超清還不夠,插幀演算法讓影片順滑如絲丨NeurIPS 2019
- 2019 年 12 月 22 日
- 筆記

作者 | 商湯
編輯 | Tokai
自相機被發明以來,人們對更高畫質影片的追求就沒有停止過。
解析度從480p,720p,再到1080p,現在有了2K、4K;幀率也從25FPS到60FPS,再到240FPS,960FPS甚至更高……
如果僅靠相機的硬體迭代來提升幀率,存在局限性,因為相機感測器在單位時間內捕捉到的光有局限。而且相機硬體迭代的周期長,成本高。
最近,商湯科技孫文秀團隊,提出了一種可以感知影片中運動加速度的影片插幀演算法(Quadratic Video Interpolation),打破了之前插幀方法的線性模型,將二次方光流預測和深度卷積網路進行融合,讓你的影片順滑如絲。
這種方法有多厲害?來看一個對比:
如果把影片放慢就能明顯感覺到,未經過插幀的慢放影片(左)會明顯示卡頓,而經過Quadratic(二次方)影片插幀方法處理的影片(右)播放流暢。
這個方法的論文被NeurIPS 2019接受為Spotlight論文,該方法還在ICCV AIM 2019 VideoTemporal Super-Resolution Challenge比賽中獲得了冠軍。
二次方插幀 VS 傳統線性插幀
之前的影片插幀方法(包括Phase[1]、DVF[2]、SepConv[3]和SuperSloMo[4]等)是假設相鄰幀之間的運動是勻速的,即沿直線以恆定速度移動。然而,真實場景中的運動通常是複雜的、非線性的,傳統線性模型會導致插幀的結果不準確。
以拋橄欖球的運動影片為例(如下圖1),真實運動中的軌跡是一條拋物線,如果在第0幀和第1幀之間進行插幀,線性模型方法模擬出來軌跡是線性軌跡(右二),與真實運動軌跡(右三)相差較大。

圖1 傳統線性模型與二次方影片插幀結果對比
但通過二次方影片插幀模型模擬出來的運動軌跡是拋物線形(圖1右一),更逼近真實軌跡。也就是說,它能夠更準確地估計影片相鄰幀之間的運動併合成中間幀,從而獲得更精準的插幀結果。
二次方插幀是怎樣「煉」成的?
研究團隊構建了一個可以感知影片運動加速度的網路模型。與傳統線性插幀模型利用兩幀輸入不同,它利用了相鄰四幀影像來預測輸入幀到中間幀的光流,簡易的流程圖如下:

圖2 二次方插幀模型的流程

、

、

和

是輸入影片連續的四幀。給定任意時刻t(0<t<1),該模型將最終生成t時刻的中間幀。而要得到

,就需要更深入了解其中的兩個關鍵技術:二次方光流預測和光流逆轉。
其中,二次方光流預測,就是中學物裡面常講到的求勻變速運動位移的過程:假設在[-1, 1]時刻的運動是勻加速運動,那麼可以利用位移推測出0時刻的速度和區間內的加速度,即可以計算出0時刻到任意t時刻的位移:


圖3:影片中物體運動的示意圖

,

,

,

分別表示物體

,
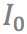
,

,

中的位置
通過以上方法,對稱地我們可以計算出

。此時,我們得到了含有加速度資訊

和
。
為了生成高品質的中間幀,我們需要得到反向光流

和

。
為此研究團隊提出一個可微分的「光流逆轉層」來預測
和
。通過以下轉換公式可以高效的將
和
和轉化為
和
,但是可能會造成逆轉的光流在運動邊界處出現強烈的振鈴效應(見圖4)。

為了消除這些強烈震蕩的部分,研究團隊提出了一種基於深度神經網路的、能夠對逆轉後光流進行自適應取樣的濾波器(Adaptive Flow Filter)。

實驗證明,自適應濾波器(ada.)能夠明顯削弱光流逆轉造成的振鈴效應,從而改善最終合成幀的品質。

圖4 自適應濾波器能夠改善逆轉的光流和合成的中間幀的品質
實驗結果
研究團隊在GOPRO、Adobe240、UCF101和DAVIS四個知名影片數據集上對提出的方法進行測評,並與業界前沿的插幀方法Phase、DVF、SepConv和SuperSloMo進行比較。在每個數據集上,二次影片插針方法都大幅超過現有的方法(見表1、表2)。

表1 本文提出的方法和業界前沿方法在GOPRO和Adobe240數據集上的比較

表2 本文提出的方法和業界前沿方法在UCF101和DAVIS數據集上的比較
除此之外,研究團隊還對各種方法生成中間幀進行了關鍵點跟蹤並進行可視化,從圖5中兩個案例的影片運動軌跡可以看出,用真實慢動作相機採集的中間幀(GT)的運動軌跡是曲線的。線性模型(SepConv、SuperSloMo、Oursw/o qua)生成的中間幀的運動軌跡都是直線,相反,本文的模型(Ours)能夠更精準的預測出非線性軌跡,獲得更好的插幀結果。

圖5 對不同方法的插幀結果進行可視化。第一行和第三行是每種方法的插幀結果和真實影像中間幀(GT)的平均。第二行和第四行對每種方法的插幀結果進行關鍵點跟蹤。
綜上,本文提出的能夠感知影片中運動加速度的插幀方法相比已有的線性插幀演算法,能夠過更好地預測中間幀。
[1]S.Meyer, O.Wang, H.Zimmer, M.Grosse, and A.Sorkine-Hornung. Phase-based frame interpolation for video.In CVPR, 2015
[2]Z.Liu,R.Yeh, X.Tang, Y.Liu, and A.Agarwala. Video frame synthesis using deepvoxel flow. In ICCV,2017.
[3]S.Niklaus, L.Mai, and F.Liu. Video frame interpolationvia adaptive separable convolution. In ICCV,2017
[4] H.Jiang, D.Sun, V.Jampani, M.Yang, E. G. Learned-Miller, and J.Kautz. Superslomo: High quality estimation of multiple intermediate frames for video interpolation. In CVPR, 2018.


