《面試八股文》之 Redis 16卷
- 2021 年 7 月 26 日
- 筆記
微信公眾號:moon聊技術
關注選擇「 星標 」, 重磅乾貨,第一 時間送達!
[如果你覺得文章對你有幫助,歡迎關注,在看,點贊,轉發]

大家好,我是 moon。
redis 作為我們最常用的記憶體資料庫,很多地方你都能夠發現它的身影,比如說登錄資訊的存儲,分散式鎖的使用,其經常被我們當做快取去使用。
可是,用了這麼久的reids,你懂它嗎?
- 1.什麼是 redis?它能做什麼?
- 2.redis 有哪八種數據類型?有哪些應用場景?
- 3.redis為什麼這麼快?
- 4.聽說 redis 6.0之後又使用了多執行緒,不會有執行緒安全的問題嗎?
- 5.redis 的持久化機制有哪些?優缺點說說
- 6. Redis的過期鍵的刪除策略有哪些?
- 7. Redis的記憶體滿了怎麼辦?
- 8.Redis 的熱 key 問題怎麼解決?
- 9.快取擊穿、快取穿透、快取雪崩是什麼?怎麼解決呢?
- 10.Redis 有哪些部署方式?
- 11.哨兵有哪些作用?
- 12.哨兵選舉過程是怎麼樣的?
- 13.cluster集群模式是怎麼存放數據的?
- 14.cluster的故障恢復是怎麼做的?
- 15.主從同步原理是怎樣的?
- 16.無硬碟複製是什麼?
1.什麼是 redis?它能做什麼?
redis: redis 即 Remote Dictionary Server,用中文翻譯過來可以理解為遠程數據服務或遠程字典服務。其是使用 C 語言的編寫的key-value存儲系統
應用場景:快取,資料庫,消息隊列,分散式鎖,點贊列表,排行榜等等
2.redis 有哪八種數據類型?有哪些應用場景?
redis 總共有八種數據結構,五種基本數據類型和三種特殊數據類型。
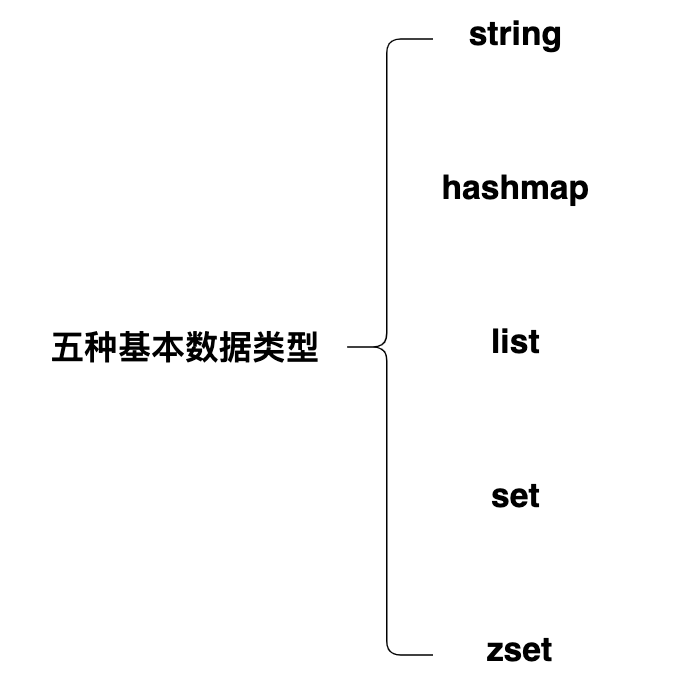
五種基本數據類型:
- 1.string:字元串類型,常被用來存儲計數器,粉絲數等,簡單的分散式鎖也會用到該類型
- 2.hashmap:key – value 形式的,value 是一個map
- 3.list:基本的數據類型,列表。在 Redis 中可以把 list 用作棧、隊列、阻塞隊列。
- 4.set:集合,不能有重複元素,可以做點贊,收藏等
- 5.zset:有序集合,不能有重複元素,有序集合中的每個元素都需要指定一個分數,根據分數對元素進行升序排序。可以做排行榜
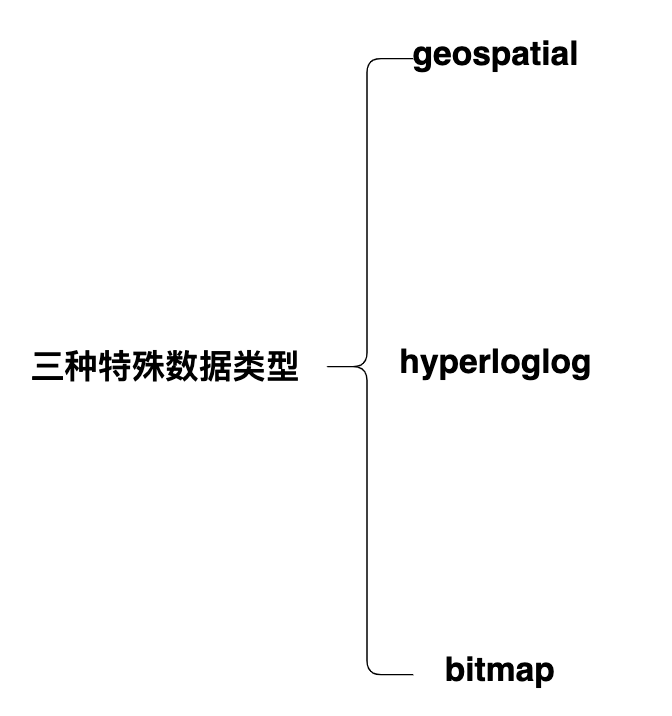
三種特殊數據類型: - 1.geospatial: Redis 在 3.2 推出 Geo 類型,該功能可以推算出地理位置資訊,兩地之間的距離。
- 2.hyperloglog:基數:數學上集合的元素個數,是不能重複的。這個數據結構常用於統計網站的 UV。
- 3.bitmap: bitmap 就是通過最小的單位 bit 來進行0或者1的設置,表示某個元素對應的值或者狀態。一個 bit 的值,或者是0,或者是1;也就是說一個 bit 能存儲的最多資訊是2。bitmap 常用於統計用戶資訊比如活躍粉絲和不活躍粉絲、登錄和未登錄、是否打卡等。

3.redis為什麼這麼快?
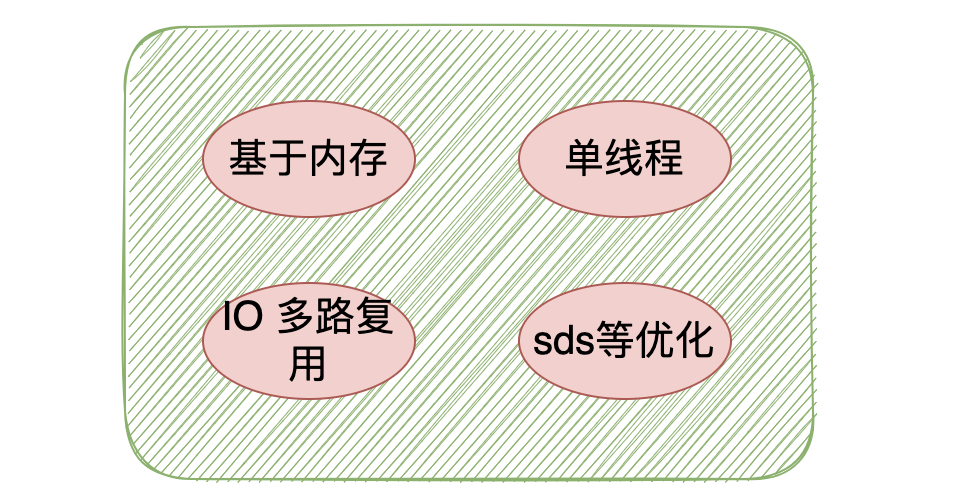
官方數據 redis 可以做到每秒近10w的並發,這麼快的原因主要總結為以下幾點:
- 1:完全基於記憶體操作
- 2:使用單執行緒模型來處理客戶端的請求,避免了上下文的切換
- 3:IO 多路復用機制
- 4:自身使用 C 語言編寫,有很多優化機制,比如動態字元串 sds
4.聽說 redis 6.0之後又使用了多執行緒,不會有執行緒安全的問題嗎?
不會
其實 redis 還是使用單執行緒模型來處理客戶端的請求,只是使用多執行緒來處理數據的讀寫和協議解析,執行命令還是使用單執行緒,所以是不會有執行緒安全的問題。
之所以加入了多執行緒因為 redis 的性能瓶頸在於網路IO而非CPU,使用多執行緒能提升IO讀寫的效率,從而整體提高redis的性能。
5.redis 的持久化機制有哪些?優缺點說說
redis 有兩種持久化的方式,AOF 和 RDB.

AOF:
- redis 每次執行一個命令時,都會把這個「命令原本的語句記錄到一個.aod的文件當中,然後通過fsync策略,將命令執行後的數據持久化到磁碟中」(不包括讀命令),
AOF的優缺點
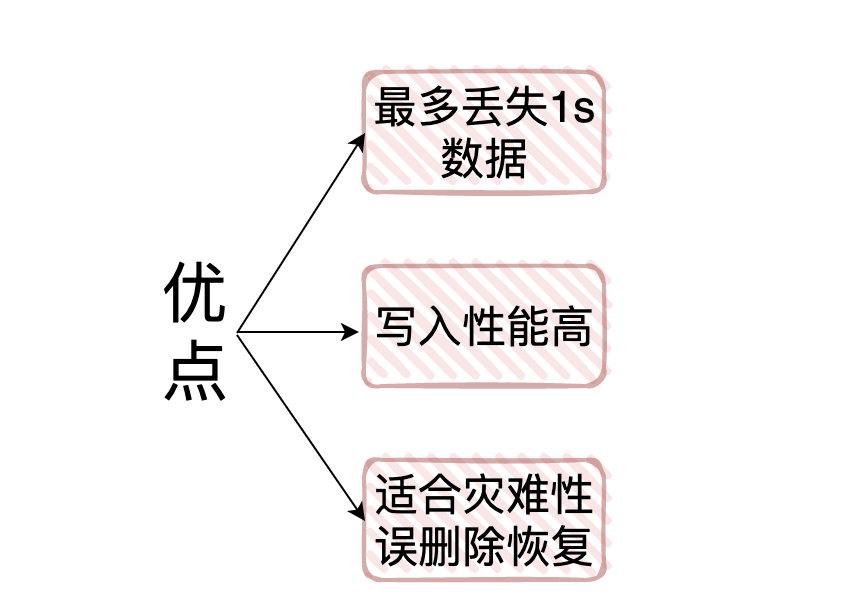
- AOF 的「優點」:
- 1.AOF可以「更好的保護數據不丟失」,一般AOF會以每隔1秒,通過後台的一個執行緒去執行一次fsync操作,如果redis進程掛掉,最多丟失1秒的數據
- 2.AOF是將命令直接追加在文件末尾的,「寫入性能非常高」
- 3.AOF日誌文件的命令通過非常可讀的方式進行記錄,這個非常「適合做災難性的誤刪除緊急恢復」,如果某人不小心用 flushall 命令清空了所有數據,只要這個時候還沒有執行 rewrite,那麼就可以將日誌文件中的 flushall 刪除,進行恢復
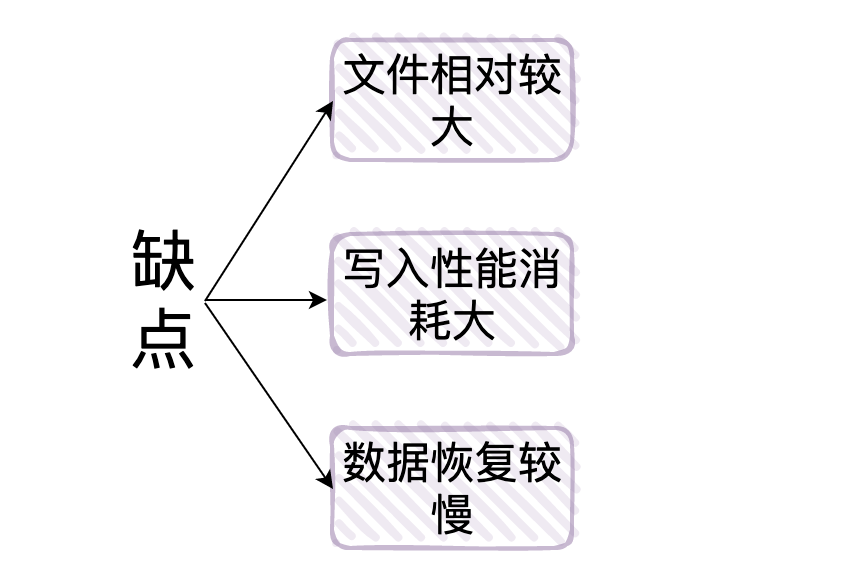
- AOF 的「缺點」:
- 1.對於同一份數據源來說,一般情況下AOF 文件比 RDB 數據快照要大
- 2.由於 .aof 的每次命令都會寫入,那麼相對於 RDB 來說「需要消耗的性能也就更多」,當然也會有 aof 重寫將 aof 文件優化。
- 3.「數據恢複比較慢」,不適合做冷備。
RDB:
- 把某個時間點 redis 記憶體中的數據以二進位的形式存儲的一個.rdb為後綴的文件當中,也就是「周期性的備份redis中的整個數據」,這是redis默認的持久化方式,也就是我們說的快照(snapshot),是採用 fork 子進程的方式來寫時同步的。
RDB的優缺點
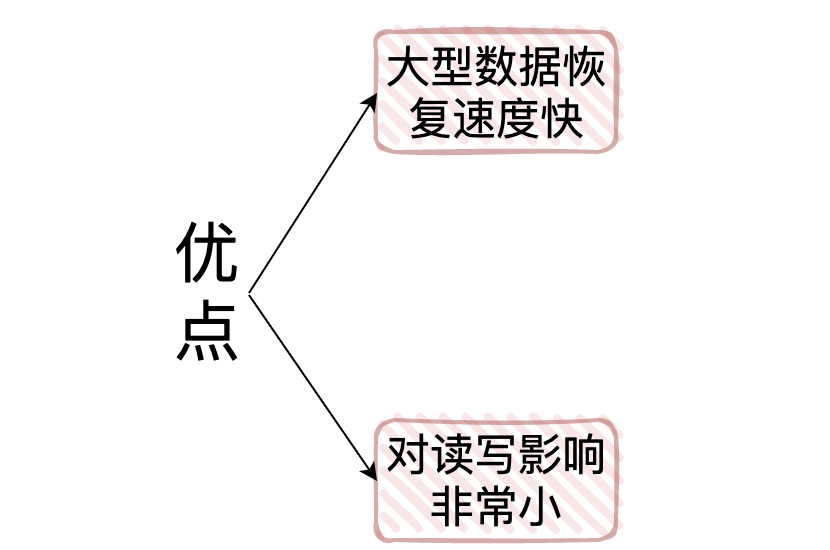
- RDB的優點:
-
1.它是將某一時間點redis內的所有數據保存下來,所以當我們做「大型的數據恢復時,RDB的恢復速度會很快」
-
2.由於RDB的FROK子進程這種機制,隊友給客戶端提供讀寫服務的影響會非常小
-
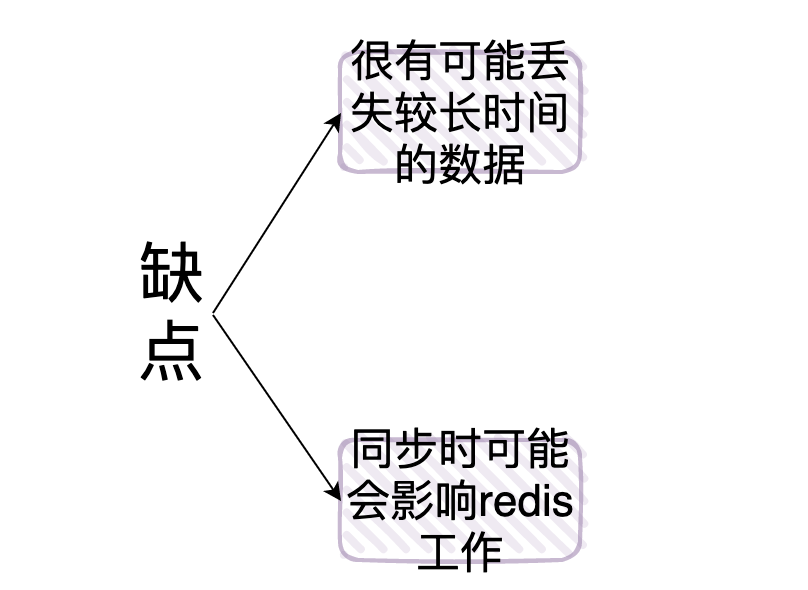
- RDB的缺點:
- 1:「有可能會產生長時間的數據丟失」
- 舉個例子假設我們定時5分鐘備份一次,在10:00的時候 redis 備份了數據,但是如果在10:04的時候服務掛了,那麼我們就會丟失在10:00到10:04的整個數據
- 2:可能會有長時間停頓:我們前面講了,fork 子進程這個過程是和 redis 的數據量有很大關係的,如果「數據量很大,那麼很有可能會使redis暫停幾秒」
- 1:「有可能會產生長時間的數據丟失」
6. Redis的過期鍵的刪除策略有哪些?
過期策略通常有以下三種:
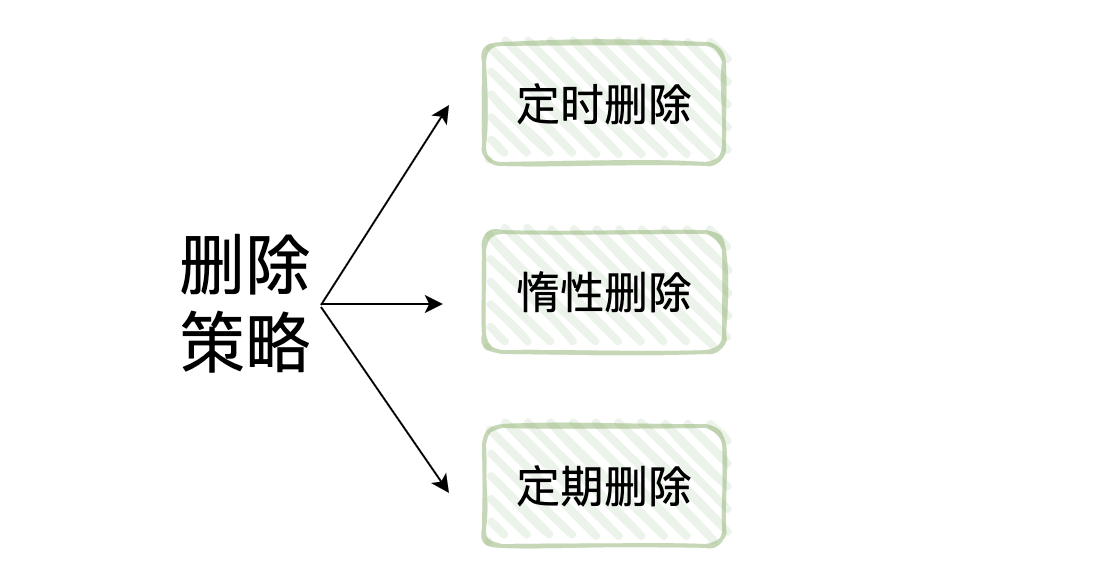
- 定時過期:每個設置過期時間的key都需要創建一個定時器,到過期時間就會立即清除。該策略可以立即清除過期的數據,對記憶體很友好;但是會佔用大量的CPU資源去處理過期的數據,從而影響快取的響應時間和吞吐量。
- 惰性過期:只有當訪問一個key時,才會判斷該key是否已過期,過期則清除。該策略可以最大化地節省CPU資源,卻對記憶體非常不友好。極端情況可能出現大量的過期key沒有再次被訪問,從而不會被清除,佔用大量記憶體。
- 定期過期:每隔一定的時間,會掃描一定數量的資料庫的expires字典中一定數量的key,並清除其中已過期的key。該策略是前兩者的一個折中方案。通過調整定時掃描的時間間隔和每次掃描的限定耗時,可以在不同情況下使得CPU和記憶體資源達到最優的平衡效果。
7. Redis的記憶體滿了怎麼辦?
實際上Redis定義了「8種記憶體淘汰策略」用來處理redis記憶體滿的情況:
- 1.noeviction:直接返回錯誤,不淘汰任何已經存在的redis鍵
- 2.allkeys-lru:所有的鍵使用lru演算法進行淘汰
- 3.volatile-lru:有過期時間的使用lru演算法進行淘汰
- 4.allkeys-random:隨機刪除redis鍵
- 5.volatile-random:隨機刪除有過期時間的redis鍵
- 6.volatile-ttl:刪除快過期的redis鍵
- 7.volatile-lfu:根據lfu演算法從有過期時間的鍵刪除
- 8.allkeys-lfu:根據lfu演算法從所有鍵刪除
8.Redis 的熱 key 問題怎麼解決?
熱 key 就是說,在某一時刻,有非常多的請求訪問某個 key,流量過大,導致該 redi 伺服器宕機
解決方案:
- 可以將結果快取到本地記憶體中
- 將熱 key 分散到不同的伺服器中
- 設置永不過期
9.快取擊穿、快取穿透、快取雪崩是什麼?怎麼解決呢?
快取穿透:
- 快取穿透是指用戶請求的數據在快取中不存在並且在資料庫中也不存在,導致用戶每次請求該數據都要去資料庫中查詢一遍,然後返回空。

解決方案:
- 布隆過濾器
- 返回空對象
快取擊穿:
- 快取擊穿,是指一個 key 非常熱點,在不停的扛著大並發,大並發集中對這一個點進行訪問,當這個 key 在失效的瞬間,持續的大並發就穿破快取,直接請求資料庫,就像在一個屏障上鑿開了一個洞。

解決方案:
- 互斥鎖
- 永不過期
快取雪崩:
- 快取雪崩是指快取中不同的數據大批量到過期時間,而查詢數據量巨大,請求直接落到資料庫上導致宕機。

解決方案:
- 均勻過期
- 加互斥鎖
- 快取永不過期
- 雙層快取策略
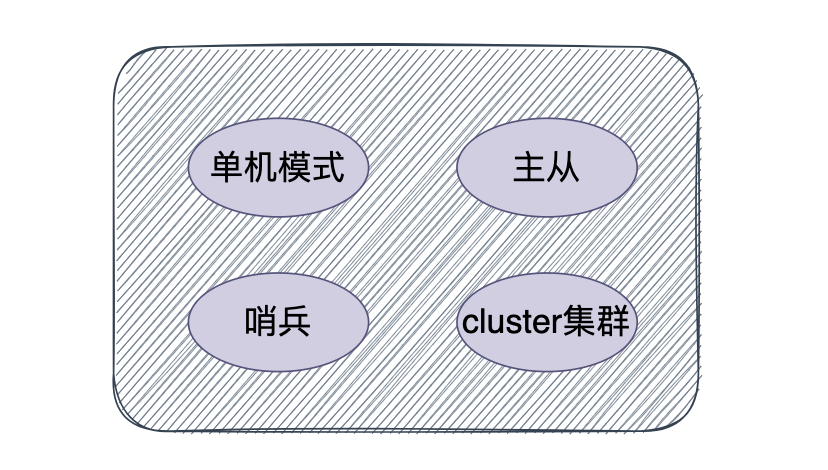
10.Redis 有哪些部署方式?
-
單機模式:這也是最基本的部署方式,只需要一台機器,負責讀寫,一般只用於開發人員自己測試
-
哨兵模式:哨兵模式是一種特殊的模式,首先Redis提供了哨兵的命令,哨兵是一個獨立的進程,作為進程,它會獨立運行。其原理是哨兵通過發送命令,等待Redis伺服器響應,從而監控運行的多個Redis實例。它具備自動故障轉移、集群監控、消息通知等功能。
-
cluster集群模式:在redis3.0版本中支援了cluster集群部署的方式,這種集群部署的方式能自動將數據進行分片,每個master上放一部分數據,提供了內置的高可用服務,即使某個master掛了,服務還可以正常地提供。
-
主從複製:在主從複製這種集群部署模式中,我們會將資料庫分為兩類,第一種稱為主資料庫(master),另一種稱為從資料庫(slave)。主資料庫會負責我們整個系統中的讀寫操作,從資料庫會負責我們整個資料庫中的讀操作。其中在職場開發中的真實情況是,我們會讓主資料庫只負責寫操作,讓從資料庫只負責讀操作,就是為了讀寫分離,減輕伺服器的壓力。
11.哨兵有哪些作用?
-
1.監控整個主資料庫和從資料庫,觀察它們是否正常運行
-
2.當主資料庫發生異常時,自動的將從資料庫升級為主資料庫,繼續保證整個服務的穩定
12.哨兵選舉過程是怎麼樣的?
-
1.第一個發現該master掛了的哨兵,向每個哨兵發送命令,讓對方選舉自己成為領頭哨兵
-
2.其他哨兵如果沒有選舉過他人,就會將這一票投給第一個發現該master掛了的哨兵
-
3.第一個發現該master掛了的哨兵如果發現由超過一半哨兵投給自己,並且其數量也超過了設定的quoram參數,那麼該哨兵就成了領頭哨兵
-
4.如果多個哨兵同時參與這個選舉,那麼就會重複該過程,知道選出一個領頭哨兵
選出領頭哨兵後,就開始了故障修復,會從選出一個從資料庫作為新的master
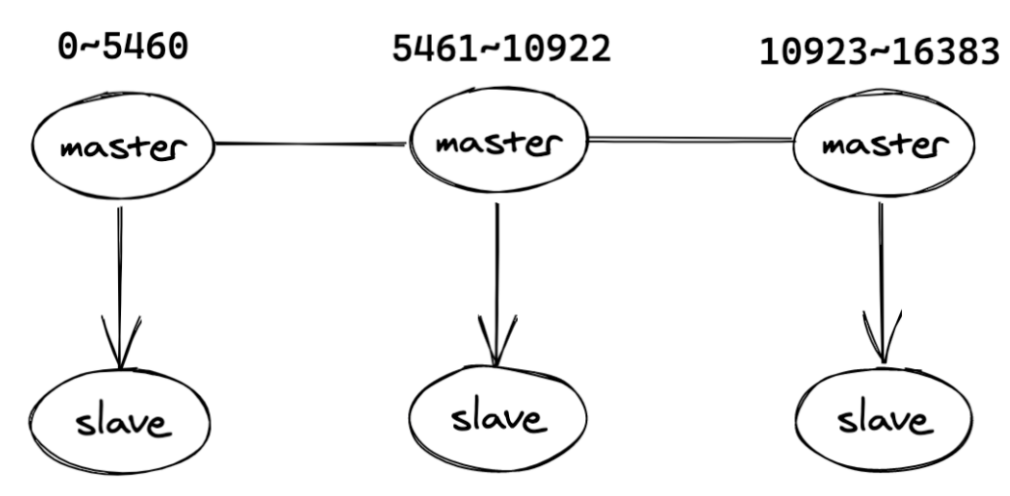
13.cluster集群模式是怎麼存放數據的?
一個cluster集群中總共有16384個節點,集群會將這16384個節點平均分配給每個節點,當然,我這裡的節點指的是每個主節點,就如同下圖:
14.cluster的故障恢復是怎麼做的?
判斷故障的邏輯其實與哨兵模式有點類似,在集群中,每個節點都會定期的向其他節點發送ping命令,通過有沒有收到回復來判斷其他節點是否已經下線。
如果長時間沒有回復,那麼發起ping命令的節點就會認為目標節點疑似下線,也可以和哨兵一樣稱作主觀下線,當然也需要集群中一定數量的節點都認為該節點下線才可以,我們來說說具體過程:
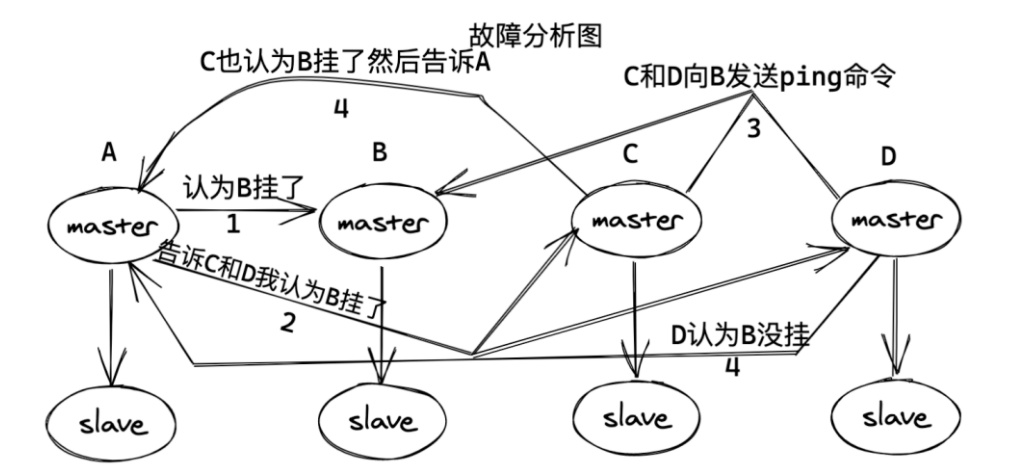
- 1.當A節點發現目標節點疑似下線,就會向集群中的其他節點散播消息,其他節點就會向目標節點發送命令,判斷目標節點是否下線
- 2.如果集群中半數以上的節點都認為目標節點下線,就會對目標節點標記為下線,從而告訴其他節點,讓目標節點在整個集群中都下線
15.主從同步原理是怎樣的?
-
1.當一個從資料庫啟動時,它會向主資料庫發送一個SYNC命令,master收到後,在後台保存快照,也就是我們說的RDB持久化,當然保存快照是需要消耗時間的,並且redis是單執行緒的,在保存快照期間redis受到的命令會快取起來
-
2.快照完成後會將快取的命令以及快照一起打包發給slave節點,從而保證主從資料庫的一致性。
-
3.從資料庫接受到快照以及快取的命令後會將這部分數據寫入到硬碟上的臨時文件當中,寫入完成後會用這份文件去替換掉RDB快照文件,當然,這個操作是不會阻塞的,可以繼續接收命令執行,具體原因其實就是fork了一個子進程,用子進程去完成了這些功能。
因為不會阻塞,所以,這部分初始化完成後,當主資料庫執行了改變數據的命令後,會非同步的給slave,這也就是我們說的複製同步階段,這個階段會貫穿在整個中從同步的過程中,直到主從同步結束後,複製同步才會終止。
16.無硬碟複製是什麼?
我們剛剛說了主從之間是通過RDB快照來交互的,雖然看來邏輯很簡單,但是還是會存在一些問題,但是會存在著一些問題。
-
1.master禁用了RDB快照時,發生了主從同步(複製初始化)操作,也會生成RDB快照,但是之後如果master發成了重啟,就會用RDB快照去恢複數據,這份數據可能已經很久了,中間就會丟失數據
-
2.在這種一主多從的結構中,master每次和slave同步數據都要進行一次快照,從而在硬碟中生成RDB文件,會影響性能
為了解決這種問題,redis在後續的更新中也加入了無硬碟複製功能,也就是說直接通過網路發送給slave,避免了和硬碟交互,但是也是有io消耗的


