圖解協程調度模型-GMP模型
- 2021 年 7 月 6 日
- 筆記
現在無論是客戶端、服務端或web開發都會涉及到多執行緒的概念。那麼大家也知道,執行緒是作業系統能夠進行運算調度的最小單位,同一個進程中的多個執行緒都共享這個進程的全部系統資源。
執行緒
三個基本概念
- 內核執行緒:在內核空間實現的執行緒,由內核管理
- 用戶執行緒:在用戶空間實現的執行緒,不歸內核管理,由用戶態完成管理
- 輕量級進程(LWP):在內核中支援用戶執行緒(用戶執行緒與內核執行緒的中間層,內核執行緒的高度抽象)
執行緒模型

-
一對一模型(內核級執行緒模型)
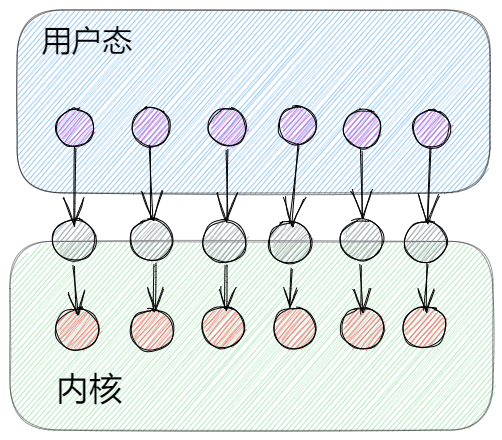
由進程創建LWP,由於每個LWP對應一個內核級執行緒,所以用戶也就是在創建一個一個內核執行緒,由內核管理執行緒。我們熟知的大多數語言就是屬於一對一模型,比如C#、java、c等(這些語言也有相應的方式實現用戶態執行緒,只是語言本身的執行緒是一對一模型)
-
一對多模型(用戶級模型)

用戶進程創建多個用戶級執行緒對應在同一個LWP上,所以本質上在內核態只會有一個內核執行緒運行,那麼用戶及執行緒的調度就是在用戶態通過用戶空間的執行緒庫對執行緒進行管理。
這類模型優點就是調度在用戶態,所以不用頻繁地進行內核態與用戶態切換,大大提升執行緒效率。python語言的協程就是這種模型實現的,但是這種模型並不能實現真正意義上的的並發。
-
多對多模型(用戶級與內核級執行緒模型)
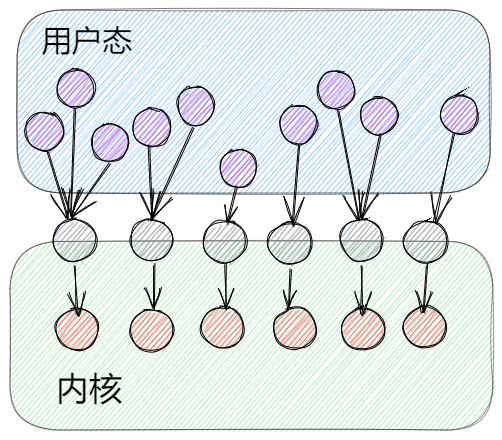
多對多模型也就是在上述兩個模型基礎上做一些優點的集合。用戶態的多個執行緒對應多個LWP,但它們之間不是一一對應的,在用戶態管理調度每個LWP對應的用戶執行緒綁定關係。
所以多對多模型是可以有更多的用戶態執行緒在相對於比較少的內核執行緒上運行的。這種用戶態執行緒也就是我們平時說的協程。Go語言的協程就是多對多模型,它由Go語言的runtime在用戶態做調度,這也是Go語言高並發的原因。



協程(Goroutine)
前面我們說到,協程就是用戶態執行緒,它的所有調度都在用戶態實現,協程這方面Go語言應該是最具代表性的(畢竟以高並發為賣點),以Go語言的協程–Goroutine作為研究對象。
GM模型
在Go語言設計的初期,Go團隊使用簡單的GM模型實現協程。
G:goroutine,也就是協程,它一般所佔的棧記憶體為2KB,運行過程中如果棧空間不夠用則會自動擴容。它可以被理解成一個被打包的程式碼段。goroutine並不是一個執行單元。
M:machine工作執行緒,就是真正用來執行程式碼的執行緒。由Go的runtime管理好它的生命周期。
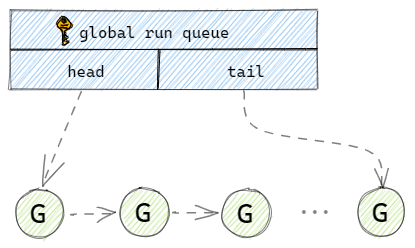
在Go語言初期使用一個全局的隊列來保存所有的G。當用戶新建一個G的時候,runtime就會將打包好的G放到全局隊列的隊尾,並維護好隊尾指針。當M執行完一個G後,就會到全局隊列的隊頭取一個G給M執行,並且維護好全局隊列的隊頭指針。
可以發現這裡有個很嚴重的問題,如果放任隨意加入G,也放任任何M隨意取G,那麼就會出現並發問題。解決並發問題很簡單,就是加鎖,Go語言團隊也確實是這樣做的。那麼加了鎖之後也就代表所有的存取操作都會涉及到這個單一的全局互斥鎖,那整個調度的執行效率大打折扣。除了鎖導致性能問題以外,還有類似系統調用時,工作執行緒經常被阻塞和取消阻塞,等等一些問題[2]。所以後續官方團隊調整了調度模型,加入了P的概念。
GMP模型
新的模型中引入了P的概念,G與M沒有什麼大的變化。
P:process處理器,代表了M所需的上下文環境,也可以理解為一個M運行所需要的Token,當P有任務時需要創建或者喚醒一個M來執行它隊列里的任務。所以P的數量決定了並行執行任務的數量,可以通過runtime.GOMAXPROCS來設定,現在的Go版本中默認為CPU的核心數。
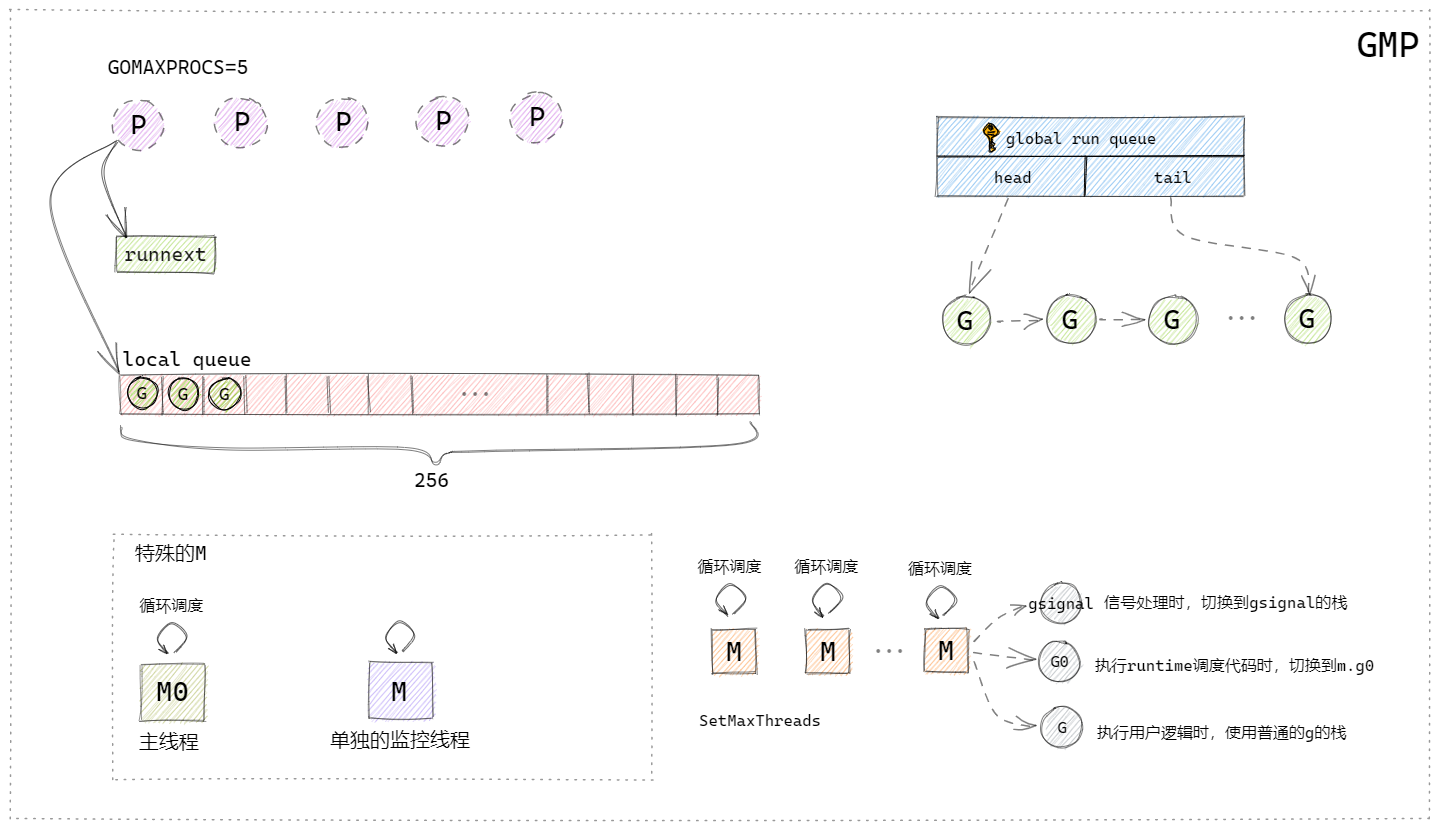
上圖根據曹大的GMP模型圖自行簡化繪製的。
P結構:一個P對應一個M,P結構中帶有runnext欄位和一個本地隊列,runnext欄位中存儲的就是下一個被M執行的G,每個P帶有一個256大小的本地數組隊列,這個隊列是無鎖的,這兩個數據結構類似於快取的概念,可以有效的解決全局隊列被頻繁訪問的問題,而且runnext和本地隊列是PM結構本地的,沒有其他的執行單元競爭,所以也不用加鎖。
M結構:
runtime中有兩個特殊的M:
①是主執行緒,它專門用來處理主線邏輯;
②是一個監控執行緒sysmon,它不需要P就可以執行,監控執行緒裡面是一個死循環,不斷地檢測是否有阻塞或者執行時間過長的G,發現之後將搶佔這些G。
普通的M:
普通的M會有很多個,空閑的M會被放在全局調度器的m idle(m 空閑)鏈表中,在需要m的時候會優先從這裡取,取不到的話就會創建新的M,M創建後就不會銷毀了。每個M結構有三個G,gsignal是M專門處理runtime的訊號的G,可以處理一些喚醒機制,G0是在執行runtime調度程式碼的時候需要切換到的G,還有一個G就是當前M需要執行的用戶邏輯的G。
M有幾種狀態:
- 自旋中(spinning): 暫時還沒找到 Goroutine 來執行,但是正在找的一個狀態。有這個狀態和 nmsping 的計數,能夠幫 runtime 判斷是不是需要再啟動額外的執行緒來執行 goroutine;
- 執行go程式碼中: M正在執行go程式碼, 這時候M會擁有一個P;
- 執行原生程式碼中: M正在執行原生程式碼或者阻塞的syscall, 這時M並不擁有P;
- 休眠中: M發現無待運行的G時會進入休眠,並添加到空閑M鏈表中, 這時M並不擁有P。
調度
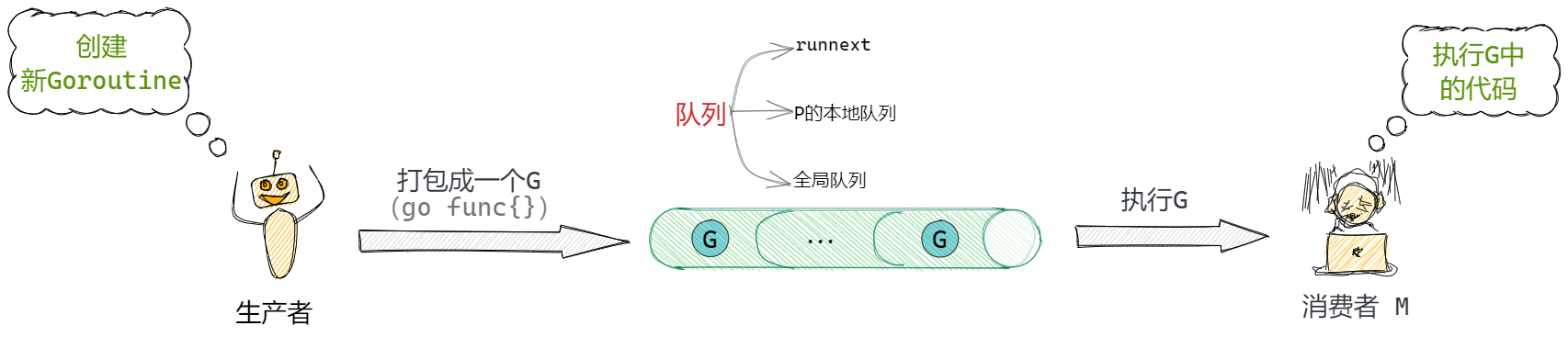
整體的調度流程就是一個生產消費過程。用戶作為生產者,用戶起了一個goroutine後,被打包成一個G,經過runtime的一系列調度後被M消費。
生產端
生產過程主要是指將一個打包好的G放入到隊列中的過程。
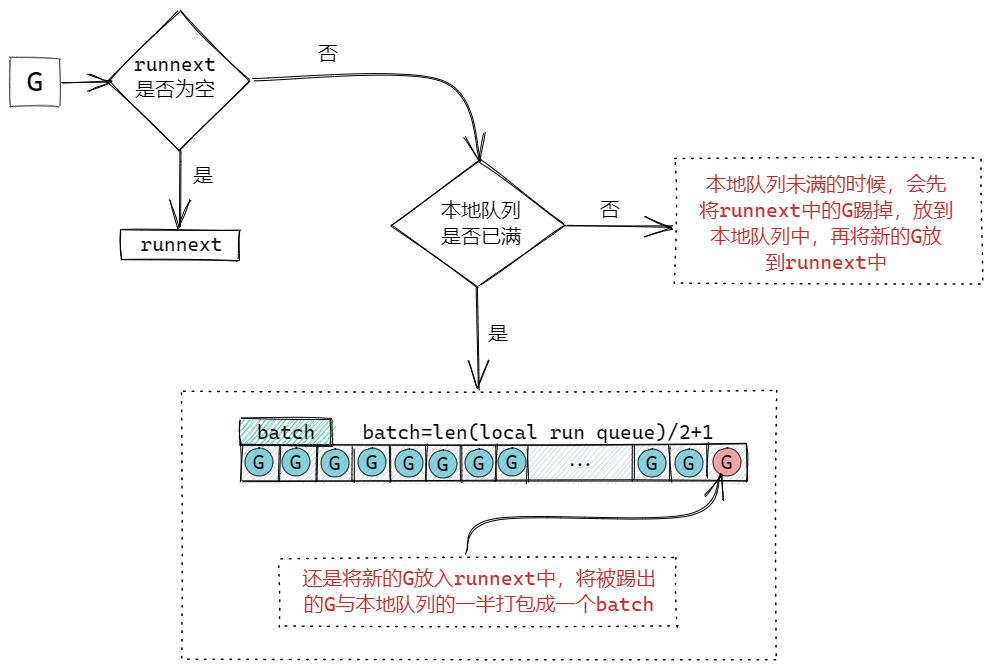
消費端
消費過程相較於生產過程複雜非常多,主要描述P和M怎樣被調度,最終由M完成執行的過程。
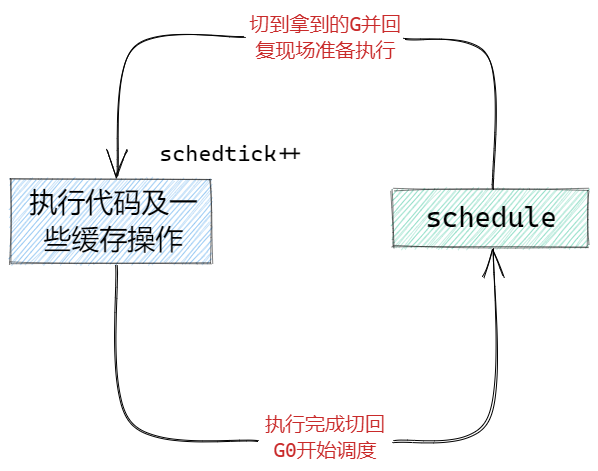
前面我們說到,每個M中有一個特殊的G0用來做調度,可以理解成當我們的M沒有執行完一個G後,需要切換到G0的棧空間,開始調用schedule函數找一個G來執行,找到後就切到找到的G的棧空間,並且執行它。
這邊注意到,在每次執行的時候,會有一個變數在不斷的++,這個schedtick我們會在每次schedule函數調度G的時候用到,接下來我們就來看看,每次調用schedule函數是如何找G的。

可以從圖中看到,整個尋找可執行G的過程,這個過程中只要找到G,就會結束schedule,返回拿到的G去執行。
-
在schedule函數中會判斷 schedtick%61 == 0,也就是每61次(為什麼是61次?我也不知道,算是個魔法數字,憑作者自己的考慮)就去全局隊列取一次(確保全局隊列中的G會被執行到)。否則我們就去當前M綁定的P的隊列中拿,當然優先執行runnext中的G。
-
當本地隊列中找不到可用的G的時候我們就會進入一個findrunnable的函數專門用來找G。
-
進入findrunnable中首先也是先在當前綁定的P的runnext和本地隊列中尋找。
-
從全局隊列中獲取,獲取的數量是 全局隊列的長度/gomaxprocs+1 ,但是最大只能拿128個G到本地隊列中,並拿出一個執行。
-
從netpoll網路輪詢器(監控網路I/O和文件I/O等耗時操作的)中獲取阻塞的G繼續執行。
-
work stealing,去其他P(隨機演算法隨機選中的)的本地隊列中竊取G到自己這邊,竊取的數量是被竊取隊列的一半。
-
再次嘗試去全局隊列獲取。
-
檢查所有空閑的P隊列,如果有可運行的G,就去綁定到那個P並執行。
-
再次嘗試去netpoll中獲取。
最後,在整個findrunnable中都沒有找到可以執行的G,當前的M就會進入休眠,並放到全局M鏈表中等待喚醒。
本文中,忽略了GC方面處理以及很多細節處理,真正的調度流程是非常複雜的,Go語言的官方程式碼是開源的並且有詳細的注釋,並且在Go版本升級過程中也會對一些邏輯有所調整,請自行注意時效性(本文基於Go1.15)
References
[1]//mp.weixin.qq.com/s/Nbl80rQRhuBpe-iJRELKHA “進程、執行緒與協程傻傻分不清?一文帶你吃透!”
[2]//docs.google.com/document/d/1TTj4T2JO42uD5ID9e89oa0sLKhJYD0Y_kqxDv3I3XMw/edit#heading=h.mmq8lm48qfcw “Scalable Go Scheduler Design Doc”


