關於Hadoop調優
Hadoop生產調優
一、HDFS—核心參數
1、NameNode 記憶體生產配置
1) NameNode 記憶體計算
每個文件塊大概佔用 150byte,一台伺服器 128G 記憶體為例,能存儲多少文件塊呢?
128 * 1024 * 1024 * 1024 / 150Byte ≈ 9.1 億
2) Hadoop2.x 系列,配置 NameNode 記憶體
NameNode 記憶體默認 2000m,如果伺服器記憶體 4G,NameNode 記憶體可以配置 3g。在hadoop-env.sh 文件中配置如下。
HADOOP_NAMENODE_OPTS=-Xmx3072m
3) Hadoop3.x 系列,配置 NameNode 記憶體
(1)hadoop-env.sh 中描述 Hadoop 的記憶體是動態分配的
# The maximum amount of heap to use (Java -Xmx). If no unit
# is provided, it will be converted to MB. Daemons will
# prefer any Xmx setting in their respective _OPT variable.
# There is no default; the JVM will autoscale based upon machine
# memory size.
# export HADOOP_HEAPSIZE_MAX=
# 要使用的最大堆數量(Java -Xmx)。如果沒有提供單位,它將被轉換為MB。守護進程會更喜歡在它們各自的_OPT變數中設置任何Xmx。沒有違約;JVM將根據機器記憶體大小自動伸縮。
# The minimum amount of heap to use (Java -Xms). If no unit
# is provided, it will be converted to MB. Daemons will
# prefer any Xms setting in their respective _OPT variable.
# There is no default; the JVM will autoscale based upon machine
# memory size.
# export HADOOP_HEAPSIZE_MIN=
# 要使用的最小堆數量(Java -Xms)。如果沒有提供單位,它將被轉換為MB。守護進程會更喜歡在它們各自的_OPT變數中設置任何Xms。沒有違約;JVM將根據機器記憶體大小自動伸縮。
HADOOP_NAMENODE_OPTS=-Xmx102400m
(2)查看 NameNode 佔用記憶體
[chaos@hadoop102 ~]$ jps
3088 NodeManager
2611 NameNode
3271 JobHistoryServer
2744 DataNode
3579 Jps
[chaos@hadoop102 ~]$ jmap -heap 2611
Heap Configuration:
MaxHeapSize = 1031798784 (984.0MB)
(3)查看 DataNode 佔用記憶體
[chaos@hadoop102 ~]$ jmap -heap 2744
Heap Configuration:
MaxHeapSize = 1031798784 (984.0MB)
查看發現 hadoop102 上的 NameNode 和 DataNode 佔用記憶體都是自動分配的,且相等。不是很合理。 經驗參考:
| Component | Memory | CPU | Disk |
|---|---|---|---|
| JournalNode 日誌節點 | 1 GB (default)Set this value using the Java Heap Size of JournalNode in Bytes HDFS configuration property. 1 GB(默認)使用位元組HDFS 配置屬性中 JournalNode的Java 堆大小設置此值。 |
1 core minimum 最少 1 個核心 |
1 dedicated disk 1個專用磁碟 |
| NameNode | Minimum: 1 GB (for proof-of-concept deployments) Add an additional 1 GB for each additional 1,000,000 blocksSnapshots and encryption can increase the required heap memory. See Sizing NameNode Heap Memory Set this value using the Java Heap Size of NameNode in Bytes HDFS configuration property.最低:1 GB(用於概念驗證部署) 每增加 1,000,000 個block 增加 1 GB 快照和加密可以增加所需的堆記憶體。 請參閱調整 NameNode 堆記憶體大小 使用位元組HDFS 配置屬性中 NameNode的Java 堆大小設置此值。 |
Minimum of 4 dedicated cores; more may be required for larger clusters 最少 4 個專用內核;更大的集群可能需要更多 |
Minimum of 2 dedicated disks for metadata1 dedicated disk for log files (This disk may be shared with the operating system.)Maximum disks: 4 至少 2 個用於元數據的專用磁碟 1 個用於日誌文件的專用磁碟(該磁碟可能與作業系統共享。) 最大磁碟數:4 |
| DataNode | Minimum: 4 GBIncrease the memory for higher replica counts or a higher number of blocks per DataNode. When increasing the memory, Cloudera recommends an additional 1 GB of memory for every 1 million replicas above 4 million on the DataNodes. For example, 5 million replicas require 5 GB of memory.Set this value using the Java Heap Size of DataNode in Bytes HDFS configuration property. 最低:4 GB 增加記憶體以獲得更高的副本計數或每個 DataNode 的更多塊數。在增加記憶體時,Cloudera 建議為 DataNode 上 400 萬個以上的每 100 萬個副本增加 1 GB 記憶體。例如,500 萬個副本需要 5 GB 記憶體。 使用位元組HDFS 配置屬性中 DataNode的Java 堆大小設置此值。 |
Minimum: 4 cores. Add more cores for highly active clusters. 最低:4 核。為高度活躍的集群添加更多核心。 |
Minimum: 4Maximum: 24The maximum acceptable size will vary depending upon how large average block size is. The DN』s scalability limits are mostly a function of the number of replicas per DN, not the overall number of bytes stored. That said, having ultra-dense DNs will affect recovery times in the event of machine or rack failure. Cloudera does not support exceeding 100 TB per data node. You could use 12 x 8 TB spindles or 24 x 4TB spindles. Cloudera does not support drives larger than 8 TB. 最少:4 最大:24 最大可接受大小將取決於平均塊大小有多大。DN 的可擴展性限制主要取決於每個 DN 的副本數,而不是存儲的總位元組數。也就是說,如果機器或機架出現故障,擁有超密集 DN 將影響恢復時間。Cloudera 不支援每個數據節點超過 100 TB。您可以使用 12 x 8 TB 軸或 24 x 4TB 軸。Cloudera 不支援大於 8 TB 的驅動器。 |
具體修改:hadoop-env.sh
export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS - Xmx1024m"
export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS -Xmx1024m"
2、NameNode 心跳並發配置
hdfs-site.xml
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode有一個工作執行緒池,用來處理不同DataNode的並發心跳以及客戶端並發的元數據操作。對於大集群或者有大量客戶端的集群來說,通常需要增大該參數。默認值是10。
<property>
<name>dfs.namenode.handler.count</name>
<value>21</value>
</property>
企業經驗
dfs.namenode.handler.count=20 × 𝑙𝑜𝑔𝑒^𝐶𝑙𝑢𝑠𝑡𝑒𝑟𝑆𝑖𝑧e
比如集群規模(DataNode 台 數)為 3 台時,此參數設置為 21。可通過簡單的 python 程式碼計算該值,程式碼如下。
[chaos@hadoop102 ~]$ sudo yum install -y python
[chaos@hadoop102 ~]$ python
Python 2.7.5 (default, Apr 11 2018, 07:36:10)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux2
Type "help", "copyright", "credits" or "license" for more
information.
>>> import math
>>> print int(20*math.log(3))
21
>>> quit()
3、開啟回收站配置
開啟回收站功能,可以將刪除的文件在不超時的情況下,恢復原數據,起到防止誤刪除、 備份等作用。
1)回收站工作機制
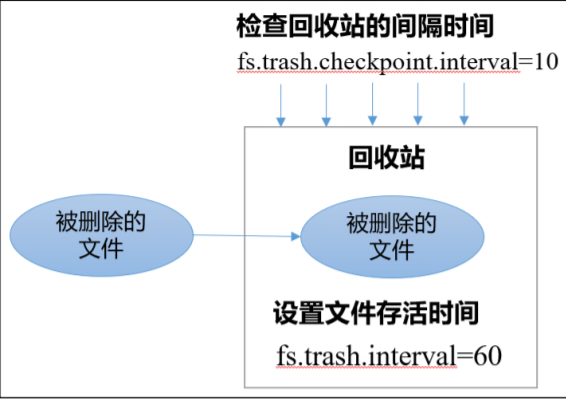
2)開啟回收站功能參數說明
(1)默認值 fs.trash.interval = 0,0 表示禁用回收站;其他值表示設置文件的存活時間。
(2)默認值 fs.trash.checkpoint.interval = 0,檢查回收站的間隔時間。如果該值為 0,則該值設置和 fs.trash.interval 的參數值相等。
(3)要求 fs.trash.checkpoint.interval <= fs.trash.interval。
3)啟用回收站
修改 core-site.xml,配置垃圾回收時間為 1 分鐘
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
4)查看回收站
回收站目錄在 HDFS 集群中的路徑:/user/chaos/.Trash/….
5)注意
(1)通過網頁上直接刪除的文件也不會走回收站。
(2)通過程式刪除的文件不會經過回收站,需要調用 moveToTrash()才進入回收站
Trash trash = New Trash(conf); trash.moveToTrash(path);
(3)只有在命令行利用 hadoop fs -rm 命令刪除的文件才會走回收站。
[chaos@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r
/user/chaos/input
2021-07-14 16:13:42,643 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hadoop102:9820/user/chaos/input' to trash at: hdfs://hadoop102:9820/user/chaos/.Trash/Current/user/chaos /input
8)恢復回收站數據
[chaos@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /user/chaos/.Trash/Current/user/chaos/input /user/chaos/input
二、HDFS—集群壓測
在企業中非常關心每天從 Java 後台拉取過來的數據,需要多久能上傳到集群?消費者關心多久能從 HDFS 上拉取需要的數據?
為了搞清楚 HDFS 的讀寫性能,生產環境上非常需要對集群進行壓測
HDFS 的讀寫性能主要受網路和磁碟影響比較大。為了方便測試,將 hadoop102、 hadoop103、hadoop104 虛擬機網路都設置為 100mbps。
100Mbps 單位是 bit;10M/s 單位是 byte ; 1byte=8bit,100Mbps/8=12.5M/s。測試網速:來到 hadoop102 的/opt/module 目錄,創建一個
[chaos@hadoop102 software]$ python -m SimpleHTTPServer
1、測試 HDFS 寫性能
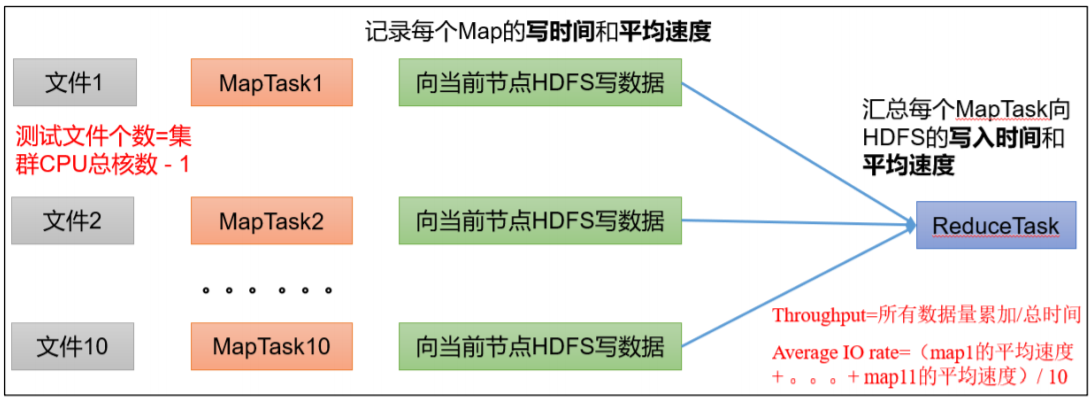
寫測試底層原理:
1)測試內容:向 HDFS 集群寫 10 個 128M 的文件
[chaos@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-clientjobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 10 fileSize 128MB
2021-02-09 10:43:16,853 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Date & time: Tue Feb
09 10:43:16 CST 2021
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Number of files: 10
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Total MBytes processed: 1280
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Throughput mb/sec: 1.61
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Average IO rate mb/sec: 1.9
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: IO rate std deviation: 0.76 2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Test exec time sec: 133.05 2021-02-09 10:43:16,854 INFO fs.TestDFSIO:
注意:nrFiles n 為生成 mapTask 的數量,生產環境一般可通過 hadoop103:8088 查看 CPU 核數,設置為(CPU 核數 – 1)
Number of files:生成 mapTask 數量,一般是集群中(CPU 核數-1),我們測試虛擬機就按照實際的物理記憶體-1 分配即可
Total MBytes processed:單個 map 處理的文件大小
Throughput mb/sec:單個 mapTak 的吞吐量
計算方式:處理的總文件大小/每一個 mapTask 寫數據的時間累加集群整體吞吐量:生成 mapTask 數量*單個 mapTak 的吞吐量
Average IO rate mb/sec::平均 mapTak 的吞吐量
計算方式:每個 mapTask 處理文件大小/每一個 mapTask 寫數據的時間
全部相加除以 task 數量
IO rate std deviation:方差、反映各個 mapTask 處理的差值,越小越均衡
2)注意:如果測試過程中,出現異常
(1)可以在 yarn-site.xml 中設置虛擬記憶體檢測為 false
<!--是否啟動一個執行緒檢查每個任務正使用的虛擬記憶體量,如果任務超出分配值,則直接將其殺掉,默認是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
(2)分發配置並重啟 Yarn 集群
3)測試結果分析
(1)由於副本 1 就在本地,所以該副本不參與測試
一共參與測試的文件:10 個文件 * 2 個副本 = 20 個壓測後的速度:1.61
實測速度:1.61M/s * 20 個文件 ≈ 32M/s 三台伺服器的頻寬:12.5 + 12.5 + 12.5 ≈ 30m/s
所有網路資源都已經用滿。
如果實測速度遠遠小於網路,並且實測速度不能滿足工作需求,可以考慮採用固態硬碟或者增加磁碟個數。
(2)如果客戶端不在集群節點,那就三個副本都參與計算
2、測試 HDFS 讀性能
1)測試內容:讀取 HDFS 集群 10 個 128M 的文件
[chaos@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-
3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-clientjobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 10 -fileSize
128MB
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Date & time: Tue Feb
09 11:34:15 CST 2021
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Number of files: 10
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Total MBytes processed: 1280
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Throughput mb/sec: 200.28
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Average IO rate mb/sec: 266.74
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: IO rate std deviation: 143.12
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Test exec time sec: 20.83
2)刪除測試生成數據
[chaos@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-clientjobclient-3.1.3-tests.jar TestDFSIO -clean
測試結果分析:為什麼讀取文件速度大於網路頻寬?由於目前只有三台伺服器,且有三個副本,數據讀取就近原則,相當於都是讀取的本地磁碟數據,沒有走網路。
3、HDFS—多目錄
NameNode 多目錄配置
1)NameNode 的本地目錄可以配置成多個,且每個目錄存放內容相同,增加了可靠性
2)具體配置如下
在 hdfs-site.xml 文件中添加如下內容
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp. dir}/dfs/name2</value>
</property>
注意:因為每台伺服器節點的磁碟情況不同,所以這個配置配完之後,可以選擇不分發(2)停止集群,刪除三台節點的 data 和 logs 中所有數據。
[chaos@hadoop102 hadoop-3.1.3]$ rm -rf data/ logs/
[chaos@hadoop103 hadoop-3.1.3]$ rm -rf data/ logs/
[chaos@hadoop104 hadoop-3.1.3]$ rm -rf data/ logs/
(3)格式化集群並啟動。
[chaos@hadoop102 hadoop-3.1.3]$ bin/hdfs namenode -format
[chaos@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
3)查看結果
[chaos@hadoop102 dfs]$ ll
總用量 12
drwx------. 3 chaos chaos 4096 12月 11 08:03 data
drwxrwxr-x. 3 chaos chaos 4096 12月 11 08:03 name1
drwxrwxr-x. 3 chaos chaos 4096 12月 11 08:03 name2
檢查 name1 和 name2 裡面的內容,發現一模一樣
DataNode 多目錄配置
1)DataNode 可以配置成多個目錄,每個目錄存儲的數據不一樣(數據不是副本)
2)具體配置如下
在 hdfs-site.xml 文件中添加如下內容
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value>
</property>
3)查看結果
[chaos@hadoop102 dfs]$ ll
總用量 12
drwx------. 3 chaos chaos 4096 4月 4 14:22 data1
drwx------. 3 chaos chaos 4096 4月 4 14:22 data2
drwxrwxr-x. 3 chaos chaos 4096 12月 11 08:03 name1
drwxrwxr-x. 3 chaos chaos 4096 12月 11 08:03 name2
4)向集群上傳一個文件,再次觀察兩個文件夾裡面的內容發現不一致(一個有數一個沒有)
[chaos@hadoop102 hadoop-3.1.3]$ hadoop fs -put wcinput/word.txt /
三、 集群數據均衡之磁碟間數據均衡
生產環境,由於硬碟空間不足,往往需要增加一塊硬碟。剛載入的硬碟沒有數據時,可以執行磁碟數據均衡命令。(Hadoop3.x 新特性)
1、生成均衡計劃
(如果只有一塊磁碟,不會生成計劃)
hdfs diskbalancer -plan hadoop103
2、執行均衡計劃
hdfs diskbalancer -execute hadoop103.plan.json
3、查看當前均衡任務的執行情況
hdfs diskbalancer -query hadoop103
4、取消均衡任務
hdfs diskbalancer -cancel hadoop103.plan.json
四、 HDFS—集群擴容及縮容
1、添加白名單
白名單:表示在白名單的主機 IP 地址可以,用來存儲數據。
企業中:配置白名單,可以盡量防止黑客惡意訪問攻擊。
配置白名單步驟如下:
1)在 NameNode 節點的/opt/module/hadoop-3.1.3/etc/hadoop 目錄下分別創建 whitelist 和 blacklist 文件
(1)創建白名單
[chaos@hadoop102 hadoop]$ vim whitelist
在 whitelist 中添加如下主機名稱,假如集群正常工作的節點為 102 103
hadoop102 hadoop103
(2)創建黑名單
[chaos@hadoop102 hadoop]$ touch blacklist
保持空的就可以
2)在 hdfs-site.xml 配置文件中增加 dfs.hosts 配置參數
<!-- 白名單 -->
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/whitelist</value>
</property>
<!-- 黑名單 -->
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>
3)分發配置文件 whitelist,hdfs-site.xml
[chaos@hadoop104 hadoop]$ xsync hdfs-site.xml whitelist
4)第一次添加白名單必須重啟集群,不是第一次,只需要刷新 NameNode 節點即可
[chaos@hadoop102 hadoop-3.1.3]$ myhadoop.sh stop
[chaos@hadoop102 hadoop-3.1.3]$ myhadoop.sh start
5)在 web 瀏覽器上查看 DN,//hadoop102:9870/dfshealth.html#tab-datanode
6)在 hadoop104 上執行上傳數據數據失敗
[chaos@hadoop104 hadoop-3.1.3]$ hadoop fs -put NOTICE.txt /
7)二次修改白名單,增加 hadoop104
[chaos@hadoop102 hadoop]$ vim whitelist
修改為如下內容
hadoop102
hadoop103
hadoop104
8)刷新 NameNode
[chaos@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
9)在 web 瀏覽器上查看 DN,//hadoop102:9870/dfshealth.html#tab-datanode
2、服役新伺服器
1)需求
隨著公司業務的增長,數據量越來越大,原有的數據節點的容量已經不能滿足存儲數據的需求,需要在原有集群基礎上動態添加新的數據節點。
2)環境準備
(1)在 hadoop100 主機上再克隆一台 hadoop105 主機
(2)修改 IP 地址和主機名稱
[root@hadoop105 ~]# vim /etc/sysconfig/network-scripts/ifcfgens33
[root@hadoop105 ~]# vim /etc/hostname
(3)拷貝 hadoop102 的/opt/module 目錄和/etc/profile.d/my_env.sh 到 hadoop105
[chaos@hadoop102 opt]$ scp -r module/* chaos@hadoop105:/opt/module/
[chaos@hadoop102 opt]$ sudo scp /etc/profile.d/my_env.sh root@hadoop105:/etc/profile.d/my_env.sh
[chaos@hadoop105 hadoop-3.1.3]$ source /etc/profile
(4)刪除 hadoop105 上 Hadoop 的歷史數據,data 和 log 數據
[chaos@hadoop105 hadoop-3.1.3]$ rm -rf data/ logs/
(5)配置 hadoop102 和 hadoop103 到 hadoop105 的 ssh 無密登錄
[chaos@hadoop102 .ssh]$ ssh-copy-id hadoop105
[chaos@hadoop103 .ssh]$ ssh-copy-id hadoop105
3)服役新節點具體步驟
直接啟動 DataNode,即可關聯到集群
[chaos@hadoop105 hadoop-3.1.3]$ hdfs --daemon start datanode
[chaos@hadoop105 hadoop-3.1.3]$ yarn --daemon start nodemanager
4)在白名單中增加新服役的伺服器
(1)在白名單 whitelist 中增加 hadoop104、hadoop105,並重啟集群
[chaos@hadoop102 hadoop]$ vim whitelist
hadoop102
hadoop103
hadoop104
hadoop105
(2)分發
[chaos@hadoop102 hadoop]$ xsync whitelist
(3)刷新 NameNode
[chaos@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes Refresh nodes successful
5)在 hadoop105 上上傳文件
[chaos@hadoop105 hadoop-3.1.3]$ hadoop fs -put /opt/module/hadoop-3.1.3/LICENSE.txt /
3、伺服器間數據均衡
1)企業經驗
在企業開發中,如果經常在 hadoop102 和 hadoop104 上提交任務,且副本數為 2,由於數據本地性原則,就會導致 hadoop102 和 hadoop104 數據過多,hadoop103 存儲的數據量小。
另一種情況,就是新服役的伺服器數據量比較少,需要執行集群均衡命令。
2)開啟數據均衡命令:
[chaos@hadoop105 hadoop-3.1.3]$ sbin/start-balancer.sh -
threshold 10
對於參數 10,代表的是集群中各個節點的磁碟空間利用率相差不超過 10%,可根據實際情況進行調整。
3)停止數據均衡命令:
[chaos@hadoop105 hadoop-3.1.3]$ sbin/stop-balancer.sh
注意:由於 HDFS 需要啟動單獨的 Rebalance Server 來執行 Rebalance 操作,所以盡量不要在 NameNode 上執行 start-balancer.sh,而是找一台比較空閑的機器。
4、黑名單退役伺服器
黑名單:表示在黑名單的主機 IP 地址不可以,用來存儲數據。
企業中:配置黑名單,用來退役伺服器。
1)編輯/opt/module/hadoop-3.1.3/etc/hadoop 目錄下的 blacklist 文件
[chaos@hadoop102 hadoop] vim blacklist
添加如下主機名稱(要退役的節點)
hadoop105
注意:如果白名單中沒有配置,需要在 hdfs-site.xml 配置文件中增加 dfs.hosts 配置參數
<!-- 黑名單 -->
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>
2)分發配置文件 blacklist,hdfs-site.xml
[chaos@hadoop104 hadoop]$ xsync hdfs-site.xml blacklist
3)第一次添加黑名單必須重啟集群,不是第一次,只需要刷新 NameNode 節點即可
[chaos@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes Refresh nodes successful
4)檢查 Web 瀏覽器,退役節點的狀態為 decommission in progress(退役中),說明數據節點正在複製塊到其他節點
5)等待退役節點狀態為 decommissioned(所有塊已經複製完成),停止該節點及節點資源管理器。注意:如果副本數是 3,服役的節點小於等於 3,是不能退役成功的,需要修改副本數後才能退役
[chaos@hadoop105 hadoop-3.1.3]$ hdfs --daemon stop datanode
stopping datanode
[chaos@hadoop105 hadoop-3.1.3]$ yarn --daemon stop nodemanager
stopping nodemanager
6)如果數據不均衡,可以用命令實現集群的再平衡
[chaos@hadoop102 hadoop-3.1.3]$ sbin/start-balancer.sh -threshold 10
五、HDFS—存儲優化
1、糾刪碼
糾刪碼原理 HDFS 默認情況下,一個文件有 3 個副本,這樣提高了數據的可靠性,但也帶來了 2 倍 的冗餘開銷。Hadoop3.x 引入了糾刪碼,採用計算的方式,可以節省約 50%左右的存儲空間。
1)糾刪碼操作相關的命令
[chaos@hadoop102 hadoop-3.1.3]$ hdfs ec
Usage: bin/hdfs ec [COMMAND]
[-listPolicies]
[-addPolicies -policyFile <file>]
[-getPolicy -path <path>]
[-removePolicy -policy <policy>]
[-setPolicy -path <path> [-policy <policy>] [-replicate]]
[-unsetPolicy -path <path>]
[-listCodecs]
[-enablePolicy -policy <policy>]
[-disablePolicy -policy <policy>]
[-help <command-name>].
2)查看當前支援的糾刪碼策略
[chaos@hadoop102 hadoop-3.1.3] hdfs ec -listPolicies
Erasure Coding Policies:
ErasureCodingPolicy=[Name=RS-10-4-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=10, numParityUnits=4]], CellSize=1048576, Id=5], State=DISABLED
ErasureCodingPolicy=[Name=RS-3-2-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=3, numParityUnits=2]], CellSize=1048576, Id=2],
State=DISABLED
ErasureCodingPolicy=[Name=RS-6-3-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=1],
State=**ENABLED**
ErasureCodingPolicy=[Name=RS-LEGACY-6-3-1024k,
Schema=[ECSchema=[Codec=rs-legacy, numDataUnits=6, numParityUnits=3]],
CellSize=1048576, Id=3], State=DISABLED
ErasureCodingPolicy=[Name=XOR-2-1-1024k, Schema=[ECSchema=[Codec=xor, numDataUnits=2, numParityUnits=1]], CellSize=1048576, Id=4], State=DISABLED
3)糾刪碼策略解釋:
RS-3-2-1024k:使用 RS 編碼,每 3 個數據單元,生成 2 個校驗單元,共 5 個單元,也就是說:這 5 個單元中,只要有任意的 3 個單元存在(不管是數據單元還是校驗單元,只要總數=3),就可以得到原始數據。每個單元的大小是 1024k=1024*1024=1048576。
RS-10-4-1024k:使用 RS 編碼,每 10 個數據單元(cell),生成 4 個校驗單元,共 14個單元,也就是說:這 14 個單元中,只要有任意的 10 個單元存在(不管是數據單元還是校驗單元,只要總數=10),就可以得到原始數據。每個單元的大小是 1024k=1024*1024=1048576。
RS-6-3-1024k:使用 RS 編碼,每 6 個數據單元,生成 3 個校驗單元,共 9 個單元,也就是說:這 9 個單元中,只要有任意的 6 個單元存在(不管是數據單元還是校驗單元,只要總數=6),就可以得到原始數據。每個單元的大小是 1024k=1024*1024=1048576。
RS-LEGACY-6-3-1024k:策略和上面的 RS-6-3-1024k 一樣,只是編碼的演算法用的是 rslegacy。
XOR-2-1-1024k:使用 XOR 編碼(速度比 RS 編碼快),每 2 個數據單元,生成 1 個校驗單元,共 3 個單元,也就是說:這 3 個單元中,只要有任意的 2 個單元存在(不管是數據單元還是校驗單元,只要總數= 2),就可以得到原始數據。每個單元的大小是1024k=1024*1024=1048576。
4)糾刪碼案例實操
糾刪碼策略是給具體一個路徑設置。所有往此路徑下存儲的文件,都會執行此策略。默認只開啟對 RS-6-3-1024k 策略的支援,如要使用別的策略需要提前啟用。
1)需求:將/input 目錄設置為 RS-3-2-1024k 策略
2)具體步驟
(1)開啟對 RS-3-2-1024k 策略的支援
[chaos@hadoop102 hadoop-3.1.3]$ hdfs ec -enablePolicy -policy RS-3-2-1024k
Erasure coding policy RS-3-2-1024k is enabled
(2)在 HDFS 創建目錄,並設置 RS-3-2-1024k 策略
[chaos@hadoop102 hadoop-3.1.3]$ hdfs dfs -mkdir /input
[chaos@hadoop202 hadoop-3.1.3]$ hdfs ec -setPolicy -path /input -policy RS-3-2-1024k
(3)上傳文件,並查看文件編碼後的存儲情況
[chaos@hadoop102 hadoop-3.1.3]$ hdfs dfs -put web.log /input
註:你所上傳的文件需要大於 2M 才能看出效果。(低於 2M,只有一個數據單元和兩個校驗單元)
(4)查看存儲路徑的數據單元和校驗單元,並作破壞實驗
2、異構存儲(冷熱數據分離)
異構存儲主要解決,不同的數據,存儲在不同類型的硬碟中,達到最佳性能的問題。
1)關於存儲類型
RAM_DISK:(記憶體鏡像文件系統)
SSD:(SSD固態硬碟)
DISK:(普通磁碟,在HDFS中,如果沒有主動聲明數據目錄存儲類型默認都是DISK)
ARCHIVE:(沒有特指哪種存儲介質,主要的指的是計算能力比較弱而存儲密度比較高的存儲介質,用來解決數據量的容量擴增的問題,一般用于歸檔)
2)關於存儲策略
說明:從Lazy_Persist到Cold,分別代表了設備的訪問速度從快到慢
| 策略ID | 策略名稱 | 副本分布 | 策略 |
|---|---|---|---|
| 15 | Lazy_Persist | RAM_DISK:1,DISK:n-1 | 一個副本保存在記憶體RAM_DISK中,其餘副本保存在磁碟中。 |
| 12 | All_SSD | SSD:n | 所有副本都保存在SSD中。 |
| 10 | One_SSD | SSD:1,DISK:n-1 | 一個副本保存在SSD中,其餘副本保存在磁碟中。 |
| 7 | Hot(default) | DISK:n | Hot:所有副本保存在磁碟中,這也是默認的存儲策略。 |
| 5 | Warm | DSIK:1,ARCHIVE:n-1 | 一個副本保存在磁碟上,其餘副本保存在歸檔存儲上。 |
| 2 | Cold | ARCHIVE:n | 所有副本都保存在歸檔存儲上。 |
3)異構存儲 Shell 操作
(1) 查看當前有哪些存儲策略可以用
[chaos@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies listPolicies
(2) 為指定路徑(數據存儲目錄)設置指定的存儲策略
hdfs storagepolicies -setStoragePolicy -path xxx -policy xxx
(3) 獲取指定路徑(數據存儲目錄或文件)的存儲策略
hdfs storagepolicies -getStoragePolicy -path xxx
(4) 取消存儲策略;執行改命令之後該目錄或者文件,以其上級的目錄為準,如果是根目錄,那麼就是 HOT
hdfs storagepolicies -unsetStoragePolicy -path xxx
(5) 查看文件塊的分布
bin/hdfs fsck xxx -files -blocks -locations
(6) 查看集群節點
hadoop dfsadmin -report
六、HDFS—故障排除
1、NameNode 故障處理
1)需求:
NameNode 進程掛了並且存儲的數據也丟失了,如何恢復 NameNode
2)故障模擬
(1)kill -9 NameNode 進程
[chaos@hadoop102 current]$ kill -9 19886
(2)刪除 NameNode 存儲的數據(/opt/module/hadoop-3.1.3/data/tmp/dfs/name)
[chaos@hadoop102 hadoop-3.1.3]$ rm -rf /opt/module/hadoop-1.3/data/dfs/name/*
3)問題解決
(1)拷貝 SecondaryNameNode 中數據到原 NameNode 存儲數據目錄
[chaos@hadoop102 dfs]$ scp -r chaos@hadoop104:/opt/module/hadoop-3.1.3/data/dfs/namesecondary/* ./name/
(2)重新啟動 NameNode
[chaos@hadoop102 hadoop-3.1.3]$ hdfs --daemon start namenode
(3)向集群上傳一個文件
2、集群安全模式&磁碟修復
1)安全模式
文件系統只接受讀數據請求,而不接受刪除、修改等變更請求
2)進入安全模式場景
NameNode 在載入鏡像文件和編輯日誌期間處於安全模式;
NameNode 再接收 DataNode 註冊時,處於安全模式
3)退出安全模式條件
dfs.namenode.safemode.min.datanodes:最小可用 datanode 數量,默認 0
dfs.namenode.safemode.threshold-pct:副本數達到最小要求的 block 占系統總 block 數的百分比,默認 0.999f。(只允許丟一個塊)
dfs.namenode.safemode.extension:穩定時間,默認值 30000 毫秒,即 30 秒
4)基本語法
集群處於安全模式,不能執行重要操作(寫操作)。集群啟動完成後,自動退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式狀態)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:進入安全模式狀態)
(3)bin/hdfs dfsadmin -safemode leave(功能描述:離開安全模式狀態)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式狀態)
3、慢磁碟監控
「慢磁碟」指的時寫入數據非常慢的一類磁碟。其實慢性磁碟並不少見,當機器運行時間長了,上面跑的任務多了,磁碟的讀寫性能自然會退化,嚴重時就會出現寫入數據延時的問題。
如何發現慢磁碟?正常在 HDFS 上創建一個目錄,只需要不到 1s 的時間。如果你發現創建目錄超過 1 分鐘及以上,而且這個現象並不是每次都有。只是偶爾慢了一下,就很有可能存在慢磁碟。
可以採用如下方法找出是哪塊磁碟慢:
1)通過心跳未聯繫時間
一般出現慢磁碟現象,會影響到 DataNode 與 NameNode 之間的心跳。正常情況心跳時間間隔是 3s。超過 3s 說明有異常。
2)fio 命令,測試磁碟的讀寫性能
(1)順序讀測試
[chaos@hadoop102 ~]# sudo yum install -y fio
[chaos@hadoop102 ~]# sudo fio -
filename=/home/chaos/test.log -direct=1 -iodepth 1 -thread -
rw=read -ioengine=psync -bs=16k -size=2G -numjobs=10 -
runtime=60 -group_reporting -name=test_r
Run status group 0 (all jobs):
READ: bw=360MiB/s (378MB/s), 360MiB/s-360MiB/s (378MB/s-378MB/s),
io=20.0GiB (21.5GB), run=56885-56885msec
結果顯示,磁碟的總體順序讀速度為 360MiB/s。
(2)順序寫測試
[chaos@hadoop102 ~]# sudo fio -
filename=/home/chaos/test.log -direct=1 -iodepth 1 -thread -
rw=write -ioengine=psync -bs=16k -size=2G -numjobs=10 -
runtime=60 -group_reporting -name=test_w
Run status group 0 (all jobs):
WRITE: bw=341MiB/s (357MB/s), 341MiB/s-341MiB/s (357MB/s357MB/s), io=19.0GiB (21.4GB), run=60001-60001msec
結果顯示,磁碟的總體順序寫速度為 341MiB/s。
(3)隨機寫測試
[chaos@hadoop102 ~]# sudo fio -filename=/home/chaos/test.log -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_randw
Run status group 0 (all jobs):
WRITE: bw=309MiB/s (324MB/s), 309MiB/s-309MiB/s (324MB/s-324MB/s),
io=18.1GiB (19.4GB), run=60001-60001msec
結果顯示,磁碟的總體隨機寫速度為 309MiB/s。
(4)混合隨機讀寫:
[chaos@hadoop102 ~]# sudo fio -filename=/home/chaos/test.log -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_r_w -ioscheduler=noop
Run status group 0 (all jobs):
READ: bw=220MiB/s (231MB/s), 220MiB/s-220MiB/s (231MB/s231MB/s), io=12.9GiB (13.9GB), run=60001-60001msec
WRITE: bw=94.6MiB/s (99.2MB/s), 94.6MiB/s-94.6MiB/s
(99.2MB/s-99.2MB/s), io=5674MiB (5950MB), run=60001-60001msec
結果顯示,磁碟的總體混合隨機讀寫,讀速度為 220MiB/s,寫速度 94.6MiB/s。
4、小文件歸檔
1)HDFS 存儲小文件弊端
每個文件均按塊存儲,每個塊的元數據存儲在 NameNode 的記憶體中,因此 HDFS 存儲小文件會非常低效。因為大量的小文件會耗盡 NameNode 中的大部分記憶體。但注意,存儲小 文件所需要的磁碟容量和數據塊的大小無關。例如,一個 1MB 的文件設置為 128MB 的塊 存儲,實際使用的是 1MB 的磁碟空間,而不是 128MB。
2)解決存儲小文件辦法之一
HDFS 存檔文件或 HAR 文件,是一個更高效的文件存檔工具,它將文件存入 HDFS 塊, 在減少 NameNode 記憶體使用的同時,允許對文件進行透明的訪問。具體說來,HDFS 存檔文 件對內還是一個一個獨立文件,對 NameNode 而言卻是一個整體,減少了 NameNode 的記憶體。
3)案例實操
(1)需要啟動 YARN 進程
[chaos@hadoop102 hadoop-3.1.3]$ start-yarn.sh
(2)歸檔文件
把/input 目錄裡面的所有文件歸檔成一個叫 input.har 的歸檔文件,並把歸檔後文件存儲
到/output 路徑下。
[chaos@hadoop102 hadoop-3.1.3]$ hadoop archive -archiveName input.har -p /input /output
(3)查看歸檔
[chaos@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /output/input.har
[chaos@hadoop102 hadoop-3.1.3]$ hadoop fs -ls har:///output/input.har
(4)解歸檔文件
[chaos@hadoop102 hadoop-3.1.3]$ hadoop fs -cp har:///output/input.har/* /

