(數據科學學習手札124)pandas 1.3版本主要更新內容一覽
本文示例程式碼及文件已上傳至我的
Github倉庫//github.com/CNFeffery/DataScienceStudyNotes
1 簡介
就在幾天前,pandas發布了其1.3版本,在這次新的版本中添加了諸多實用的新特性,今天的文章我們就一起來get其中主要的一些內容更新~

2 pandas 1.3主要更新內容一覽
使用pip install pandas==1.3.0 -U -i //pypi.douban.com/simple/安裝1.3版本後,下面我們來看看新的版本給我們帶來了哪些新特性:
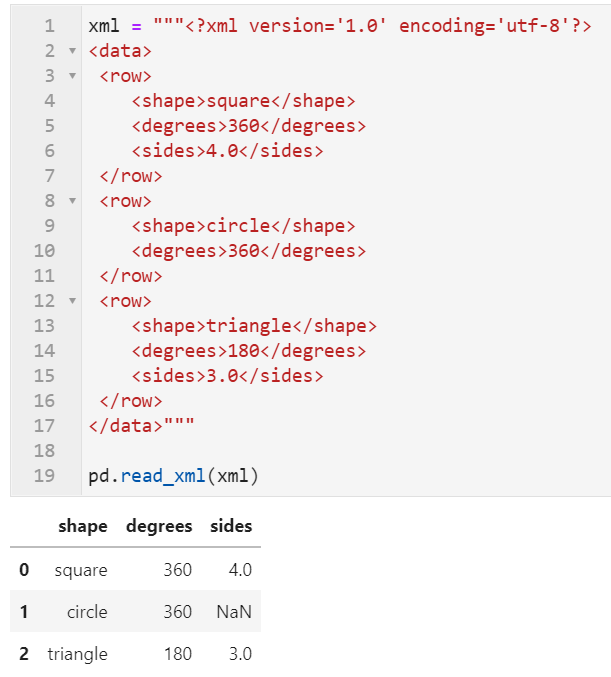
2.1 新增對xml文件的讀寫操作
在這次新版本中新增了對xml格式數據進行解析讀寫的功能,對此有特殊需求的朋友可以前往//pandas.pydata.org/docs/user_guide/io.html#xml詳細了解:
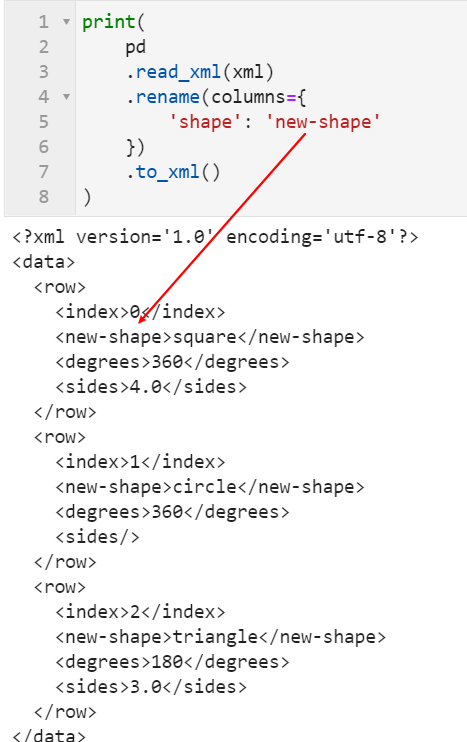
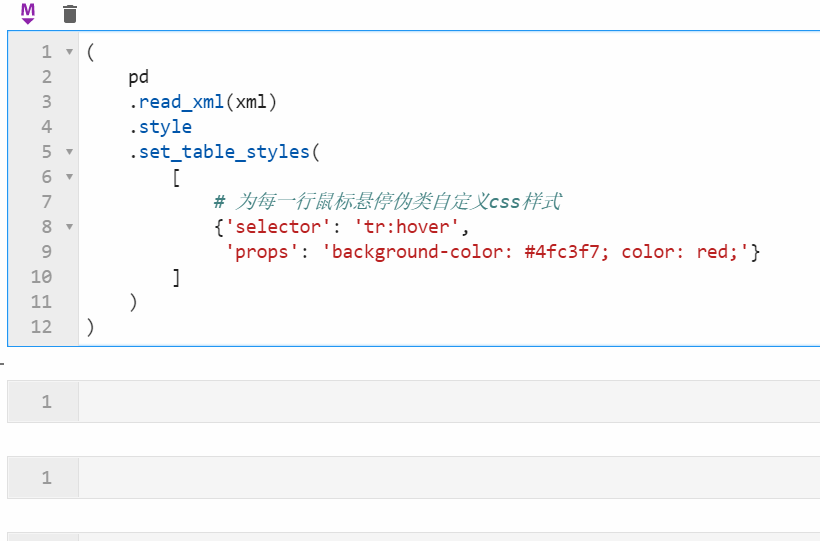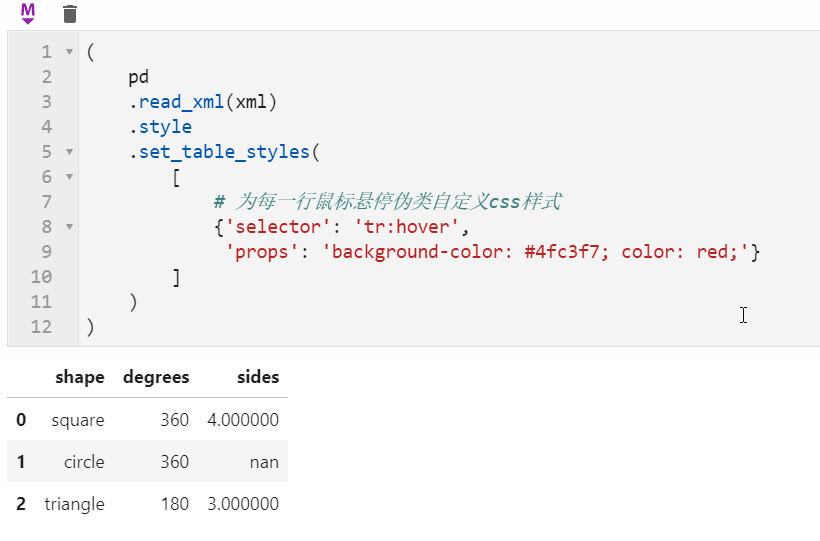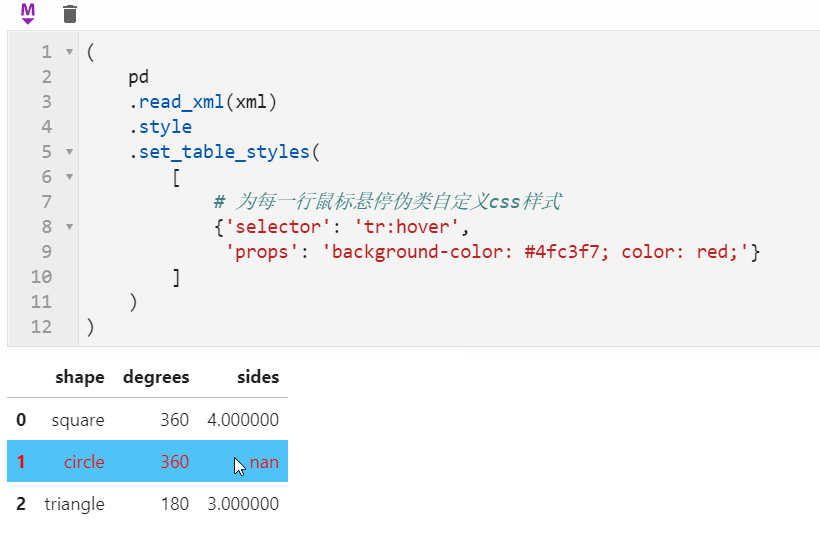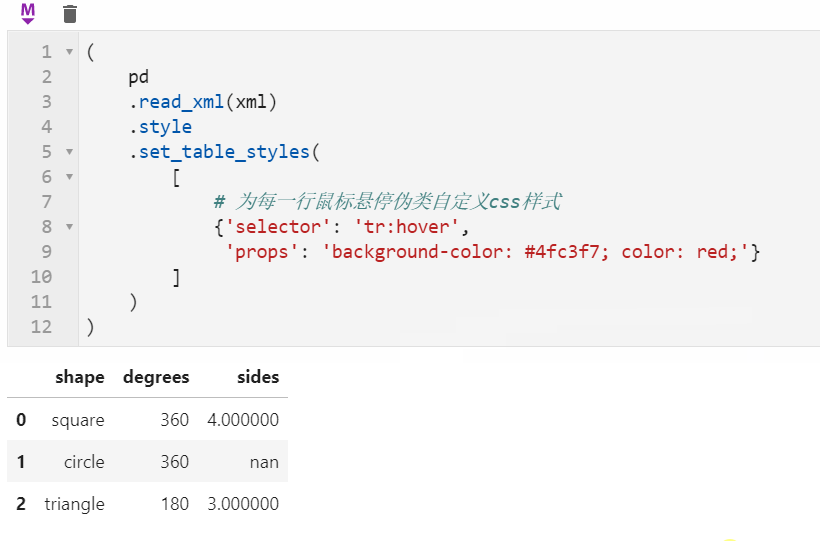
2.2 Styler可使用原生css語法
很多朋友都知道pandas中可以配合Styler對數據框進行自定義樣式輸出,其中最自由的是通過Styler.set_table_styles()來自定義css樣式,以前的方式需要將一條css屬性寫到二元組中傳入,在1.3版本中可以直接傳入css字元串,比如下面我們通過設置hover偽類樣式,來修改每一行滑鼠懸停時的樣式:
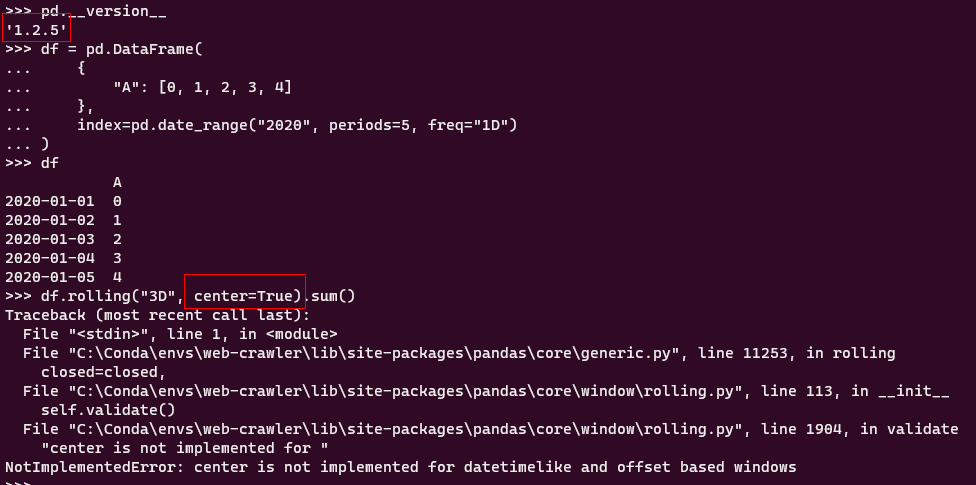
2.3 center參數在時間日期index的數據框rolling操作中可用
在先前的版本中,如果針對行索引為時間日期型的數據框進行rolling滑窗操作使用center參數將每行記錄作為窗口中心時會報錯:
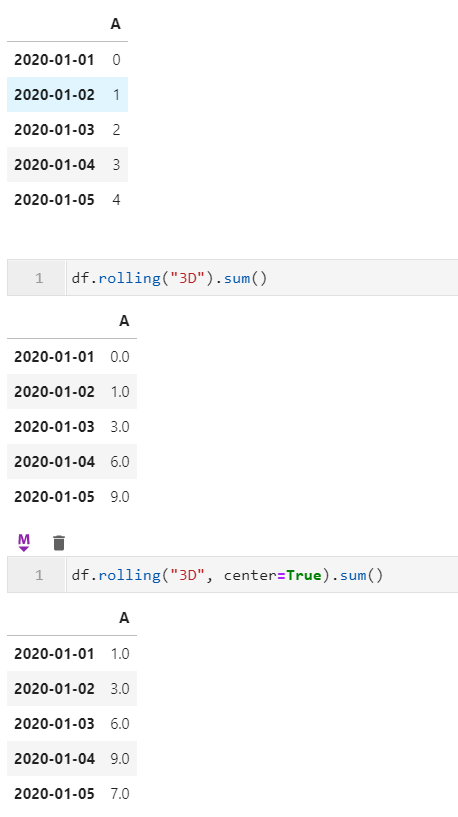
而在1.3中這個問題終於得到解決~方便了許多時序數據分析時的操作:
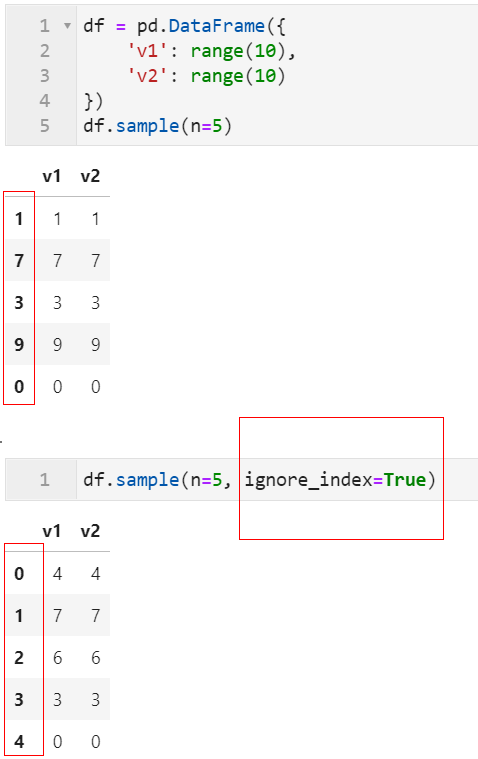
2.4 sample()隨機抽樣新增ignore_index參數
我們都知道在pandas中可以使用sample()方法對數據框進行各种放回/不放回抽樣,但以前版本中抽完樣的數據框每行記錄還保持著先前的行索引,使得我們還得多一步reset_index()操作,而在1.3中,新增類似sort_values()和drop_duplicates()中的同名參數ignore_index:
2.5 explode()新增多列操作支援
當數據框中某些欄位某些位置元素為列表、元組等數據結構時,我們可以使用explode()方法來基於這些序列型元素進行展開擴充,但在以前的版本中每次explode()操作只支援對單個欄位的展開,如果數據中多個欄位之間同一行對應序列型元素位置是一一對應的,需要展開後也是一一對應的,操作起來就比較棘手。
而1.3版本中直接對多欄位同步explode()進行了支援:

2.6 append模式下寫出多工作表excel文件的新策略
在1.3版本中,針對mode='a'模式下向外寫出多工作表excel文件,新增了參數if_sheet_exists來設定新工作表與已存在工作表重名時的處理策略,默認為'error'即直接拋出錯誤,'new'則會自動修改工作表名,'replace'則會覆蓋原同名工作表:

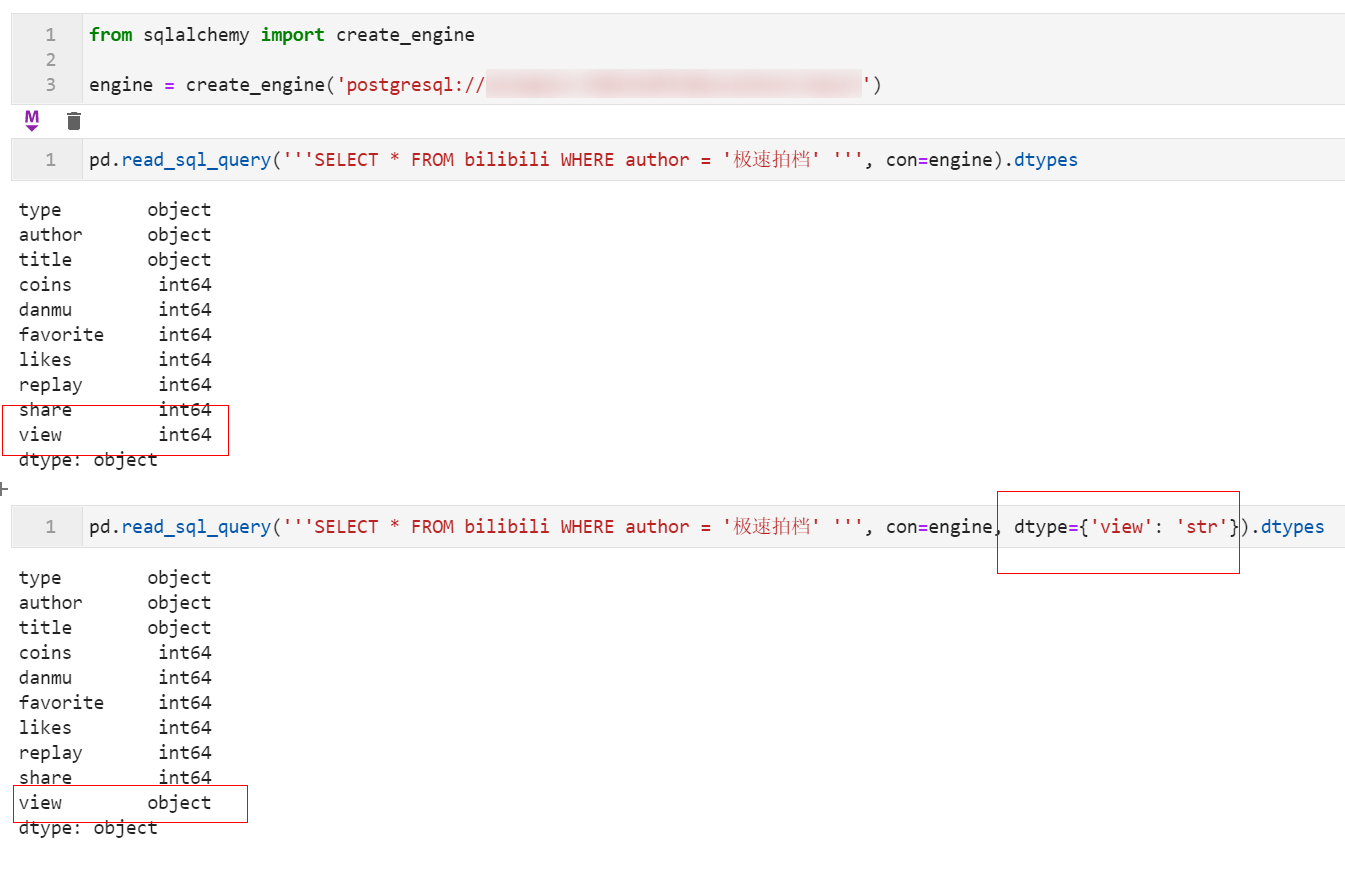
2.7 結合SQL讀取資料庫表時可直接設置類型轉換
在1.3版本中,我們在使用read_sql_query()結合SQL查詢資料庫時,新增了參數dtype可以像在其他API中那樣一步到位轉換查詢到的數據:
以上就是本文的全部內容,歡迎在評論區與我進行討論~


