Grafana、Prometheus、mtail-日誌監控
- 2021 年 7 月 21 日
- 筆記
一:日誌如何監控
在上一篇部落格Grafana、Prometheus-監控平台中,簡單了解了Grafana與Prometheus對項目做特定的監控打點,可視化的配置操作。
但是對於沒有設置監控或者不容易進行監控的遺留應用程式,有時重寫、修補或重構該應用程式以暴露內部狀態的成本絕對不是一項有利的工程投資,
或者還可能存在監控上的技術限制。但是你仍然需要了解應用程式內部發生的情況,最簡單的方法之一是調整日誌輸出。
就例如在我的另一篇部落格 分散式調度任務-ElasticJob 中遇到的bug,com.dangdangelastic-job中間件會出現一直在選主,導致業務程式執行不下去的問題,
日誌會一直在列印 LeaderElectionService [traceId=] – Elastic job: leader node is electing, waiting for 100 ms at server ‘192.168.0.6’,
像這種問題就很難通過業務打點去監控,因此就需要監控業務系統的日誌文件,進而去監控系統是否出問題。
網上對於業務日誌的監控,我比較過這三個
1:ELK-「ELK」是三個開源項目的首字母縮寫,這三個項目分別是:Elasticsearch、Logstash 和 Kibana。
Elasticsearch 是一個搜索和分析引擎。
Logstash 是伺服器端數據處理管道,能夠同時從多個來源採集數據,轉換數據,然後將數據發送到諸如 Elasticsearch 等「存儲庫」中。
Kibana 則可以讓用戶在 Elasticsearch 中使用圖形和圖表對數據進行可視化。
2:Loki,Grafana Labs 團隊最新的開源項目,是一個水平可擴展,高可用性,多租戶的日誌聚合系統。
3:mtail :它是一個google開發的日誌提取工具,從應用程式日誌中提取指標以導出到時間序列資料庫或時間序列計算器,
用途就是: 實時讀取應用程式的日誌、 再通過自己編寫的腳本進行分析、 最終生成時間序列指標。
工具適合自己的才是最好的,無論是ELK還是Loki都是功能齊全的日誌採集系統,當然它們也有各自的優勢,
但是因為本人當前只是為了採集生產日誌中的一個error,所有並不想去安裝配置多個基建,因為才採用最簡單的mtail。
二:mtail 安裝啟動
下載地址://github.com/google/mtail/releases
安裝:
chmod 0755 mtail sudo cp mtail /usr/local/bin
編寫監控腳本
touch /etc/mtail/Elastic_job_electing_count.mtail
內容如下:
counter elastic_job_electing_count /leader node is electing, waiting for 100 ms at server/ { elastic_job_electing_count ++ }
統計 「leader node is electing, waiting for 100 ms at server」 出現的次數。
當然mtail支援的腳本語法還是比較全的,可以參考://github.com/google/mtail/blob/main/docs/Programming-Guide.md
運行:
sudo mtail --progs /etc/mtail --logs '/var/log/*.log'
第一個參數–progs告訴mtail在哪裡找到我們的程式,第二個參數–logs告訴mtail在哪裡找到要解析的日誌文件。
我們使用glob模式(//godoc.org/path/filepath#Match)來匹配/var/log目錄中的所有日誌文件。
你可以指定以逗號分隔的文件列表,也可以多次指定–logs參數。
參數詳解:控制台運行 mtail –help
下面列舉幾個簡單的參數
參數 描述
-address 綁定HTTP監聽器的主機或IP地址
-alsologtostderr 記錄標準錯誤和文件
-emit_metric_timestamp 發出metric的記錄時間戳。如果禁用(默認設置),則不會向收集器發送顯式時間戳。
-expired_metrics_gc_interval metric的垃圾收集器運行間隔(默認為1h0m0s)
-ignore_filename_regex_pattern 需要忽略的日誌文件名字,支援正則表達式。
-log_dir mtail程式的日誌文件的目錄,與logtostderr作用類似,如果同時配置了logtostderr參數,則log_dir參數無效
-logs 監控的日誌文件列表,可以使用,分隔多個文件,也可以多次使用-logs參數,也可以指定一個文件目錄,支援通配符*,指定文件目錄時需要對目錄使用單引號。如:
-logs a.log,b.log
-logs a.log -logs b.log
-logs 『/export/logs/*.log』
-logtostderr 直接輸出標準錯誤資訊,編譯問題也直接輸出
-override_timezone 設置時區,如果使用此參數,將在時間戳轉換中使用指定的時區來替代UTC
-port 監聽的http埠,默認3903
-progs mtail腳本程式所在路徑
-trace_sample_period 用於設置跟蹤的取樣頻率和發送到收集器的頻率。將其設置為100,則100條收集一條追蹤。
-v v日誌的日誌級別,該設置可能被 vmodule標誌給覆蓋.默認為0.
-version 列印mtail版本
程式啟動後默認監聽3903埠,可以通過//ip:3903訪問,metrics可以通過//ip:3903/metrics訪問
三:配置Prometheus數據源
Prometheus的安裝部署見:Grafana、Prometheus-監控平台
vim prometheus-config.yml
# 全局配置 global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: # 監控mtail日誌 - job_name: 'mtail' static_configs: - targets: ['內網ip:3903']
重啟Prometheus後,在grafana大盤裡新增一個新的panel,再為其配置已經設置好的datasource
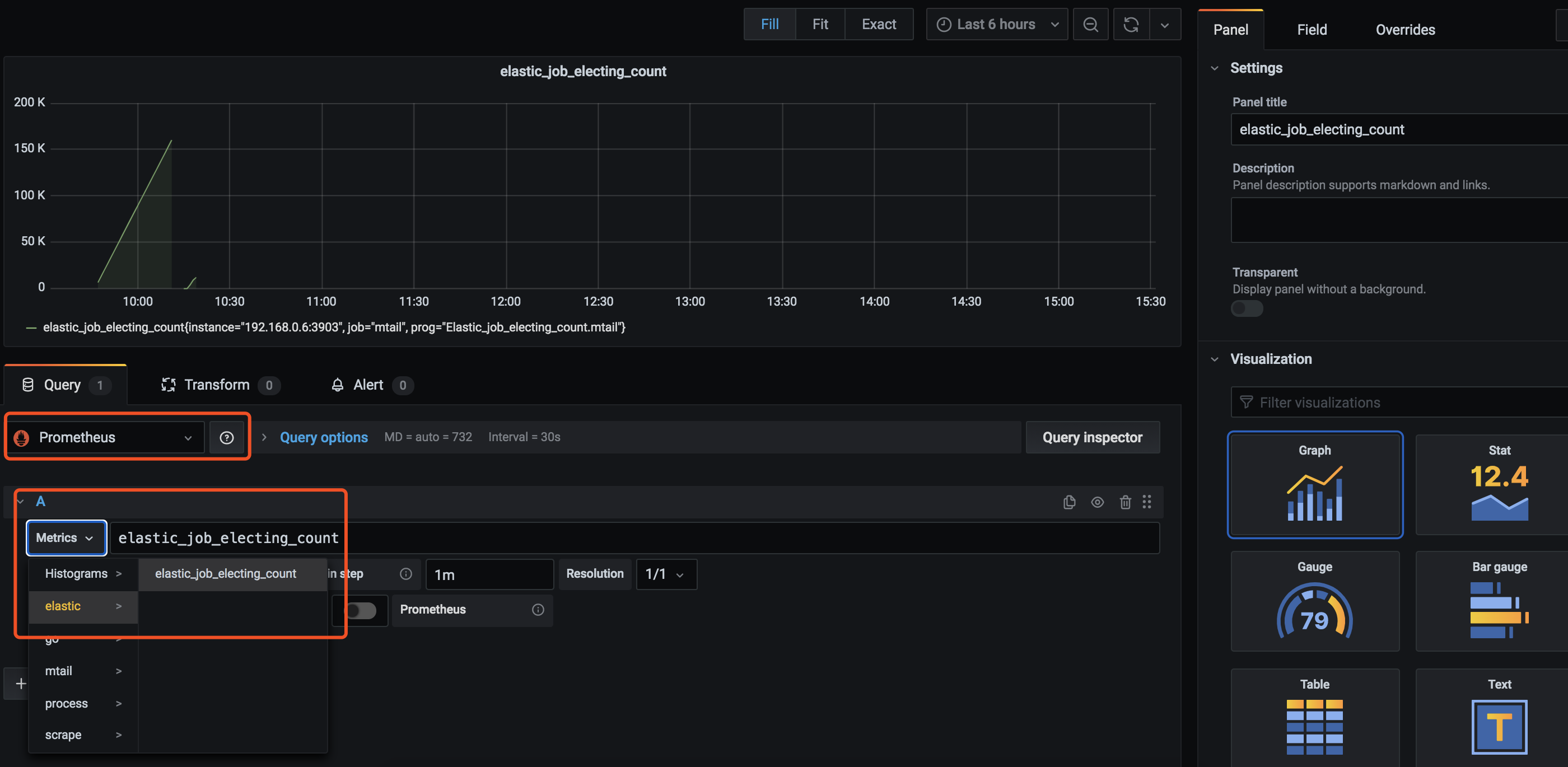
至此,一個簡單去監控業務系統日誌中,出現某段日誌的統計就實現了, 然後再為其配置一個告警規則,並發送釘釘或郵件,就可以方便及時的處理線上的問題了。


