使用 python 把一個文件生成 C 語言中的數組並保存到頭文件中
(一)要做什麼
之前有這麼一個需求,是要把一個二進位文件裡面的數據,轉換成 C 程式碼裡面的數組,可以看之前的一篇文章:
NUC980 運行 RT-Thread 驅動 SPI 介面 OLED 播放 badapple
於是用 python 把這個功能給做了出來,原理非常簡單,程式碼量也很小。
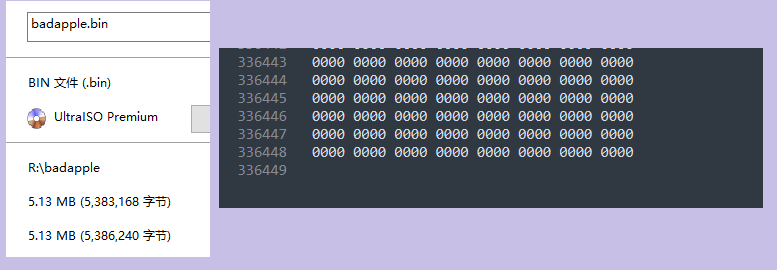
所處理的文件大小如下,用一個編輯器以二進位形式打開的話,一行16位元組,一共 336448 行。
(二)實現功能
上程式碼,Show me your code.Talk is cheap.
import os
import time
start_time = time.time()
fileinfo = os.stat("badapple.bin")
line = fileinfo.st_size / 16
print(line)
首先導入 os、time 模組,os 模組用戶獲取所處理文件的大小,生成的頭文件裡面的數組每 16 位元組一行,time 模組用於統計程式所使用時間,上述程式碼運行結果為:

336648 行,正好與之前看到的一致。
然後定義一個變數,用來存儲最終的數據:
target = "#ifndef __BADAPPLE_H__ \n#define __BADAPPLE_H__\n\n const uint8_t badapple[] = \n{\n"
然後打開文件 badapple.bin,以二進位、只讀方式打開,每次讀取一位元組,然後轉換成二進位,與 0x 組成一個位元組數據,保存到上述字元串中,每處理完 16 位元組添加換行,處理完後關閉文件,程式碼如下:
f = open("badapple.bin", "rb")
for l in range(int(line)):
for j in range(16):
data = f.read(1)
he = "0x" + data.hex()
target = target + he + ","
print(l)
target = target + "\n"
target = target + "}; \n\n#endif\n"
print(target)
f.close()
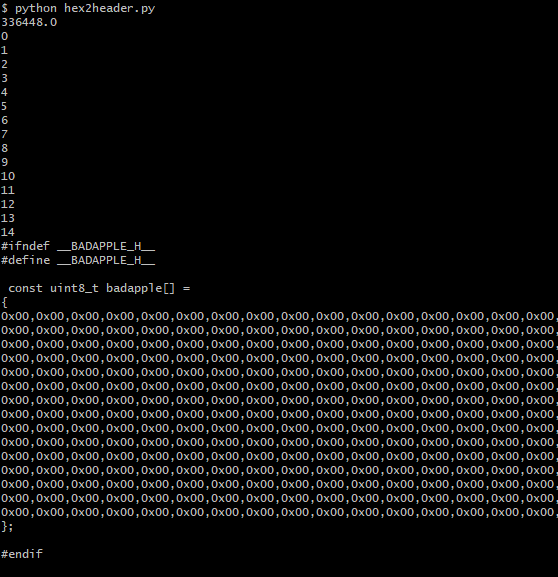
由於全部數據有 30 多萬行,不好測試,先只處理 badapple.bin 文件中的前 15 行,來測試下程式碼有沒有問題,把上面程式碼中的第二行改為:
for l in range(15):
運行結果為:
看上去是可以的,然後實現把轉換出來的數據保存到文件中,並加上獲取運行改程式碼所花時間,程式碼如下:
file = open("badapple.h","w")
file.write(target)
file.close()
end_time = time.time()
print(end_time - start_time)
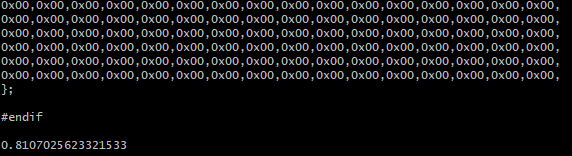
運行結果為:
所生成的文件為:
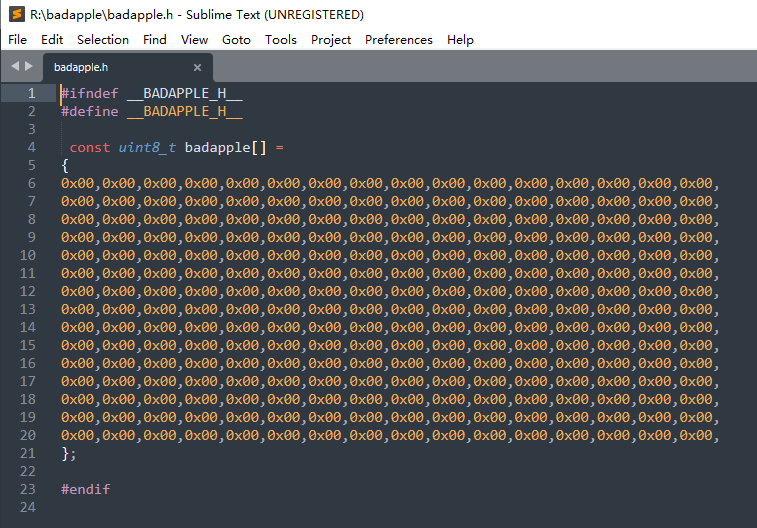
從所生成的文件來看,算是大功告成了,把所需處理行數改為實際文件的行數,就完成了。
然而,我還是圖樣圖森破啊,我以為我在第二層,其實我在第五層。
第一次運行的時候,跑了幾十分鐘,停了,感覺所花時間大大久了,
出於對自己寫的程式碼負責的態度,第二天下午 3 點多的時候,再次把這程式碼跑了起來,可是到了6點多還是沒跑完,又中途結束了,
很好奇,究竟需要多長時間來跑,第三天,一早上就把程式碼跑了起來,結果是到了下午 6 點多,差不多 7 點才跑完,來看下運行的最後結果:
從數字來看,30545 秒,感覺也不是很大,可是轉換為小時的話:
30545 / 60 / 60 = 8.4
居然達到了 8.4 個小時,這是生成的文件:
(三) 優化
要這麼久時間來跑肯定是不實際的,修改下程式碼,之前是一個位元組一個位元組從文件裡面讀出來,這次改為每次從文件中讀取 16 位元組,轉換,然後再讀取16位元組,知道結束,程式碼如下:
target = "#ifndef __BADAPPLE_H__ \n#define __BADAPPLE_H__\n\n const uint8_t badapple[] = \n{\n"
line = fileinfo.st_size / 16
print(line)
for l in range(int(line)):
data = f.read(16)
he = ""
for da in data:
he = he + hex(da) + ","
print(l)
target = target + he + "\n"
target = target + "}; \n\n#endif\n"
運行下,最後結果為:

2165 秒,大概是 36 分鐘,也還是有點長。
再改改,對比下這 2 中方法,第二種是每次讀出來的位元組數是第一種的16倍,速度明顯提升了,可以看出時間是損耗在從文件讀取數據,那如果一次性把所用數據從文件種讀取出來會不會更快呢?試了下,程式碼改為:
f = open("badapple.bin", "rb")
target = "#ifndef __BADAPPLE_H__ \n#define __BADAPPLE_H__\n\n const uint8_t badapple[] = \n{\n"
dat = f.read()
print(type(dat))
f.close()
whole = dat.__len__()
line = int(whole / 16)
for i in range(line):
temp = dat[i*16:i*16+16]
he = ""
for da in temp:
he = he + hex(da) + ","
target = target + he + "\n"
print(i)
target = target + "}; \n\n#endif\n"
運行了下,結果為:
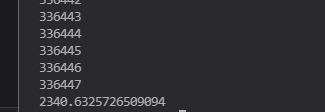
2340 秒,居然比第二種方法還長。
還有什麼方法可以改進呢?現在時間估計是花在轉換上面,在轉換上有沒有改進方法,目前還沒找出來。
(四)做的更通用
那是不是說這段程式碼就完全沒用,非也非也,用來轉換小點的文件還是可以的,這不止可以轉換二進位文件,還可以轉換其他任何文件,比如圖片、字型檔等,以下是轉換一張圖片運行的結果:
為了更通用,修了下程式碼,如下:

運行的時候需要傳個參數,這個參數就是要處理的文件,最後生成的頭文件、頭文件里數組命名都是根據處理的文件的名字來設定的,運行過程中還顯示處理進度,最後顯示處理所花時間。比如把上述程式碼保存到文件 hex2header.py,比如要轉換的文件為 test.pdf,用法為:
python hex2header.py test.pdf
實際運行為:
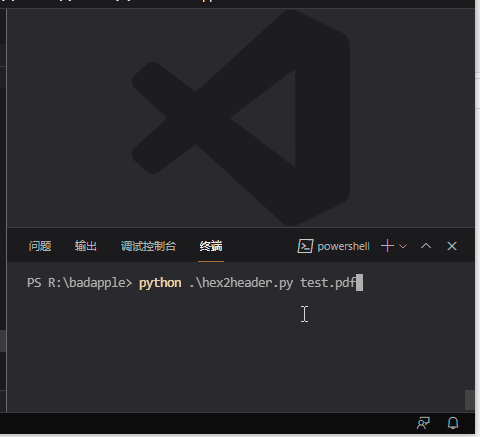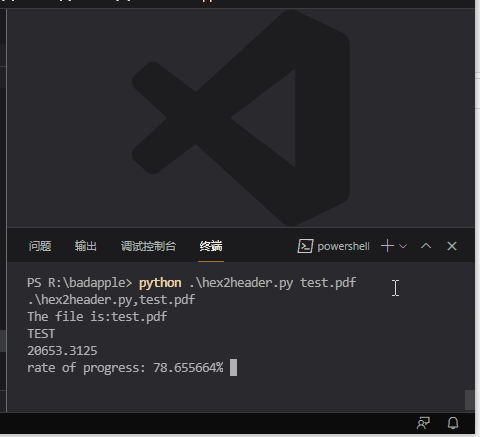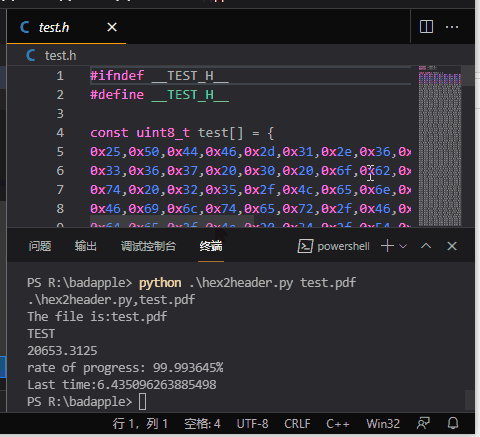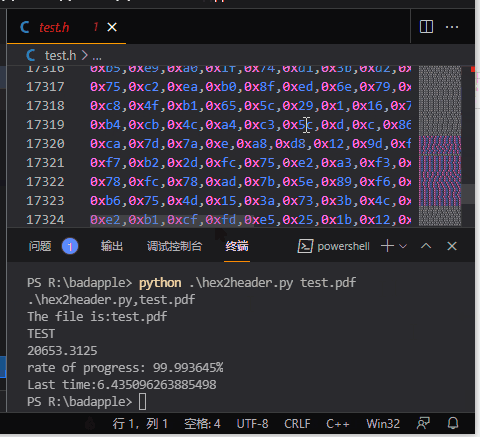
這示例轉換了一個 323K 大小的 pdf 文件,每行 16 位元組的話,大概 20653 行,花了6.4 秒的時間。
轉載請註明出處://www.cnblogs.com/halin/


