hive學習筆記之九:基礎UDF
- 2021 年 7 月 8 日
- 筆記
歡迎訪問我的GitHub
//github.com/zq2599/blog_demos
內容:所有原創文章分類匯總及配套源碼,涉及Java、Docker、Kubernetes、DevOPS等;
《hive學習筆記》系列導航
本篇概覽
- 本文是《hive學習筆記》的第九篇,前面學習的內置函數儘管已經很豐富,但未必能滿足各種場景下的個性化需求,此時可以開發用戶自定義函數(User Defined Function,UDF),按照個性化需求自行擴展;
- 本篇內容就是開發一個UDF,名為udf_upper,功能是將字元串欄位轉為全大寫,然後在hive中使用這個UDF,效果如下圖紅框所示:
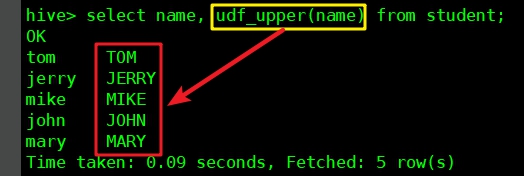
- 本篇有以下章節:
- 開發
- 部署和驗證(臨時函數)
- 部署和驗證(永久函數)
源碼下載
- 如果您不想編碼,可以在GitHub下載所有源碼,地址和鏈接資訊如下表所示:
| 名稱 | 鏈接 | 備註 |
|---|---|---|
| 項目主頁 | //github.com/zq2599/blog_demos | 該項目在GitHub上的主頁 |
| git倉庫地址(https) | //github.com/zq2599/blog_demos.git | 該項目源碼的倉庫地址,https協議 |
| git倉庫地址(ssh) | [email protected]:zq2599/blog_demos.git | 該項目源碼的倉庫地址,ssh協議 |
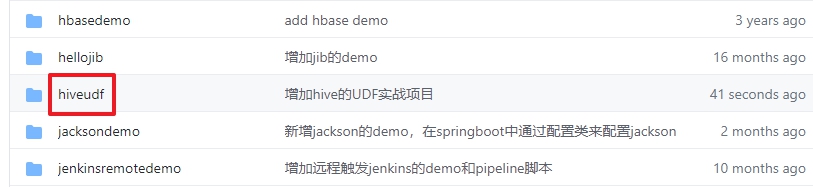
- 這個git項目中有多個文件夾,本章的應用在hiveudf文件夾下,如下圖紅框所示:
開發
- 新建名為hiveudf的maven工程,pom.xml內容如下,有兩處需要關注的地方,接下來馬上講到:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="//maven.apache.org/POM/4.0.0"
xmlns:xsi="//www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="//maven.apache.org/POM/4.0.0 //maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bolingcavalry</groupId>
<artifactId>hiveudf</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.2</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>pentaho-aggdesigner-algorithm</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.7</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project>
- 上述pom.xml中,兩個依賴的scope為provided,因為這個maven工程最終只需要將咱們寫的java文件構建成jar,所以依賴的庫都不需要;
- 上述pom.xml中排除了pentaho-aggdesigner-algorithm,是因為從maven倉庫下載不到這個庫,為了能快速編譯我的java程式碼,這種排除的方式是最簡單的,畢竟我用不上(另一種方法是手動下載此jar,再用maven install命令部署在本地);
- 創建Upper.java,程式碼如下非常簡單,只需存在名為evaluate的public方法即可:
package com.bolingcavalry.hiveudf.udf;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDF;
public class Upper extends UDF {
/**
* 如果入參是合法字元串,就轉為小寫返回
* @param str
* @return
*/
public String evaluate(String str) {
return StringUtils.isBlank(str) ? str : str.toUpperCase();
}
}
- 編碼已完成,執行mvn clean package -U編譯構建,在target目錄下得到hiveudf-1.0-SNAPSHOT.jar文件;
- 接下來將咱們做好的UDF部署在hive,驗證功能是否正常;
部署和驗證(臨時函數)
- 如果希望UDF只在本次hive會話中生效,可以部署為臨時函數,下面是具體的步驟;
- 將剛才創建的hiveudf-1.0-SNAPSHOT.jar文件下載到hive伺服器,我這邊路徑是/home/hadoop/udf/hiveudf-1.0-SNAPSHOT.jar;
- 開啟hive會話,執行以下命令添加jar:
add jar /home/hadoop/udf/hiveudf-1.0-SNAPSHOT.jar;
- 執行以下命令創建名為udf_upper的臨時函數:
create temporary function udf_upper as 'com.bolingcavalry.hiveudf.udf.Upper';
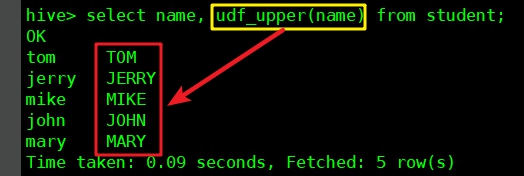
- 找一個有數據並且有string欄位的表(我這是student表,其name欄位是string類型),執行以下命令:
select name, udf_upper(name) from student;
- 執行結果如下,紅框中可見udf_upper函數將name欄位轉為大寫:
- 這個UDF只在當前會話窗口生效,當您關閉了窗口此函數就不存在了;
- 如果您想在當前窗口將這個UDF清理掉,請依次執行以下兩個命令:
drop temporary function if exists udf_upper;
delete jar /home/hadoop/udf/hiveudf-1.0-SNAPSHOT.jar;
- 刪除後再使用udf_upper會報錯:
hive> select name, udf_upper(name) from student;
FAILED: SemanticException [Error 10011]: Line 1:13 Invalid function 'udf_upper'
部署和驗證(永久函數)
- 前面體驗了臨時函數,接下來試試如何讓這個UDF永久生效(並且對所有hive會話都生效);
- 在hdfs創建文件夾:
/home/hadoop/hadoop-2.7.7/bin/hadoop fs -mkdir /udflib
- 將jar文件上傳到hdfs:
/home/hadoop/hadoop-2.7.7/bin/hadoop fs -put /home/hadoop/udf/hiveudf-1.0-SNAPSHOT.jar /udflib/
- 在hive會話窗口執行以下命令,使用hdfs中的jar文件創建函數,要注意的是jar文件地址是hdfs地址,一定不要漏掉hdfs:前綴:
create function udf_upper as 'com.bolingcavalry.hiveudf.udf.Upper'
using jar 'hdfs:///udflib/hiveudf-1.0-SNAPSHOT.jar';
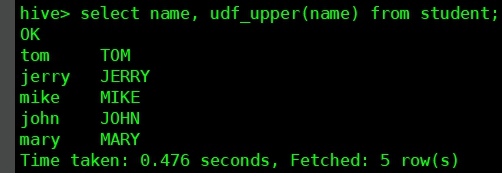
- 試一下這個UDF,如下圖,沒有問題:
6. 新開hive會話窗口嘗試上述sql,依舊沒有問題,證明UDF是永久生效的;
- 至此,咱們已經對hive的UDF的創建、部署、使用都有了基本了解,但是本篇的UDF太過簡單,只能用在一進一出的場景,接下來的文章咱們繼續學習多進一出和一進多出。
你不孤單,欣宸原創一路相伴
歡迎關注公眾號:程式設計師欣宸
微信搜索「程式設計師欣宸」,我是欣宸,期待與您一同暢遊Java世界…
//github.com/zq2599/blog_demos


