大數據 | 分散式文件系統 HDFS
HDFS全稱Hadoop Distributed File System,看名字就知道是Hadoop生態的一個組件,它是一個分散式文件系統。
它的出現解決了獨立機器存儲大數據集的壓力,它將數據集進行切分,存儲在若干台電腦上。
HDFS 的特點與應用場景
適合存儲大文件
HDFS 支援 GB 級別甚至 TB 級別的文件,它會把大文件切分成若干個塊存儲在不同的節點上,在進行大文件讀寫時採用並行的方式提高數據的吞吐量。
容錯性高
HDFS有多副本機制,它會自動保存副本到不同的節點。即使有一台節點宕機了也不會丟失數據。
適用於流式的數據訪問
HDFS 適用於批量數據的處理,不適合互動式處理。它設計的目標是通過流式的數據訪問保證高吞吐量,不適合對低延遲用戶響應的應用。
適用於讀多寫少場景
HDFS 中的文件支援一次寫入、多次讀取,寫入操作是以追加的方式(append)添加在文件末尾,不支援對文件的任意位置進行修改。
HDFS的相關概念
數據塊(Block)
和磁碟的數據塊概念相似,磁碟中的塊是數據讀寫的最小單位,而HDFS中文件被切分成多個塊,作為獨立的存儲單元,但是比磁碟的塊大得多,默認為128MB,且小於一個塊大小的文件不會佔據整個塊的空間。
需要說明的一點是,數據塊不能設置太小,否則在查找的過程中會造成定址時間長,導致效率慢;另一方面,數據塊太小會造成很多小文件,進而造成元數據也更多,佔用記憶體就更多。
NameNode和DataNode
HDFS中由NameNode和DataNode組成Master-Slave模式(主從模式)運行,NameNode負責管理文件系統的命名空間和文件元數據,記錄了每個文件中各個塊所在的數據節點資訊,而DataNode則是HDFS中的工作節點,負責存儲數據和讀寫操作。簡單理解就是NameNode是主管,DataNode是負責幹活的工人。
Secondary NameNode
若NameNode故障,文件系統上的文件將會丟失,因此對NameNode實現容錯很重要,Hadoop中提供了兩種容錯機制,一種是備份那些組成文件系統元數據持久狀態的文件;另一種就是用Secondary NameNode.
需要注意的是,Secondary NameNode運行在獨立的電腦上,它只是一個輔助而不是一個備用,它不能被用於NameNode。它用於定期合併編輯日誌和命名空間鏡像,防止編輯日誌過大,在NameNode發生故障時啟用。
塊快取
DataNode進行讀寫操作,一般是從磁碟讀取,但對於讀取頻繁的文件,可以被快取在DataNode的記憶體中,以提高讀操作的性能。
HDFS 架構
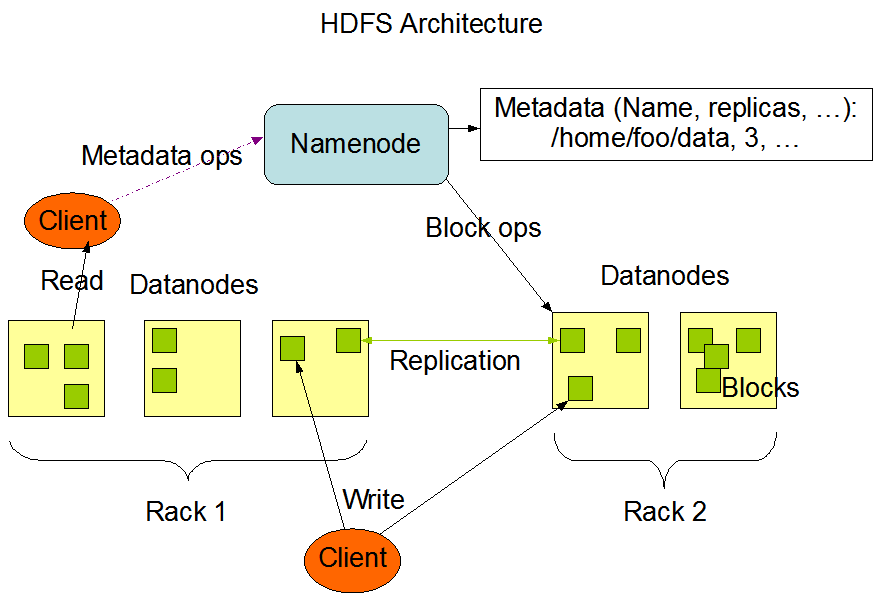
Namenode管理元數據;Datanode存儲Block;Block有多個副本存在不同的節點;節點可以放在不同的機架(Rack);客戶端通過與Namenode與Datanode交互讀取數據(具體的讀寫流程後面講)
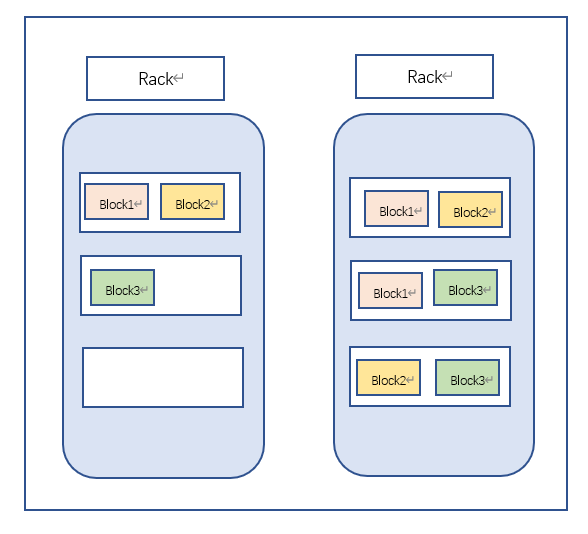
機架感知和副本機制
通常,大型Hadoop集群會分布在很多機架上。
一般為了提高效率,希望不同節點之間的通訊盡量發生在同一個機架之內,而不是跨機架。
另外為了提高容錯能力,儘可能把數據塊的副本放到多個機架上。
機架感知並不是自動感知的,而是需要管理者告知集群實現的。
以一個三副本為例,HDFS機架感知和副本機制大概如圖所示
讀寫流程
讀操作
簡要流程:
客戶端向NameNode發起讀數據請求;
NameNode響應請求並告訴客戶端要讀的文件的數據塊位置;
客戶端就近到對應DataNode取數,當數據讀取到達末端,關閉與這個DataNode的連接,並查找下一個數據塊,直到文件數據全部讀完;
最後關閉輸出流。
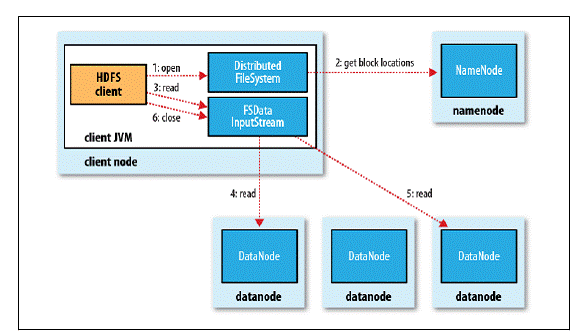
詳細流程:
-
客戶端通過調用 FileSystem 對象的 open() 方法來打開希望讀取的文件,對於 HDFS 來說,這個對象是分散式文件系統的一個實例;
-
DistributedFileSystem 通過RPC 調用 NameNode 以確定文件起始塊的位置,由於存在多個副本,因此Namenode會返回同一個Block的多個文件的位置,然後根據集群拓撲結構排序,就近取;
-
前兩步會返回一個 FSDataInputStream 對象,該對象會被封裝成 DFSInputStream 對象,DFSInputStream 可以方便的管理 datanode 和 namenode 數據流,客戶端對這個輸入流調用 read() 方法;
-
存儲著文件起始塊的 DataNode 地址的 DFSInputStream 隨即連接距離最近的 DataNode,通過對數據流反覆調用 read() 方法,可以將數據從 DataNode 傳輸到客戶端;
-
到達塊的末端時,DFSInputStream 會關閉與該 DataNode 的連接,然後尋找下一個塊的最佳 DataNode,這些操作對客戶端來說是透明的,從客戶端的角度來看只是讀一個持續不斷的流;
-
一旦客戶端完成讀取,就對 FSDataInputStream 調用 close() 方法關閉文件讀取。
寫操作
簡單流程:
客戶端發起寫數據請求;
NameNode響應請求,然後做一些檢查,比如查看文件是否存在,達標則創建文件;
客戶端將文件切分成若干個塊,然後上傳,先把第一個塊傳到Datanode1,然後Datanode1再傳給Datanode2,以此類推,傳完為止;
成功後DataNode會返回一個確認隊列給客戶端,客戶端進行效驗,然後客戶端上傳下一個數據塊到DataNode,直到所有數據塊寫入完成;
當所有數據塊全部寫入成功後,客戶端會向NameNode發送一個回饋並關閉數據流。
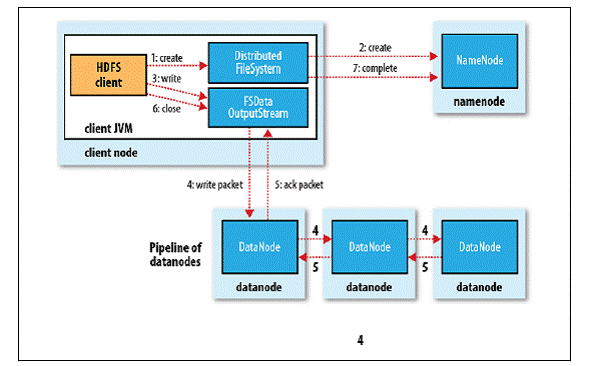
詳細流程:
-
客戶端通過調用 DistributedFileSystem 的 create() 方法創建新文件;
-
DistributedFileSystem 通過 RPC 調用 NameNode 去創建一個沒有 Blocks 關聯的新文件,創建前 NameNode 會做各種校驗,比如文件是否存在、客戶端有無許可權去創建等。如果校驗通過,NameNode 會為創建新文件記錄一條記錄,否則就會拋出 IO 異常;
-
前兩步結束後會返回 FSDataOutputStream 的對象,和讀文件的時候相似,FSDataOutputStream 被封裝成 DFSOutputStream,DFSOutputStream 可以協調 NameNode 和 Datanode。客戶端開始寫數據到 DFSOutputStream,DFSOutputStream 會把數據切成一個個小的數據包,並寫入內部隊列稱為「數據隊列」(Data Queue);
-
DataStreamer 會去處理接受 Data Queue,它先問詢 NameNode 這個新的 Block 最適合存儲在哪幾個 DataNode 里,比如重複數是 3,那麼就找到 3 個最適合的 DataNode,把他們排成一個 pipeline。DataStreamer 把 Packet 按隊列輸出到管道的第一個 Datanode 中,第一個 DataNode 又把 Packet 輸出到第二個 DataNode 中,以此類推;
-
DFSOutputStream 還有一個隊列叫 Ack Quene,也是由 Packet 組成,等待 DataNode 的收到響應,當 Pipeline 中的所有 DataNode 都表示已經收到的時候,這時 Akc Quene 才會把對應的 Packet 包移除掉;
-
客戶端完成寫數據後調用 close() 方法關閉寫入流;
-
DataStreamer 把剩餘的包都刷到 Pipeline 里然後等待 Ack 資訊,收到最後一個 Ack 後,通知 NameNode 把文件標示為已完成。
總結
本文簡單講了 HDFS 的特點與應用場景、相關概念、架構、副本機制和機架感知以及讀寫流程。如果覺得有幫到你或者有所收穫,麻煩動動小手點個贊或隨手轉發。
微信掃碼關注不迷路,第一時間獲取文章哦


