多級快取架構(六)
在資訊暴炸的時代,為了在項目中提高數據載入效率,快取技術是必不可以少的,快取技術存在於應用場景的方方面面。從瀏覽器請求,到反向代理伺服器,從進程內快取到分散式快取。其中快取策略,演算法也是層出不窮,下面要說的就是一套如何實現一套可以對後端伺服器形成最小壓力的架構。
一、快取的解析
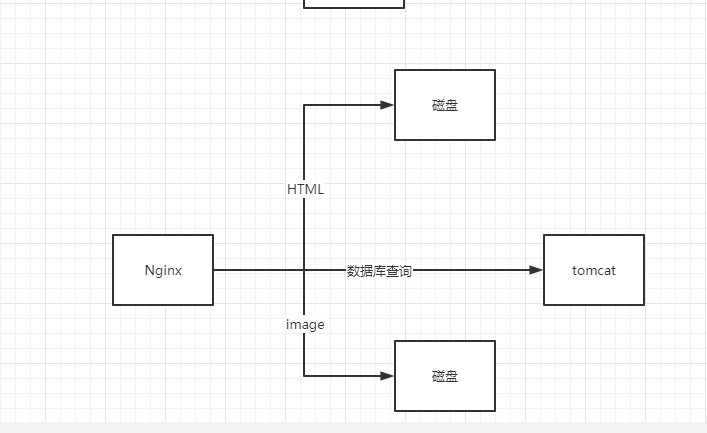
借一下上一篇文章中的圖,其實現在問很多人怎麼提高數據的訪問速度和效率,很多人都能回答出做快取處理,這句話可以說對也可以說不對,對是因為沒錯,快取是可以提高效率,但並不是做了快取處理他的並發量就一定能提升的上來,就以上圖為例,如果說前端請求很高,達到了2000K,如果所有的數據載入在後端redis中做了快取,如果這時所有用戶請求全部從前端傳到後端,伺服器照樣承受不了這麼高並發,所以說只在後端提升了載入速度是沒有用的,正確的做法是把快取在到Nginx中而不是存到後台伺服器,原因就是Nginx能承受的並發比tomcat要高。
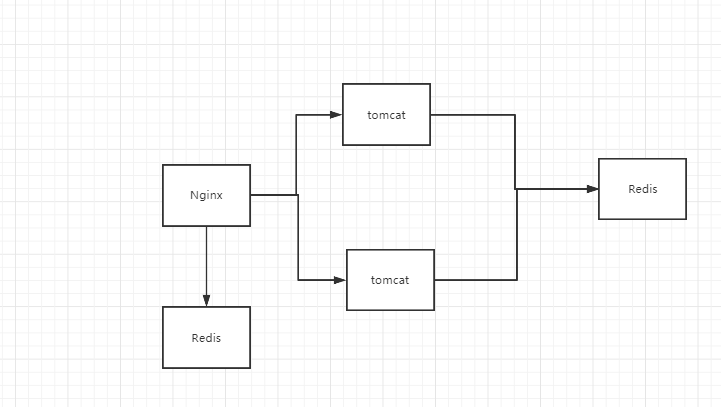
有了這個思路後,架構就要換一下了,如上圖,當第一次請求過來時走後台去後台Redis中查詢,並存在Nginx下面的Redis,之後的所有請求就不用走後台查詢,這樣性能就提升上來了,這時還要考慮一個問題,那就是如果Nginx下的Redis本身沒有快取數據又怎麼搞,那就要去Nginx快取中去找,因為Nginx本身是帶有快取功能的,如果Nginx中存在要的快取就直接從Nginx中返回給用戶,這樣一設計後可以幾十萬個請求就只有幾十個落在了後台伺服器上了。這種設計除了可以有效提高載入速度、降低後端服務負載之外,還可以防止快取雪崩,這也就是電商中用的多級快取架構體系。
二、應用
我們在看購物平台時有很多商品優先推薦展示,這些其實都是推廣商品,並非真正意義上的熱門商品,首頁展示這些商品數據需要載入效率極高,並且商城首頁訪問頻率也是極高,所以需要對首頁數據做快取處理,首先想到的就是Redis快取。

接下來要作的東西就是設計推廣商品的表結構及邏輯設計,其實這推廣產品不一定只在首頁出現,可能在別的地方也有,所以可以設計一張表存放這玩意,表結構如下
DROP TABLE IF EXISTS `ad_items`; CREATE TABLE `ad_items` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(100) DEFAULT NULL, `type` int(3) DEFAULT NULL COMMENT '分類,1首頁推廣,2列表頁推廣', `sku_id` varchar(60) DEFAULT NULL COMMENT '展示的產品', `sort` int(11) DEFAULT NULL COMMENT '排序', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=123 DEFAULT CHARSET=utf8;
建立實體類:
@Data @AllArgsConstructor @NoArgsConstructor //MyBatisPlus表映射註解 @TableName(value = "ad_items") public class AdItems implements Serializable{ @TableId(type = IdType.AUTO) private Integer id; private String name; private Integer type; private String skuId; private Integer sort; }
public interface AdItemsMapper extends BaseMapper<AdItems> { }
public interface SkuService extends IService<Sku> { /** * 根據推廣產品分類ID查詢Sku列表 * @param id * @return */ List<Sku> typeSkuItems(Integer id); }
@Service public class SKuServiceImpl extends ServiceImpl<SkuMapper, Sku> implements SkuService { @Resource private AdItemsMapper adItemsMapper; @Resource private SkuMapper skuMapper; @Override public List<Sku> typeSkuItems(Integer id) { //1.查詢當前分類下的所有列表資訊 QueryWrapper<AdItems> adItemsQueryWrapper = new QueryWrapper<AdItems>(); adItemsQueryWrapper.eq("type",id); List<AdItems> adItems = adItemsMapper.selectList(adItemsQueryWrapper); //2.根據推廣列表查詢產品列表資訊 List<String> skuids = adItems.stream().map(adItem->adItem.getSkuId()).collect(Collectors.toList()); return skuids==null || skuids.size()<=0? null : skuMapper.selectBatchIds(skuids); } }
@RestController @RequestMapping(value = "/sku") public class SkuController { @Autowired private SkuService skuService; /**** * 根據推廣分類查詢推廣產品列表 * */ @GetMappingpublic List<Sku> typeItems(@RequestParam(value = "id")Integer id){ //查詢 List<Sku> skus = skuService.typeSkuItems(id); return skus; } }
經過上面的程式碼就可以實現熱門商品推廣操作,但是有個問題,因為前面說過熱點數據訪問量大,是要放在快取裡面進行快取處理的,下面就來完成這最後一步
三、快取處理
在改程式碼前先要說明幾個常用的註解:
#Redis配置 redis: host: 192.168.32.135 port: 6379
然後在啟動類上開啟快取
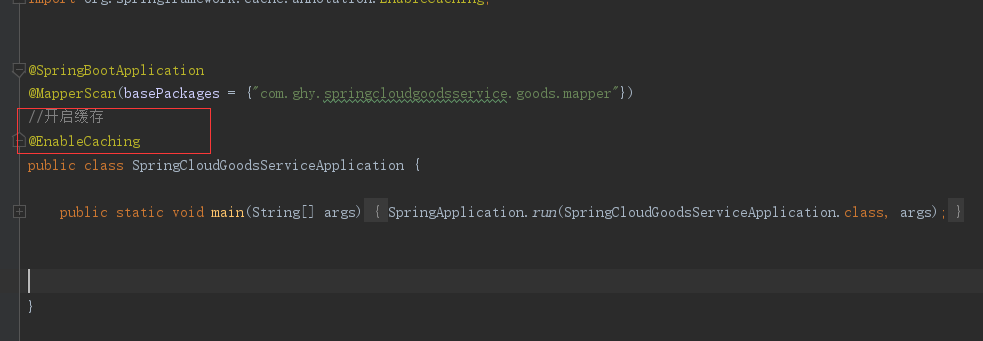
然後修改SKuServiceImpl類,加上紅框內內容

完成這一步快取就做好了,但是有個問題,前面說過熱點商品可能在多個地方都存被調用的情況,針對這個情況就要寫feigin介面,在寫feigin介面同時我也順便把修改和刪除操作給寫了,後面就懶著改這個類了
在spring-cloud-api的pom文件中先引用以下包
<!--工具包-->
<dependency>
<groupId>com.ghy</groupId>
<artifactId>spring-cloud-common</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<!--openfeign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
<version>2.2.5.RELEASE</version>
</dependency>
然後在spring-cloud-goods-api伺服器寫feigin介面
@FeignClient(value = "spring-cloud-goods-service")
public interface SkuFeign {
/****
* 根據推廣分類查詢推廣產品列表
*/
@GetMapping(value = "/sku")
List<Sku> typeItems(@RequestParam(value = "id")Integer id);
/****
* 根據推廣分類刪除推廣產品列表
*
*/
@DeleteMapping(value = "/sku")
RespResult delTypeItems(@RequestParam(value = "id")Integer id);
/****
* 根據推廣分類修改推廣產品列表
*/
@PutMapping(value = "/sku")
RespResult updateTypeItems(@RequestParam(value = "id")Integer id);
}
四、Lua+Redis實現多級快取
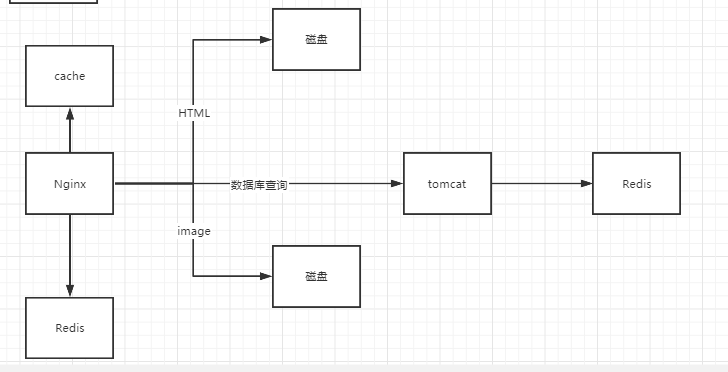
前面說過Lua和多級快取,接下來就把這兩個東西結合起來實現;前面說過前端請求過來後第一次會通過Nginx會分發到tomact進行查詢,然後將查詢的數據放到nginx中去;現在要做的操作就是通過Lua腳本完善後面的操作,操作流程是這樣,當請求過來
nginx會先執行lua腳本數據先從redis中去查詢先看下redis有沒有對應的數據,如果有則直接把數據響應給用戶,沒有再經過tomact查詢;這時有的人會問,如果一不小心把Redis伺服器中的數據全清空了怎麼辦,其實問題也不大,前面也提過Nginx本身也帶有快取,當Redis沒查找數據時,他會去Nginx自身查下,看能不能找到數據;
下面先寫一個lua腳本;
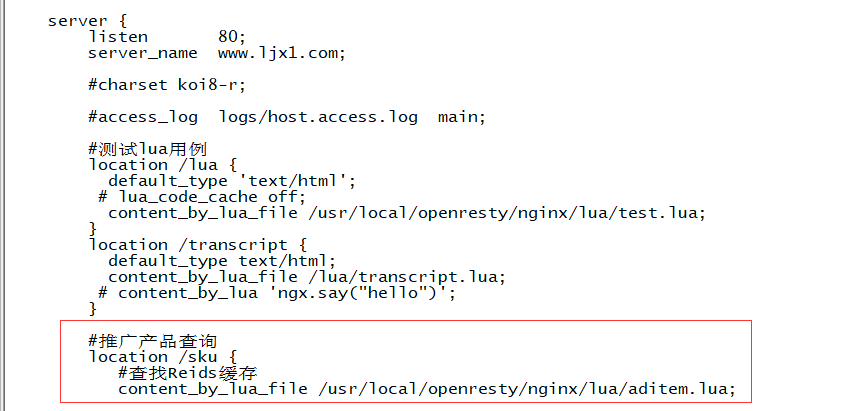
進入/usr/local/openresty/nginx/lua,在裡面創建一個aditem.lua腳本
--數據響應類型JSON ngx.header.content_type="application/json;charset=utf8" --Redis庫依賴 local redis = require("resty.redis"); local cjson = require("cjson"); --獲取id參數(type) local id = ngx.req.get_uri_args()["id"]; --key組裝 local key = "ad-items-skus::"..id --創建鏈接對象 local red = redis:new() --設置超時時間 red:set_timeout(2000) --設置伺服器鏈接資訊 red:connect("192.168.32.135", 6379) --查詢指定key的數據 local result=red:get(key); --關閉Redis鏈接 red:close() if result==nil or result==null or result==ngx.null then return true else --輸出數據 ngx.say(result) end
#推廣產品查詢 location /sku{ content_by_lua_file /usr/local/openresty/nginx/lua/aditem.lua; }

五、nginx代理快取
前面有提過,當Redis快取沒有數據時,請求會去nginx快取找數據;在這時就要提到一個東西,那就是proxy_cache ;proxy_cache 是用於 proxy 模式的快取功能,proxy_cache 在 Nginx 配置的 http 段、server 段中分別寫入不同的配置。http 段中的配置用於定義 proxy_cache 空間,server 段中的配置用於調用 http 段中的定義,啟用對server 的快取功能。要想使用它就要完成兩個步驟:第一個步驟是定義快取空間;第二個步驟是在指定地方使用定義的快取 。
1、開啟Proxy_Cache快取,這個需要在nginx.conf中配置才能開啟快取:
proxy_cache_path /usr/local/openresty/nginx/cache levels=1:2 keys_zone=proxy_cache:10m max_size=1g inactive=60m use_temp_path=off;
#先找Nginx快取 rewrite_by_lua_file /usr/local/openresty/nginx/lua/aditem.lua; #啟用快取openresty_cache proxy_cache proxy_cache; #針對指定請求快取 #proxy_cache_methods GET; #設置指定請求會快取 proxy_cache_valid 200 304 60s; #最少請求1次才會快取 proxy_cache_min_uses 1; #如果並發請求,只有第1個請求會去伺服器獲取數據 #proxy_cache_lock on; #唯一的key proxy_cache_key $host$uri$is_args$args; #動態代理,這是在快取中都沒查到的情況
proxy_pass http://192.168.32.32:8081;
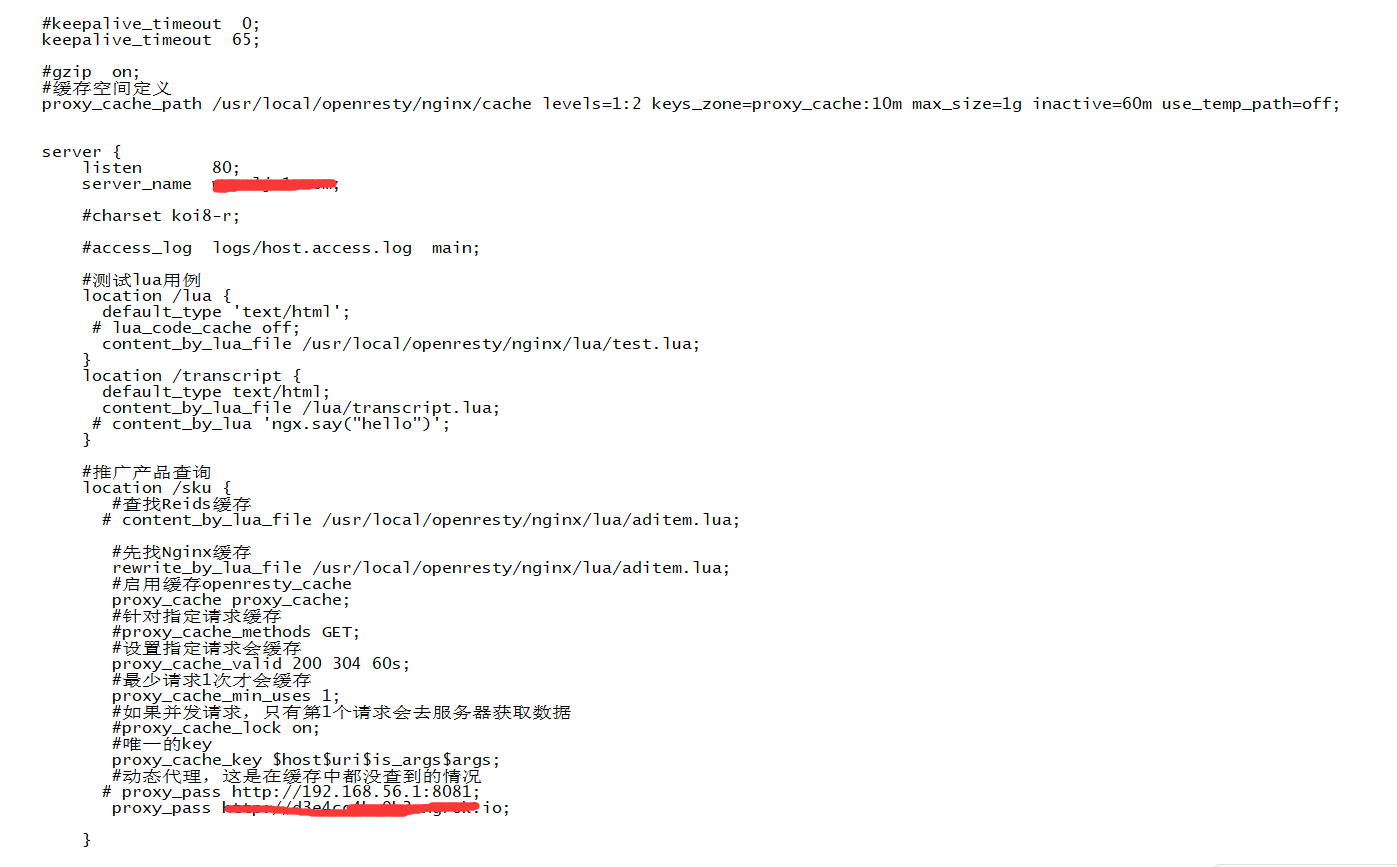
1:先查找Redis快取 2:Redis快取沒數據,直接找Nginx快取 3:Nginx快取沒數據,則找真實伺服器
這時還可以發現在cache目錄下多了目錄個文件,這個東西就是Nginx快取;這裡補充下,如果你的linux是布在雲上而你的項目是內外,那麼動態代理配置的就是項目的公網地址;
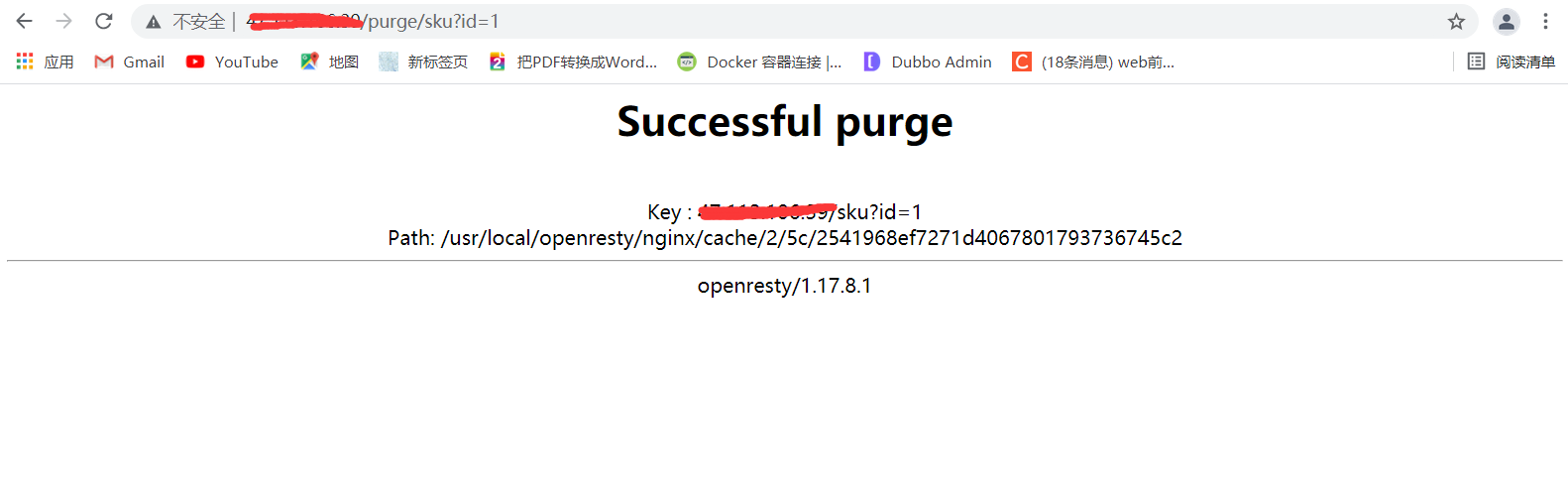
六、Cache_Purge代理快取清理
#清理快取
location ~ /purge(/.*) {
#清理快取
proxy_cache_purge proxy_cache $host$1$is_args$args;
}