微服務SpringCloud之zipkin鏈路追蹤
- 2019 年 10 月 3 日
- 筆記
隨著業務發展,系統拆分導致系統調用鏈路愈發複雜一個前端請求可能最終需要調用很多次後端服務才能完成,當整個請求變慢或不可用時,我們是無法得知該請求是由某個或某些後端服務引起的,這時就需要解決如何快讀定位服務故障點,以對症下藥。於是就有了分散式系統調用跟蹤的誕生。
Spring Cloud Sleuth
一般的,一個分散式服務跟蹤系統,主要有三部分:數據收集、數據存儲和數據展示。根據系統大小不同,每一部分的結構又有一定變化。譬如,對於大規模分散式系統,數據存儲可分為實時數據和全量數據兩部分,實時數據用於故障排查(troubleshooting),全量數據用於系統優化;數據收集除了支援平台無關和開發語言無關係統的數據收集,還包括非同步數據收集(需要跟蹤隊列中的消息,保證調用的連貫性),以及確保更小的侵入性;數據展示又涉及到數據挖掘和分析。雖然每一部分都可能變得很複雜,但基本原理都類似。
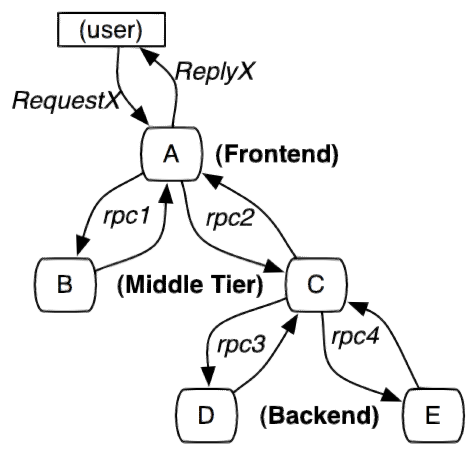
服務追蹤的追蹤單元是從客戶發起請求(request)抵達被追蹤系統的邊界開始,到被追蹤系統向客戶返迴響應(response)為止的過程,稱為一個“trace”。每個 trace 中會調用若干個服務,為了記錄調用了哪些服務,以及每次調用的消耗時間等資訊,在每次調用服務時,埋入一個調用記錄,稱為一個“span”。這樣,若干個有序的 span 就組成了一個 trace。在系統向外界提供服務的過程中,會不斷地有請求和響應發生,也就會不斷生成 trace,把這些帶有span 的 trace 記錄下來,就可以描繪出一幅系統的服務拓撲圖。附帶上 span 中的響應時間,以及請求成功與否等資訊,就可以在發生問題的時候,找到異常的服務;根據歷史數據,還可以從系統整體層面分析出哪裡性能差,定位性能優化的目標。
Spring Cloud Sleuth為服務之間調用提供鏈路追蹤。通過Sleuth可以很清楚的了解到一個服務請求經過了哪些服務,每個服務處理花費了多長。從而讓我們可以很方便的理清各微服務間的調用關係。此外Sleuth可以幫助我們:
耗時分析: 通過Sleuth可以很方便的了解到每個取樣請求的耗時,從而分析出哪些服務調用比較耗時;
可視化錯誤: 對於程式未捕捉的異常,可以通過集成Zipkin服務介面上看到;
鏈路優化: 對於調用比較頻繁的服務,可以針對這些服務實施一些優化措施。
spring cloud sleuth可以結合zipkin,將資訊發送到zipkin,利用zipkin的存儲來存儲資訊,利用zipkin ui來展示數據。
測試
1.啟動zipkin server
由於是參考純潔的微笑的部落格http://www.ityouknow.com/springcloud/2018/02/02/spring-cloud-sleuth-zipkin.html,但在我創建zipkin-server項目引入註解@EnableZipkinServer時提示已不能使用。建議使用默認的zipkin的jar包,具體使用方法可以查看github的文檔。這裡直接下載下了jar,然後使用記憶體方式存儲,java -jar zipkin-server-2.17.0-exec.jar.
/** * @deprecated Custom servers are possible, but not supported by the community. Please use our * <a href="https://github.com/openzipkin/zipkin#quick-start">default server build</a> first. If you * find something missing, please <a href="https://gitter.im/openzipkin/zipkin">gitter</a> us about * it before making a custom server. * * <p>If you decide to make a custom server, you accept responsibility for troubleshooting your * build or configuration problems, even if such problems are a reaction to a change made by the * OpenZipkin maintainers. In other words, custom servers are possible, but not supported. */
2.項目中添加zipkin的支援
在SpringColudZuulSimple、EurekaClient中引入依賴spring-cloud-starter-zipkin。
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> <version>2.1.3.RELEASE</version> </dependency>
然後在application.properties中設置屬性
spring.zipkin.base-url=http://localhost:9411 spring.sleuth.sampler.probability=1.0
spring.zipkin.base-url指定了Zipkin伺服器的地址,spring.sleuth.sampler.percentage將取樣比例設置為1.0,也就是全部都需要。
Spring Cloud Sleuth有一個Sampler策略,可以通過這個實現類來控制取樣演算法。取樣器不會阻礙span相關id的產生,但是會對導出以及附加事件標籤的相關操作造成影響。 Sleuth默認取樣演算法的實現是Reservoir sampling,具體的實現類是PercentageBasedSampler,默認的取樣比例為: 0.1(即10%)。不過我們可以通過spring.sleuth.sampler.percentage來設置,所設置的值介於0.0到1.0之間,1.0則表示全部採集。
3.驗證
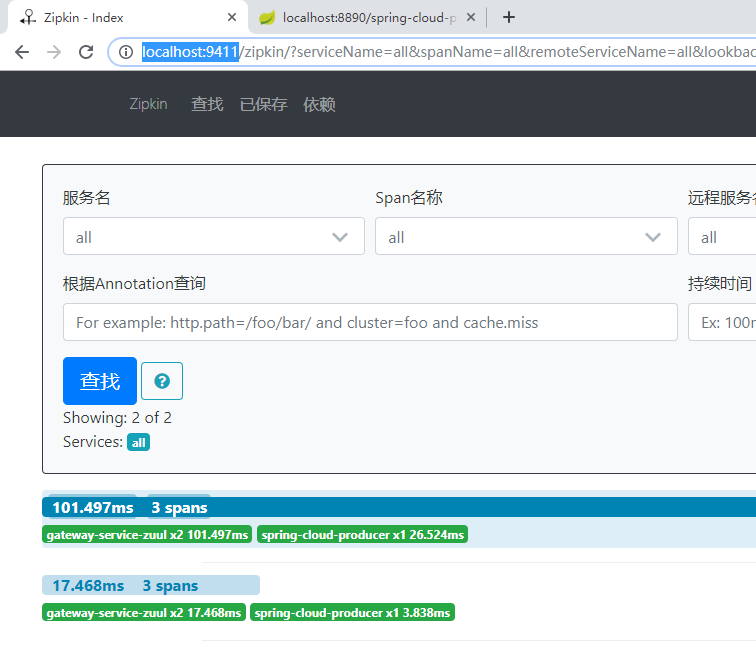
依次啟動EurekaServer、EurekaClient、SpringColudZuulSimple,然後在瀏覽器中輸入http://localhost:8890/spring-cloud-producer/hello?name=cuiyw&token=123,刷新幾次,然後在http://localhost:9411頁面點擊查詢,可以看到如下資訊。
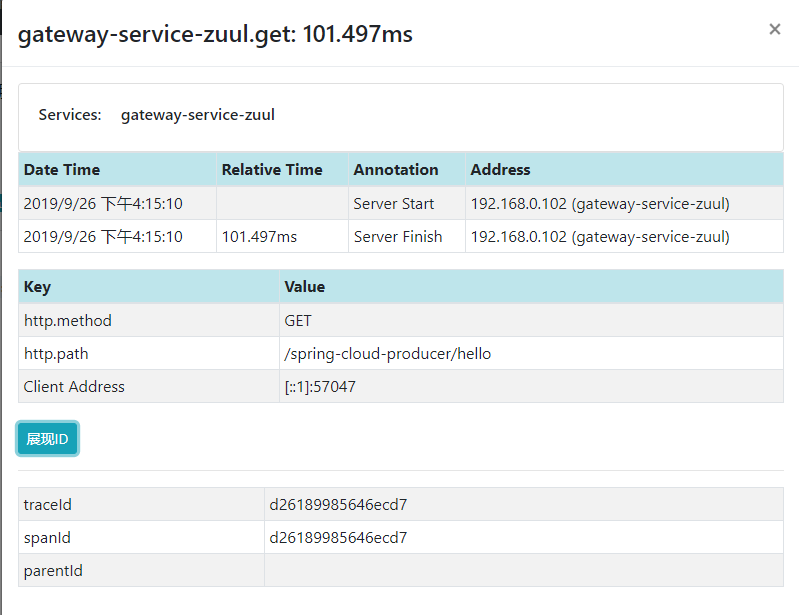
點擊每項記錄都能看到每項的具體耗時資訊和順序。
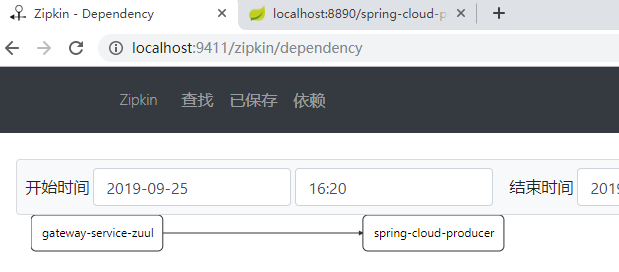
點擊依賴分析,可以看到項目之間的調用關係
總結
這裡使用的記憶體的方式來存儲數據,生產環境一般會使用消息隊列RabbitMQ、Kafka或者資料庫mysql存儲,具體使用方法可以查看zipkin的官方文檔。
參考:http://www.ityouknow.com/springcloud/2018/02/02/spring-cloud-sleuth-zipkin.html
