java架構之路-(mysql底層原理)Mysql事務隔離與MVCC
- 2019 年 10 月 3 日
- 筆記
上幾篇部落格我們大致講了一下mysql的底層結構,什麼B+tree,什麼Hash需要回行啊,再就是講了mysql優化的explain,這次我們來說說mysql的鎖。
mysql鎖
鎖從性能上分為樂觀鎖(用版本對比來實現)和悲觀鎖,樂觀鎖的性能要比悲觀鎖高。
從對資料庫操作的類型分,分為讀鎖和寫鎖(都屬於悲觀鎖)
讀鎖(共享鎖):針對同一份數據,多個讀操作可以同時進行而不會互相影響。除鎖以外的執行緒只可讀,不可以寫入。
寫鎖(排它鎖):當前寫操作沒有完成前,它會阻斷其他寫鎖和讀鎖。除鎖以外的執行緒不可以做任何操作。
從對數據操作的粒度分,分為表鎖和行鎖,再就是不常提到的間隙鎖。
我們主要來說表鎖和行鎖,還有我們的間隙鎖。
注意:有鎖等待的幾乎都為悲觀鎖
表鎖
顧名思義,加了表鎖,會將整張表鎖住。開銷很小,加鎖很快,不會出現死鎖;鎖定粒度大,發生鎖沖 突的概率最高,並發度最低;
我們來看幾條命令。以student表為例
加表鎖:lock table 表名稱 read(write),表名稱2 read(write);
lock table student write;
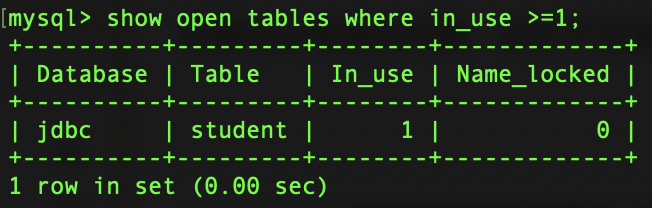
查看錶狀態(是否被加鎖):
show open tables;
內有有一個列為In_use為1的即為已有鎖存在。
解鎖表:unlock tables;
unlock tables;
行鎖
每次操作鎖住一行數據。開銷大,加鎖慢;會出現死鎖;鎖定粒度最小,發生鎖衝突的概率最低,並發度最高。
說到這要提到我們的ACID了,我們來複習一下。
A(atomicity)原子性:
即事務要麼全部做完,要麼全部不做,不會出現只做一部分的情形,如A給B轉帳,不會出現A的錢少了,B的錢卻沒有增加的情況,要麼全部成功,要麼全部失敗(回滾)。這一系列的動作可以視為一個原子。
C(consistency)一致性:
指的是事務從一個狀態到另一個狀態是一致的,如A減少了100,B不可能只增加30。
I(isolation)隔離性:
即一個事務在沒有完成數據的提交修改時,對其它事務是不可見的。當然這裡有個隔離級別的概念,在不同隔離級別下,這裡會有不同的表現形式。
D(durability)持久性:
一旦事務提交,則所做修改就會被永久保存到資料庫中。
然後就是我們的並發事務處理帶來的問題,先過一遍這些都會造成什麼後果。
更新丟失(Lost Update)
當兩個或多個事務選擇同一行,然後基於最初選定的值更新該行時,由於每 個事務都不知道其他事務的存在,就會發生丟失更新問題–最後的更新覆蓋了由其 他事務所做的更新。
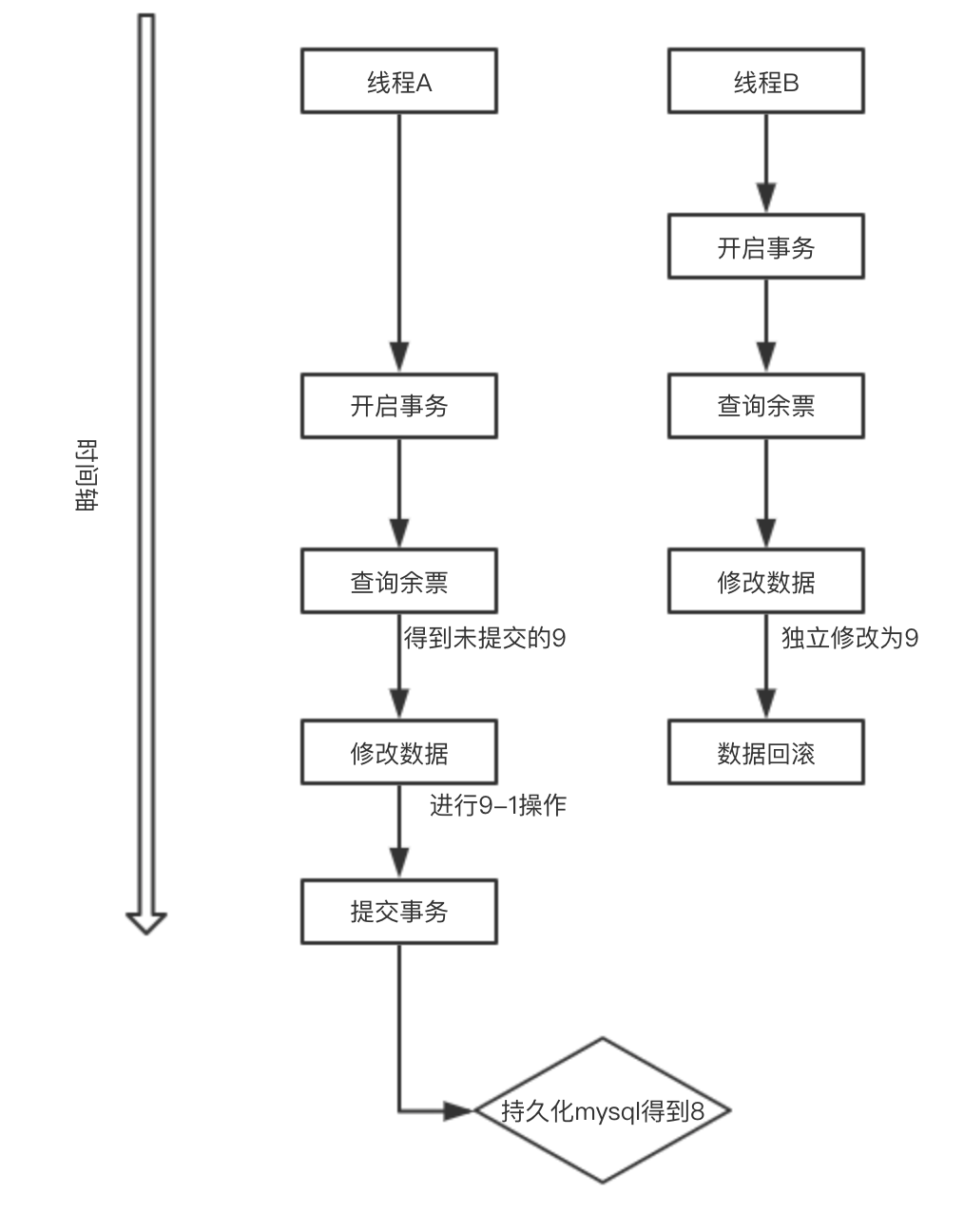
舉例:比如我們同時開啟兩個執行緒去售票,賣一張少一張,我們執行緒A開啟事務,同時我們開啟執行緒B,同時查詢到余票為10張,賣一張吧。A賣了一張,10-1,剩餘9張,我們B執行緒也賣了一張也是10-1,也剩餘9張,提交A,提交B,我們明明賣了兩張票,可是資料庫得到的確實9,只賣了一張票。

臟讀(Dirty Reads)
一個事務正在對一條記錄做修改,在這個事務完成並提交前,這條記錄的數 據就處於不一致的狀態;這時,另一個事務也來讀取同一條記錄,如果不加控 制,第二個事務讀取了這些“臟”數據,並據此作進一步的處理,就會產生未提 交的數據依賴關係。這種現象被形象的叫做“臟讀”。 一句話:事務A讀取到了事務B已經修改但尚未提交的數據,還在這個數據基 礎上做了操作。此時,如果B事務回滾,A讀取的數據無效,不符合一致性要求。
不可重讀(Non-Repeatable Reads)
一個事務在讀取某些數據後的某個時間,再次讀取以前讀過的數據,卻發現 其讀出的數據已經發生了改變、或某些記錄已經被刪除了!這種現象就叫做“不 可重複讀”。 一句話:事務A讀取到了事務B已經提交的修改數據,不符合隔離性。
幻讀(Phantom Reads)
一個事務按相同的查詢條件重新讀取以前檢索過的數據,卻發現其他事務插入了滿足其查詢條件的新數據,這種現象就稱為“幻讀”。 一句話:事務A讀取到了事務B提交的新增數據,不符合隔離性
後面的兩個說完MVCC機制也就知道是怎麼回事了,暫時放在這裡。
這些問題我們再回到我們的資料庫吧。

一般都設置為可重複讀的。資料庫的事務隔離越嚴格,並發副作用越小,但付出的代價也就越大,因為事務隔離實質上就是使事務在一定程度上“串列化”進行,這顯然與“並發”是矛盾的。 同時,不同的應用對讀一致性和事務隔離程度的要求也是不同的,比如許多應用
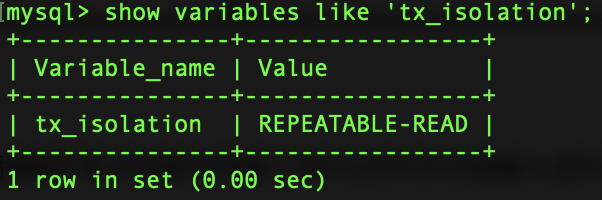
對“不可重複讀”和“幻讀”並不敏感,可能更關心數據並發訪問的能力。 常看當前資料庫的事務隔離級別: show variables like ‘tx_isolation’; 設置事務隔離級別:set tx_isolation=’REPEATABLE-READ’;
其餘的可以自己去嘗試一下,讀未提交READ-UNCOMMITTED,讀已提交READ-COMMITTED,可串列化SERIALIZABLE;
MVCC:
這個超級重要,懂了這個上面的幾乎都懂了~!

英文全稱為Multi-Version Concurrency Control,翻譯為中文即 多版本並發控制。這個概念很抽象,我們並不知道他控制的是什麼。
舉一個栗子來說一下,假設我們的MySQL表裡有兩個虛擬的欄位,一個叫開啟事務ID,一個叫刪除事務ID,都為自增的。再開啟事務時不會給予任何數值,在執行第一條SQL時,給予開啟事務ID一個數字,我們假設為0,但是不給與提交事務ID(還是為空)。以我們給出的學生表為例上圖說話。
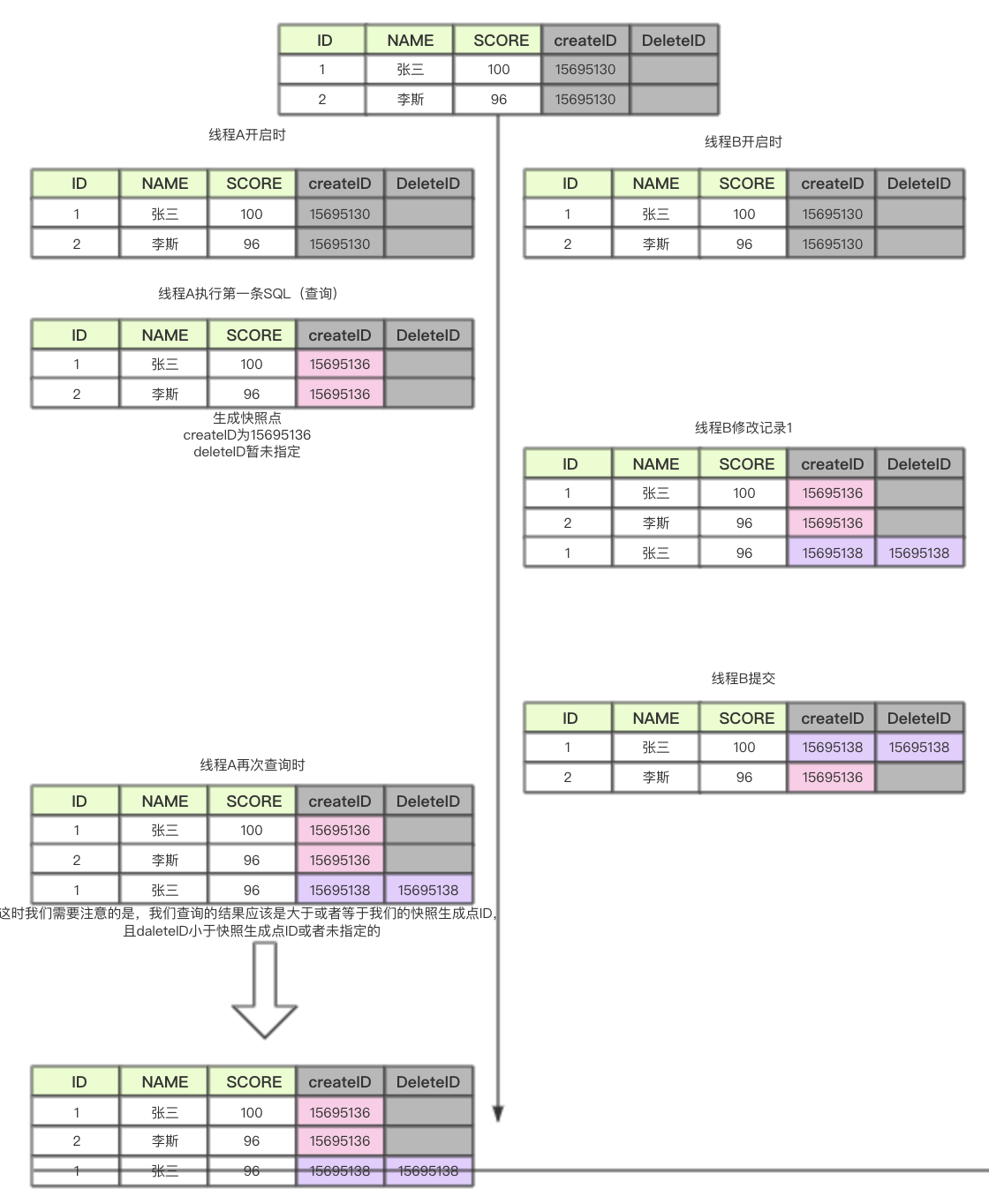
簡單說一下圖的意思,我們每次在運行sql的時候,都會以時間戳生成一個快照版本號,如果是查詢SQL,會把這個版本號更新到我們的createID欄位,增刪改操作會把我們的版本號更新到的deleteID欄位,每個執行緒事務之間版本號是獨立的,對於我們的下一次查詢來說,我們會查詢數據中createID大於等於我們的快照版本號,且deleteID小於我們的當前的快照版本號ID的數據。MVCC一般在可重複讀的隔離級別,但同時在讀已提交也是試用的。MVCC缺點是會保存多個快照版本,造成了空間的冗餘,但是保證了每個執行緒的獨立操作。
間隙鎖
簡單說一下間隙鎖,如果我們的表ID是自增的,我們寫一個開啟事務,我們寫一條修改SQL
update student set name = ‘1111’ where id>8 and id<22;
也就是說,不管你有沒有id為8~22的數據,這時都對小於8的最大ID到大於22的最小ID這個範圍加了鎖,這斷範圍是禁止你新增和修改的,其餘位置是可以的。看你的表結構
比如你的表是
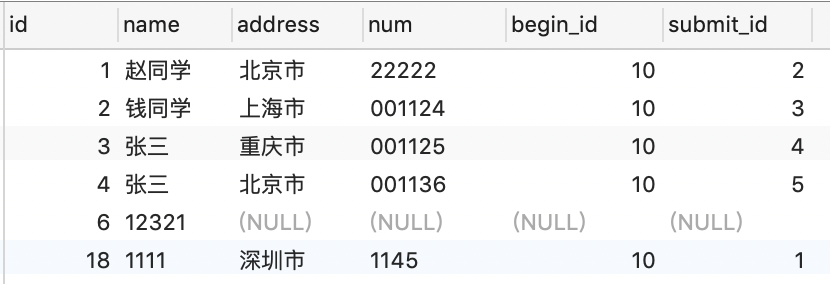
sql為 update student set name = ‘1111’ where id>8 and id<22; 其實我們加鎖的範圍是(6~22)的範圍開區間都是不可以操作的 。
鎖升級:
我們內部的InnoDB的鎖是加在索引上的,也就是說,我們update或者delete時後面的where條件儘力要跟索引欄位。
鎖的分析:
分別表示為
Innodb_row_lock_current_waits: 當前正在等待鎖定的數量
Innodb_row_lock_time: 從系統啟動到現在鎖定總時間長度(等待總時長)
Innodb_row_lock_time_avg: 每次等待所花平均時間(等待平均時長)
Innodb_row_lock_time_max:從系統啟動到現在等待最長的一次所花時間
Innodb_row_lock_waits:系統啟動後到現在總共等待的次數(等待總次數)
死鎖
也就是相互的鎖等待造成死鎖。
查看近期死鎖日誌資訊:show engine innodb statusG; 大多數情況mysql可以自動檢測死鎖並回滾產生死鎖的那個事務,但是有些情況mysql沒法自動檢測死鎖
儘可能讓所有數據檢索都通過索引來完成,避免無索引行鎖升級為表鎖,合理設計索引。
盡量縮小鎖的範圍,儘可能減少檢索條件範圍,避免間隙鎖。
盡量控制事務大小,減少鎖定資源量和時間長度,涉及事務加鎖的sql
盡量放在事務最後執行
儘可能低級別事務隔離


