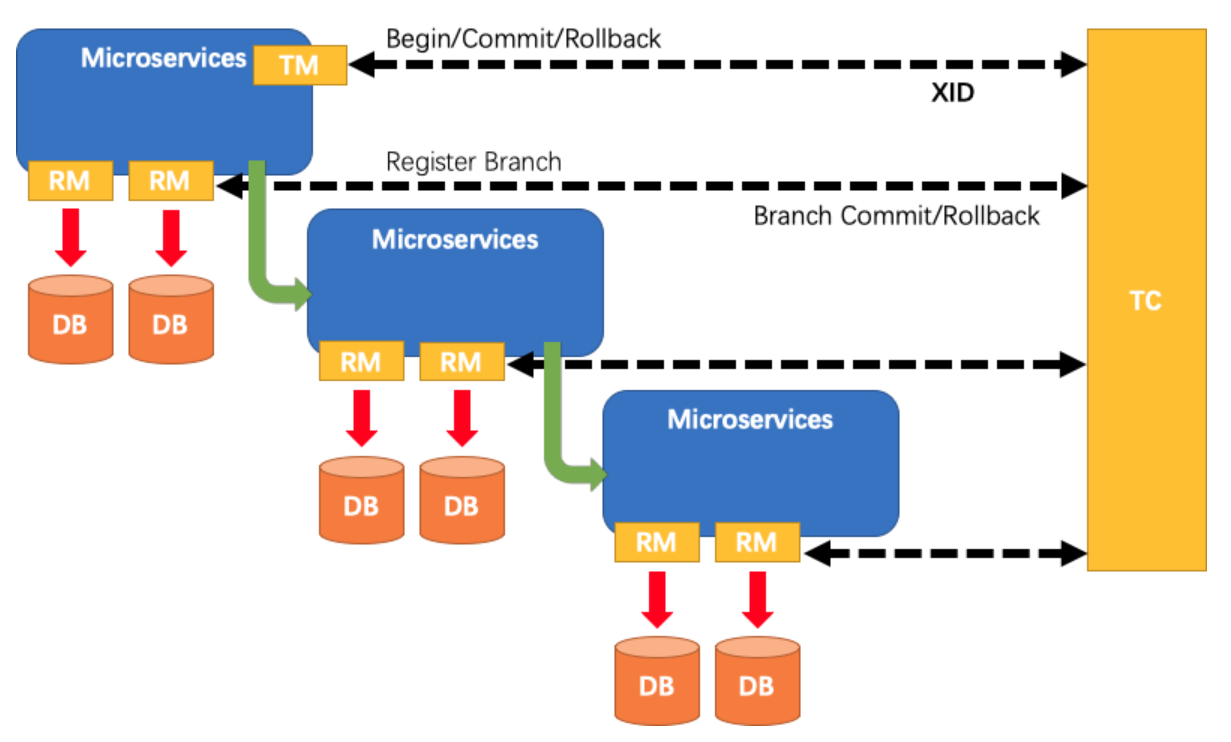
- TM要求TC開始一個全新的全局事務。
- TC生成一個代表該全局事務的XID。XID貫穿整個微服務的調用鏈。
- TM要求TC提交或回滾XID對應的全局事務。
- TC驅動XID對應的全局事務下的所有分支事務完成提交或回滾。
Seata支援 XA、TCC、Saga模式,但支援的主要方式是 AT。
2. ShardingSphere對分散式事務的支援
ShardingSphere 通過整合常用的幾個事務開源實現,如Atomkkos、Narayana,為本地事務、兩階段事務和柔性事務提供統一的分散式事務介面,並彌補當前方案的不足,提供一站式的分散式事務解決方案是ShardingSphere的設計目標。
使用實例://gitee.com/mmcLine/spring-cloud-transaction
裡面readme有詳細的項目介紹。