【論文小綜】基於外部知識的VQA(視覺問答)
我們生活在一個多模態的世界中。視覺的捕捉與理解,知識的學習與感知,語言的交流與表達,諸多方面的資訊促進著我們對於世界的認知。作為多模態領域的一個典型場景,VQA旨在結合視覺的資訊來回答所提出的問題。從15年首次被提出[1]至今,其涉及的方法從最開始的聯合編碼,到雙線性融合,注意力機制,組合模型,場景圖,再到引入外部知識,進行知識推理,以及使用圖網路,多模態預訓練語言模型…近年來發展迅速。 傳統的VQA僅憑藉視覺與語言資訊的組合來回答問題,而近年來許多研究者開始探索外部資訊對於解決VQA任務的重要性。

![]()
如圖所示,這裡的VQA pair中,要回答問題「地面上的紅色物體能用來做什麼」,要想做出正確的回答「滅火」,所依靠的資訊不僅來源於圖片上所識別出的「消防栓」,還必須考慮到來自外部的事實(知識)「消防栓能滅火」作為支撐。這就是一個典型的VQA上應用外部知識的場景。傳統的VQA近些年發展迅速,隨著CV/NLP方向基礎理論的發展,在模型性能,覆蓋數據方面均有了大幅提高。傳統VQA模型之外,基於預訓練語言模型的多模態VQA任務也逐漸興起,大家開始關注如何利用多模態預訓練的方法,解決通用VQA問題。
但以上種種方法,始終無法解決這些需要外部知識的困難VQA問題。接下來我將結合多篇論文簡述在VQA上應用外部知識的方法,做相應的梳理。
【1】Ask Me Anything: Free-Form Visual Question Answering Based on Knowledge From External Sources
發表會議:CVPR 2016
會議等級:CCF-A
論文鏈接:Ask Me Anything
![]()
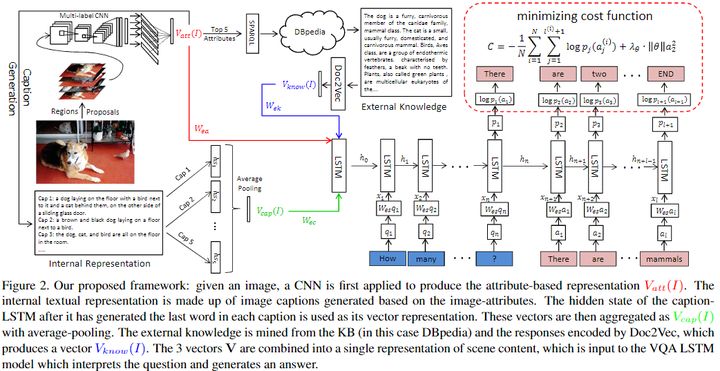
推理與知識的實際存儲進行分離是基於外部知識VQA相關論文所持的觀點。該論文核心思想是將自動生成的影像描述與外部的Knowledge bases融合,以實現對問題的預測。其中生成影像描述的方法借鑒了同年作者發表的了一篇文章[5]:給定一張影像,先預測影像中各種屬性,然後再將這些屬性代替之前的 CNN 影像特徵,輸入到 RNN 當中生成語句。這個簡單的操作使他們的影像標註模型在當年 COCO影像標註大賽上排名第一。添加中介屬性減小雙模態鴻溝的方法,也用在了本文中。
對於一個給定的V-Q pair,首先用CNN提取圖片特徵屬性,然後利用這些檢測到的屬性,使用sparql查詢語句從knowledge base比如DBpedia中提取出影像相關描述的一個段落,利用Doc2Vec對這些段落編碼。同時,根據圖片特徵屬性使用Sota的image caption方法形成影像對應的段落特徵表達。
最後將上面兩種資訊以及編碼的屬性結合在一起並輸入作為一個Seq2Seq模型的初始初始狀態,同時將問題編碼作為LSTM的輸入,利用最大似然方法處理代價函數,預測答案。

![]()
該方法的可解釋性相對於端到端的模型而言強了許多,這也是後續許多模型採用的思想,即各種特徵融合到一起然後丟到一個遞歸網路例如LSTM中。最後在COCO-QA數據集上取得了Sota效果。

![]()
【2】Fvqa: Fact-based visual question answering
發表期刊:TPAMI 2018
期刊等級:CCF-A
論文鏈接:Fvqa
程式碼地址:data
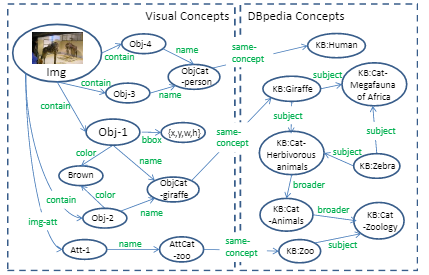
既然knowledge 和 reasoning 對 VQA 都很重要,那麼就可以考慮將它們兩個結合在一起,進行顯示推理。和以往直接把影像加問題直接映射到答案不同,作者提出的Ahab[3]模型的答案是可追溯的,就是通過查詢語句在KG中的搜索路徑可以得到一個顯式的邏輯鏈。這也是一種全新的能夠進行顯式推理的 VQA 模型。並且,他們提出了一種涉及外部知識的VQA任務。它首先會通過解析將問題映射到一個 KB 查詢語句從而能夠接入到已有知識庫中。同時將提取的視覺概念(左側)的圖鏈接到DBpedia(右側)裡面,如下圖所示。
![]()
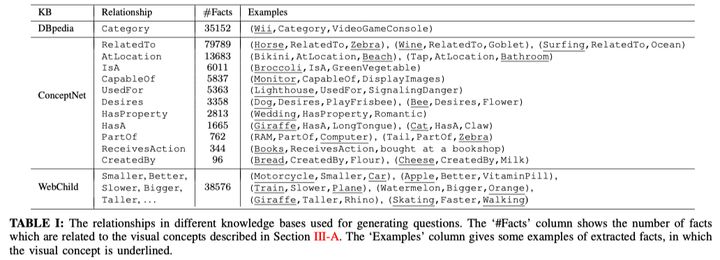
同期發表的FVQA是對其的改進和梳理,並且貢獻了這方面很重要的數據集:除了一般的圖片、問題、回答以外,這個數據集還提供了支撐這一回答的事實Facts事實集合(參考數據來源於DBpedia, Conceptnet, WebChild三個資料庫),共包括4216個fact。某種意義上來說,該數據集是基於fact去針對性構建的。具體如下:
![]()
在實際的數據中,fact以關係三元組的形式表示,其中的relationship使用來自於資料庫中已有的定義。
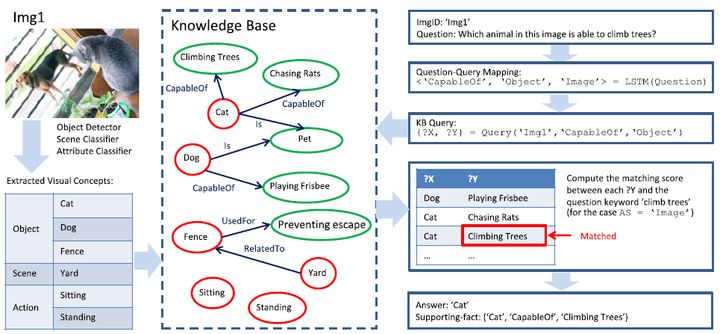
模型的第一部分和ahab類似,檢測影像中的視覺概念,然後將他們與知識庫對齊並連接到subgraph中。第二步將自然語言式的問題映射到一個查詢類型,然後相應地確定關鍵的關係類型,視覺概念和答案源。再根據上面的資訊構建一個特殊的查詢會去請求上一步當中建立好的圖,找到所有滿足條件的事實。最後通過關鍵詞篩選得到對應問題的答案。
![]()
【3】Out of the Box: Reasoning with Graph Convolution Nets for Factual Visual Question Answering
發表會議:NIPS 2018
會議等級:CCF-A
論文鏈接:Out of the box
程式碼地址:
前文提出的方法大多類似於組合模型。此外,近幾年也有涉及到圖來解決外部知識VQA問題的方法[7]。
![]()
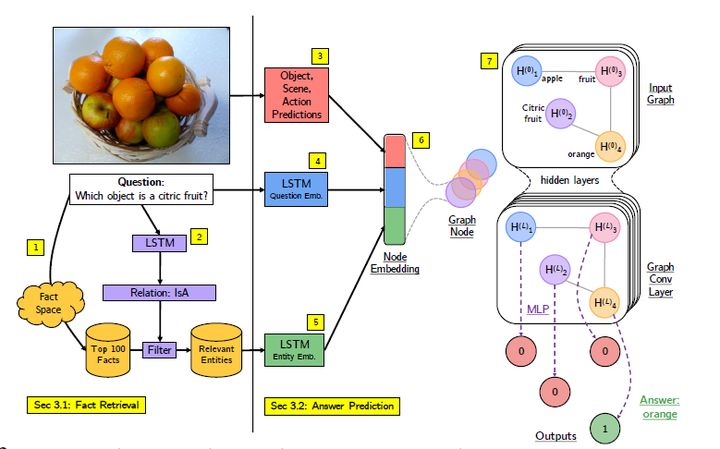
該文章的作者基於FVQA數據集,把之前深度網路篩選事實的這一訓練過程用圖卷積網路代替,成為一個端到端的推理系統,用於具有知識庫的視覺問題解答。
一共分為七個步驟,給定影像和問題,首先使用相似性評分技術根據影像和問題從事實空間獲得相關事實。 使用LSTM模型從問題預測關係,篩選fact來進一步減少相關事實及其實體的集合。然後分別進行影像視覺概念提取,問題的LSTM嵌入,以及事實片語的的LSTM嵌入,將影像的視覺概念multi-hot向量和問題的lstm嵌入向量組合,並與每一個實體的LSTM嵌入拼接,作為一個實體的特徵表示,同時也是作為GCN模型里圖上的一個節點。圖中的邊代表實體之間的關係。最後將GCN輸出的每一個實體節點特徵向量作為多層感知機二元分類模型的輸入,最後輸出的結果通過argmax得到最終的決策結果。
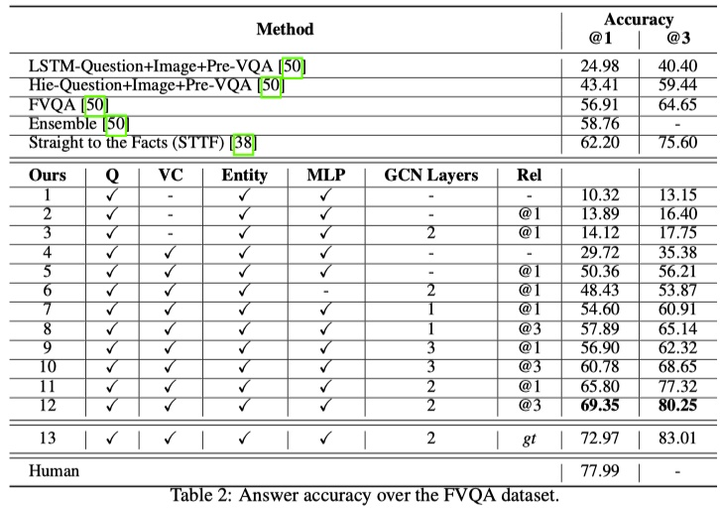
模型在雙層GCN以及top3 relation的設定下,超過了FVQA的方法大概10%。(58.7%->69.3),結果如下:
![]()
【4】Straight to the facts: Learning knowledge base retrieval for factual visual question answering
發表會議: ECCV 2018
會議等級:CCF-B
論文鏈接: Straight to the facts
程式碼地址:
在回答給定上下文(例如影像)的問題時,該文章將觀察到的內容與常識無縫結合在一起。對於自然參與我們日常工作的自主代理和虛擬助手,在最常根據上下文和常識回答問題的地方,利用觀察到的內容和常識的演算法非常有用。許多前述方法集中在問題回答任務的視覺方面,即,通過結合問題和影像的表示來預測答案。這與描述的類人方法明顯不同,後者將觀察與常識相結合。為此,相關研究設計了一種從問題中提取關鍵字並從知識庫中檢索包含這些關鍵字的事實的方法。但是,同義詞和同形異義詞構成了難以克服的挑戰。
![]()
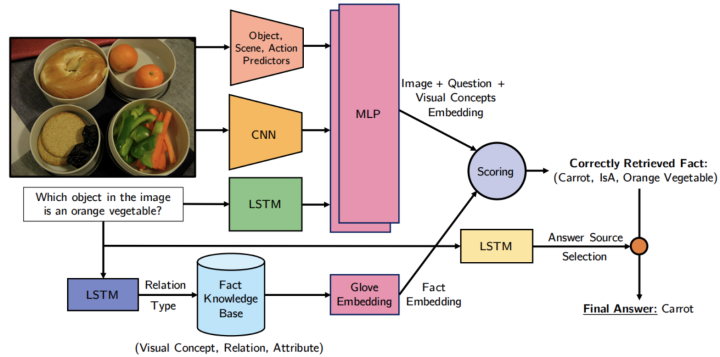
為了解決這個問題,作者開發了一種基於學習的檢索方法,如圖 所示。更具體地說,他們的方法學習事實和問題影像對到嵌入空間的參數映射。為了回答問題,他們使用與所提供的問題影像對最一致的事實。知識庫中的事實是根據視覺概念(例如,對象,場景和從輸入影像中提取的動作)進行過濾的。然後將預測的查詢應用於過濾後的資料庫,從而獲得一組檢索到的事實。然後,在檢索到的事實和問題之間計算匹配分數,以確定最相關的事實。最正確的事實構成了問題答案的基礎。
給定影像和關於影像的問題,通過在影像上使用CNN,在問題上使用LSTM以及將兩種方式組合在一起的多層感知器(MLP)來獲得影像+問題嵌入。 為了從知識庫(KB)中過濾相關事實,使用另一個LSTM從問題中預測事實關係類型。 使用GloVe嵌入對檢索到的結構化事實進行編碼。 通過嵌入向量之間的點積對檢索到的事實進行排序,並返回排名靠前的事實以回答問題。
當前的任務是通過使用外部知識庫KB來預測給定影像x的問題Q的答案y,該知識庫由一組事實fi組成,知識庫中的每個事實fi都表示為形式為fi =(ai, ri, bi) 的資源描述框架(RDF)三元組,其中ai是影像中的視覺概念,bi是與主題相關的屬性或短語 ri是兩個實體之間的關係。 數據集| R | = 13包含關係r = {Category, Comparative, HasA, IsA, HasProperty, CapableOf, Desires, RelatedTo, AtLocation, PartOf, ReceivesAction, UsedFor, CreatedBy}。 數據集中的知識庫的三元組示例有(Umbrella, UsedFor, Shade), (Beach, HasProperty, Sandy), (Elephant, Comparative-LargerThan, Ant).
該模型一共有三個需要訓練參數的模組:
預測fact關係類型的多分類器;
預測答案來源的二分類器;
計算fact score的模組,主要的參數在參與編碼GNN的MLP中。
文章把這三個模組分別進行單獨的訓練。前兩個只是簡單的分類模型,因此用對應的數據和cross-entropy loss進行訓練即可。第三個模組的訓練則稍微費勁一些。這裡追求的目標是,ground-truth fact 的score比其他的score更大,為此,文章借鑒了軟間隔SVM的思想,確保以下的條件成立:
此外,文章還用到了hard negative mining的訓練方法。面對數據集規模不大的情況(FVQA數據集中只有5,286個問題),該方法強化了模型對錯判的糾正,從而有效提升模型的準確性。
【5】Ok-vqa: A visual question answering benchmark requiring external knowledge
發表會議: CVPR 2019
會議等級:CCF-A
論文鏈接: OK-VQA
程式碼地址:data
該文章[6]的問題背景是,對於已有的小部分需要外部知識的數據集,依賴於結構化知識(例如上文提到的FVQA)。而已有的VQA數據集,問題難度普遍不高,標準VQA數據集,超過78%的問題能夠被十歲以下兒童回答。
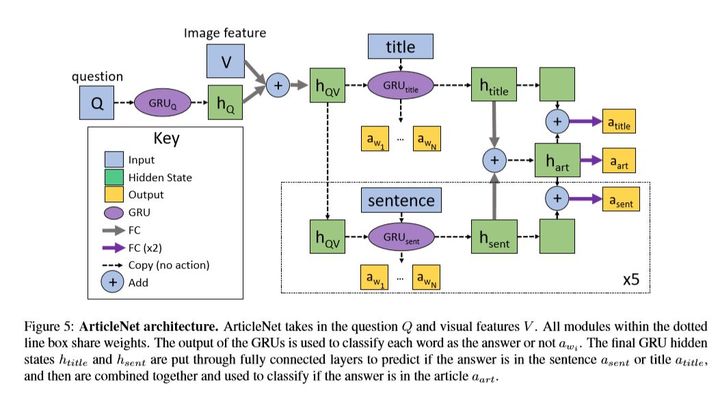
於是,作者提出並構建了一個(最)大規模的需要外部知識的數據集( Outside Knowledge VQA ),並且在OK-VQA數據集上就目前最好的VQA模型提供了benchmark實驗。與此同時,提出了一種ArticleNet的方法,可以處理互聯網上的非結構化數據來輔助回答其中的問題。
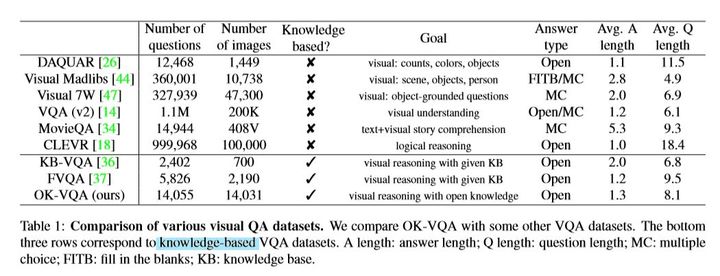
數據集大小和對比如下:
![]()
因為標準VQA數據集品質不高(難度低),所以作者自行請MTurk工人,從COCO數據集中進行了數據採集、問題搜集、問題品質篩選、問題回答。同時通過過濾操作,降低了bias的影響,減少文本對於某些回答的偏差(如 Is there …)。同時考慮了長尾效應。就數據分類而言,劃分了10+1(other)個類別,保證問題類型的互斥。

![]()
圖片場景覆蓋了COCO總共的365個場景中的350.。保證了覆蓋率和分布的合理性。 就ArticleNet模型而言,其分為三步:
(1)從圖片(pre-trained+ scene classifiers)和問題pair中搜集關鍵字,並組合成可能的query (2)使用wiki的API進行檢索,獲得排名最高的幾個文章。 (3)基於query 的單詞在這幾篇文章中得到最有可能的句子。 (4)【可選】從句子中得到最有可能的詞作為答案。
![]()
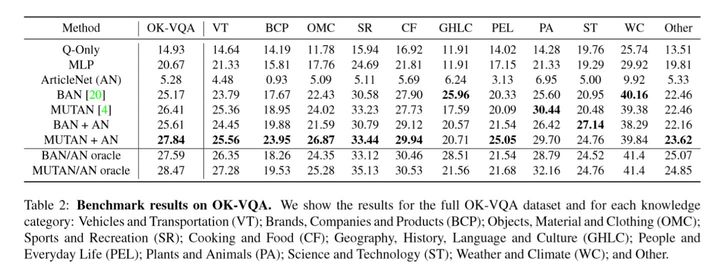
ArticleNet模型可以與許多已有的VQA模型進行拼接以提升模型在外部知識VQA場景下性能。作者進行了相應實驗:
![]()
其中ArticleNet的結合方法是將sentence與具體模型中某一層的輸出向量進行一個向量拼接,以捕獲外部資訊。ArticleNet單獨作用的方法可能一般(依賴於互聯網數據,比較死板),但是如何和其他模型結合e.g. mutan、ban(end-2-end),效果都會有提升。同時其並不是和VQA模型一起訓練,可以單獨訓練。如下是ArticleNet在其中起作用的例子:

![]()
【6】Kvqa: Knowledge-aware visual question answering
發表會議:AAAI 2019
會議等級:CCF-A
論文鏈接:KVQA
程式碼地址:
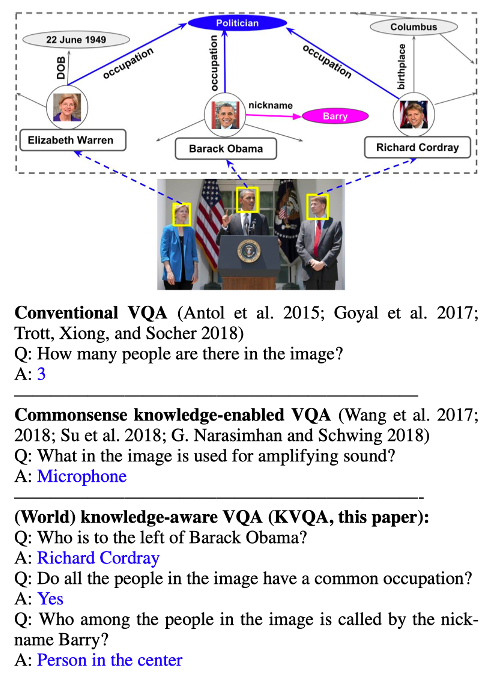
這篇論文發表在2019年AAAi上,核心貢獻在於發布一個關注圖片中命名實體知識的數據集,解決這個問題需要的知識區別於常識知識,而是作者所提到的world knowledge。如圖
![]()
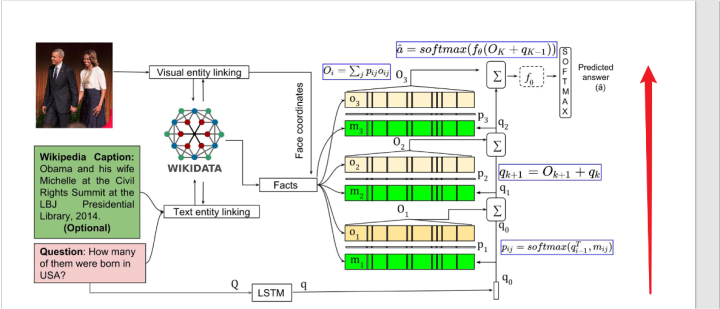
它提出的方法並沒有很大的創新點,簡單描述一下就是三個步驟。
第一步把問題和影像使用某些方法,對齊到一個知識庫中,然後第二步把對齊得到的fact和相關人物的坐標拿出來,用一個模型比如BLSTM進行表示。
第三步和問題的表示進行進行soft attention(也就是點乘之後進行softmax),然後相加,最後輸入到一個softmax中進行分類。這裡作者應該是希望模型能找到和當前問題最相關的fact,給其更高的權重,以進行最後的分類。
然後作者模型為了解決邏輯是multi-hop的多跳視覺問答問題,使用了模型堆疊的方法,也就是把第三步裡面的soft attention重複三次,每次的問題輸入的表示是前一層的輸出。
模型整體結構如圖所示:
![]()
缺點:commonsense knowledge 和world knowledge就組織方式而言我不認為有明顯的區別。
方法沒有明顯的創新
【7】Mucko: Multi-Layer Cross-Modal Knowledge Reasoning for Fact-based Visual Question Answering
發表會議:IJCAI 2020
會議等級:CCF-A
論文鏈接:Mucko
程式碼地址:code
作者對比了前人的工作,一個方向是將問題轉化成關鍵詞,然後在候選事實中根據關鍵詞匹配檢索出對應的支撐事實的pineline方式,比如前文所提的FVQA,但是如果視覺概念沒有被問題完全提及(比如同義詞和同形異義詞)或者事實圖中未捕獲提及的資訊(比如它問紅色的柱子是什麼,卻沒有提到消防栓),那這類方法就會因為匹配而產生誤差。另一個方向將視覺資訊引入到知識圖中,通過GCN推導出答案,就比如前文提到的out of the box模型。雖然解決了上面的問題但是每個節點都引入了相同且全部的視覺資訊,而只有一部分的視覺資訊和當前節點是相關的,這樣會引入雜訊。並且每個節點都是固定形式的的視覺-問題-實體的嵌入表示,這使得模型無法靈活地從不同模態中捕獲線索。而本文[8]則較好地解決了上述問題。
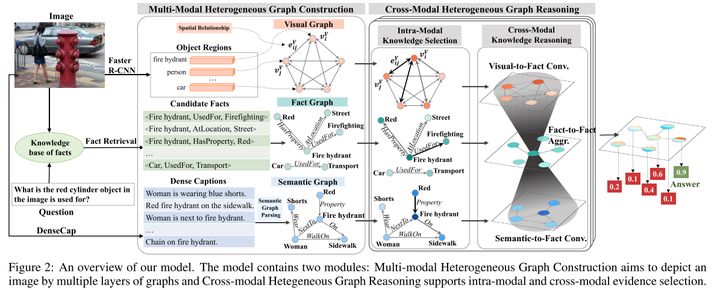
![]()
文章的出發點是將影像表示成一個多模態的異構圖,其中包含來自不同模態三個層次的資訊(分別是視覺圖、語義圖和事實圖),來互相補充和增強VQA任務的資訊。具體來說,視覺圖包含了影像中的物體及其位置關係的表示,語義圖包含了用於銜接視覺和知識的高層語義資訊,事實圖則包含影像對應的外部知識,它的構造思想參考了out of the box 模型。
然後進行每個模態內的知識選擇:在問題的引導下確定每個節點和邊在內部圖卷積過程中的分數權重佔比,然後進行常規的update操作。也就是說在跨模態之前,先獨立選擇單個模態內有價值的證據,讓和問題相關性強的節點及邊,在圖內部卷積過程中占更大的權重。這三個模態內部的卷積操作都是相同的,只是節點和邊的表示不同。
最後,跨模態的知識推理是基於part2模態內的知識選擇的結果。考慮到資訊的模糊性,不同圖很難顯式地對齊,所以作者採用一種隱式的基於注意力機制的異構圖卷積網路方法來關聯不同模態的資訊,從不同層的圖中自適應地收集互補線索並進行匯聚。包括視覺到事實的卷積和語義到事實的卷積。比如視覺到事實的卷積場景中,對於事實圖中的每個節點vi,計算視覺圖中每個節點vj和它在問題引導下的相似度注意力分數,越互補的節點它的相似度分數就越高,然後根據這個分數對視覺圖加權求和,得到事實圖中每個節點來自視覺圖層的事實互補資訊。
分別迭代地執行Part2模態內的知識選擇和Part3跨模態的知識推理,執行多個step可以獲得最終的fact實體表示,並將其傳到一個二元分類器,輸出概率最高的實體當做預測的答案。
模型在三個數據集上驗證了實驗結果。該模型在FVQA上表現很好:
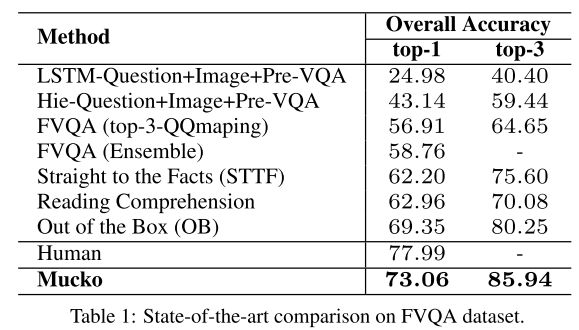
![]()
另外一個數據集Visual7W KB也和FVQA類似,問題是直接根據Conceptnet生成的。不同點在於他不提供fact。可以看到結果也明顯好於Sota。
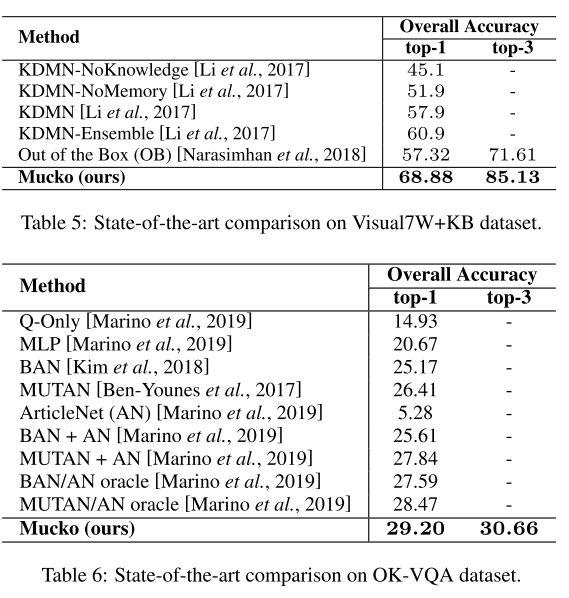
![]()
第三個數據集OK-VQA比較特殊,沒有知識庫作為參考,知識跨度大難度高,sota只有30%不到。該模型在其上表現的不太好,不過還是比Sota要高大概0.7%。原因猜測是光憑藉單一的外部知識庫可能不足以對ok-vqa達到較大提升,所以ok-vqa問題在未來實際上還有很大的提升空間。
該模型另外一個優點是結果具有比較好的解釋性。上圖是FVQA數據下測試的結果。把fact graph中最重要fact所對應的top2視覺和語義對象節點,用虛線連接,虛線上的值表示了跨模態卷積中不同層哪些節點對結果影響重要性更大,結果比較直觀。熱力條根據最後特徵融合時的gate值得到,密度越大則代表對應位置通道的重要性越高。可以發現,在大多數的情況下事實資訊會更重要,也就是密度最大。因為FVQA中97.3%的問題都是需要額外知識才能回答的。而密度第二大的區域往往會由問題的類型決定是視覺更重要還是問題更重要。比如第二個圖中問題裡面的hold by這個詞無法在圖片中具體體現,所以所以語義資訊的佔比會更大一些。而第一個圖的話則視覺資訊佔比更大。
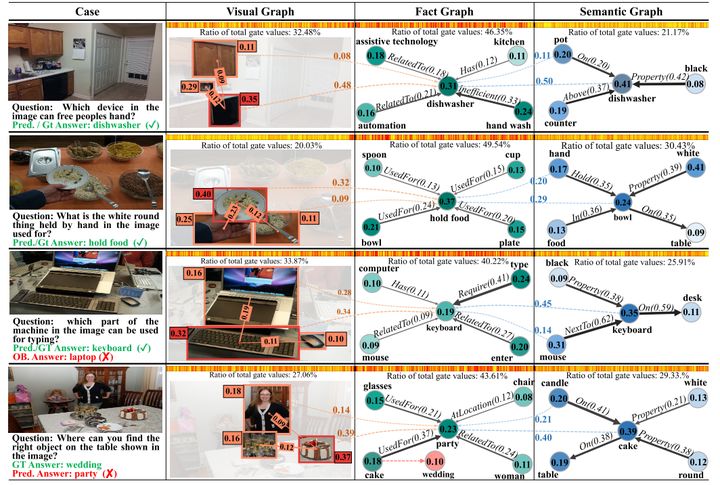
![]()
【8】Conceptbert: Concept-aware representation for visual question answering
發表會議:EMNLP 2020
會議等級:CCF-B
論文鏈接:Conceptbert
程式碼地址:code
普通VQA的工作主要關注直接分析問題和影像就可以得出答案的問題(沒有外部知識),對於需要常識/外部結構化基本事實支撐的VQA問題,可以分為兩種方法:
方法一:對於需要 常識/外部結構化基本事實 支撐的VQA問題
方法二:對於需要 常識/外部結構化基本事實 支撐的VQA問題
他們有以下缺點:
1) 不是 end-to-end;
2) 不是 fully trainable;
3) 大多基於普通詞嵌入;
基於此,本文作者提出了一種Concept-Aware的演算法,使用 ConceptNet KGE 來編碼 common sense knowledge(對數據集無要求, 不需要查詢query, 使用了bert),主要創新點來自於:
-
1) 學習了一個 joint Concept-Vision-Language embedding 來解VQA問題。
-
2) 捕捉 image-question-knowledge 直接的特殊交互。
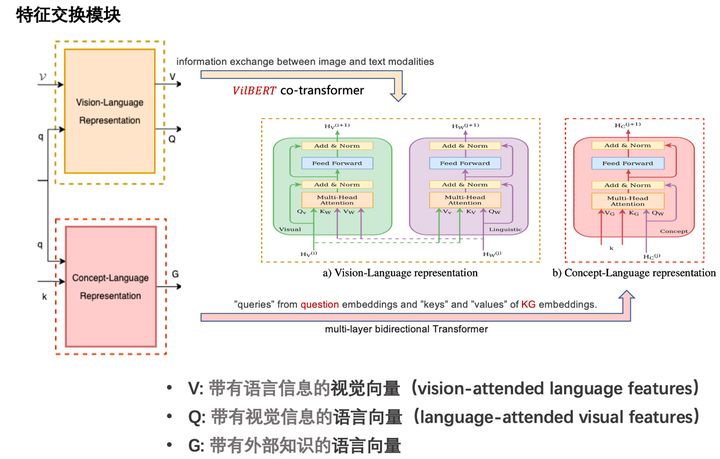
其中三種模態的交互過程如圖所示:
![]()
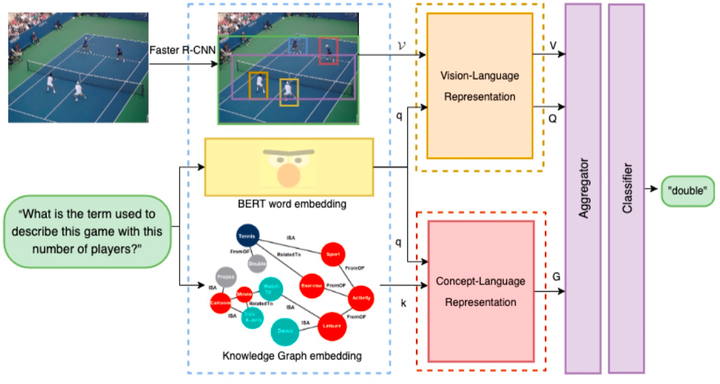
文章整體模型如圖所示:
![]()
並最終模型取得了不錯的效果:
-
VQA 2.0 (not sota);
-
OK-VQA(sota)
整個流程可以表示於:
– 得到對應模態的嵌入表示 – 通過兩個並行模態融合模組 — 視覺-語言(輸出2個向量) — 知識-語言(輸出1個向量) – 聚合三種向量 — 帶有語言資訊的視覺向量 — 帶有視覺資訊的語言向量 — 帶有外部知識的語言向量 – 分類器進行答案分類
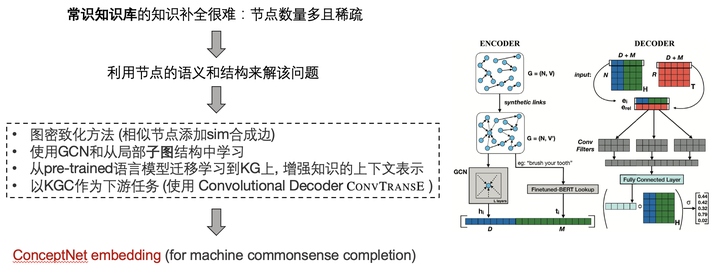
該工作有以下的前置工作:
![]()
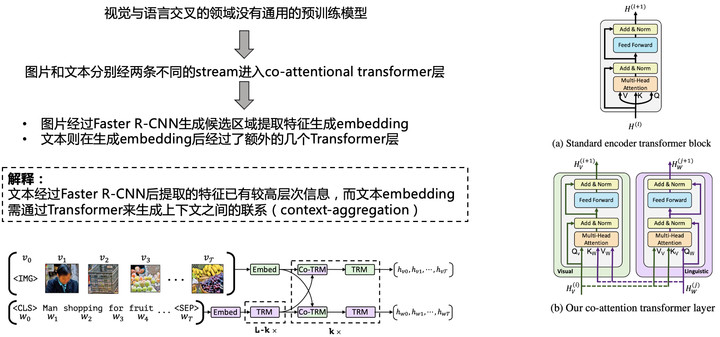
![]()
該文章對於後續工作有許多啟發:常識知識庫某種程度上可增強許多VQA任務,哪怕不是顯式地需要外部知識。多模態任務中以圖的形式引入外部知識依然有很大的潛力可以挖掘,預訓練fine-tune +(交叉)注意力機制 + 外部知識 + KG圖結構 某種程度上可以使得 資訊最大化.
【9】Zero-shot Visual Question Answering using Knowledge Graph
發表會議:ISWC 2021
會議等級:CCF-B
論文鏈接:ZS-F-VQA
程式碼地址:code/data
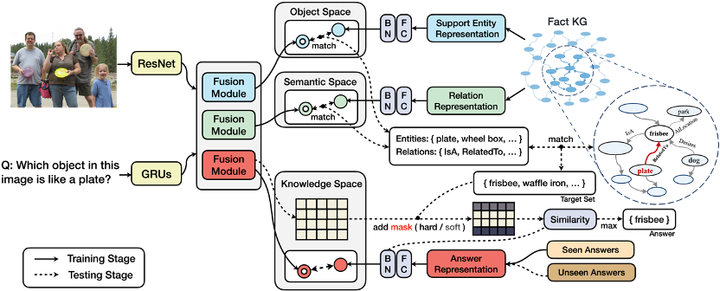
![]()
現有的許多方法採用pipeline的模式,多模組分工進行跨模態知識處理和特徵學習,但這種模式下,中間件的性能瓶頸會導致不可逆轉的誤差傳播(Error Cascading)。此外,大多數已有工作都忽略了答案偏見問題——因為長尾效應的存在,真實世界許多答案在模型訓練過程中可能不曾出現過(Unseen Answer)。
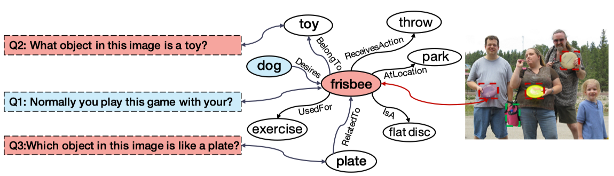
![]()
該工作提出了一種適用於零樣本視覺問答(ZS-VQA)的基於知識圖譜的掩碼機制,更好結合外部知識的同時,一定程度緩解了誤差傳播對於模型性能的影響。並在原有F-VQA數據集基礎上,提供了基於Seen / Unseen答案類別為劃分依據的零樣本VQA數據集(ZS-F-VQA)。實驗表明,其方法可以在該數據集下達到最佳性能,同時還可以顯著增強端到端模型在標準F-VQA任務上的性能效果。
人天生就具有強大的領域遷移能力,且這種能力往往不需要很多的樣本,甚至僅需一些規則描述,根據過往的經驗與知識就可以迅速適應一個新的領域,並對新概念進行認知。基於此假設,作者設計零樣本下的外部知識VQA:測試集答案與訓練集的答案沒有重疊。即,在原有F-VQA數據集基礎上,提供以Seen / Unseen答案類別為劃分依據的ZS-F-VQA數據集,並提出了一種適用於零樣本視覺問答(ZS-VQA)的基於知識圖譜的掩碼機制。
區別於傳統VQA基於分類器的模型設定,本文採取基於空間映射的方法,建立多個特徵空間並進行知識分解,同時提出了一種靈活的可作用於任何模型的k mask設定,緩解少樣本情況下對於Seen類數據的領域漂移。這提供了一種多模態數據和KG交互的新思路,實驗證明在多個模型上可取得穩定的提升,更好地結合外部知識同時緩解誤差傳播對於模型性能的影響。
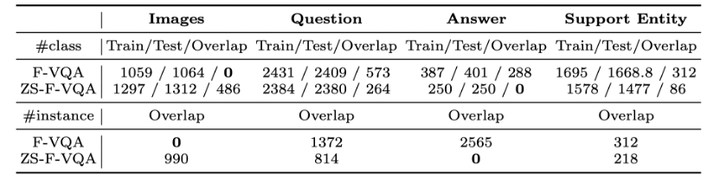
新數據集(注意到,原始F-VQA是根據圖片進行數據劃分的,因此在image上的重疊(overlap)是0,而ZS-F-VQA在answer上重疊為0。):
![]()
方法包含兩部分。
第一部分,三個特徵空間以處理不同分布的資訊:實體空間(Object Space)、語義空間(Semantic Space)、知識空間(Knowledge Space)的概念。其中:
實體空間主要處理影像/文本中存在的重點實體與知識庫中存在實例的對齊;
語義空間關注視覺/語言的交互模態中蘊含的語義資訊,其目的是讓知識庫中對應關係的表示在獨立空間中進行特徵逼近。
知識空間讓 (問題,影像)組成的pair與答案直接對齊,建模的是間接知識,旨在挖掘多模態融合向量中存在的(潛層)知識。
第二部分是基於知識的答案掩碼。
給定輸入影像/文本資訊得到融合向量後,基於第一部分獨立映射的特徵空間和給定的超參數Ke / Kr,根據空間距離相似度在實體/語義空間中得到關於實體/關係的映射集,結合知識庫三元組資訊匹配得到答案候選集。答案候選集作為掩碼的依據,在知識空間搜索得到的模糊答案的基礎上進行掩碼處理,最後進行答案排序。
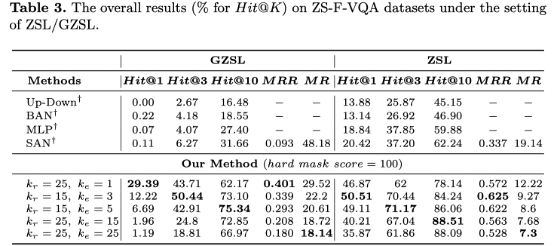
作者設計了兩種掩碼類型:硬掩碼(hard mask)和軟掩碼(soft mask),主要作用於答案的判定分數(score),區別在於遮掩分數的多少。作用場景分別為零樣本場景和普通場景。零樣本背景下領域偏移問題嚴重,硬掩碼約束某種意義上對於答案命中效果的提升遠大於丟失正確答案所帶來的誤差。而普通場景下過高的約束則容易導致較多的資訊丟失,收益小於損失。
模型在ZSL/GZSL下表現提升顯著
![]()
case study:

![]()
小結:
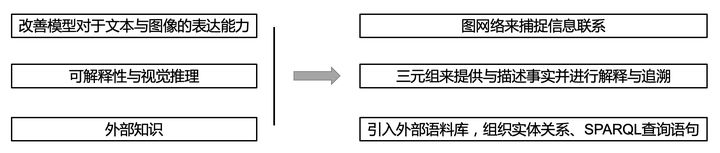
總而言之,形形色色的方法各有千秋。在實際應用中,可以根據不同方法的優劣和實際場景的條件選擇合適的VQA模型。目前來說解決VQA問題主要方向主要是三個大方向(改善模型對於文本與影像的表達能力,可解釋性與視覺推理,外部知識),其 知識圖譜(KG)而言在這三個方向中都有涉及。起到的作用分別對應於:用圖網路來捕捉資訊聯繫,通過三元組來提供與描述事實並進行解釋與答案追溯,以及引入外部語料庫,組織實體關係和spaql查詢語句。
![]()
此外,現有的模型默認訓練集與測試集具有獨立同分布的特質,但現實往往不盡如人意,也就是說同分布的假設大概率要打破。正如三點陣圖靈獎大佬最近發表的文章Deep Learning for AI中所強調的核心概念——高層次認知。將現在已經學習的知識或技能重新組合,重構成為新的知識體系,隨之也重新構建出了一個新的假想世界(如在月球上開車),這種能力是人類天生就被賦予了的,在因果論中,被稱作「反事實」能力。現有的統計學習系統僅僅停留在因果關係之梯的第一層,即觀察,觀察特徵與標籤之間的關聯,而無法做到更高層次的事情。
零樣本領域(ZSL)如何合理利用已有知識?我們普遍認為見過的就是事實,而未見過的就是事實以外的錯誤(反事實),這顯然過於絕對。零樣本某種意義上,就可看成是反事實的一種特例。
當然,未來還有許多潛在的方法和應用等待挖掘,歡迎大家補充和交流。
碼字不易~ 希望對你能有幫助和啟發

