CVPR2021 | 開放世界的目標檢測
本文將介紹一篇很有意思的論文,該方向比較新,故本文保留了較多論文中的設計思路,背景知識等相關內容。
前言:
人類具有識別環境中未知對象實例的本能。當相應的知識最終可用時,對這些未知實例的內在好奇心有助於了解它們。 這促使我們提出一個新的電腦視覺問題,稱為:「開放世界對象檢測」,其中模型的任務是:
1)將尚未引入的對象識別為「未知」,無需明確監;
2)在逐漸接收到相應的標籤時,逐步學習這些已識別的未知類別,而不會忘記先前學習的類別。
我們制定了這個問題,引入了評估協議並提供了一種新穎的解決方案,我們稱之為 ORE:開放世界對象檢測器,基於對比聚類和基於能量的未知對象識別。
我們的實驗評估和消融研究分析了 ORE 在實現開放世界目標方面的功效。作為一個有趣的副產品,我們發現識別和表徵未知實例有助於減少增量心理對象檢測設置中的混亂,在那裡我們實現了SOTA性能,而無需額外的方法論。我們希望我們的工作能夠吸引對這個新確定但至關重要的研究方向的進一步研究。
論文:Towards Open World Object Detection
源碼://github.com/JosephKJ/OWOD
關注公眾號CV技術指南,及時獲取更多電腦視覺技術總結文章。
本文出發點
深度學習加速了目標檢測研究的進展,其中模型的任務是識別和定點陣圖像中的對象。 所有現有的方法都在一個強有力的假設下工作,即所有要檢測的類在訓練階段都可用。當我們放寬這個假設時會出現兩個具有挑戰性的場景:
1)測試影像可能包含來自未知類的對象,這些對象應該被歸類為未知。
2)當有關此類已識別未知數的資訊(標籤)可用時,模型應該能夠逐步學習新類。
發展心理學研究發現識別未知事物的能力是吸引好奇心的關鍵。這種好奇心激發了學習新事物的慾望。 這促使我們提出一個新問題,即模型應該能夠將未知對象的實例識別為未知對象,然後在訓練數據逐漸到達時以統一的方式學習識別它們。 我們將此問題設置稱為開放世界對象檢測。
開放世界對象檢測設置比現有的封閉世界、靜態學習設置更自然。 世界在新類的數量、類型和配置方面是多樣化和動態的。 我們不能假設在訓練期間可以看到推理時期望的所有類。 檢測系統在機器人、自動駕駛汽車、植物表型分析、醫療保健和監控中的實際部署無法在內部訓練的情況下全面了解推理時預期的類別。
人們可以從部署在這種設置中的對象檢測演算法中期望的最自然和現實的行為是自信地將未知對象預測為未知,並將已知對象歸入相應的類。 當有關已識別未知類的更多資訊可用時,系統應該能夠將它們合併到其現有的知識庫中。 這將定義一個智慧對象檢測系統,我們正在努力實現這一目標。
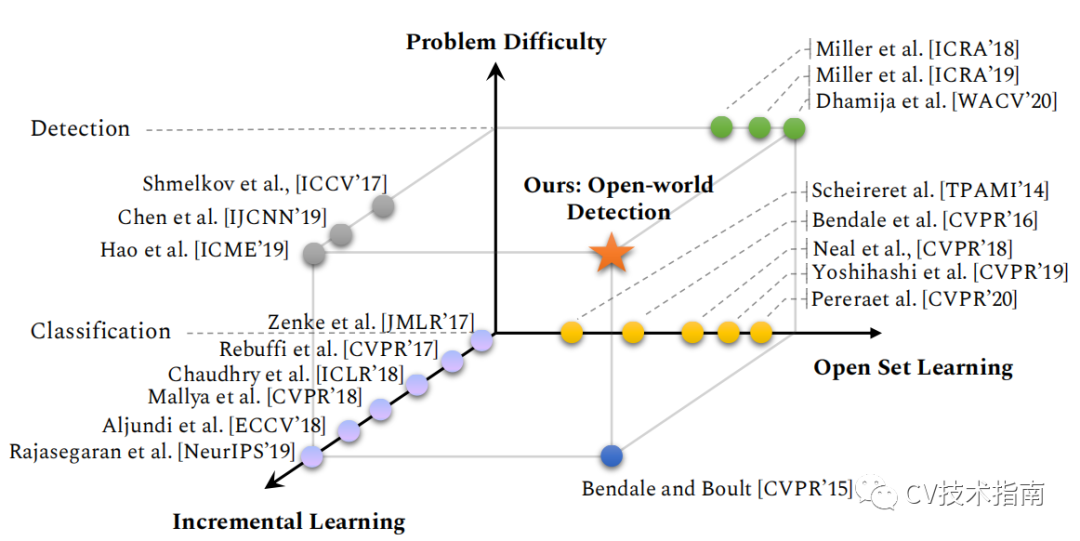
![]()
電腦視覺任務難度圖
本文貢獻
• 我們引入了一種新穎的問題設置,即開放世界對象檢測,它更接近地模擬現實世界。
• 我們開發了一種稱為 ORE 的新方法,它基於對比聚類、未知感知提議網路和基於能量的未知識別,以應對開放世界檢測的挑戰。
• 我們引入了一個全面的實驗設置,它有助於測量對象檢測器的開放世界特徵,並根據競爭基準線方法對其進行基準測試。
• 作為一個有趣的副產品,所提出的方法在增量對象檢測方面實現了最先進的性能,即使主要不是為此而設計的。
Open World Object Detection

![]()
開放世界對象檢測設置考慮了一個對象檢測模型 Mc,該模型經過訓練可以檢測所有以前遇到的 C 個對象類。 重要的是,模型 MC 能夠識別屬於任何已知 C 類的測試實例,並且還可以通過將其分類為未知類實例來識別新的或未見過的類實例,用標籤(0) 表示。然後人類將未知的實例集 Ut識別 n 個新的感興趣類(在潛在的大量未知數中)並給模型提供訓練示例。
學習器逐步添加 n 個新類並自行更新以生成更新的模型 MC+n,而無需在整個數據集上從頭開始重新訓練。已知類集也更新 Kt+1 = Kt + {C + 1, … . . ,C+n}。這個循環在物體檢測器的整個生命周期中持續,在那裡它用新知識自適應地更新自己。
ORE(開放世界目標檢測器)
一種成功的開放世界對象檢測方法應該能夠在沒有明確監督的情況下識別未知實例,並且在將這些識別出的新實例的標籤呈現給模型以進行知識升級(無需從頭開始重新訓練)時,不會忘記早期實例。 我們提出了一個解決方案 ORE,它以統一的方式解決了這兩個挑戰。
設計思路如下:
神經網路是通用函數逼近器,它通過一系列隱藏層學習輸入和輸出之間的映射。在這些隱藏層中學習的潛在表示直接控制每個功能的實現方式。 我們假設在對象檢測器的潛在空間中學習明確區分類別可能會產生雙重影響。
首先,它幫助模型識別未知實例的特徵表示與其他已知實例有何不同,這有助於將未知實例識別為新穎性。 其次,它有助於學習新類實例的特徵表示,而不會與潛在空間中的先前類重疊,這有助於在不遺忘的情況下進行增量學習。幫助我們意識到這一點的關鍵部分是我們在潛在空間中提出的對比聚類。
為了使用對比聚類對未知數進行最佳聚類,我們需要對未知實例進行監督。 即使是潛在的無限未知類集的一小部分,手動注釋也是不可行的。 為了解決這個問題,我們提出了一種基於區域提議網路(RPN) 的自動標記機制來偽標記未知實例。 潛在空間中自動標記的未知實例的固有分離有助於我們基於能量的分類頭區分已知和未知實例。
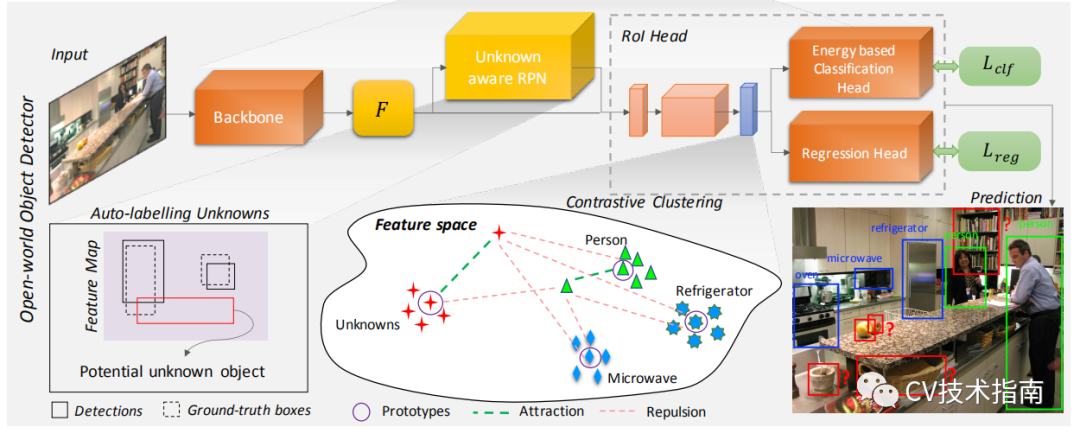
![]()
如上圖所示,選擇 Faster R-CNN 作為基礎檢測器。與單階段的Retina Net 檢測器和YOLO 檢測器相比,它具有更好的開放集性能。
Faster R-CNN是一個兩階段的目標檢測器。在第一階段,一個與類別無關的區域提議網路 (RPN) 從共享骨幹網路的特徵圖中提出可能具有對象的潛在區域。第二階段對每個提議區域的邊界框坐標進行分類和調整。由感興趣區域 (RoI) 頭部中的殘差塊生成的特徵進行對比聚類。RPN 和分類頭分別用於自動標記和識別未知數。
對比聚類演算法如下:

![]()
Auto-labelling Unknowns with RPN
我們基於區域提議網路 (RPN) 與類別無關的事實。給定輸入影像,RPN 為前景和背景實例生成一組邊界框預測,以及相應的對象分數。我們將那些具有高對象分數但不與真實對象重疊的提議標記為潛在的未知對象。簡單地說,我們選擇前 k 個背景區域提議,按其對象性分數排序,作為未知對象。
Energy Based Unknown Identififier
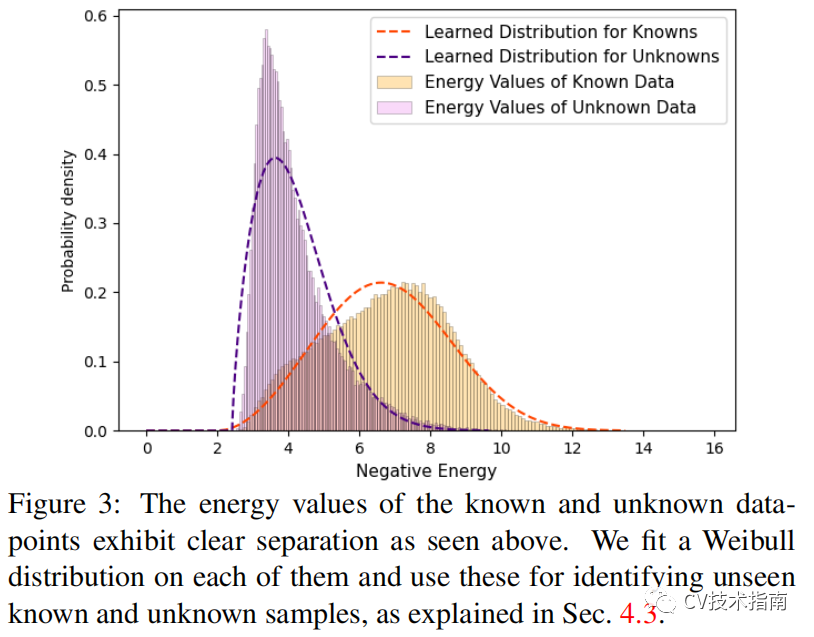
![]()
由於通過對比聚類在潛在空間中實施了清晰的分離,可以看到已知類數據點和未知數據點的能級明顯分離,如上圖所示。我們通過energy based models(EBMs)來學習一個能量函數,使用單個輸出標量來估計觀察變數 F 和可能的輸出變數集 L 之間的兼容性。
Alleviating Forgetting
我們考慮了終身學習中的很多方法,最終決定使用相對簡單的 ORE 方法來減輕遺忘,即我們存儲一組平衡的示例並在每個增量步驟之後微調模型。在每一點上,我們確保每個類的最少 Nex 實例存在於示例集中。
評協議
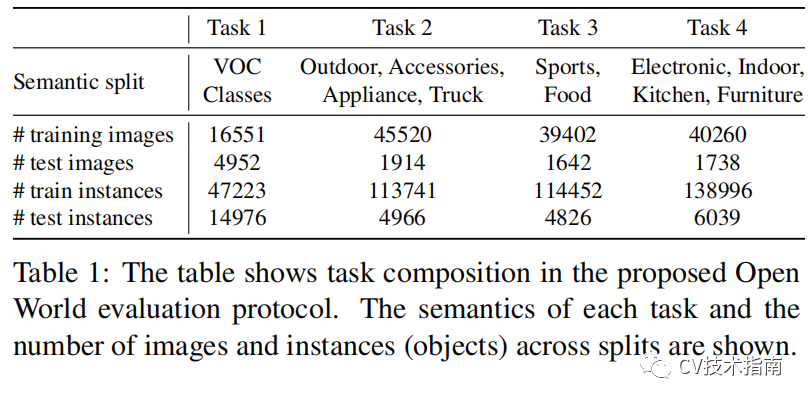
![]()
實驗結果
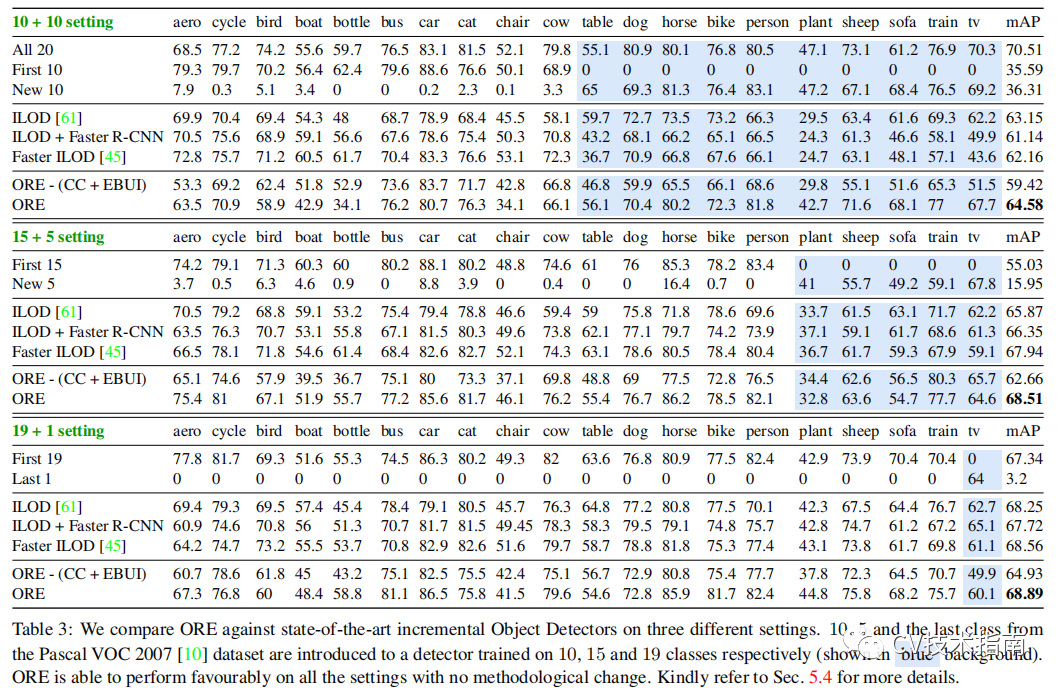
![]()
藍色部分為剛開始作為背景,在經過ORE訓練後自主識別的準確度。

![]()
該圖展示了ORE通過RPN很好地識別了一些未知對象,但在第三張圖中也有指鹿為馬的現象出現。
本文來源於公眾號 CV技術指南 的論文分享系列。
歡迎關注公眾號 CV技術指南 ,專註於電腦視覺的技術總結、最新技術跟蹤、經典論文解讀。
在公眾號中回復關鍵字 「技術總結」 可獲取以下文章的匯總pdf。



其它文章

