天池-安泰杯跨境電商智慧演算法大賽(冠軍)方案分享
- 2019 年 12 月 22 日
- 筆記
天池-安泰杯跨境電商智慧演算法大賽
–冠軍團隊:法國南部
團隊成員:Rain/Fish/楠枰
在19年9月下旬結束的"安泰杯"跨境電商智慧演算法大賽中,來自京東零售的法國南部隊伍成功從1960支隊伍中脫穎而出,在複賽階段成功逆襲到第一,並通過答辯獲得冠軍。在接近2千隻參賽隊伍中他們如何取勝,並成功壓制住植物的反擊,他們獲勝方案又有什麼可取之處?本文將會給出完整的賽題解析和解題方案介紹。
★ 賽題介紹 ★
AliExpress是阿里巴巴海外購物網站,其網站的海外用戶可以在AliExpress挑選購買自己心意的商品。對於AliExpress來說,目前某些國家A的用戶群體比較成熟,沉澱了大量的該國用戶的行為數據。但是還有一些待成熟國家B的用戶在AliExpress上的行為比較稀疏。
對於這些國家B用戶的推薦演算法如果單純不加區分的使用全網用戶的行為數據,可能會忽略這些國家用戶的一些獨特的用戶特點。而如果只使用國家B的用戶的行為數據,由於數據過於稀疏,不具備統計意義,會難以訓練出正確的模型。
賽題難點是:怎樣利用已成熟國家A的稠密用戶數據和待成熟國家B的稀疏用戶數據,訓練出的正確模型對於國家B的用戶有很大價值。
賽題數據給出若干日內來自成熟國家的部分用戶的行為數據,以及來自待成熟國家的A部分用戶的行為數據,以及待成熟國家的B部分用戶的行為數據去除每個用戶的最後一條購買數據,讓參賽人預測B部分用戶的最後一條行為數據。
賽題評價指標:賽題旨在通過海量數據挖掘用戶下一個可能交互商品,選手們可以提交預測的TOP30商品列表,排序越靠前命中得分越高。
賽題具體使用MRR(Mean Reciprocal Rank)對選手提交的表格中的每個用戶計算用戶得分:

其中, 如果選手對該buyer的預測結果predict k命中該buyer的最後一條購買數據則s(buyer,k)=1 s(buyer,k)=1; 否則s(buyer,k)=0 s(buyer,k)=0. 而選手得分為所有這些score(buyer)的平均值。

★ 賽題數據 ★
初賽數據
● 商品屬性表
數據中共涉及2840536個商品,對於其中大部分商品,都會給出該商品的類目id、店鋪id以及加密價格,其中價格的加密函數f(x)為一個單調增函數。
● 訓練數據
給出xx國的用戶的購買數據和yy國的部分用戶的購買數據。

● 測試數據
給出yy國的B部分用戶的購買數據除掉最後一條。數據的整體統計資訊如下:

商品屬性表、訓練數據、測試數據對應的文件:item_attr, train和test。無論是訓練數據還是測試數據,都具有如下的格式:

其中各欄位含義如下:
1. buyer_country_id: 買家國家id, 有'xx'和'yy'兩種取值;
2. buyer_admin_id: 買家id;
3. item_id: 商品id;
4. create_order_time: 訂單創建時間;
5. irank: 每個買家對應的所有記錄按照時間順序的逆排序;
初賽數據集特點:
1)每個用戶有至少7條購買數據;
2)測試數據中每個用戶的最後一條購買數據所對應的商品一定在訓練數據中出現過;
3)少量用戶在兩個國家有購買記錄,評測中忽略這部分記錄;
複賽數據
在給出若干日內來自某成熟國家xx的部分用戶的點擊購買數據,以及來自某待成熟國家yy和待成熟國家zz的A部分用戶的點擊購買數據,以及國家yy和zz的B部分用戶的截止最後一條購買數據之前的所有點擊購買數據,讓參賽人預測B部分用戶的最後一條購買數據。
● 商品屬性表
點擊購買數據中涉及9136277個商品,對於其中大多數商品,我們都會給出該商品的類目id、店鋪id以及加密價格,其中價格的加密函數f(x)為一個單調增函數。
● 訓練數據
給出xx國的用戶的點擊、購買數據和yy國、zz國的A部分用戶的點擊、購買數據。

● 測試數據
給出yy國、zz國的B部分用戶的最後一條購買數據之前的點擊購買數據。

無論是訓練數據還是測試數據,都具有如下的格式:

其中各欄位含義如下:
1. buyer_country_id: 買家國家id, 只有'xx','yy','zz'三種取值2. buyer_admin_id: 買家id
3. item_id: 商品id
4. log_time: 商品詳情頁訪問時間
5. irank: 每個買家對應的所有記錄按照時間順序的逆排序
6. buy_flag: 當日是否購買
複賽數據集特點:
1)每個用戶有若干條點擊數據和至少1條購買數據 (但測試數據中該條購買記錄可能未給出到選手;
2)每個用戶的最後一條數據的buy_flag一定為1 (但測試數據中該條數據未給出到選手;
3)測試數據中每個用戶的最後一條點擊數據(也是購買數據)所對應的商品一定在訓練數據中出現過;
4)可能存在少量跨國買家.
★ 賽題分析 ★
賽題分析是深入理解賽題的最有效的方法,也是構建有效特徵和模型的先驅條件。
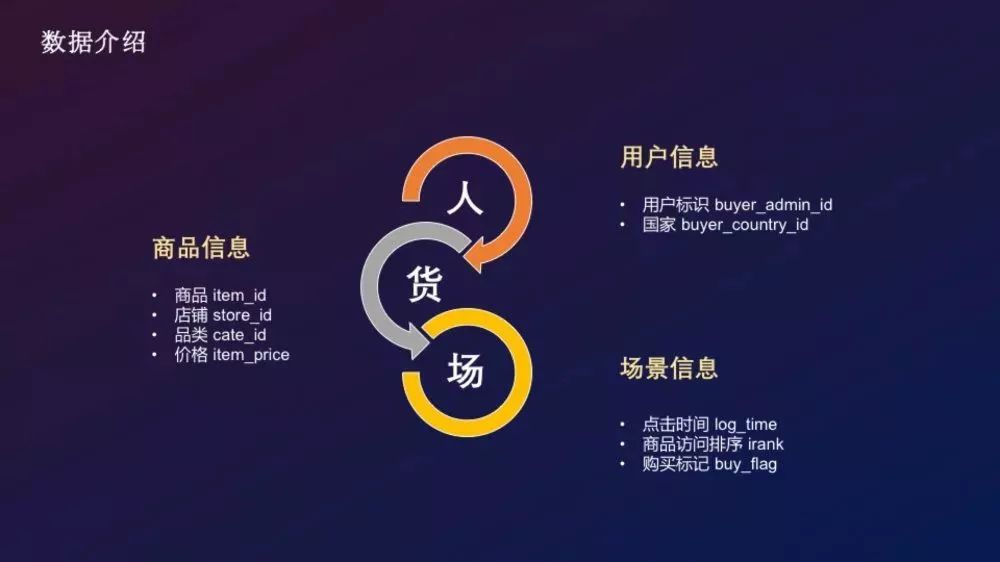
根據零售行業的人貨場概念,賽題提供了關於用戶行為日誌的常見欄位可分為如下部分:
- 用戶:用戶標識、用戶國籍
- 商品:商品標識、店鋪、品類、價格
- 場景:點擊時間、訪問排序、購買標記
通過對賽題數據進行探索和分析,我們發現可以根據預測商品是否在歷史交互過分成兩種不同分布的用戶:
- 歷史交互用戶(68%):即預測商品用戶曾經已交互過,在召回-排序階段: 召回:可通過buy_flag=1,將交互商品全量召回 排序:基於用戶商品交互資訊,解決排序問題,預測精度高
- 冷啟動用戶(32%):即預測商品用戶從未交互過,在召回-排序階段: 召回:基於商品關聯資訊召回,召回難度大 排序:基於用戶最近交互商品與關聯資訊進行排序,預測精度較低
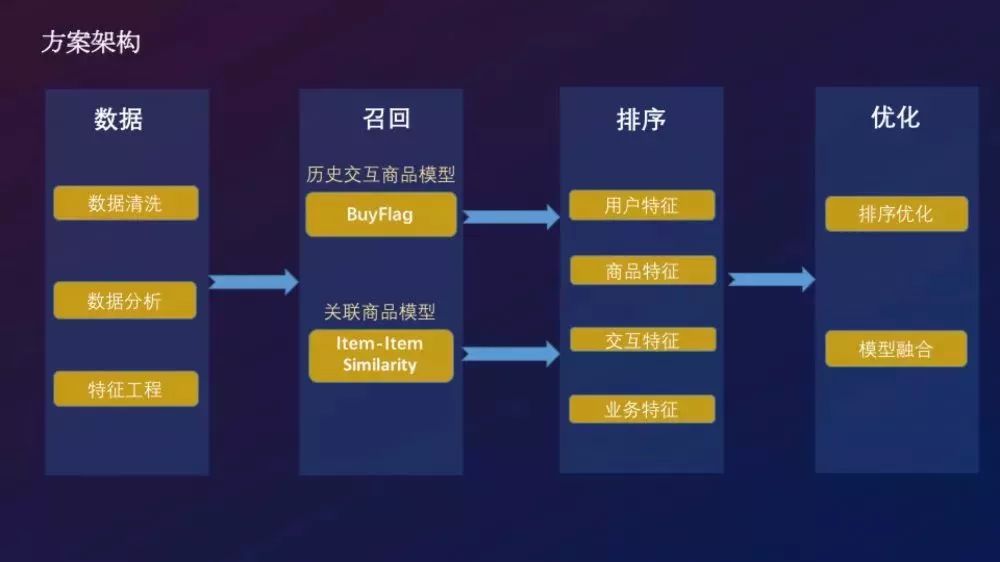
方案思路:面對兩種不同分布的用戶,我們因地制宜基於不同樣本和特徵分別建立兩個排序模型,然後再通過用戶判斷模型對兩個排序的結果進行優化。
★ 特徵工程 ★
賽題所給的欄位相對簡單,主要可分為:用戶-商品-場景,我們通過對不同類型因素進行交叉複合,並使用基礎統計手段進行計算,構造出高階特徵,提取出購物決策的相關資訊:

通過對以上維度的交叉統計,形成高階特徵群,提取出購物決策的關鍵資訊,下圖給出了所提取特徵的貢獻度:

★ 構建模型 ★
根據上述的分析我們構建了兩個模型:
- 歷史交互商品模型
- 關聯商品模型
歷史交互商品模型
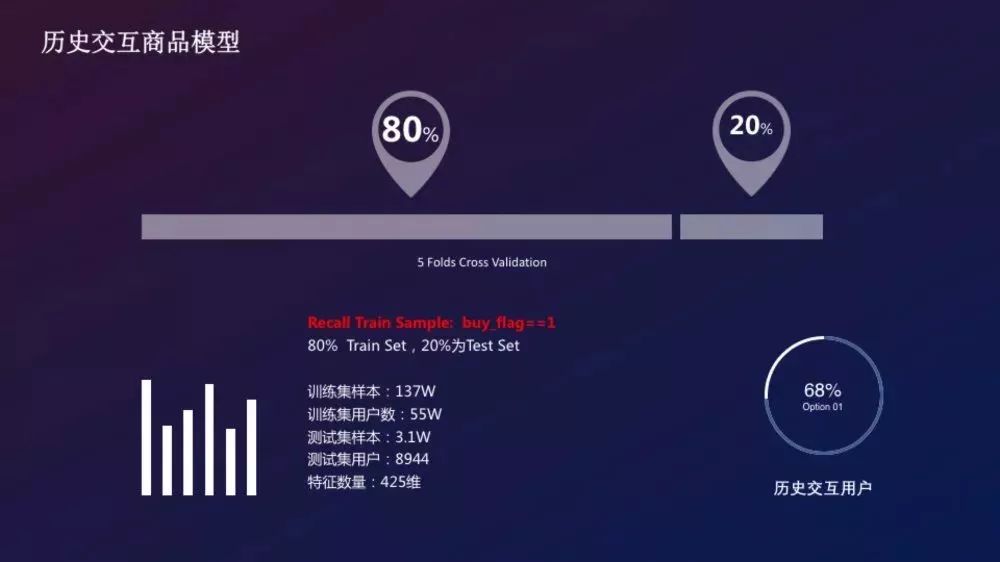
- 樣本構造:提取buy_flag=1的user-item作為樣本,用戶最後交互的設為正樣本,其他為負樣本
- 模型資訊:這裡使用的LightGBM模型;
- 樣本資訊:
- 訓練集樣本數:137W
- 訓練集用戶數:55W
- 測試集樣本數:3.1W
- 測試集用戶數:8944
- 特徵數量:425
- Model:LightGBM
- loss function:AUC
- 模型效果: AUC: 0.9493 MRR: 0.8922
- Recall Rate 樣本召回率:
- Top1 item:81%
- Top3 item:92.5%
- Top10 item:99%

這個時候線上達到0.6085的成績,排名第五,當然目前僅是考慮到了歷史有過交互的商品,接下來將建立關聯商品模型。
關聯商品模型
那麼我們如何找到用戶未來可能交互的商品?比較好的方法是挖掘關聯商品,根據用戶歷史交互商品,找到這些商品的關聯品。

- Item-Item similarity Based on Sequnence 商品相似性:基於用戶行為序列計算,假設用戶越近交互的兩個商品相似性越高,並且考慮先後次序,通過線性搜索得到如下相似度計算公式:
- 樣本構造:對用戶最近5個交互商品的關聯商品(加上時間衰減權重),選取每個用戶TOP50關聯商品,之前得到的關聯度中間結果直接作為特徵訓練排序模型
- 模型資訊:
- 訓練集樣本數:940W
- 訓練集用戶數:18W
- 測試集樣本數:47W
- 測試集用戶數:8944
- 特徵數量:222
- Model:LightGBM
- loss function:AUC
- 模型效果: AUC: 0.9736 MRR: 0.0554
- Rcall Rate:
- Top1 item:3.1%
- Top3 item:6.3%
- Top30 item:15%

經過關聯商品模型來解決冷啟動的問題,我們的成績也由0.6085提高到0.6187,排名提升到第一。
★ 模型融合/優化 ★
排序優化

如圖所示,歷史商品模型排序第4的商品召回率僅有1.5,而關聯模型排序第一位召回率為3.1。
為了優化排序結果,優化兩部分模型的結果,通過用戶判別模型(預測用戶是否為冷啟動用戶),對概率大於0.95的高置信度用戶直接截取掉歷史TOP3後,與商品與關聯模型的結果進行拼接,得到最終的Top30商品排序。

模型融合
- Enseblem 對於歷史交互商品模型,訓練了LightGBM、Xgboost、CatBoost三個模型,通過對預測結果簡單加權進行融合。

- Stacking 此外,在每個模型訓練過程中通過簡單Stacking將其他4折的預測結果作為特徵反喂模型,進一步擬合結果。
通過排序優化和stacking後,我們將分數從0.6198提升到0.6256,進一步拉開了與其他隊伍的差距。
★ 比賽總結 ★
在本次比賽前期,我花費了大量精力進行數據探索和分析,基於對數據和業務的了解才確立了最終的方案和優化路線。當對數據之間的聯繫瞭然於心後,開始進行細緻的特徵工程以提取各種資訊,在也是歷史交互模型得分提升的關鍵。
此後,為了提高召回率,嘗試了Embedding、協同過濾等方法,但是由於數據量和category欄位少的限制,都沒取得太好的效果,開始基於業務理解,嘗試建立關聯度計算公式,通過不斷搜索參數,取得了不錯的召回率,由此建立關聯商品模型,此時成績也上升到第一名。
最後階段,我們開始提高模型的精度和穩定性,一是建立了用戶判別模型對排序進行了優化,二是對模型進行了融合以及stacking,得到了0.6256分數,進一步擴大了領先優勢。
取勝關鍵 = 充分理解業務 + 完備的特徵工程 + 合理建模方法 + 細緻結果優化 + 堅持就是勝利!
比賽PPT和程式碼分享關注我們的開源項目:
https://github.com/datawhalechina/competition-baseline
更多資訊 關注Coggle數據科學



