基於混合模型的語音降噪效果提升
上篇文章(基於混合模型的語音降噪實踐)實踐了基於混合模型的演算法來做語音降噪,有了一定的降噪效果。本篇說說怎麼樣來提升降噪效果。
演算法里會算每個音素的高斯模型參數,也會建一個音素分類的神經網路模型。這些都是依賴於音素對齊的,音素對齊做的越好,每個音素的高斯模型越準確,音素分類模型越收斂準確率越高,從而演算法的降噪效果越好。先前做音素對齊用的是開源工具speech-aligner,怎麼樣讓音素對齊做的更好呢?自己做不太現實(不僅周期長,而且相關專業知識積累有限),還得依賴專業工具。調研下來MFA(Montreal-Forced-Aligner,也是基於kaldi的)是目前用的最多的音素對齊工具,且有大廠(比如微軟)在用,品質有保證,同時它支援中文和自己訓練模型。它不僅支援GMM-HMM,還支援DNN-HMM(官網文檔這麼說),用DNN-HMM的語音識別效果是好於GMM-HMM的,直觀上覺得基於DNN-HMM的音素對齊應該是好於基於GMM-HMM的。我用的MFA是最新版本2.0,訓練集還是thchs30(數據集一樣,方便跟先前的結果比較),經過5步(monophone->triphone->lda->sta1->sat2)訓練後得到了模型,基於這個模型得到了每個文件的音素對齊資訊。奇怪的是訓練過程中沒有經過DNN訓練這一步,文檔中明明說支援的呀,調查後發現2.0已不支援DNN訓練,1.1是支援的,網站上的文檔沒有更新,作者只是在回答問題時確認了,並且給了理由,如下圖:
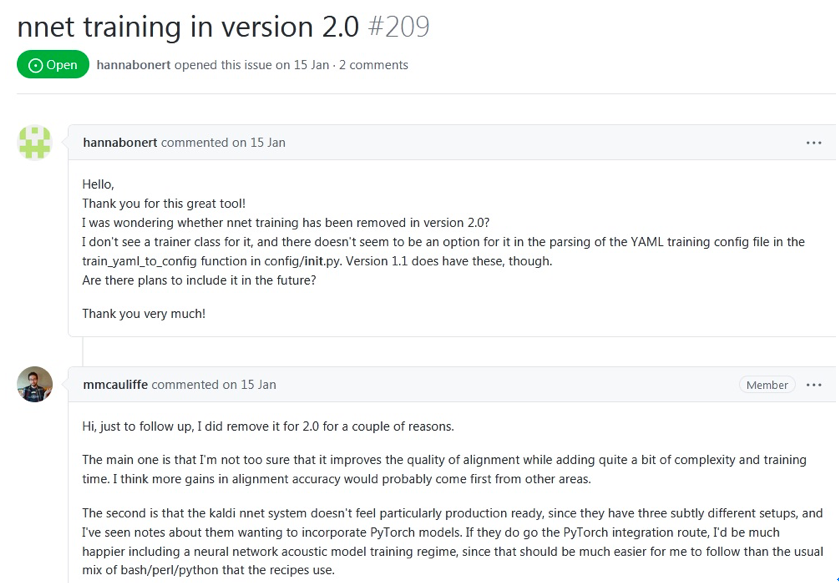
可以看出是作者不確信DNN訓練能否提升對齊品質才在新版本里刪掉DNN訓練的,同時他認為提升對齊的準確率應該來自其他方面。這與直觀的理解有出入,我想他們肯定做過很多次實驗才有這個結論的,不然不會在新版本里刪掉DNN訓練。
MFA和speech-aligner都基於kaldi。MFA有哪些訓練步驟比較清晰,可以基於自己的數據集生成模型。而speech-aligner不知道有哪些訓練步驟(沒調查到相關資訊, 後來用以前做kaldi時生成的工具解析了它提供的模型文件,可以確認的是GMM),且只能用它提供的模型,不支援自己訓練生成模型。看上去MFA中文音素分類更合理些,不像speech-aligner只根據聲韻母分,比如MFA中ting1分成 t i1 ng三個音素,而speech-aligner分成t ing1兩個音素。 基於上面的比較,我覺得用MFA(基於大數據集訓練自己的模型)音素對齊準確率是優於speech-aligner的。
有了每個語音文件的音素對齊資訊後,還像先前那樣把屬於同一個音素的所有幀放在一起算高斯模型參數,也得到了每個語音文件每幀所屬音素label的CSV文件,用來訓練音素分類網路模型(模型訓練時網路結構、層數等均不改變,唯一改變的是每個語音文件每幀所屬音素label的CSV文件)。訓練後驗證集和測試集下的準確率分別是0.79和0.76,較先前用speech-aligner都有0.1左右的提高。從這結果可以看出MFA的音素對齊效果是好於speech-aligner的。拿一批先前的雜訊為NOISEX-92中的white白雜訊的語音文件做降噪(這些語料在用speech-aligner時也用過,有降噪後的音頻,方便比較),同樣用PESQ來做評估,與用speech-aligner時降噪MOS均值提升如下表:

從上表看出,在低SNR(0和5 dB)時,用兩種對齊工具MOS值沒明顯變化,估計是雜訊較大,經過兩種音素分類網路後音素判別準確率差不多。在高SNR(10和15 dB)時,用MFA的MOS值相比用speech-aligner提升明顯。高SNR時,雜訊較小,經過MFA對齊的音素分類網路後音素判別準確率高一些,從而也使降噪效果好些。
通過使用新的音素對齊工具明顯提升了高SNR下的降噪效果,低SNR下的沒提升。怎麼樣才能讓低SNR下的降噪效果也提升呢?我想到了前面做KWS關鍵詞識別時用到的加噪訓練方法。語音識別中通過給乾淨語音疊加雜訊去訓練,能顯著提升帶噪語音的識別率。因為用於降噪的文件中的雜訊是NOISEX-92中的white白雜訊,所以訓練時疊加雜訊也用這種典型雜訊,分別以4種SNR(0/5/10/15 dB)疊加到乾淨語音中看效果。這裡把乾淨語音和雜訊按指定的SNR做疊加簡單說一下。以乾淨語音為基準,保持不變,改變雜訊的能量從而滿足SNR的要求,然後疊加到乾淨語音上得到帶噪語音。SNR公式是SNR = 10*log10(C/N),其中C和N分別表示乾淨語音和期望雜訊的平均功率。變形得到N = C/10(SNR/10))。假設真實雜訊平均功率是P,幅值為n,期望雜訊的幅值為x,由於平均功率和幅值是平方的關係,所以N/P = x2/n2,從而求得期望雜訊的幅值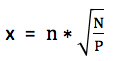 。假設原乾淨語音的幅值為c,所以最終疊加後的語音幅值為 (c + x)。寫成python程式碼大致如下圖所示:
。假設原乾淨語音的幅值為c,所以最終疊加後的語音幅值為 (c + x)。寫成python程式碼大致如下圖所示:

訓練後得到了新的音素分類網路模型,不管是驗證集還是測試集,準確率都比加噪前有所下降。 基於新的模型對先前的帶噪語音降噪,發現低SNR下的MOS值有0.1左右的提升,高SNR下的提升不明顯,具體如下表:

上表驗證了通過加噪訓練能提升低SNR下的降噪效果。這裡只是實驗,只加了一種要降噪的帶噪語音里的雜訊。實際中各種雜訊都有,需要把乾淨語音疊加多種雜訊去訓練。為了再提升降噪效果,我又嘗試了加大音素分類模型的參數個數(用的是CNN網路,加大網路的層數),從兩倍到四倍都試驗過,均不能明顯提升MOS均值(MOS值提升都小於0.05)。這說明加大模型參數對降噪沒什麼效果。
總結下,為了提升降噪效果,我做了三種嘗試,分別是用更好的音素對齊工具使音素對齊的更準確、加噪訓練音素分類網路模型和加大音素分類模型的參數,前兩種分別對高SNR和低SNR的語音降噪有效果,第三種沒什麼效果。加上混合模型的演算法本身,各種SNR下的語音降噪MOS值提升在0.4~0.5之間。


