面試問題記錄 二 (資料庫、Linux、Redis)
面試問題記錄 二 (資料庫、Linux、Redis)
前言
接著上次的面試問題記錄,在最後還有幾道問的數據結構方面的知識點要補充
還是那句話:如果文中解釋有明顯錯誤,勞煩請及時指正我,在這不勝感激!!!
一、MySQL
1.說說MySQL與MongoDB的區別?
答:首先就是MySQL是關係型資料庫,由二維表及其自身之間的關係組成的數據組織,這樣易於維護,而且適用於SQL複雜的查詢、支援事務等;MongoDB的話是以數據結構化的方式存儲,而且和MySQL不同,它是只能存儲在隨機存儲器上的,底層數據結構是B樹, 雖然本身沒有事務機制,但是可以從邏輯上實現事務。
2.內連接、左連接、右連接是怎樣的?
答:內連接(inner join)是把匹配的都顯示出來,比如兩張表,首先確定從哪張表查出要匹配的欄位,然後加上關鍵字inner join,把後面符合條件的結果查出來;左連接(left join)是將左表為基準,來一一匹配右表,如果匹配不上返回左表內容,右表返回空;右連接(right join)是將右表為基準,來一一匹配左表,如果匹配不上則返回右表內容,左表返回null。
3.如何分庫分表?為什麼分?
答:當我們一開始資料庫中沒有進行分庫分表的時候,由於資料庫中的數據量並不是可控的,而且隨著業務的發展,數據量就會不斷擴大,這樣會導致資料庫的操作開銷越來越大,而且伺服器的資源是有限的,最終數據量和資料庫的處理能力都會到達瓶頸;分庫分表有垂直和水平方式,一般是先垂直後水平,垂直是按一個系統中不同的業務來分庫分表,也可以解決那種表中欄位較多,數據量大,不常用的,長度比較長的進行分表處理;水平是將數據量大的單張表的數據分到不同的資料庫,相同結構的表中。當然使用這種策略還會遇到事務一致性、容量限制、分頁排序、全局主鍵唯一等問題。分庫分表的話,目前知道的是用單獨的服務MyCat去實現或者用ApacheShardingJDBC實現,只不過ShardingJDBC是融合在項目中的。
4.說一下事務?
答:事務就是將一組SQL語句放在同一批次內執行,如果一組中有一個SQL語句執行不成功,則整個批次中的SQL語句都不會執行,而MySQL事務只支援InnoDB和嵌入型資料庫BDB。事務具有的ACID原則,也就是原子性、一致性、隔離性、持久性;而原子性表示整個事務中所有操作,要麼全成功,要麼全都不執行;一致性表示不管在任何給定的時間並發事務有多少,都要保持系統處於一致的狀態;隔離性表示如果有兩個或多個事務同一時間發生,事務將進行串列化或序列化,來保證同一時間只有一個請求來操作數據;持久性表示事務一旦執行完畢後,事務所做的操作將持久的保存在資料庫中,而且不會回滾。
5.如何分頁?
答:用limit關鍵字,limit (pageNo-1)*pageSzie,pageSzie [pageNo:頁碼,pageSize:單頁面顯示條數]
6.三大範式知道嗎?
答:第一範式是表示列的原子性,保證每一列都是最小單元,不能再分割了;第二範式是在第一範式的基礎上建立的,每一列都要和主鍵相關,主要針對聯合主鍵而言,就是每個表只描述一件事情;第三範式確保滿足第二範式,每一列都和主鍵直接相關,而不是間接相關,也就是避免數據冗餘。
具體可參考下面兩篇文章:《資料庫設計三大範式 》 《資料庫範式那些事》
面試文章:資料庫面試題
7.它的索引是怎麼實現的?
答:快速定位表中內容的一種機制,幫助MySQL高效獲取數據的數據結構。索引主要有四種,一主鍵索引Primary Key,二唯一索引Unique,三常規索引index,四全文索引FullText。而且mysql5.6以前的版本只有MyIsam支援全文索引,之後的話,兩種數據引擎都支援全文索引,且欄位數據類型為char,varchar、text及其系列的數據類型。
可參考文章:漫談資料庫索引
二、Linux
1.說一下你常用的命令
答:最基礎的話,比如cd進入某個目錄、pwd顯示當前文件路徑、ls查看文件列表、ll查看文件列表詳情、mkdir創建目錄、rm刪除、mv移動、cp複製、find搜索、whereis顯示二進位文件路徑、which查找文件、cat查看文件內容、grep匹配文件中具體內容,tar壓縮解壓、zip壓縮、unzip解壓、init 6重啟、init 0立刻關機、shutdown關機、ifconfig、ip addr查看網路介面屬性、ps -ef查看所有進程、top顯示進程狀態、netstat監聽連接埠、kill進程、service、systemctl服務查看、啟動、終止(service命令服務名在中間,systemctl命令服務名在最後),data顯示系統日期時間。
三、Redis
1.Redis是什麼?為什麼用它?
答:redis是基於記憶體可持久化的日誌型、key-value型資料庫;首先就是它可以做高速快取,而且有多種數據類型,支援事務,其次可以簡單實現消息隊列和session共享;redis的話也是針對一些數據量不是很大,訪問頻繁的數據。這樣訪問數據的話,就會變得快而且安全。
可參考文章:《Redis面試題》 《為什麼要用Redis》
2.Redis支援的數據類型有哪些?
答:應該有8種,最基本的是五種;字元串string、哈希hash、集合set、列表list、有序集合zset;
3.快取雪崩、快取穿透、快取擊穿可以解釋一下嗎?
答:首先快取是這樣
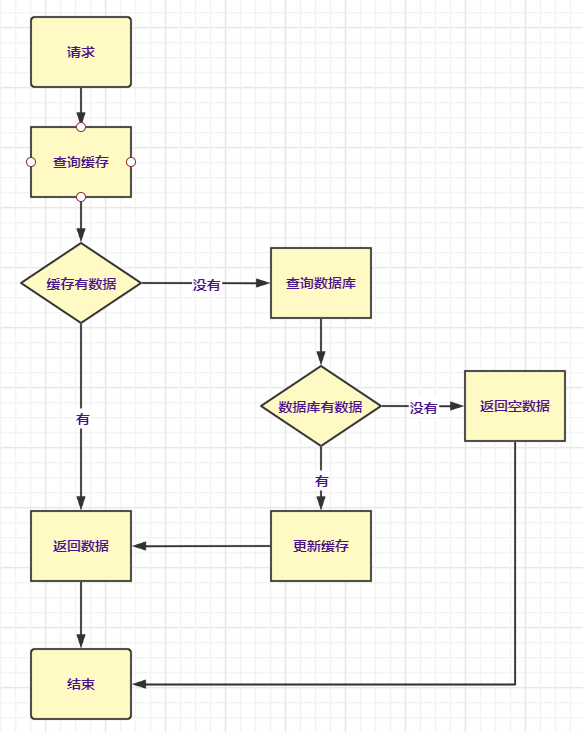
快取雪崩:快取中大量key同時失效,導致大量請求打在資料庫上,導致資料庫承受不住,宕機;還有就是快取伺服器崩了。可以使用熱點數據永不失效、排隊、限流、降級、主從+哨兵模式,這方面並未有做過深的探究。
快取擊穿:和雪崩相反,當某些超熱點的數據在快取過期瞬間打在資料庫上,使資料庫壓力過重,崩潰。可以將熱點數據設置永不過期,或者在拿數據的時候加互斥鎖。
快取穿透:如果快取和資料庫都沒有的數據記錄,被頻繁的請求和調用,導致資料庫中沒有數據,快取也沒法更新數據;這樣的方式也被用於惡意攻擊,不走尋常路。可以在後端做數據校驗,增添過濾器。
4.如何保證快取和資料庫數據一致?
答:一般是設置快取過期時間,等超時之後直接從資料庫重新讀取回填快取,也就是要刪除快取,更新資料庫的操作。
二是先刪除快取,再更新資料庫。方法就是延時雙刪,比如有兩個執行緒A和B,首先A刪除快取,去更新資料庫,然後B來讀快取,發現快取已經被刪除,然後去讀資料庫,此時A還未更新完成,所以B拿到的數據是舊的,然後將舊值寫入快取,因為給A設置了一個估算時間sleep,這個時間是大於B的整個過程的,所以這個時間已過,快取將又被刪除,這樣當有別的執行緒來訪問,則從資料庫中得到最新的數據。
四、上篇補充內容
1.快速排序是怎樣的?
答:參考:《十大經典排序演算法(動圖演示)》,《玩轉Java快速排序》
2.說一下HashMap?
答:存儲結構 默認容量 裝載因子 hashcode/equals 1.7和1.8版本變化
1.內部存儲結構:數組+鏈表+紅黑樹(JDK8)
2.默認容量16,默認裝載因子0.75。
3.key和value對數據類型的要求都是泛型。
4.key可以為null,放在table[0]中。
5.hashcode:計算鍵的hashcode作為存儲鍵資訊的數組下標用於查找鍵對象的存儲位置。equals:HashMap使用equals()判斷當前的鍵是否與表中存在的鍵相同
3.為什麼用迭代器?
答:為了提供給不同集合類的統一遍歷的介面,迭代器也是一種設計模式吧。
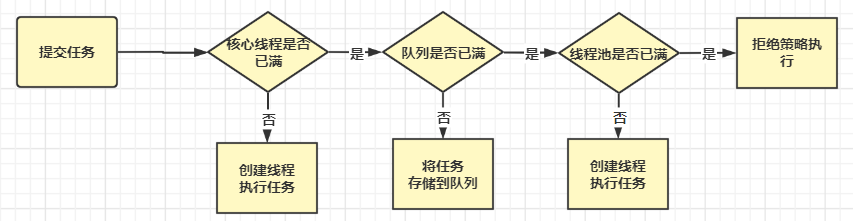
4.執行緒池流程
最後
就簡單的記錄了一下,到後期會把一些面試的資料也會總結一下,畢竟這次也是一小部分的問題;具體關於JavaEE上的還未修改出來,也會在最近加緊總結。其實現在面試也更多去偏向業務上的東西,加上自己的理解,像「八股文」這種東西還是需要看的,畢竟有些問題實在是很基礎,不問也不行。
最近也是發現一句話「無關緊要的事情,直接捨棄。集中火力,不要分散自己的學習精力。你不能什麼都學」
平常真的是把注意力放在了廣度上,而從未去深度的get那個點。


